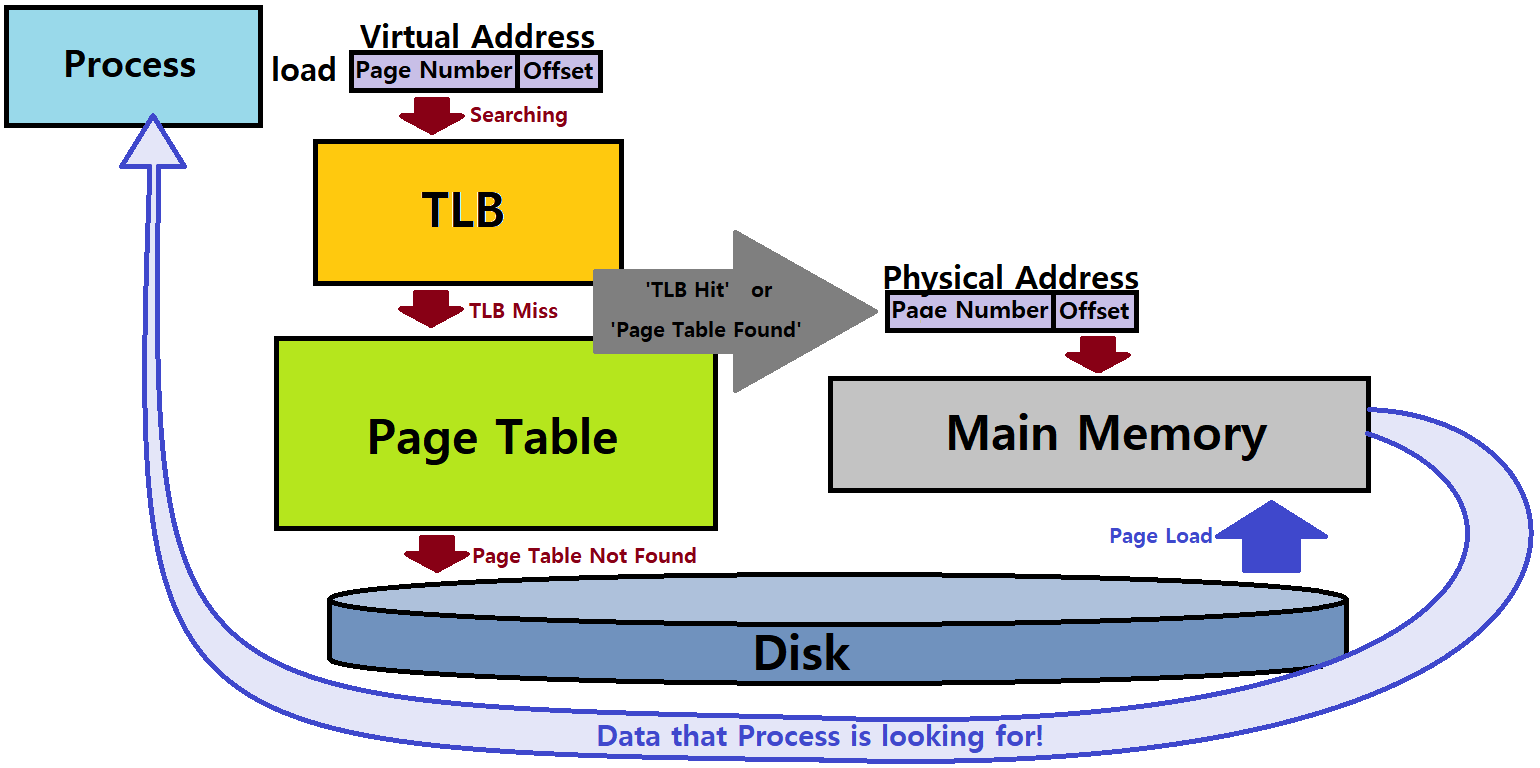
이제 대망의 Paging 기법에 대해 알아보자. Paging은 지금까지 학습한 Process Loading Mechanism의 끝판왕이며, 현대 OS에서 실제로 사용하는 상용 기술이자 원리이다. 열심히 공부해보도록 하자.
Introduction
Recap
Paging은 사실 우리에게 어느 정도 익숙한 개념이다. 그간 Computer Science를 공부하며 자주 들어봤을 개념이며, SP나 OS 초반 Chapter에서 몇 차례 간단히 알아본 바 있기 때문이다. 우리가 알고 있는 내용을 정리해보면 다음과 같다.
-
Paging은 Process Address Space를 Fixed-Size의 Page라는 단위로 나눈다. ★
- Segmentation에선 Segment라는 가변 사이즈의 Logical Unit으로 나누었던 것과 대조적!
-
Physical Memory도 고정 크기의 Page Frame, 약칭 Frame으로 나뉜다. ★
- Page와 Frame의 Size는 일반적으로 동일하게 설계하며, Page의 개수가 Frame의 개수보다 많거나 같은 경우가 많다. (Disk에도 Page를 둘 수 있기 때문)
-
Process마다 Page Table을 가지며, Page Table을 통해 Virtual Address를 Physical Address로 변환한다. ★
-
Logical Address는 Page Number와 Offset으로 구성된다.
-
Physical Address는 Page Frame Number와 Offset으로 구성된다.
-
일반적으로 Physical Memory의 Frame들 중, 초반 Frame들은 OS를 위해 Reserve한다. ★
-
Paging의 장점
-
Flexibility : Address Space에 대한 Abstraction, 즉, Memory Virtualization을 효과적으로 보조한다. ★★
-
Simplicity : Free Space 관리가 단순하다. Free List의 유지가 간단하다. 그냥 Page 단위로 처리하면 되기 때문! ★★
- Segmentation에선 Segment마다 일일이 따져봐야했음.
