현대 데이터센터, 클러스터 구성의 트렌드는 Disaggregated Architecture라고 볼 수 있다. 이때, 우리는 흔히 Compute Node, Storage Node, Memory Node 등 기존 서버들에 특정 역할을 부여하고 이름을 구분 짓곤 하는데, 직전 포스트에서 현대 AI향 Compute Node가 어떻게 생겼고 어떤 Feature들을 가지는지 간단히 알아본 바 있다. 자, 오늘은 Storage Node이다.
몇주전 StorageReview에 QSAN에서 최근 출시한 XN4226D에 대한 리뷰글이 올라왔다. XN4226D는 NVMe 기반 Block/File-Supported Storage Solution, 2U 섀시에 26개의 NVMe Bay를 탑재하였다. Dual-Active Controller 구조를 통해 고가용성을 제공한다고 프로모팅되고 있으며, QSM4라는 전용 소프트웨어를 통해 Snapshot, (De)Duplication, Compression, GC 등을 수행한다고 한다.

XN4는 QSAN의 대표적인 NVMe Array 제품군 (정식 명칭은 Expandable NVMe All Flash Unified Storage라고 함)으로, 해마다 업그레이드 버전이 나오고 있다.
오늘 포스트에선 위 StorageReview 리뷰글을 토대로 XN4의 최신 제품인 XN4226D를 '''현시대의 AI향 대표적인 Storage Node '''로서 소개하고자 한다 (Technically 얘기하면 Storage Node에 연결된 Array라고 말할 수 있으나 본 포스팅에선 그냥 Node라고 일컫는다).

주요 스펙
- 스토리지 인터페이스: Block (iSCSI, FCP, NVMe-oF)과 File (NFS, SMB, FTP, WebDAV)을 동시 지원
