* 본 글은 중국 cnblogs의 한 포스트를 한글로 번역한 글입니다. 따로 글 수정 없이 바로 번역했으며, 제가 중요하다고 생각하는 부분만 bold나 밑줄로 표기했습니다.
최근 DeepSeek이 자사의 파일 시스템인 Fire-Flyer File System (3FS)을 오픈소스로 공개하면서 다양한 업계의 주목을 다시 받고 있다. AI 비즈니스에서는 텍스트, 이미지, 영상 등 방대한 비정형 데이터를 처리해야 하며, 동시에 폭발적으로 증가하는 데이터 양에도 대응해야 한다. 따라서 분산 파일 시스템은 AI 학습을 위한 핵심 저장 기술로 자리잡고 있다.
이 글은 3FS의 구현 메커니즘을 심층적으로 분석하고, JuiceFS와의 비교를 통해 두 파일 시스템의 차이점과 각각의 적합한 활용 사례를 이해하는 데 도움을 주고자 한다. 아울러, 3FS에서 배울 만한 혁신적인 기술 포인트들도 함께 살펴본다.
아키텍쳐 비교
3FS
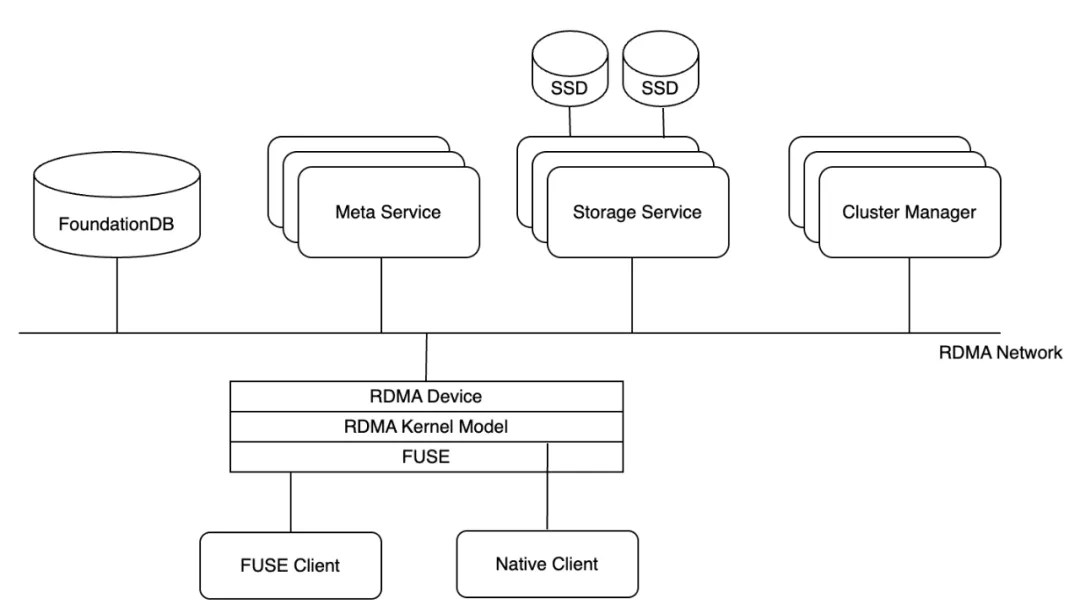
3FS (Fire-Flyer File System)는 AI 학습 및 추론 작업에 최적화된 고성능 분산 파일 시스템이다. 이 시스템은 고속 NVMe 저장장치와 RDMA 네트워크를 활용하여 공유 스토리지 계층을 제공한다. 3FS는 DeepSeek이 2025년 2월에 오픈소스로 공개하였다.
- 3FS는 주로 다음과 같은 모듈들로 구성되어 있다:
- 클러스터 관리자 (Cluster Manager)
- 메타데이터 서비스 (Metadata Service)
- 스토리지 서비스 (Storage Service)
- 클라이언트 (Client): FUSE 클라이언트, 네이티브 클라이언트
-
모든 모듈은 RDMA 네트워크를 통해 통신한다.
-
메타데이터 서비스와 스토리지 서비스는 클러스터 관리 서비스에 주기적으로 하트비트 (heartbeat) 신호를 전송하며, 클러스터 관리 서비스는 클러스터 멤버 변경을 처리하고 클러스터 구성 정보를 다른 서비스 및 클라이언트에 전달하는 역할을 담당한다.
-
시스템의 신뢰성을 높이고 단일 장애 지점을 방지하기 위해 클러스터 관리 서비스는 다중 노드로 구성되며, 이 중 하나가 마스터 노드로 선출된다.
- 마스터 노드에 장애가 발생하면, 다른 노드가 마스터로 승격된다.
- 클러스터 구성 정보는 보통 ZooKeeper나 etcd와 같은 신뢰성 있는 분산 서비스에 저장된다.