-
~> 허나, 이러한 Paging을 구현하기 위해, 각 Process마다 Page Table을 두어야 한다는 메모리적 부담이 생긴다. ★
~~> 이에 대한 처리를 어떻게 하는지 앞으로 알아볼 것이다!
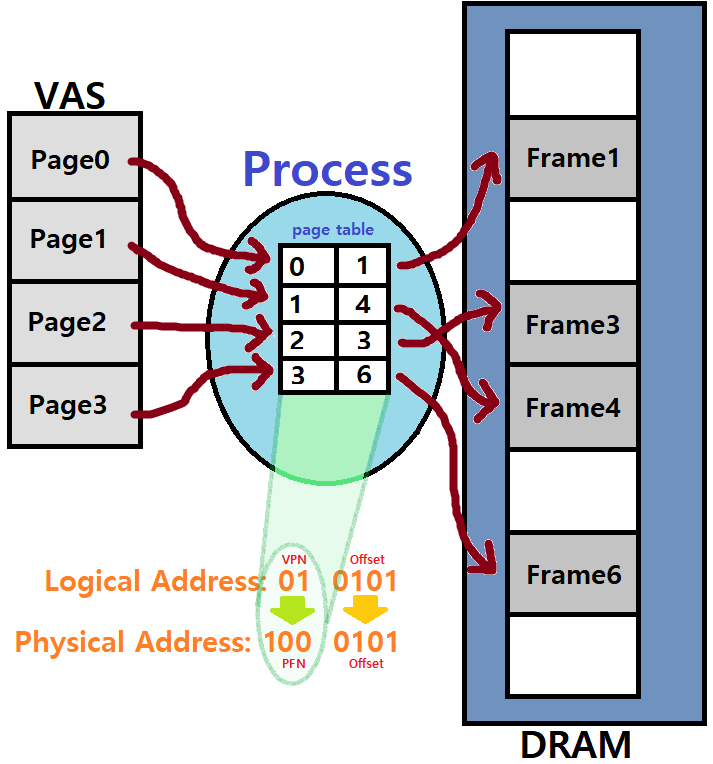
ex) 간단한 예제를 들어보자. 만약, VAS가 64Bytes이고, Physical Memory가 128Bytes인 조그만 컴퓨터가 있다고 하자.
-
Page와 Frame이 16Bytes 크기이면, VAS에는 4개의 Page가, Physical에는 8개의 Frame이 있을 것이다. (간단한 산수)
-
이때, Logical Address는 총 64Bytes 공간을 표현해야한다.
-
64 = 2^6
- 총 6Bits로 구성된다.
-
마찬가지 논리로 Physical Address는 7Bits로 구성될 것이다.
-
또한, 같은 논리로 Page와 Frame의 크기는 16Bytes이므로, 4Bits로 표현할 수 있다.
-
-
따라서, Logical Address는 "Page Number + Offset"으로 구성되므로,
-
'ㅁㅁ/ㅁㅁㅁㅁ'으로 묘사할 수 있다.
-
앞으로, Page Number를 VPN(Virtual Page Number)라 부르자.
- 반대로, Frame Number는 PFN(Page Frame Number)라 부른다.
-
-
Physical Address는 'ㅁㅁㅁ/ㅁㅁㅁㅁ'이 될 것이다. 앞이 PFN, 뒤가 Offset!
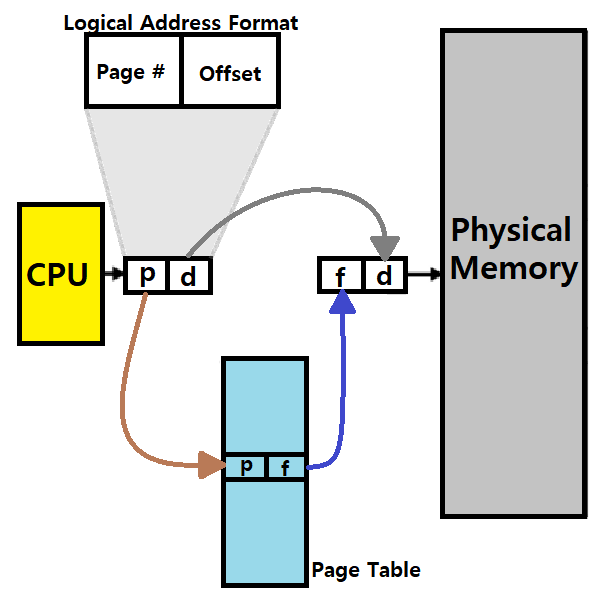
~> Logical Address가 Physical Address로 Translation되는 과정을 간단히 확인하자. 어렵지 않게 이해할 수 있을 것이다.
Page Table
이러한 Paging 기법의 구현 시 다음의 고민이 필요하다.
"만약, 예를 들어, 32Bits Address Space를 가진 Computer가, 4KB 크기의 Page를 가진다고 하면, 4K = 2^12이므로 하위 12Bits는 Offset을, 상위 20Bits는 VPN을 가리킬 것이다."
"이는, Page가 2^20개 있음을 의미한다."
"이때, Page Table에서 각 Entry가 4Bytes라 하면, 2^20 x 4 = 4MB의 크기가 Page Table을 위해 존재해야 한다."
"그런데, 이 Page Table은 Process마다 존재한다. 모든 Process가 각각 4MB의 Page Table을 가져야 한다면, 상당한 메모리적 부담이 된다."
Page Table을 어디다 두어야 할까?
결국, Physical Memory에 두는 수밖에 없을 것이다. ★★★
이를 위해, 각 Process마다 Page Table이 Memory에 저장된 위치 정보를 알아야할 것이고, 이를 PTBR(Page Table Base Register)라는 곳에 두곤 한다. ★
그런데, Physical Memory에 두면 Memory Accessing마다 Page Table을 위한 Memory Accessing이 수반되므로 결과적으로 Access를 두 번 하는 꼴이 된다. ★★★
너무 느릴텐데.. 어떡할까...