- 통신 프로토콜: NVMe-oF over TCP/RDMA, iSCSI, Fibre Channel 등 지원
- 성능
- 셋업: Dell PowerEdge R750 + 4 NVIDIA ConnectX-5 dual-port 25G NICs + 8개 DAC (Direct Attach Copper) 케이블 직접 연결 (No Switch) + RAID6 (8개 Block Volume가 even하게 분산 저장) + FIO
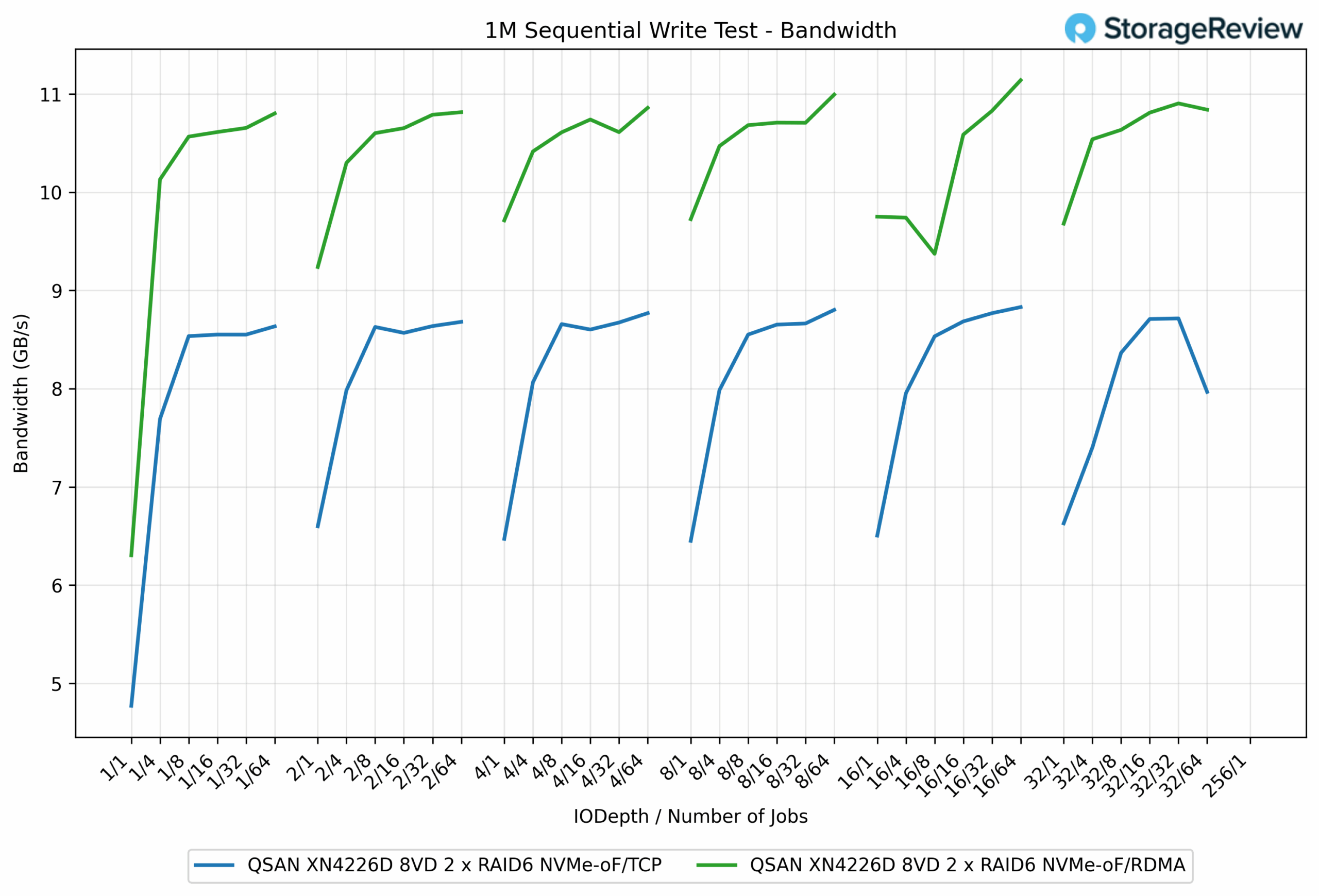
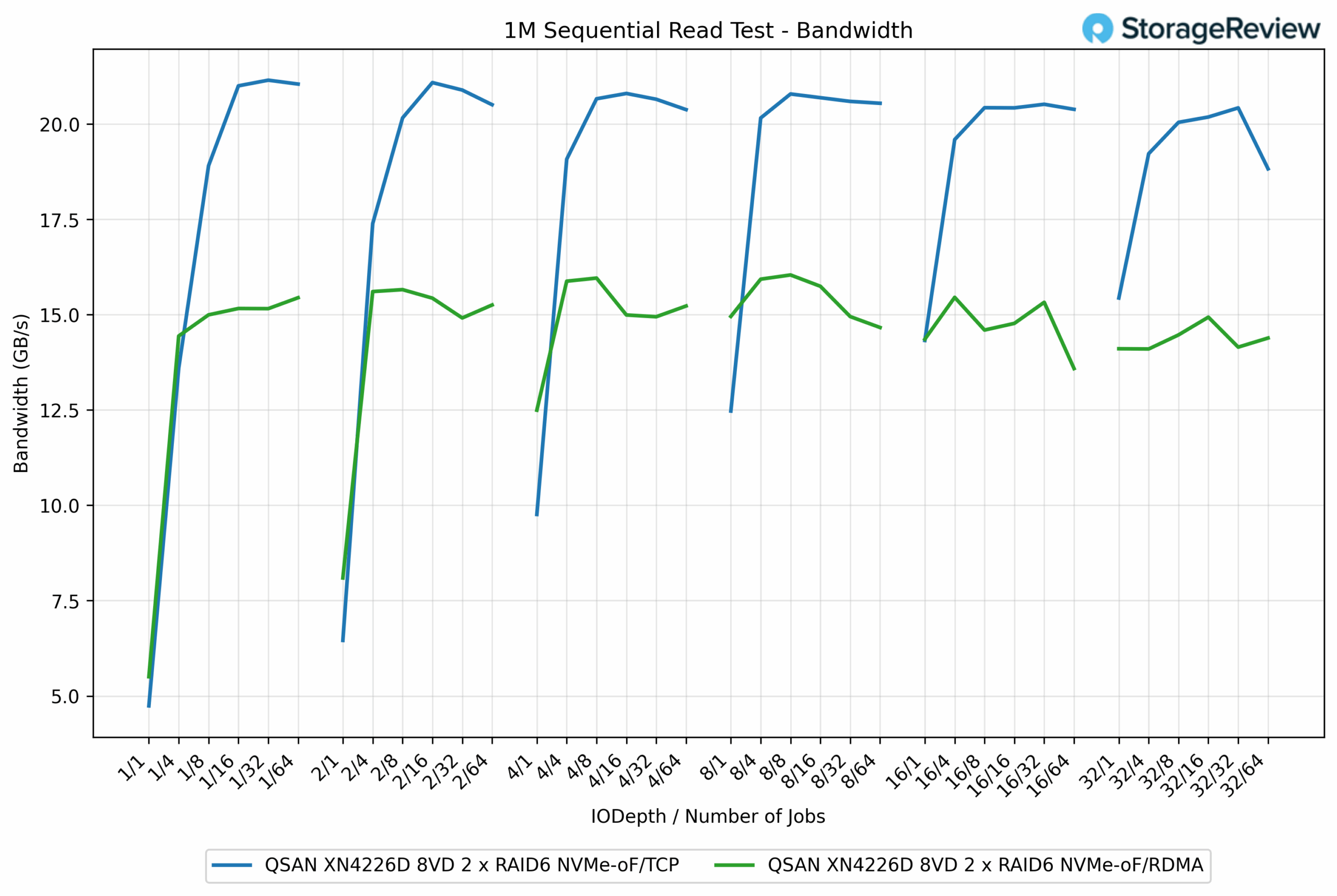
- 1M Sequential Workload
- Write - RDMA 11.14 GB/s (26%↑ vs TCP)
- Read - TCP 21.21 GB/s (33%↑ vs RDMA)
- Write - RDMA 11.14 GB/s (26%↑ vs TCP)
- Random Workload
- 64K Random Write - RDMA ≈ 21%↑ IOPS
- 16K Random Read - RDMA ≈ 23배↑ IOPS 및 37배 낮은 Latency
- 4K Random Read/Write: RDMA 5-10% 우세
일단 순차 읽기에서 TCP 기반 NVMe-oF 성능을 상당히 잘 잡은 모습이고, 그외에도 전체적으로 측정치가 우수함. 이정도면 Pure Storage, Dell의 하이엔드 NVMe Arrray 제품군과 유사한 수준이라고 보면 될듯
- 확장성: 2U 섀시 내 26 2.5″dual-port U.2 / U.3 NVMe SSD 2.5″ SAS SSD (for expansion units) 3.5″ SAS HDD (for expansion units) 탑재 가능 (U.2 NVMe (PCIe Gen 4 8lane) SAS 12 Gb/s (for expansion units)) - 최대 Raw는 798TB, Expansion은 16.7 PB까지 확장 가능
