Compute Node란?
컴퓨터 시스템 분야 논문이나 article들을 읽다보면 흔히 Compute Node란 표현을 쓰곤 한다. Compute Node란 뭘까? 우리가 통상적으로 Compute Node라고 말할 땐, 데이터센터 안에서 실제 연산을 담당하는 기본 단위 서버 정도의 의미를 갖는다. 반대로 Storage Node, Memory Node라는 개념들도 있고, 그 핵심엔 Disaggregated Architecture 철학이 있으나, 본 포스트에선 이런 쪽을 상세히 다루고자 하는건 아니다.
아무튼, Compute Node는 데이터를 이용해 AI 학습/추론, Data Analytics, 시뮬레이션 같은 작업을 수행한다. 대규모 클러스터나 슈퍼컴퓨터를 구성할 땐 보통 수백에서 수천 대의 Compute Node가 병렬로 연결되어 돌아가며, 이 전체가 하나의 거대한 분산 컴퓨팅 시스템으로 작동하게 된다.
대장급은 어떻게 생겼어? - TO86-SD1-AA05
본 포스트에선, 다음과 같은 질문에 대한 답이 될 수 있는 SOTA 서버를 하나 소개하는게 목적이다.
현 AI 시대에 걸맞는 Compute Node는 보통 어떻게 생겨먹었어?
이번 OCP Global Summit 2025에서 GIGABYTE가 공개한 TO86-SD1-AA05는 이러한 질문에 대한 아주 대표적인 예시가 될 수 있다.

약 8U 정도 되는 거대한 몸체를 보라..!

주요 스펙
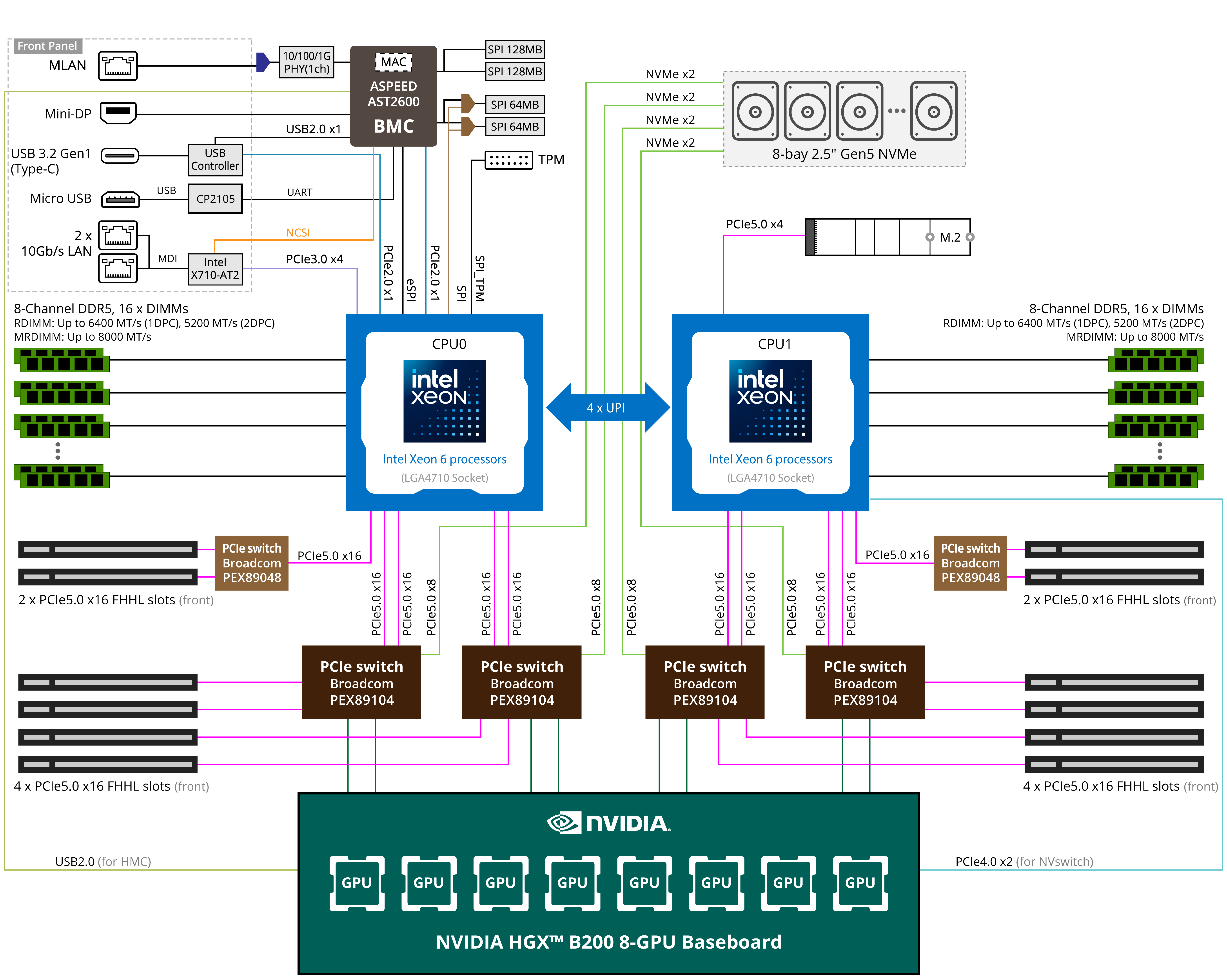
- CPU 듀얼 Intel Xeon 6 (최대 288 E-cores 또는 128 P-cores)
- GPU NVIDIA HGX B200 플랫폼 (8개 Blackwell GPU 탑재)
- GPU 간 연결 1.8 TB/s NVLink + NVSwitch
- 메모리 8채널 DDR5 RDIMM / MRDIMM, 최대 32 DIMM 슬롯
- 스토리지 8 × 2.5" NVMe Gen5 핫스왑 베이 + Gen5 4레인 M.2 슬롯 하나
- 확장 슬롯 12 × FHHL PCIe Gen5 x16
- 네트워크 2 × 10 GbE (Intel X710), BlueField-3 DPU 및 ConnectX-7 NIC 호환
- 전원 설계 48–54 V DC Bus Bar (OCP ORv3 표준)