~> 앞으로 우리는 이 고민에 대한 답을 찾아갈 것이다.
=> Page Table을 어디다 둘지, 그리고 어떻게 취급해야할지!
한편, 사실 Page Table이 실제 구현 시에 위와 같이 간단한 형태로 존재하는 것은 아니다. 주로 Linear Page Table, Array의 형태로 구현하는 것은 맞지만, 단순히 VPN에 Mapping PFN 정보만 담겨 있는 것은 아니고, 아래와 같은 추가적인 Entry들도 존재한다.
- Entries in Page Table
- Valid Bit : Address Translation이 Valid한지를 나타낸다.
- Protection Bit : Page가 Read/Write될 수 있는지, 또는 Execution될 수 있는지 등을 나타낸다.
- Present Bit : Page가 Physical Memory에 있는지, 아니면 Disk에 있는지를 나타낸다.
- Dirty Bit : Page가 Memory에 올라온 이후에 수정된 적이 있는지를 나타낸다.
- 수정된 Page이면 최대한 Disk로 다시 돌려놓지 않고, 'Dirty하지 않은(수정되지 않은)' Page들은 Memory에서 우선적으로 축출한다. 왜? 효율적이기 때문!
- 이 과정에서 Dirty Bit가 사용되는 것이다.
- 수정된 Page이면 최대한 Disk로 다시 돌려놓지 않고, 'Dirty하지 않은(수정되지 않은)' Page들은 Memory에서 우선적으로 축출한다. 왜? 효율적이기 때문!
- Reference(Accessed) Bit : Page가 Access되었는지를 나타낸다.
~> Page Table에는 VPNtoPFN 정보 뿐만 아니라 위와 같이 다양한 정보를 나타내는 Bit들이 들어있다. ★
~~> 아래는 Intel x86계열 Architecture의 Page Table Entry 모습이다.

아래는 Paging 기법에서 Memory Access가 어떻게 진행되는지를 보여주는 C 코드이다.
/* Logical Address에서 VPN만 추출한다. */
VPN = (vaddr & VPN_MASK) >> SHIFT;
/* 해당하는 Page Table Entry, PTE 뽑아낸다. */
PTE = AccessMemory(PTBR + (VPN * sizeof(PTE)));
/* 예외를 확인한다. */
if (PTE.Valid == false) Exception(SEGMENTATION_FAULT);
else if (CanAccess(PTE.ProtectBits) == false) Exception(PROTECTION_FAULT);
else
{ /* Fetch하자! */
offset = vaddr & OFFSET_MASK;
paddr = (PTE.PFN << PFN_SHIFT) | offset;
Register = AccessMemory(paddr);
}~> 간단히 이해할 수 있을 것이다.
Faster Translation by TLBs
자, 이제 본격적으로 Paging에 대해 알아보자. 바로 위의 파트에서 우리는 Page Table의 크기가 크기 때문에 Physical Memory에 두어야 한다는 것, 하지만 그로 인해 Page Table Access 시의 Overhead가 늘어난다는 것을 확인했다. Logical Address를 Physical Address로 변환하기 위해 Page Table을 도입했는데, 그 Page Table 자체가 Physical Memory에 존재하기 때문에 두 번의 Memory Access가 발생하는 것이다.
"그렇다면, Memory Access를 조금 더 빠르게 하면 되지 않을까?"
~> Faster Translation을 도모하자!
~~> 무엇을 통해서? HW의 도움을 받아보자.
==> MMU HW 안에 Page Table Access 시의 Contents를 Caching해보자! ★★★
Cache가 도입됐던 이유 : Memory Access가 느리니까 더 빠른 Memory Access를 위해 Cache를 두어 속도 향상 도모!
이 원리를 Translation에도 똑같이 적용해보자는 것! ★
What is TLBs?
-
Page Table은 'Per-Process Data Structure', 즉, 모든 Process가 각각 가진 자료구조이다.
-
Page Table의 크기는 커다랗다. 그래서 Main Memory에 두어야 한다.
-
그런데, Physical Memory에 두면, 매번 Data/Instruction Access 시 두 번의 Memory Access가 발생한다.
- 한 번은 Page Table을 위해 한 번은 Data/Instruction을 위해! ★
-
이는 성능 저하 요소이다.
-
이러한 'Double Memory Access' 문제는 MMU(Memory Management Unit) HW 내에 'Associative Memory' 또는 'TLBs(Translation Look-aside Buffers)'라 불리는 HW Cache를 두어 해결할 수 있다. ★
Page Table에 대한 Lookup 과정을 조금 더 빠르게 해보자는 것!
-
일반적인 TLB는 32, 64, 또는 128개의 Entry를 가진다.
-
상당히 작은 공간이다. Page Table이나 Main Memory 크기만큼 크지 않다.
- 이는 곧 Replacement의 필요성을 의미하는데, 이는 후술한다.
-
이러한 TLB는 일반적으로 'Full Associative Method'로 운용된다.
- Page Table의 정보, 즉, Translation 정보가 TLB 아무 위치나 다 위치할 수 있다는 것이다. (Full Associative Method) ★
- 일반적으로 Computer Architecture 수업에서 이 개념을 들어볼 수 있다.