- Controller CPU: Intel Xeon 4코어/8코어 기반
- 메모리: 16 x 32GB DDR4 RDIMM - 최대 2 TB DDR4 RDIMM 확장 가능
- 네트워크 포트
- (기본) 2.5 GbE × 2, 10 GbE SFP+ × 8
- (옵션) 25 GbE SFP28, 100 GbE QSFP, 32 Gb Fibre Channel
- 확장: 최대 20개의 SAS 확장 유닛 연결
- 파워: 850 W × 2, 80 Plus Platinum 등급


소프트웨어 Features
- QSAN 스토리지 전용 운영체제인 QSM4 탑재
- Web UI와 RESTful API 제공
- RAID 0, 1, 5, 6, 10, 50, 60 등 다수 지원
- Thin Provisioning, Compression, GC, 스냅샷, 비동기·동기 복제
- SSL/TLS, RBAC, AD/LDAP, SED, ISE 지원
- REST API 기반 자동화, 알림, 로그, 모니터링 대시보드
File 서비스를 하고자 한다면, GUI 환경에서 위처럼 필요한 프로토콜을 여러개 선택해 시작할 수 있다.
QSAN의 브랜드 색상을 따라서 GUI를 만든 것으로 보이는데, 개인적으로 이런 초록 계열 색상이 스토리지 같은 느낌도 나고 보기도 편한거 같다.
GPU Direct Storage 성능
리뷰어가 NVIDIA H100 GPU가 2개 장착된 서버 환경 (Dell PowerEdge R7715 + Quad-Port Broadcom 25G NIC (Direct Attach), 4 Connections + NVMe-oF over TCP)에서 Magnum IO GDS 성능을 측정한 결과
- Sequential Read 최대 11.0 GiB/s
- Sequential Write 최대 7.2 GiB/s
로 측정되었다.