-
파일을 열거나 생성하는 등의 메타데이터 연산을 수행할 때, 해당 요청은 메타데이터 서비스로 전달되어 파일 시스템의 의미론을 구현한다.
-
메타데이터 서비스는 여러 개가 존재하며 상태를 저장하지 않는 (stateless) 구조이다. 이 서비스들은 직접적으로 메타데이터를 저장하지 않고, 트랜잭션을 지원하는 키-값 데이터베이스인 FoundationDB를 활용하여 메타데이터를 저장한다.
- 이에 따라 클라이언트는 어떤 메타데이터 서비스에 접속하든 유연하게 처리가 가능하며, 이 설계는 메타데이터 서비스의 독립성과 무상태성을 통해 시스템의 확장성과 안정성을 높인다.
-
각 스토리지 서비스는 여러 개의 로컬 SSD를 관리하며, 청크 (chunk) 저장 인터페이스를 제공한다. 스토리지 서비스는 CRAQ (Chain Replication with Apportioned Queries) 방식을 통해 강력한 일관성을 보장한다. 3FS에 저장되는 파일은 기본적으로 512KB 단위의 고정 크기 블록으로 분할되어 여러 SSD에 복제되며, 이를 통해 데이터 신뢰성과 접근 속도를 향상시킨다.
-
3FS 클라이언트는 두 가지 접근 방식을 제공한다: FUSE 클라이언트와 네이티브 클라이언트(Native Client).
- FUSE 클라이언트는 일반적인 POSIX 인터페이스를 지원하며 사용이 간편하다.
- 반면, 네이티브 클라이언트는 더 높은 성능을 제공하지만 클라이언트 API를 직접 호출해야 하므로 다소 침습적이다. 이에 대한 자세한 분석은 이후에 다룰 예정이다.
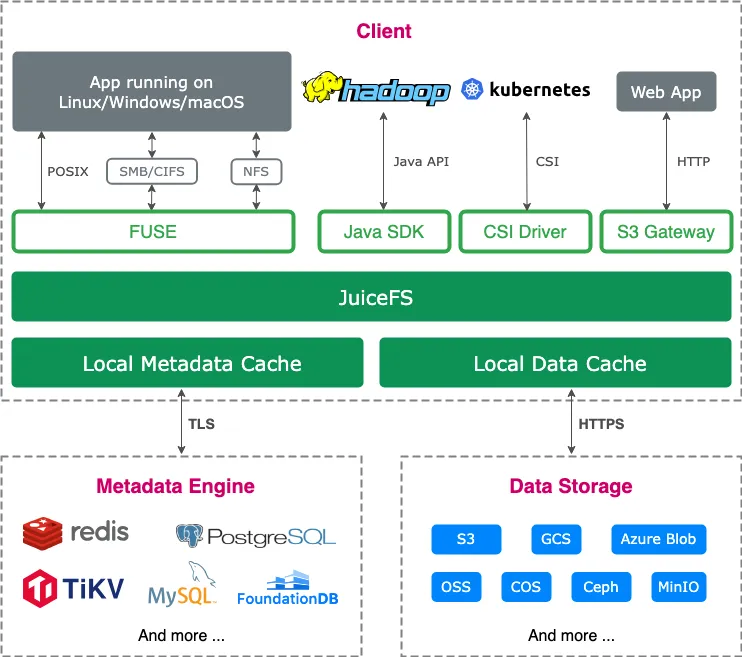
JuiceFS
JuiceFS는 데이터를 오브젝트 스토리지에 저장하는 클라우드 네이티브 분산 파일 시스템이다. 커뮤니티 버전은 다양한 메타데이터 서비스와 통합이 가능하며, 여러 활용 시나리오에 폭넓게 적용될 수 있다. 2021년에 GitHub에 오픈소스로 공개되었다. 엔터프라이즈 버전은 고성능 환경에 최적화되어 있으며, 생성형 AI, 자율주행, 퀀트 금융, 생명공학 등 대규모 AI 작업에 널리 사용되고 있다.
- JuiceFS 파일 시스템은 크게 다음 세 부분으로 구성된다:
- 메타데이터 엔진: 파일 시스템의 일반적인 메타데이터와 파일 데이터의 인덱스를 저장하는 역할을 한다.
- 데이터 저장소: 일반적으로 오브젝트 스토리지 서비스를 사용하며, 퍼블릭 클라우드 오브젝트 스토리지 또는 프라이빗 환경에 배포된 오브젝트 스토리지가 될 수 있다.
- JuiceFS 클라이언트: POSIX (FUSE), Hadoop SDK, CSI Driver, S3 Gateway 등 다양한 접근 방식을 제공한다.
아키텍쳐적 차이
모듈 구성 관점에서 보면 두 파일 시스템은 큰 차이를 보이지 않는다. 두 시스템 모두 메타데이터와 데이터의 분리 설계를 채택하고 있으며, 각 모듈의 기능도 유사하다.