- Page Table의 정보, 즉, Translation 정보가 TLB 아무 위치나 다 위치할 수 있다는 것이다. (Full Associative Method) ★
-
각 Entry에는 Translation 정보가 들어있다. 즉, VPNtoPFN 정보가 들어있는 것이다. ★
- 거기에, 추가적으로 Valid Bits, Protection Bits, Address-Space Identifier (ASID), Dirty Bits 등의 정보가 들어있다. ★
- ASID(Address-Space Identifier) : Process마다 구분짓는 ID로, 현재 다루는 Page Table이 어떤 Process의 Page Table인지를 알려준다. (후술)
- 거기에, 추가적으로 Valid Bits, Protection Bits, Address-Space Identifier (ASID), Dirty Bits 등의 정보가 들어있다. ★
-

~> Process가 특정 Page에 접근하기 위해 최초로 Page Table에 Access할 때, 해당 Translation 정보를 TLB로 Cache하고, 그 다음 Access부턴 HW TLB에서 바로 Data를 가져오겠다는 것임. (Cache의 논리 그대로!) ★★★
How it works?
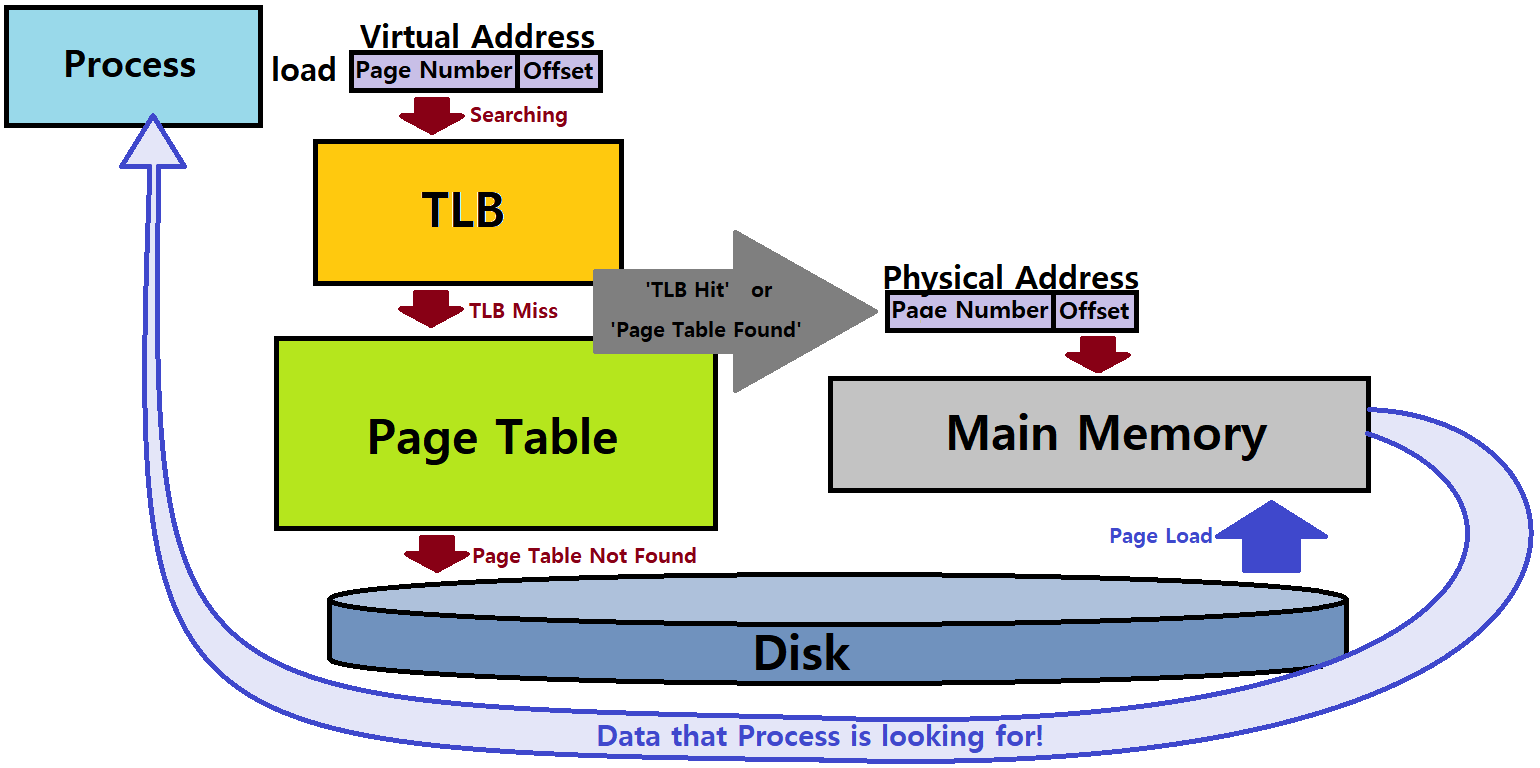
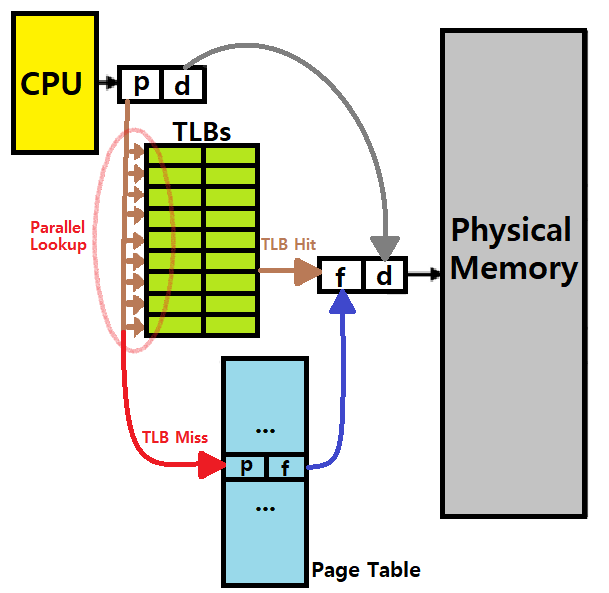
-
위 그림을 보자. TLB를 도입한 Paging의 기본적인 동작 원리를 개괄적으로 파악할 수 있을 것이다.