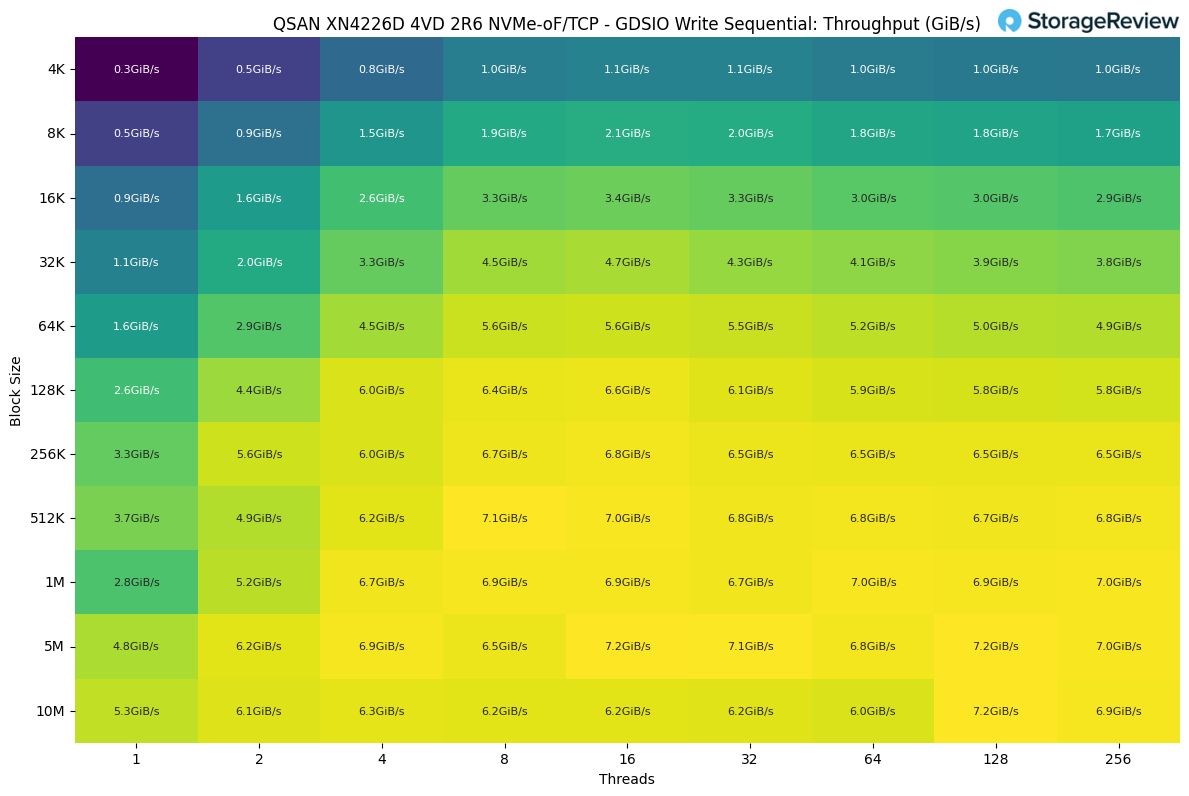
"In the GDSIO Sequential Write workload, throughput scaled with both block size and thread count but plateaued well below the read performance ceiling. The system achieved a peak of 7.2 GiB/s, utilizing larger block sizes, such as 5M and 10M, at 128 threads."
"At the smallest block sizes, throughput was modest. With 4K blocks, performance started at 0.3GiB/s with a single thread and scaled to 1.0 GiB/s with 32 threads, then leveled off. Increasing the block size to 64K unlocked more bandwidth, reaching 5.6GiB/s with eight threads before tapering slightly at higher concurrency."
"The best balance occurred around 512K to 1M blocks, where throughput ranged from 6.7 to 7.1GiB/s across different thread counts, indicating that the system reached saturation in this range. Beyond that point, additional threads did not yield meaningful gains, and in some cases, performance actually dipped slightly due to increased overhead."
AI향의 하이엔드 Storage Node라 하면, 앞으로의 시대에는 이 정도 스펙의 어레이는 생각해야한다.
그래서,, 얼마야?
Compute Node 포스트에서도 얘기했지만, 그래서 궁극적으로 이런 하이엔드급 장비는 Compute ~ Storage 상관 없이 기본적으로 매우 비싸다.
단순 장비 구매 가격뿐만 아니라, 거기에 붙어야할 서브 장비들, 전력, 운용 비용 등 모든 요소를 고려했을 때 TCO 관점에서 쉽사리 구매를 결정할 수 없는 장비들이다.
대충 추정해보자.
XN4의 본체 가격이 공개적으로 나와있진 않아서 정확히 얼마인진 모르나, 대충 5000만원 정도 한다고 치자.
요즘 NVMe U.2 7.68TB Enterprise SSD는 보통 100만원 정도 보면 된다.
26개 꽉 채운다고 하면 2600만원이다.
이게 다인가?
DAC이나 광케이블 하나당 수십 만원에, 100GbE 스위치 쓴다고 하면 대충 이것만 1500만원은 봐야겠지. NIC 2개 꼽으려면 400만원 정도 든다 치고, 그외 나머지 부수 장비들까지 고려하면, 얼추 1억에 가까운 금액까지 치솟을 수 있음을 가늠할 수 있다. 각 컴포넌트를 완전 최상급으로만 갖추면 훨씬 더 될거고, 거기에 운용/관리 비용, 전기료까지 생각하면 상당한거다.
이전 포스팅에서 Compute Node는 하이엔드 급이면 2억 이상이라고 얘기했었는데, Disg. Arch.에서 수천-수만대의 Node를 두고 운용한다는게 정말 얼마나 큰 돈이 드는 일인지 새삼 느껴진다!
Cost-Efficiency는 굉장히 중요하다,,
본 글에 담긴 Claim격의 서술은 모두 제 개인의 의견일 뿐이며 아무런 대표성을 가지지 않습니다.