다만, 3FS 및 JuiceFS 엔터프라이즈 에디션과 달리 JuiceFS 커뮤니티 에디션은 다양한 오픈소스 데이터베이스와의 호환성을 통해 메타데이터를 저장할 수 있으며, 모든 메타데이터 연산이 클라이언트 내부에 캡슐화되어 별도의 무상태 메타데이터 서비스를 운영할 필요가 없다.
(1) 스토리지 모듈
-
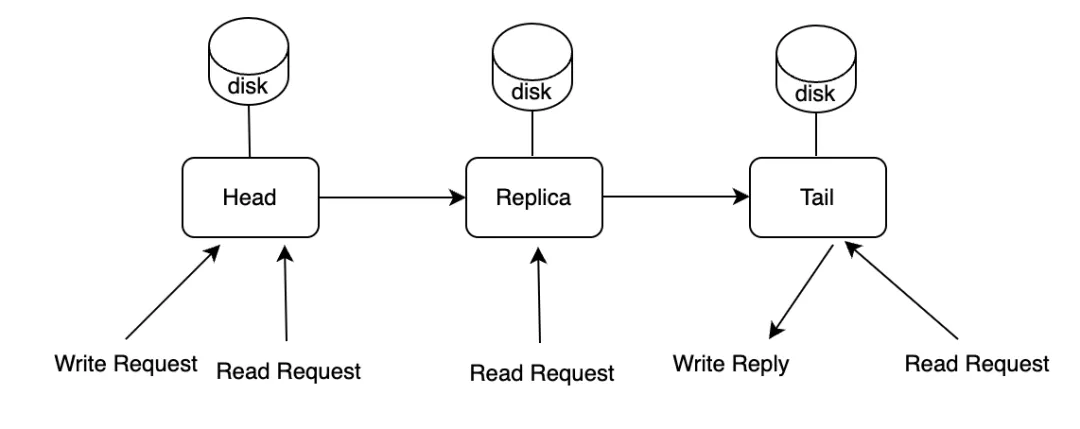
3FS는 대량의 로컬 SSD를 데이터 저장에 활용한다. 데이터 저장의 일관성을 보장하기 위해, 3FS는 CRAQ (Chain Replication with Apportioned Queries)라는 간단한 데이터 일관성 알고리즘을 사용한다.
- 여러 개의 복제본이 체인 형태로 구성되며, 쓰기 요청은 체인의 헤드 (Head)에서 시작되어 테일 (Tail)에 도달하면 성공 응답을 반환한다. 반면, 읽기 요청은 체인의 모든 복제본에 전달할 수 있다. 만약 오염된 (Dirty) 노드의 데이터를 읽게 되면, 해당 노드는 테일 노드에 상태를 확인하여 일관성을 보장한다 (아래 그림).
-
데이터는 순차적으로 작성되며 노드 간에 전파되기 때문에 상대적으로 높은 지연 (latency)이 발생할 수 있다. 체인 내의 복제본 중 하나가 사용 불가능해지면, 3FS는 해당 복제본을 체인의 끝으로 이동시키고, 복제본이 다시 사용 가능해졌을 때 이를 복구한다. 복구 시에는 사용 불가능했던 기간의 증분 데이터만 복원하는 것이 아니라 전체 청크(Chunk) 데이터를 통째로 복사해야 한다. 모든 복제본에 동기적으로 데이터를 쓰고 증분 복구를 하려면 로직이 훨씬 복잡해지는데, 예를 들어 Ceph는 pg log를 사용해 데이터 일관성을 유지한다.
- 이러한 3FS의 설계는 쓰기 지연을 유발하지만, 읽기 기반의 AI 애플리케이션 시나리오에서는 큰 영향을 주지 않는다.
-
반면, JuiceFS는 오브젝트 스토리지를 데이터 저장소로 사용하기 때문에, 오브젝트 스토리지가 제공하는 높은 데이터 신뢰성과 일관성 등의 장점을 활용할 수 있다. 스토리지 모듈은 오브젝트 조작을 위한 GET / PUT / HEAD / LIST 등의 인터페이스를 제공하며, 사용자는 필요에 따라 다양한 스토리지 시스템과 연동할 수 있다. 예를 들어, 클라우드 벤더의 오브젝트 스토리지 또는 MinIO, Ceph RADOS와 같은 프라이빗 오브젝트 스토리지를 사용할 수 있다. JuiceFS 커뮤니티 버전은 로컬 캐시를 제공하여 AI 시나리오에서의 대역폭 요구를 충족시키며, 엔터프라이즈 버전은 분산 캐시를 사용해 더 큰 범위의 집계된 읽기 대역폭 요구를 충족시킨다.
(2) 메타데이터 모듈
- 3FS에서는 파일 속성 정보가 KV (Key-Value) 형태로 메타데이터 서비스에 저장된다. 이 서비스는 무상태 (stateless)이며 고가용성을 갖춘 서비스로, FoundationDB를 기반으로 한다.