-
p는 VPN이다. VPN에 대해서 TLBs를 먼저 Parallel Lookup으로 찾아보는 것이다. MMU HW 안에서 말이다. 언제? Page Table을 찾아보기 전에! ★★
- Linear Search는 오래 걸리고, Hash의 사용은 추가적인 메모리의 도입을 의미한다. 즉, 이 Search를 최대한 효율적으로 하기 위해 HW로 애초에 미리 설계해버린 'Parallel Lookup'이 투입되는 것이다. ★
-
TLB의 Entry는 VPNtoPFN Translation 정보가 들어 있다.
-
내가 원하는 Translation 정보가 발견되면 TLB Hit, 발견되지 않으면 TLB Miss이다.
-
Hit이면 그곳에서 그대로 Data(Translation 정보)를 꺼내, Physical Address를 만들어서 Process가 원하는 정보가 있는 위치(paddr)로 이동해 Data를 접근해 사용한다. ★★
- Memory Access 한 번! (실제 데이터 접근만)
-
Miss이면 (Main Memory 안에 있는) Page Table로 넘어가 Data(Translation 정보)를 꺼내, Physical Address를 만들어서 Process가 원하는 정보가 있는 위치(paddr)로 이동해 Data를 접근해 사용한다. ★
- Memory Access 두 번! (Page Table 접근과 실제 데이터 접근이 함께!)
-
-
~> 당연히, TLB Hit이면 접근 속도가 굉장히 빨라진다. ★
여담) TLBs의 일부 Entry는 항상 Fast Access를 제공하기 위해 Reserve(Wire-Down)되어 있다. 주로, 핵심 Kernel Code 등이 이러하다. ★
How good it is?
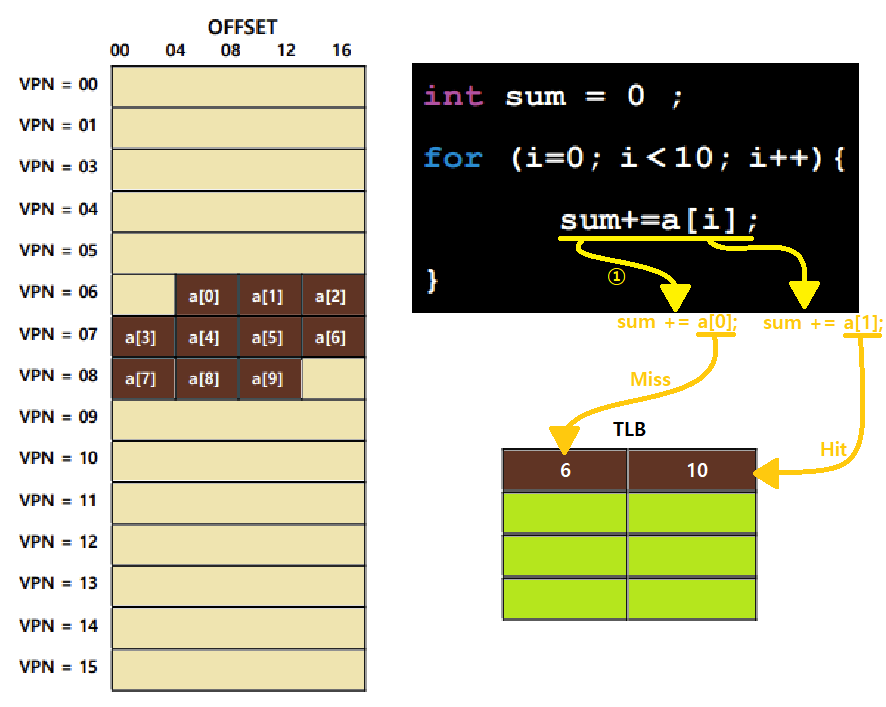
TLB 개념을 도입함으로써 Paging이 얼마나 빨라지는지 확인해보자. 아래의 예시를 보자.

-
좌측 그림은 한 Process의 Virtual Memory를 나타내고, 하나의 기다란 막대기가 하나의 Page를 의미한다. Offset을 보아하니, 한 Page의 크기가 16Bytes임을 알 수 있다.
- Page의 개수는 16개이다.
- 따라서, Offset은 4Bits, VPN도 4Bits로 표현할 수 있는 System이다.
- Page의 개수는 16개이다.
-
이러한 System에서 우측 코드와 같은 Program을 돌린다. 이때, 6번 Page는 10번 Frame에, 7번 Page는 20번 Frame에, 8번 Page는 30번 Frame에 맵핑되어 있다고 가정하자.
-
이제, Program을 돌리자. a[0]를 먼저 Access한다. 최초 상황이니, TLB Miss가 일어날 것이다.
-
Page Table의 Translation 정보를 가져와 TLB에 올려놓을 것이다.
- 즉, '6 | 10'이란 Entry가 TLB에 생길 것이다.
-
이어, a[1], a[2]를 차례로 접근하는데, 이들은 a[0]와 같은 Page(Frame)이므로 두 번다 TLB Hit가 될 것이다.
-
같은 논리로, a[3]은 TLB Miss일 것이고, a[4], a[5], a[6]은 TLB Hit일 것이다.
-
같은 논리로, a[7]은 TLB Miss일 것이고, a[8], a[9]는 TLB Hit일 것이다.
