
DB 구성 및 ETL 컴포넌트 구성
Intro
원하는 웹서버를 구현하기 위해 데이터를 배치단위로 수집하고, 수집한 데이터를 저장하기 위한 ETL 프로세스를 구축하면서 필요한 컨테이너들을 여러개 띄우기로 했다.
하지만 특정 컨테이너가 계속해서 내려가는 상황 혹은 터미널이 아예 동작하지 않는 문제가 발생했다.
이유는 로컬 컴퓨터의 자원을 잘 파악하고 할당하지 못해서 생긴 문제였다.
Spark Container
Spark의 클러스터 매니저를 따로 두지 않고 서버 한대로 작동하는 방식으로local 모드와 Standalone 모드를 지원한다.
Standalone mode테스트를 위해 작성한docker-compose파일
spark-worker-3:
<<: *spark-common
command: bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKER_WEBUI_PORT=8081
- SPARK_WORKER_MEMORY=2G
- SPARK_WORKER_CORES=2
depends_on:
- spark-master
ports:
- "9083:8081" 가장 큰 문제는 여기서 발생했다.
spark 클러스터를 구성하면서 자원을 할당해 주어야 하는데 각각의 클러스터가 cpu cores를 2개씩 사용한다는 점이다.
현재 개발하고 있는 컴퓨터의 자원을 확인해보면 8개의 코어가 존재하는데, 당연히 정상적으로 작동할 수가 없다.
( 예전에 suffle과 partitioning 에서 발생하는 병목현상을 확인하기 위해 구성했던 클러스터를 그대로 사용한 것이 문제..)
강제로 컨테이너가 종료되고 로그도 제대로된 로그를 발생시키지 않았다.
docker desktop에 Container CPU usage 를 확인해볼 수 있었다.
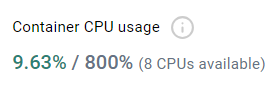
문제가 생겼을 당시 사용가능한 CPU수는 1개였는데, 7배 이상의 사용을 요구했으니, 컨테이너가 내려가는 것이 당연했다.
Next
로컬 스토리지에 데이터가 잘 저장된 것이 확인됐다.
DB는 ElasticSearch 와 MySQL를 사용했는데, Java Spring을 이용해 Restful하게 서버를 구축하고 RESTAPI 이점을 최대한 구현해보려 한다.