- FoundationDB는 애플이 오픈소스로 공개한 고성능 분산 Key-Value 데이터베이스로, 높은 안정성을 자랑한다. FoundationDB는 모든 키 값을 전역적으로 정렬한 후, 이를 여러 노드에 균등하게 분산시켜 저장한다.
- 디렉터리 목록 조회 (list directory)의 효율성을 높이기 위해, 3FS는 DENT라는 접두어에 상위 디렉터리의 inode 번호와 이름을 조합한 값을 dentry key로 사용한다.
- inode key는 INOD 접두어와 inode ID를 결합하여 생성되며, 이 때 inode ID는 리틀 엔디안 (little-endian) 바이트 순서로 인코딩되어 여러 FoundationDB 노드에 균등 분산되도록 설계되어 있다.
- 이러한 방식은 JuiceFS의 메타데이터 서비스에서 사용하는 트랜잭션 기반 Key-Value DB(TKV)의 저장 방식과 유사하다.
- inode key는 INOD 접두어와 inode ID를 결합하여 생성되며, 이 때 inode ID는 리틀 엔디안 (little-endian) 바이트 순서로 인코딩되어 여러 FoundationDB 노드에 균등 분산되도록 설계되어 있다.
- JuiceFS 커뮤니티 에디션의 메타데이터 모듈도 스토리지 모듈과 마찬가지로, 다양한 메타데이터 연산 인터페이스를 제공하며, 이를 통해 다양한 메타데이터 서비스와 연동할 수 있다. 예를 들어, Redis, TiKV와 같은 KV 데이터베이스, MySQL, PostgreSQL 등의 관계형 데이터베이스, 그리고 FoundationDB 등과 연동이 가능하다.
- 반면, JuiceFS 엔터프라이즈 에디션은 자체 개발한 고성능 메타데이터 서비스를 사용하며, 부하 상황에 따라 데이터와 핫스팟 연산을 자동 분산시켜 특정 노드에 메타데이터 연산이 집중되는 현상 (예: 인접 디렉터리 내 파일들에 대한 반복 연산)으로 인한 성능 저하를 방지할 수 있도록 설계되어 있다.
(3) 클라이언트
- 3FS 클라이언트는 일반적인 FUSE 인터페이스를 제공하는 것 외에도, FUSE를 우회하여 직접 데이터를 조작할 수 있는 API 세트, 즉 네이티브 클라이언트 (Native Client)를 함께 제공한다. 이 API의 호출 방식은 Linux AIO (Asynchronous I/O)와 유사한 형태를 띠며, FUSE 모듈 사용 시 발생하는 데이터 복사 (data copy)를 회피함으로써 I/O 지연(latency)과 메모리 대역폭 사용량을 줄이는 것이 주요 목적이다.
- 3FS는 hf3fs_iov 구조체를 활용하여 공유 메모리의 크기, 주소 및 기타 속성을 저장하고, IoRing을 이용해 두 프로세스 간의 통신을 수행한다.
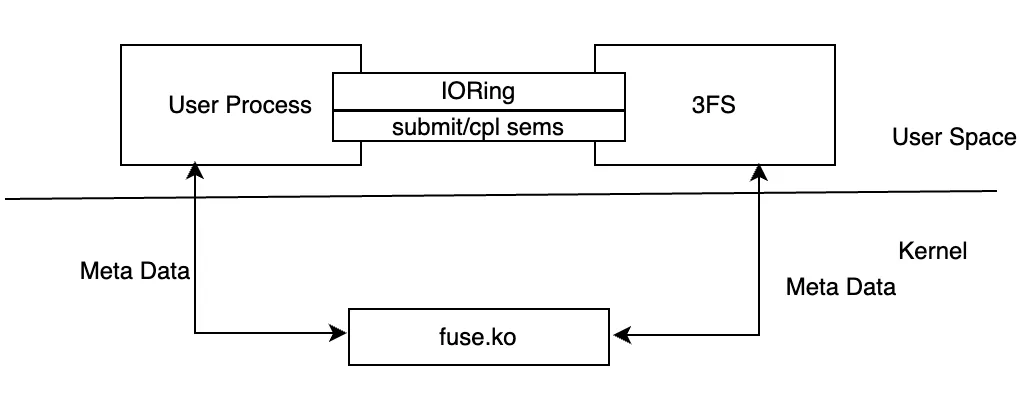
- 사용자가 인터페이스를 호출하여 메모리를 생성하면, hf3fs_iov 구조체에 해당하는 메모리가 /dev/shm 상에 할당되며, 이 공유 메모리를 가리키는 소프트 링크 (soft link)가 생성된다.
- 이 소프트 링크의 경로는 /mount_point/3fs-virt/iovs/에 위치한 가상 디렉터리이며, 3FS FUSE 프로세스가 해당 소프트 링크 생성 요청을 수신하고 경로가 해당 가상 디렉터리에 속함을 인식하면, 소프트 링크의 이름을 통해 공유 메모리의 관련 파라미터를 파싱한 뒤, 이 메모리 주소를 모든 RDMA 장치에 등록한다 (IORing 제외).