-
~> 결과적으로, 총 10번의 Memory Access 중 3번의 Miss, 7번의 Hit가 일어났다. TLB Hit Rate는 70%라 할 수 있겠다. ★
TLB는 Cache로서, Spatial Locality를 이용해 좋은 성능을 발휘한다. ★★★
※ Locality 복습
-> Temporal Locality : 최근에 Access한 Data/Instruction 정보는 근 시간 내에 다시 Access할 확률이 높다.
-> Spatial Locality : Program이 특정 번지 Memory를 Access하면, 이어 그 주변의 Memory를 Access할 확률이 높다.
TLB(Cache)는 이 두 Locality를 모두 고려해 도입된 개념이다. ★
TLB Miss Mechanisms
Memory Access 시 VPNtoPFN Translation 정보가 TLB 안에 있는지를 확인한다. 이때, TLB에서 Miss가 나면 Page Table에서 TLB로 Translation 정보를 복사해놓는 작업이 필요할 것이다. 이 과정은 다음과 같은 두 방법론으로 구현할 수 있다.
-
(1) Hardware-Managed TLB
-
HW에서 TLB Miss 시의 Translation Fetch 작업을 처리한다.
-
Intel CISC 계열에서 주로 사용하는 방식이다.
-
TLB Miss가 일어나면 HW에서, 해당하는 Page Table의 위치를 찾고, 거기서 VPNtoPFN Translation 정보를 알아내서 가져와 TLB에 맵핑한다. 그러한 루틴이 HW에 마련되어 있는 것 ★
- 이를 위해선 HW가 Page Table의 Memory 내 위치, 그리고 Decoding 시의 Format을 알아야 한다. ★★
- Translation 정보를 Page Table에서 가져와 TLB에 Update한 다음, 그 Memory Access Instruction을 다시 수행한다. ★
- TLB Hit!
- 마치 OS의 Fault Handling처럼 동작하는 것이다.
- Translation 정보를 Page Table에서 가져와 TLB에 Update한 다음, 그 Memory Access Instruction을 다시 수행한다. ★
- 이를 위해선 HW가 Page Table의 Memory 내 위치, 그리고 Decoding 시의 Format을 알아야 한다. ★★
-
단점은 아무래도 Page Table Entry의 Format에 따라 HW가 설계되기 때문에 Format이 달라질 때마다 HW도 재-설계해야한다는 것이다.
- Page Table의 위치를 알아야한다는 부담도 있다.
- Intel에선 CR3 Register에 이 Page Table 위치를 저장한다. ★
- Page Table의 위치를 알아야한다는 부담도 있다.
-
이 (1)번 방식을 Code로 나타내면 아래와 같다.
VPN = (vaddr & VPN_MASK) >> SHIFT; // Virtual Address에서 VPN 추출
Success = TLB_Lookup(&TlbEntry, VPN); // 해당 VPN으로 TLB에서 Parallel Lookup 수행!
/* TLB Hit */
if (Success == true) {
if (CanAccess(TlbEntry.ProtectBit) == true) {
Offset = vaddr & OFFSET_MASK; // offset 추출
paddr = (TlbEntry.PFN << SHIFT) | Offset; // Physical Address 도출
AccessMemory(paddr); // 명령 수행
}
else RaiseException(PROTECTION_ERROR); // Protection Bit가 False이면
}
/* TLB Miss */
else {
PTEaddr = PTBR + (VPN * sizeof(PTE)); // 메모리 내 Page Table 탐색
PTE = AccessMemory(PTEaddr); // 추가적인 Memory Access (오버헤드)
if (PTE.Valid == false)
RaiseException(SEGMENTATION FAULT);
else {
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits); // TLB에 Update
RetryInstruction(); // Access 재시도
}
}~> Virtual Address에서 뽑아낸 VPN을 가지고 TLB Parallel Lookup을 수행하고 있다.
~> TLB Miss 시 PTBR(Page Table Base Register, 앞서 말한 CR3와 같은 것)에다 'VPN x EntrySize'를 더해 '내가 원하는 Page Table Entry'의 위치를 만들고, 해당 위치에서 Translation 정보를 뽑아내고 있다. ★★★
~> TLB Update 후 TLB Miss를 일으킨 Instruction을 다시 수행하고 있음을 기억하자. ★
- (2) Software-Managed TLB
- TLB Miss가 일어나면 HW가 OS에게 Exception(Trap)을 발생시켜 OS가 Handler를 통해 Miss 처리를 하도록 하는 방식이다. ★
- RISC, MIPS 계열에서 이 방식을 쓴다.
이 (2)번 방식을 Code로 나타내면 아래와 같다.
VPN = (vaddr & VPN_MASK) >> SHIFT;
Success = TLB_Lookup(&TlbEntry, VPN);
/* TLB Hit */
if (Success == true) {
if (CanAccess(TlbEntry.ProtectBits) == true) {
Offset = vaddr & OFFSET_MASK;
paddr = (TlbEntry.PFN << SHIFT) | Offset;
Register = AccessMemory(paddr);
}
else RaiseException(PROTECTION_FAULT);
}
/* TLB Miss */
else {
/* HW가 OS에게 Trap 예외를 일으켜, OS가 TLB Miss에 대한
Handling을 직접 수행한다. SW-Managed TLB Method! */
RaiseException(TLB_MISS);
}~> 우리는 1번, 앞으로 HW-Managed TLB 방식을 가정하고 학습할 것!
Issues about TLBs
이제 우리는 Paging, TLBs에 대한 개념을 이해할 수 있다. 이제는, 이러한 TLB의 구현 시 고려해야할 Issue들에 대해 알아보자.
Distinguish Processes
아래의 그림을 보자. ProcessA와 ProcessB가 돌고 있다. ProcessA가 돌다가 ProcessB로 Context Switch한다. 이때, 만약 두 Process의 특정 명령 접근 Page가 VPN이 동일하다고 하면, 여기서 TLB는 두 Process(또는 Page Table)을 어떻게 구분할 것인가?
