apply(), groupby(), pivot_table() 세가지 메서드의 기능이 비슷한데, 각각 활용방법을 정확히 이해할 필요가 있을 듯.
고급 전처리 및 피벗테이블
행/열 삭제
# Column 삭제
df.drop('class', axis = 'columns')
df.drop(['class', 'age','who'], axis = 'columns')
df.drop(['who','deck','alive'], axis = 'columns', inplace = True)
# Row 삭제
df.drop([1,3,5,7,9])
# 새로운 열 생성(마지막에 생성)
df['VIP'] = True
# 열 생성 (위치, 조건 지정)
df.insert(5,'RICH', df['age']>30)dtype: category
# category 변경
df['who'] = df['who'].astype('category')
# category 출력
df['who'].cat.categories
# category 변경
df['who'].cat.categories = ['아이','남자','여자']
# category 개수 출력
df['who'].value_counts()문자열 처리
# 각 열의 값을 '/'를 기준으로 split, 첫번째 데이터만 표시
seoul['지번주소'].apply(lambda x : x.split('/')[0])
seoul['지번주소'].str.split('/').str[0]dtype : datetime
# 열 dtype -> datetime으로 변경 뒤, dt.year... 를 사용해 접근
df2['대여일자'] = pd.to_datetime(df2['대여일자'])
df2['연도'] = df2['대여일자'].dt.year
df2['월'] = df2['대여일자'].dt.month
df2['일'] = df2['대여일자'].dt.day
df2['요일'] = df2['대여일자'].dt.weekday구간 나누기
# 1. 구간 나누기 (pd.cut ())
# 임의로 구간 설정하여 나누기 -> 어느 한 구간으로 데이터 쏠릴 수 있다
age_bins = [0,15,30,45, sample['age'].max()]
pd.cut(sample['age'], age_bins, right = False).value_counts()
# 2. 균등 분할 (pd.qcut())
labels = ['young', 'normal', 'old']
pd.qcut(sample['age'], q = 3, labels = labels)데이터 전처리 / 피벗 테이블
groupby()
참고 사이트: https://teddylee777.github.io/pandas/pandas-groupby/
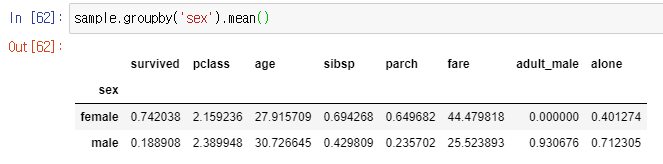
# 성별 기준 평균
df.groupby('sex').mean()
# 2개 이상의 컬럼으로 그룹 : 성별, 좌석등급 별 통계
df.groupby(['sex','pclass']).mean()
# 1개의 특정 컬럼에 대한 결과
df.groupby(['sex','pclass'])['survived'].mean()
pd.DataFrame(df.groupby(['sex','pclass'])['survived'].mean())
df.groupby(['sex','pclass'])[['survived']].mean()
# index 초기화
df.groupby(['sex', 'pclass'])['survived'].mean().reset_index()
# 성별, 좌석등급 별 통계
df.groupby(['sex', 'pclass'])[['survived', 'age']].agg(['mean', 'sum'])
groupby() 예제
- 남자 나이 결측치는 남자 나이의 평균으로 채우기
- 여자 나이 결측치는 여자 나이의 평균으로 채우기
sample['age'] = sample.groupby('sex')['age'].apply(lambda x: x.fillna(x.mean()))sample.groupby('sex') 의 'age' 열의 모든 행(female, male)에 대해 apply(lambda x: x.fillna(x.mean()))을 적용
pivot_table()
엘셀의 피벗과 동작이 유사하며, groupby() 와도 동작이 유사하다
index, columns, values를 지정해서 피벗
# index 에 그룹을 표기
df.pivot_table(index = 'who', values = 'survived')
#columns 에 그룹을 표기
df.pivot_table(columns = 'who', values = 'survived') |  |
|---|
# 다중 그룹에 대한 단일 컬럼
df.pivot_table(index = ['who', 'pclass'], values = 'survived')