- 이 때 ibv_reg_mr를 호출하여 얻은 등록 결과는 RDMABuf::Inner라는 구조체에 저장되어 이후 RDMA 요청 처리에 사용된다.
- 동시에, IoRing의 메모리 역시 hf3fs_iov 구조체에 저장되지만, 소프트 링크를 생성할 때 파일 이름에 IoRing 관련 정보가 추가된다. FUSE 프로세스가 해당 메모리가 IoRing 용도임을 판단하면, 자신의 프로세스 내에도 해당 IoRing을 생성한다. 이 과정을 통해 사용자 프로세스와 FUSE 프로세스는 동일한 IoRing을 공유하게 된다.
- 이 소프트 링크의 경로는 /mount_point/3fs-virt/iovs/에 위치한 가상 디렉터리이며, 3FS FUSE 프로세스가 해당 소프트 링크 생성 요청을 수신하고 경로가 해당 가상 디렉터리에 속함을 인식하면, 소프트 링크의 이름을 통해 공유 메모리의 관련 파라미터를 파싱한 뒤, 이 메모리 주소를 모든 RDMA 장치에 등록한다 (IORing 제외).
- 프로세스 간 협업 측면에서, 3FS는 /mount_point/3fs-virt/iovs/ 디렉터리에 세 가지 우선순위에 따른 제출 세마포어 (submit semaphore)를 공유하는 가상 파일 세 개를 생성한다. 사용자 프로세스는 요청을 IoRing에 넣은 뒤, 이 세마포어들을 통해 FUSE 프로세스에 새 요청이 있음을 알린다. IoRing의 꼬리(tail)에는 요청 완료 세마포어가 포함되어 있으며, FUSE 프로세스는 sem_post를 호출하여 사용자 프로세스에 요청 처리가 완료되었음을 알린다. 이 메커니즘은 두 프로세스 간의 효율적인 데이터 통신 및 작업 동기화를 보장한다.
-
3FS의 FUSE 클라이언트는 기본적인 파일 및 디렉터리 조작 기능을 제공하는 반면, JuiceFS의 FUSE 클라이언트는 보다 포괄적인 기능을 제공한다. 예를 들어, 3FS 파일 시스템에서 파일 길이는 최종 일관성 (eventual consistency)을 따르므로, 쓰기 도중에는 사용자에게 잘못된 길이 정보가 보일 수 있다. 반면 JuiceFS는 각 오브젝트 업로드가 성공할 때마다 즉시 파일 길이를 갱신한다.
-
또한 JuiceFS는 다음과 같은 고급 파일 시스템 기능도 지원한다:
- BSD 락(flock)과 POSIX 락(fcntl) 지원
- file_copy_range 인터페이스 지원
- readdirplus 인터페이스 지원
- fallocate 인터페이스 지원
- JuiceFS는 FUSE 클라이언트 외에도 Java SDK, S3 Gateway, CSI Driver 등 다양한 접근 방식을 제공하며, 엔터프라이즈 버전에서는 Python SDK도 제공한다. Python SDK는 사용자 프로세스 내에서 JuiceFS 클라이언트를 실행함으로써, FUSE로 인해 발생하는 추가적인 성능 오버헤드를 회피할 수 있다. 자세한 내용은 Python SDK 문서를 참고하면 된다.