"Cannot distinguish which entry is from which process!"
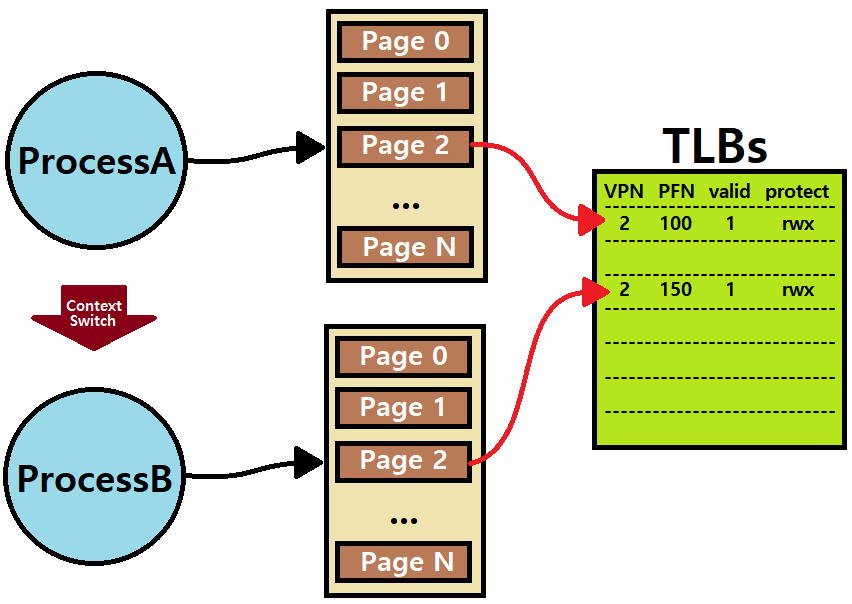
Solution: 'Address Space Identifier (ASID)'를 도입한다.
TLB Entry의 특정 Field에 ASID라는 Bits를 두어 Process를 구분하는 것이다. ★
- 일반적으로 ASID에는 8개의 Bits를 부여한다. 즉, 2^8 = 256개의 Process를 구분할 수 있는 것이다.
- 너무 적지 않은가?
- OS는 ASID를 Dynamic하게 배정한다. 즉, 쉽게 말해 현재 수행 중인 Process에게 매번 다른 번호를 동적으로 부여한다는 것이다. ★
- 그래서, 특정 시간에 동시에 수행되는 Process가 256개 이상일리는 만무하므로 8개의 비트이면 Process를 구분하기에 충분하다. ★
- OS는 ASID를 Dynamic하게 배정한다. 즉, 쉽게 말해 현재 수행 중인 Process에게 매번 다른 번호를 동적으로 부여한다는 것이다. ★
- 너무 적지 않은가?

Page Sharing
두 Process P1, P2가 있다고 하자. 각 Process에 대해 Page Table이 하나씩 있는데, 이때, P1과 P2가 공통의 Physical Memory 공간을 Share하는 상황이 있을 수 있다.
-
즉, 서로 다른 Process의 Memory Access가 같은 Frame을 가리키는 것이다.
-
VPNtoPFN Translation 정보에서 PFN 값이 같은 상황 ★
-
Process끼리 메모리를 공유하고 있는 상황!
-
Why some pages(frames) are shared?
Cuz, sharing of pages can reduce the number of physical pages in use. ★
아래 그림을 보자.
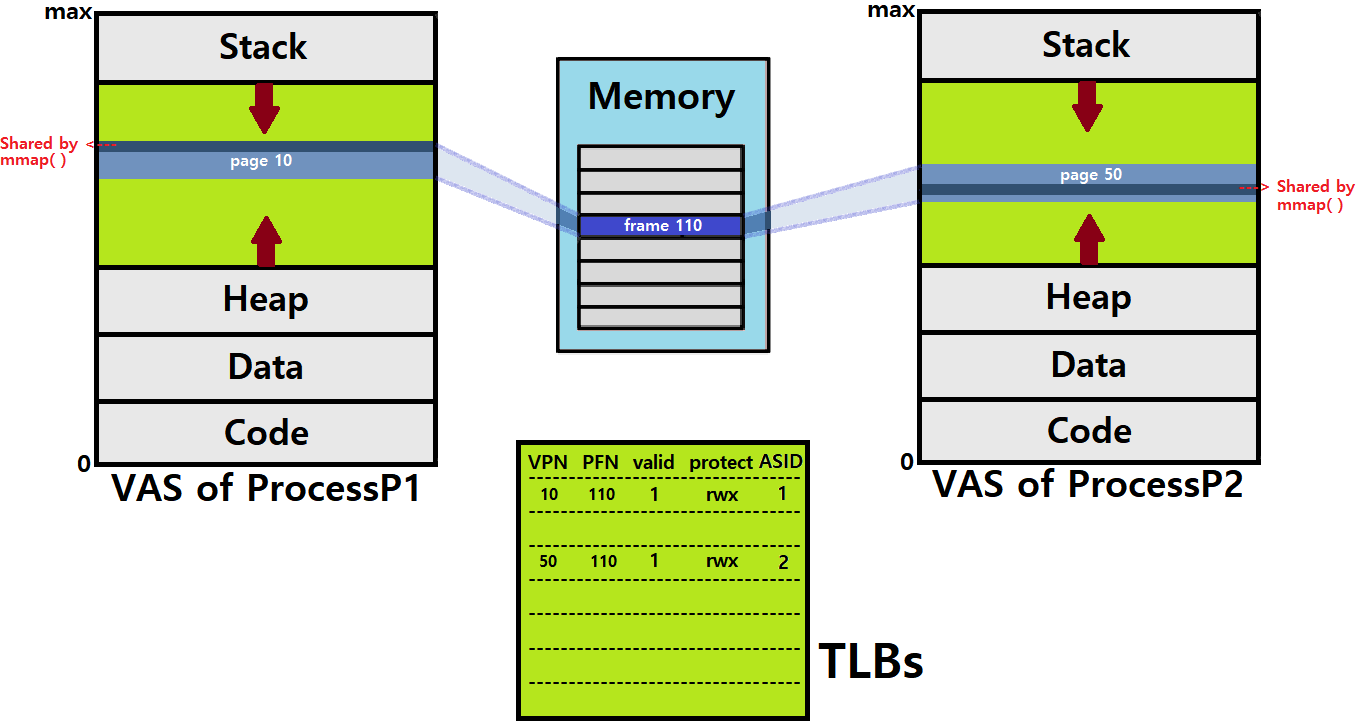
-
우리는 과거 mmap System Call을 통해 Physical Memory의 특정 공간을 Process VAS에 맵핑할 수 있다고 했다.