- 랙 단위로 수랭 / 공랭 혼합 냉각 지원
- 크기 8OU (OCP Open Rack V3 기반 GPU 서버)

섀시 안에 큼직하게 NVIDIA HGX B200 플랫폼을 품고 있는게 상당히 인상적이다.
Intel Xeon 6 CPU가 들어가 있는데, 참고로 이 세대는 CXL 2.0 지원을 지원한다. PCIe 확장 슬롯에 CXL 메모리를 꼽으면 (아마도?) 바로 쓸 수 있지 않을까 싶다.
올해부터 슬슬 CXL-Ready한 상용 서버들이 등장하는거 같은데, 국내 메모리 기업들도 이러한 추세에 시간적으로 잘 Align해서 제품 양산까지 갔으면 좋겠는데, 특별히 아직 소식이 없는게 조금 아쉬운 면이다.
물론 이미 1-2년 전부터 CMM-D처럼 연구용으로 판매하는건 종종 있긴 한데, 고 녀석들은 사실 외부 컨트롤러 업체에 설계를 맡겨 간단히 급하게 만든 수준이라 아직 상용-Ready는 아닌거 같다.,
여기서 MRDIMM이란 모듈이 언급되는데, 이는 차세대 DDR5 모듈로, 기존 DIMM보다 2배 가까운 대역폭을 제공하는게 특징이다. 요즘 하이엔드 서버에선 자주 보이는듯?함.
그래서,, 얼마야?
요즘 Superpod이란 표현을 종종 쓰던데, 이런 서버, Compute Node가 진짜 그런 워딩에 적합한거 같다.
암튼, 본 글을 통해 하고 싶었던 말은, 요즘 AI향 데이터센터의 Compute Node라 함은, 이 정도 등치를 가진 녀석이란거다. 모든 연산이 이 곳에서 이뤄지고, 모델의 학습과 추론이 여기서 터진다.
우리가 흔히 연구 회의나 논문 등에서 “Compute Node 하나 더 추가함”이라고 말하지만, 현 시대에는 그 한 대 안에 수십 개의 CPU 코어, 수천 개의 GPU 코어, TB급 메모리/스토리지, 그리고 이젠 심지어 CXL까지, 뭐 별에별 하드웨어는 다 들어가고, 추가로 수냉까지 들어가게 된다.
그러면 우리는 결국 이런 질문으로 귀결될 수 밖에 없을 것이다..
그래서,, 얼마야?
여기서 "얼마"라는건 단순히 저런 머신과 구성 컴포넌트 (e.g., SSD, NIC, Switch ...)를 구매하는 '가격'만을 의미하는게 아니다. 저거 돌리려면 도대체 전력이 얼마나 들까? 저거 식히려면 도대체 전력이 얼마나 들까? 쟤가 차지하는 공간은 도대체 얼마나 될까? 이런 요소들이 다 포함되는거다.