File Distribution 비교
3FS File Distribution
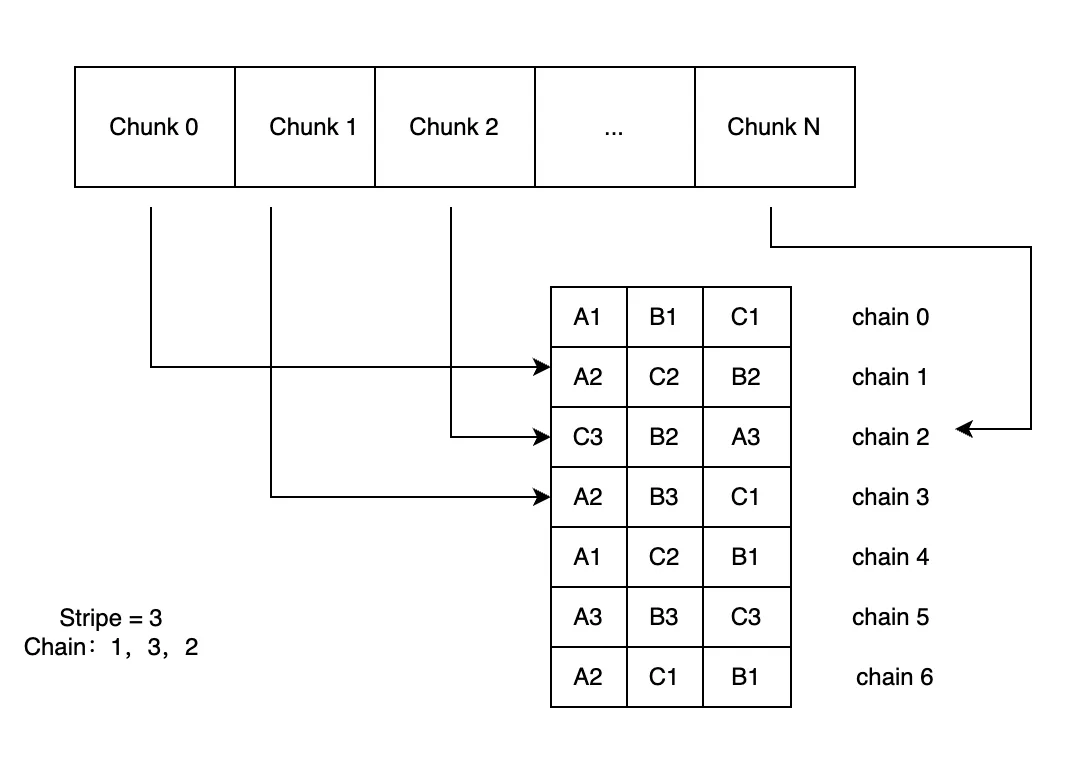
3FS는 각 파일을 고정 길이의 청크(chunk)로 분할하며, 각 청크는 앞서 언급한 CRAQ 알고리즘 기반의 체인(Chain)에 배치된다. 사용자는 3FS에서 제공하는 스크립트를 사용해 체인 테이블을 생성한 후, 이를 메타데이터 서비스에 제출한다. 새로운 파일이 생성될 때, 시스템은 해당 테이블에서 지정된 개수의 체인(stripe로 정의됨)을 선택하고, 이 체인들의 정보를 파일의 메타데이터에 저장한다.
- 3FS의 청크 크기는 고정되어 있으므로, 클라이언트는 파일의 inode에 대한 체인 정보만 한 번 조회하면, 이후에는 I/O 요청의 offset 및 길이 (length) 정보를 기반으로 해당 요청이 어떤 청크에 속하는지 계산할 수 있다. 즉, 매번 데이터베이스를 조회할 필요가 없다.
- 청크의 인덱스는 offset / chunk_size로 계산된다.
- 해당 청크가 속한 체인의 인덱스는 chunk_id % stripe로 구할 수 있다.
- 체인 인덱스를 통해 해당 체인을 구성하는 타겟 (target) 노드 정보를 가져올 수 있으며, 이후 클라이언트는 라우팅 정보를 기반으로 I/O 요청을 해당 스토리지 서비스에 전송한다. 스토리지 서비스는 쓰기 요청을 수신하면, 데이터를 Copy-on-Write(COW) 방식으로 새 위치에 저장하며, 참조된 데이터가 삭제되기 전까지는 기존 데이터도 계속 읽을 수 있다.
데이터 불균형 문제를 완화하기 위해, 각 파일의 첫 번째 체인은 라운드 로빈 방식으로 선택된다. 예를 들어 stripe가 3일 경우, 첫 번째 파일은 chain0, chain1, chain2를 사용하고, 다음 파일은 chain1, chain2, chain3를 사용하게 된다. 이후, 선택된 3개의 체인은 무작위로 정렬되어 메타데이터에 저장된다. 아래 그림은 stripe가 3일 때 파일이 분산 저장되는 예시이며, 무작위 정렬된 체인의 순서는 1, 3, 2이다.
JuiceFS의 파일 분산 방식
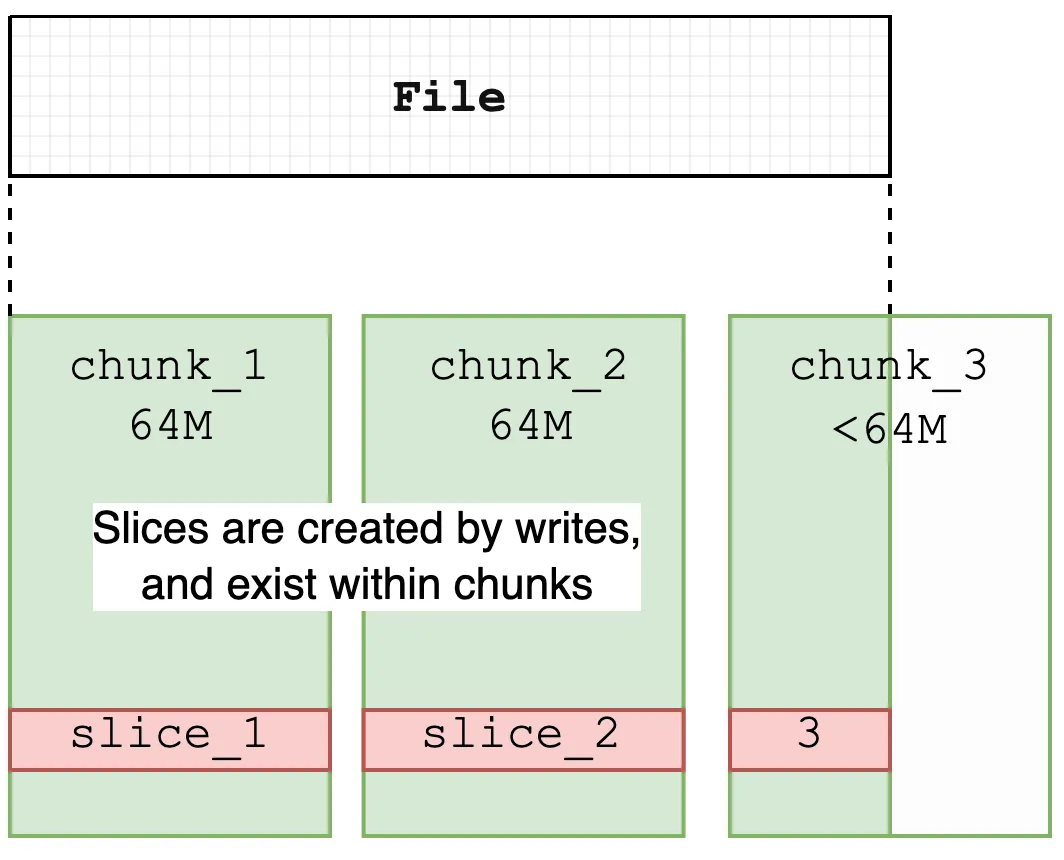
JuiceFS는 데이터를 Chunk, Slice, Block이라는 규칙에 따라 관리한다. 각 Chunk의 크기는 고정적으로 64MB이며, 이는 주로 데이터 탐색 및 위치 지정 최적화를 위해 사용된다. 실제 파일 쓰기 작업은 Slice 단위로 수행되며, 각 Slice는 하나의 연속된 쓰기 동작을 의미하고, 특정 Chunk에 속하며 Chunk 경계를 넘지 않기 때문에 최대 길이는 64MB를 초과하지 않는다.