# index에 컬럼을 중첩하지 않고 행과 열로 펼친 결과
df.pivot_table(index = 'who', columns = 'pclass', values = 'survived')
# 다중 통계 함수 적용
df.pivot_table(index = 'who', columns = 'pclass', values = 'survived', aggfunc = ['sum', 'mean'])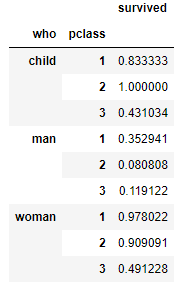 | 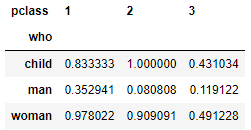 | 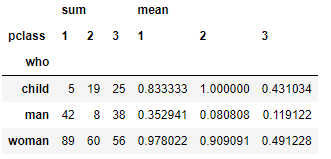 |
|---|
# aggfunc 의 default 값은 mean 이다
tips.pivot_table(index = 'day', columns = 'time', values = 'total_bill' , aggfunc = ['mean','sum'])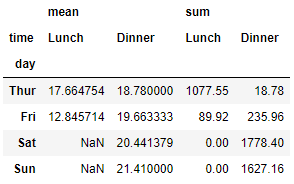
마무리 문제
아래와 같은 dataset(taxis)에서
- 요일별
distance의 평균 산출
- 요일별
- 구한 평균치 보다 작은(미만) 데이터만 추출
(예시) 0: 월요일 평균distance가3.21597이라면3.21597보다 작은 데이터만 추출(월~일요일까지 모두 적용)
- 구한 평균치 보다 작은(미만) 데이터만 추출
- 필터 후
distance,fare,tip에 대한 중앙값(median) 과 표준편차(std)를 산출
- 필터 후
- 요일(
dayofweek)과payment별fare의 중앙값(median)과 표준편차(std)를 산출합니다.
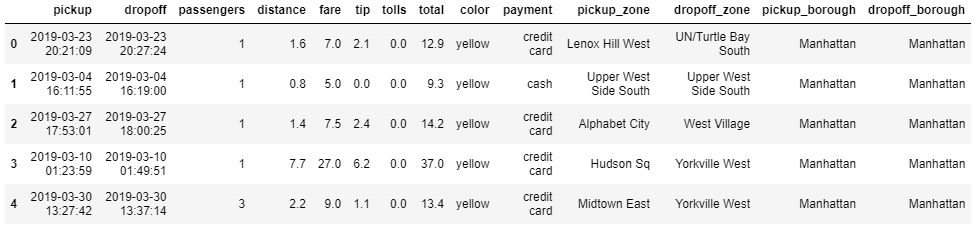
- 요일(
1. 요일별 distance 산출
import numpy as np
import pandas as pd
import seaborn as sns
# pickup 열의 데이터 타입은 datetime
taxis = sns.load_dataset('taxis')
# 'dayofweek' 열 생성
taxis['dayofweek'] = taxis['pickup'].dt.dayofweek
# 요일별 distance 평균 값
table_mean = taxis.groupby(by='dayofweek')['distance'].mean().reset_index()2. 구한 평균치 보다 작은 데이터 추출
def is_small(x):
return x['distance'] < table_mean.loc[x['dayofweek'], 'distance']
######################################################
cond = taxis.apply(is_small, axis = 1)3. 필터 후 distance, fare, tip에 대한 중앙값(median) 과 표준편차(std)를 산출
small_table = taxis.loc[cond, ['distance', 'fare', 'tip']].aggg(['median', 'std'])4. 요일(dayofweek)과 payment 별 fare의 중앙값(median)과 표준편차(std)를 산출
taxis.pivot_table(index = 'dayofweek', columns = 'payment', values = 'fare', aggfunc = ['median', 'std'])데이터 연결 및 병합, 데이터프레임 시각화
데이터 연결(concat)
단순 연결 (행, 열 방향으로 연결 가능)
# 행
pd.concat([A,B], axis = 0)
# 열
pd.concat([A,B], axis = 1)데이터 병합(merge)
4가지 방식
- inner: 교집합(default)
- outer: 합집합
- left: 왼쪽 기준
- right: 오른쪽 기준
- 병합하려는 컬럼의 이름이 다른 경우 :
pd.merge(A,B,left_on='이름',right_on='고객명')
merge 예제
- dataset 두가지 (
userprofile,rating_final)를 병합하고 birth_year기준으로 1980년 이상, 1989년 이하 출생 자를 필터 후rating의 평균과 표준편차 산출
# 필터링 함수
def filter_age(x):
return (x['birth_year'] >= 1980) & (x['birth_year'] <= 1989)
# merge
merged = pd.merge(userprofile, rating_final, how = 'inner')
# 필터링
cond_age = merged.apply(filter_age, axis = 1)
# rating의 평균과 표준편차
merged.loc[cond_age, 'rating'].agg(['mean', 'std'])
# rating의 평균만 산출하는경우
merged.loc[cond_age, 'rating'].mean()