장비만 놓고 보면, 셋업을 어떻게 하느냐에 따라 가격이 천차만별일텐데, 여기를 보면, Dell PowerEdge XE8640 (CPU 64코어 + 4× NVIDIA HGX H100) 기반으로 셋업할 때를 가정하면 대충 최소 한화 2억 정도 추산되는거 같다. 그리고 부수 장비를 어떻게 꾸리느냐에 따라 이마저도 훨씬 더 올라갈 수 있을 것이다.
Cost-Efficiency를 향해
흔히 TCO란 표현을 많이 쓰는데, AI 시대에 접어들면서 요즘 AI향 데이터센터를 구축한다는 소식이 국내외에 자주 등장한다. 그런 센터들엔 결국 저런 서버들이 여럿 들어가게 될텐데, 그러면 자연스레 도대체 돈이 얼마나 들지, TCO를 감당할 수 있을런지 걱정이 들게 된다.
또한, 한편으로는 최대한 현재 가용 가능한 리소스를 어떻게 더 효율적으로 사용할 수 있을지 고민하게 된다. 이런 방향에서 최근 SOSP'25에 발표된 논문인 Aegaeon: Effective GPU Pooling for Concurrent LLM Serving on the Market은 상당한 시사점을 준다. 이 논문의 핵심 Claim을 간단히 요약하면 "Alibaba Cloud says it cut Nvidia AI GPU use by 82% with new pooling system— up to 9x increase in output lets 213 GPUs perform like 1,192"인데, GPU Access를 Token-Level로 가상화하고, Work을 잘개 쪼개서 Pool을 매시간 바쁘게 활용하는걸 Feature하는 연구이다.
Hugging Face와 같은 모델 마켓에 있는 수많은 LLM의 접근 패턴을 보면 결국 Long-Tail 경향성을 갖고 있는데, 반면 Alibaba와 같은 클라우드 입장에선 고객들이 GPU 인스턴스를 각 모델마다 따로따로 예약하고는 idle하게 방치하고 있는 꼴이 되는 것이다. 약 18% 가량의 GPU가 전체 요청의 1%만 처리하는 수준이라고 한다. 우리가 본 글에서 확인한, 저 비싼 Compute Node를 놀리고 있는 모양새인 것이다.
재밌는건, 인기 모델들은 오히려 순간적인 Traffic Burst가 발생하는데, 오히려 이럴땐 인스턴스가 제대로 대응하지 못하는 패턴도 공존한다고 한다. 즉, 결론적으로 리소스를 많이 가져야할 애들은 그러지 못하고 있고, 대부분의 애들은 Over-provision한 상태인 것이다.
기존에는 이를 Multiplexing이나 Auto-scaling으로 대응하곤 했는데, 전자는 GPU VRAM이 기본적으로 한계가 있다보니 2-3개 모델 수준밖에 안되었고, 후자는 Request-Level로 스케일링이 되어 마찬가지로 Blocking 상태가 긴 문제가 있다고 한다.
본 논문에선 이를 Token-Level로 모델을 전환하고 Preemption하도록 스케쥴링 기법을 새롭게 도입한 것이다. 실험 결과, GPU당 최대 7개 모델까지 공유가 되었고, 최소 2배 이상의 수용률이 나온다고 한다. 그 다음, 실제로 Alibaba Cloud에서 베타 운용도 해봤다는데, 82%가량 GPU를 덜 써도 기존과 같은 서비스 제공이 가능했다고 한다.
이런 흐름을 보면, 결국 서비스 Provider들은 수요에 맞춰 끊임 없이 스케일링할 순 없는 노릇이니 이런 Cost 효율화 방향의 연구에 더 집중할 수 밖에 없는 거 같다. 당연한 흐름인거 같고, 연구자들은 이런 쪽으로 전문성을 파보면 좋지 않을까.
반대로, 장비를 파는 사람들은 이런 Cost-Efficiency향 니즈에 소극적으로 대응해야할지, 아니면 오히려 적극적으로 대응해서 시장 파이를 빠르게 확보하는게 중요할지, 이런 부분을 잘 고민해야할 것이고..
Cost-Efficiency really matters!
본 글에 담긴 Claim격의 서술은 모두 제 개인의 의견일 뿐이며 아무런 대표성을 가지지 않습니다.