- Chunk와 Slice는 논리적 분할 단위인 반면, Block은 실제 저장을 위한 물리적 단위이며, 기본 크기는 4MB이다. Block은 오브젝트 스토리지 및 디스크 캐시에 데이터를 최종 저장하는 데 사용되는 최소 단위이다.
- 보다 자세한 내용은 공식 웹사이트 소개를 참고하면 된다.
JuiceFS에서의 Slice는 다른 파일 시스템에서는 흔히 볼 수 없는 독특한 구조이다. 이 구조의 주요 역할은 파일 쓰기 작업을 기록하고, 이를 오브젝트 스토리지에 영구 저장하는 것이다. 오브젝트 스토리지는 제자리(in-place) 수정을 지원하지 않기 때문에, JuiceFS는 Slice 구조를 도입함으로써 전체 파일을 다시 쓰지 않고도 내용 일부를 수정할 수 있도록 설계되었다. 이러한 방식은 기존 객체를 덮어쓰지 않고 새로운 객체만 생성한다는 점에서 저널링 파일 시스템(Journal File System)과 유사하다.
파일이 수정될 경우, 시스템은 새로운 Slice를 생성하고, 해당 Slice가 업로드된 후 메타데이터를 갱신하여 파일 내용이 새로운 Slice를 참조하도록 한다. 기존에 덮어쓰인 Slice는 비동기 압축 프로세스를 통해 오브젝트 스토리지에서 삭제되며, 이로 인해 일시적으로 오브젝트 스토리지의 사용량이 실제 파일 시스템 사용량보다 많아질 수 있다.
또한 JuiceFS의 모든 Slice는 한 번만 기록(write-once)되므로, 하위 오브젝트 스토리지의 일관성(consistency)에 대한 의존도를 줄이고, 캐시 시스템의 복잡성을 크게 완화시켜 데이터 일관성 보장을 보다 쉽게 만든다. 이 설계는 파일 시스템의 제로-카피(zero-copy) 시맨틱 구현에도 적합하며, copy_file_range나 clone과 같은 고급 파일 조작도 지원할 수 있다.
3FS의 RPC (Remote Procedure Call) 프레임워크
3FS는 하위 네트워크 통신 프로토콜로 RDMA를 사용하며, 이는 현재 JuiceFS에서는 지원되지 않는다. 아래는 이에 대한 분석이다.
- 3FS는 기본 IB (InfiniBand) 네트워크 연산을 수행하기 위한 RPC 프레임워크를 자체 구현하였다. 이 프레임워크는 네트워크 통신 외에도 직렬화 (serialization), 패킷 병합 (packet merging) 등 다양한 기능을 제공한다.
- C++ 언어는 기본적으로 리플렉션 (reflection) 기능이 없기 때문에, 3FS는 템플릿을 활용한 리플렉션 라이브러리를 구현하여, RPC에서 사용하는 요청 (request) 및 응답 (response) 구조체의 직렬화를 가능하게 한다. 직렬화가 필요한 데이터 구조는 특정 매크로를 사용하여 직렬화할 속성만 정의하면 된다.
