Spark mode
local mode
로컬머신 한대로 spark application을 개발하고, 데이터를 처리할 수 있다.
local모드에서 spark optimization을 하고자 한다면 아래의 두가지를 고려하여 application을 작성할 수 있게 된다.
core의 갯수 (프로세스에서 처리되는 스레드의 갯수와 동일해진다)
local[*]을 사용하게 된다면 물리머신에 존재하는 core을 모두 가져다 사용하게 된다.driver의memory
spark = SparkSession.builder \
.master("local[n]") \
.appName("Spark_Submit") \
.config("spark.driver.memory","2G")\
.getOrCreate()standalone mode
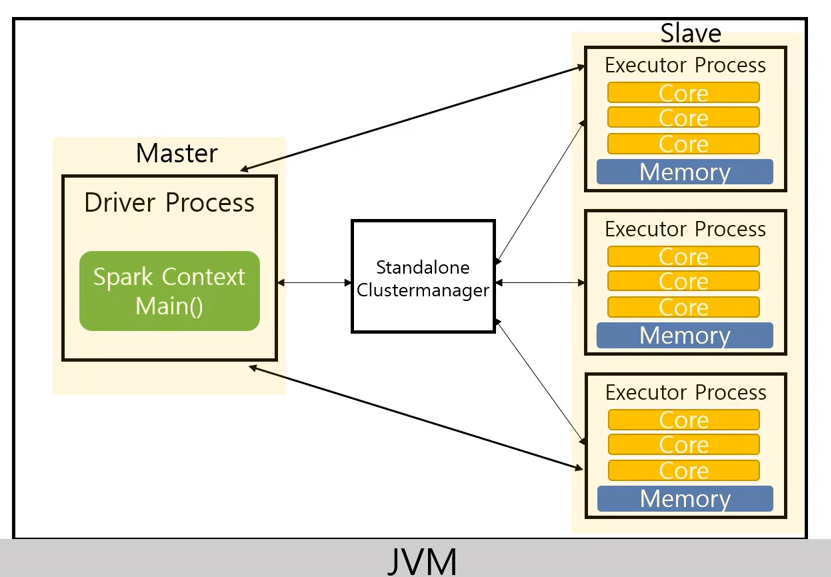
로컬머신 한대로 spark application을 실행시킬 수 있다. 완벽한 분산 시스템(여러대의 서버)은 아니지만
아래의 두 가지 정도를 적절하게 구성하여 분산 처리를 할 수 있다.
executor의 갯수executor당core및memory의 할당
이때 cluster 매니저를 따로 사용하는 것이 아닌 spark내부에 자체적으로 존재하는 maneger를 사용한다.
이를 standalone모드라고 한다.
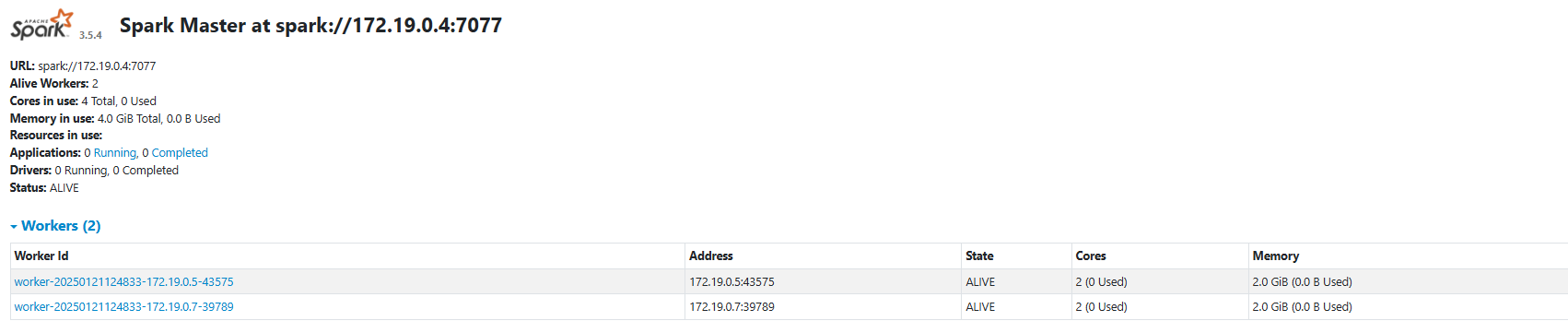
클러스터 구성을 위해 1개의 마스터 노드와 2개의 worker 노드를 구성했다.
특징으로는
worker노드가masterurl을 찾을 수 있도록hostname을 지정해 주었다.worker노드의 각 컨테이너에 메모리와 core 의 제한을 두었다.
이는spark application을 제출할 시에 해당 자원을 넘어서 제출할 수 없다.
services:
spark-master:
<<: *spark-common
command: bin/spark-class org.apache.spark.deploy.master.Master
hostname: spark-master
environment:
- SPARK_MODE=master
- SPARK_MASTER_PORT=7077
- SPARK_MASTER_WEBUI_PORT=8080
ports:
- "7077:7077"
- "9080:8080"
- "4444:4040"
expose:
- "7077"
spark-worker-1:
<<: *spark-common
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKER_WEBUI_PORT=8081
- SPARK_WORKER_MEMORY=2G
- SPARK_WORKER_CORES=2
depends_on:
- spark-master
ports:
- "9081:8081"
spark-worker-2:
<<: *spark-common
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKER_WEBUI_PORT=8081
- SPARK_WORKER_MEMORY=2G
- SPARK_WORKER_CORES=2
depends_on:
- spark-master
ports:
- "9082:8081"-
docker compose file에 준 변수에 맞게 worker 노드가 구성이 됐다.
-
SparkSession에서master를master노드의 URL로 작성한다.
spark = SparkSession.builder \
.master("spark://spark-master:7077") \
.appName("Spark_Submit") \
.config("spark.jars","/opt/airflow/resources/elasticsearch-spark-30_2.12-8.11.1.jar,/opt/airflow/resources/mysql-connector-j-8.0.33.jar") \
.config("spark.eventLog.dir","/opt/bitnami/spark/spark-events")\
.config("spark.history.fs.logDirectory","/opt/bitnami/spark/spark-events")\
.getOrCreate()Spark submit하는 쉘 스크립트에서executor당core수와memory도 설정이 가능하다.
#!/bin/bash
script=$@
JOBNAME="RefineData"
DRIVER_MEMORY="2g"
EXECUTOR_MEMORY="2g"
echo "Job name is ${JOBNAME}"
echo "submit this job >> ${script}"
echo 'start spark submit with bash operator'
spark-submit \
--name ${JOBNAME} \
--jars /opt/airflow/resources/elasticsearch-spark-30_2.12-8.11.1.jar,/opt/airflow/resources/mysql-connector-j-8.0.33.jar \
--master spark://spark-master:7077 \
--conf spark.executor.cores=2 \
--conf spark.driver.memory=${DRIVER_MEMORY} \
--conf spark.executor.memory=${EXECUTOR_MEMORY} \
--conf spark.num.executors=2\
--conf spark.eventLog.enabled=true\
${script}