- 이를 통해 복수의 Process가 Memory Sharing을 할 수 있다고 했다.
- 그러한 상황은 위와 같은 꼴을 지닐 것이다.
- 이를 통해 복수의 Process가 Memory Sharing을 할 수 있다고 했다.
-
한편, 두 Process가 똑같은 Library를 참조하며 동작한다고 하면, Library 코드를 각 VAS에 따로 따로 Load하면 좋지 않다. 메모리 낭비이다.
- 이때, Shared Memory로서, 위 mmap 예시처럼 Physical Memory를 공유해 사용하면 좀 더 효율적일 것이다.
-
또 다른 상황을 생각해보자. 어떤 Process가 fork한다고 하자. 해당 Process의 Binary Image가 Copy되어 Child가 생성될 것이다.
-
만약, 이때 Child가 exec System Call을 호출해 다른 Program을 돌리게 되면, Image Copy 행위는 아무런 쓸모가 없어진다. ★
-
그렇다면, "이러한 Copy Overhead는 어떡해야하나요?"라는 의문이 들 것이다.
-
그런데, 사실, 이 Copy Overhead는 없다.
- Process fork 시, Copy는 바로 이뤄지지 않는다. 'Copy-on-write' 방식으로 이뤄지는데, 처음 Child가 생성될 때는 Page Table만 Copy된다. ★★★
- VAS를 모조리 Copy하지 않고, Page Table만 Copy한 후, Child에서 write 작업이 이뤄질때, 그 Write의 대상이 되는 Page만 기존과 다른 Frame에 맵핑한다. ★★★
- 즉, 나머지는 Page Sharing하는 것이다.
- VAS를 모조리 Copy하지 않고, Page Table만 Copy한 후, Child에서 write 작업이 이뤄질때, 그 Write의 대상이 되는 Page만 기존과 다른 Frame에 맵핑한다. ★★★
- Process fork 시, Copy는 바로 이뤄지지 않는다. 'Copy-on-write' 방식으로 이뤄지는데, 처음 Child가 생성될 때는 Page Table만 Copy된다. ★★★
-
지금까지 우리의 학습에선 이 Overhead를 모르고 있던 것!
-
-
아무튼, mmap을 통한 Shared Memory 상황, 같은 Library 참조 상황, fork 시의 Copied Image 상황에서 모두 Page Sharing이 일어난다.
이처럼, Page를 Sharing할 수 있다는 것을 기억하자. Process는 다른데 Page에 맵핑된 PFN이 같은 상황 ★★
참고로, 헷갈리지 말라. VPN은 당연히 같을 수 있다.
Replacement Policy
한편, TLB는 작다. 작은 공간이다. 128개 정도 Entry가 있다고 했다.
우리가 TLB에 새로운 Entry를 추가할 때, 만일 TLB가 꽉차 있다면 기존의 한 Entry를 Evict하고 새로운 것으로 Replace해야한다.
이때, 어떤 Entry를 Evict할 것인가?
TLB Miss Rate를 줄이는 방향으로, Hit Rate를 높이는 방향으로 뽑아내야 Performance가 높아질 것이다. ★
-
(1) LRU(Least Recently Used) Policy
- 가장 예전에 사용됐던 Entry를 Evict한다.
- Temporal Locality를 이용한다. ★
- Corner-Case가 존재한다. ★★
- 구현이 어렵다. (쉽게 생각해봐도, LRU인지 찾는것을 어떻게 할지 막막하다)
-
(2) Random Policy
- 그냥 랜덤하게 Evict한다.
- 구현이 쉽고, Corner-Case에서 동작이 좋다. ★
- Workload에 따라 성능이 좌우된다. ★
※ Corner-Case of LRU Policy : 만약, TLB의 Entry 개수가 n개인데, 특정 Program이 (n+1)개의 Page를 순차적으로 접근하는 행위를 반복한다고 해보자. 0 ~ n번의 Page가 TLB에 올라간다. (n+1)번 Page가 TLB에 맵핑될 때, 가장 LRU인 0번 Page가 Evict될 것이다.
자, 이번엔 다시 돌아와서 0번 Page를 Access해야하는데 TLB Miss가 날 것이다. 이번엔 1번이 LRU이니 1번이 Evict될 것인데, 그 다음 Access는 1번 Page이다.
~> 이처럼, 계속해서 TLB Miss가 날 것이다. LRU에는 이러한 Corner-Case가 존재한다. ★★★
~~> Random Policy에 의거해 Replace할 경우, 이러한 문제점을 피할 수 있겠다.
아래는 실제 MIPS System의 TLB Entry Format이다. 우리는 이제 Paging을 꽤 이해했다!

금일 포스팅은 여기까지이다. 다음 포스팅도 Paging에 관한 이야기다. 아직 갈 길이 멀다.