- 모든 RPC 호출은 비동기 방식(asynchronous)으로 처리되므로, 직렬화된 데이터는 힙(Heap)에 할당되어야 하며, 호출이 완료된 후 해제되어야 한다.
- 메모리 할당/해제 속도를 높이기 위해, 할당된 객체는 캐시된다. 이 캐시는 TLS (Thread-Local Storage) 큐와 글로벌 큐 두 부분으로 구성되어 있다.
- TLS 큐에서 캐시를 가져올 경우에는 락(lock)이 필요 없으며,
- TLS 캐시가 비어 있을 경우에만 글로벌 큐에서 락을 걸고 캐시를 가져온다. 즉, 이상적인 경우에는 락 없이 캐시를 사용할 수 있어 성능이 향상된다.
- 메모리 할당/해제 속도를 높이기 위해, 할당된 객체는 캐시된다. 이 캐시는 TLS (Thread-Local Storage) 큐와 글로벌 큐 두 부분으로 구성되어 있다.
- I/O 요청에서 사용하는 메모리와는 달리, 캐시 객체의 메모리는 RDMA 디바이스에 등록되지 않는다. 따라서 데이터가 IBSocket에 도착하면, 이를 IB 디바이스에 등록된 버퍼로 복사해야 한다. 여러 개의 RPC 요청은 하나의 IB 요청으로 병합되어 전송될 수 있다.
결론
대규모 AI 학습에서 가장 중요한 요구사항은 높은 읽기 대역폭(read bandwidth)이다. 이를 위해 3FS는 성능 우선 (performance-first) 설계 전략을 채택하였으며, 데이터를 고속 디스크에 저장하고, 사용자가 직접 하위 저장 장치를 관리해야 한다. 이러한 방식은 성능 향상에는 효과적이지만, 비용이 더 높고 유지보수가 번거롭다. 또한, 하드웨어의 성능을 최대한 활용하기 위해 클라이언트에서 네트워크 카드까지 제로-카피 (zero-copy)를 구현하고, 공유 메모리 및 세마포어를 활용해 I/O 지연 및 메모리 대역폭 사용량을 최소화하였다.
더불어, TLS 기반 I/O 버퍼 풀 및 네트워크 요청 병합을 통해 소규모 I/O 및 파일 메타데이터 연산 처리 능력을 향상시켰고, 더 뛰어난 성능을 제공하는 RDMA 기술도 도입하였다. 향후에도 3FS의 성능 최적화 진전에 주목하며, 이러한 기술들을 실제 활용 환경에 어떻게 적용할 수 있을지 지속적으로 탐구할 예정이다.
한편, JuiceFS는 오브젝트 스토리지를 하위 데이터 저장소로 사용함으로써, 스토리지 비용을 크게 절감하고 운영 및 유지보수를 간소화할 수 있다. AI 환경에서의 읽기 성능 요구를 만족시키기 위해, JuiceFS 엔터프라이즈 에디션은 분산 캐시, 분산 메타데이터 서비스, Python SDK 등을 도입하여, 낮은 저장 비용을 유지하면서도 파일 시스템의 성능과 확장성을 동시에 확보하였다. 다가오는 v5.2 엔터프라이즈 에디션에서는 TCP 네트워크에서도 제로-카피 기능이 구현되어, 데이터 전송 효율이 더욱 향상될 예정이다.
JuiceFS는 완전한 POSIX 호환성, 성숙하고 활발한 오픈소스 생태계를 바탕으로 더 넓은 범위의 사용 시나리오에 적응할 수 있으며, Kubernetes CSI를 지원하여 클라우드 플랫폼의 배포 및 운영을 대폭 단순화시킨다. 또한, 쿼터 관리, 보안 관리, 재해 복구 등 다양한 엔터프라이즈급 관리 기능을 함께 제공하여, 기업이 실제 생산 환경에 JuiceFS를 보다 쉽게 적용하고 운영할 수 있도록 지원한다.
3FS의 각개 컴포넌트를 보면 특별히 새로울 것이 없거나, 또는 어찌보면 굉장히 당연한 얘기를 그럴듯하게 설명한 느낌이 든다. 하지만 이들의 value는 그러한 각개 요소에 있는게 아니라, 현대 AI 워크로드 서빙을 위해 적합한 각개 기술들을 적재적소에 넣고 섞어서 하나의 제대로된 스토리지 서비스를 제공했다는 점이 아닐까 싶다. 저런 기술들을 하나로 통합해서 구축하기가 결코 쉽지 않았을텐데, 딥시크가 AI만 잘하는줄 알았는데 시스템도 상당히 고급 인력들을 많이 가지고 있지 않나 싶음.
본 글에 담긴 Claim격의 서술은 모두 제 개인의 의견일 뿐이며 아무런 대표성을 가지지 않습니다.
