- Multinomial classification: 여러 개의 클래스가 있을 때 예측하는 분류기법.
remind — Logistic regression
- H(X)=XW
- 시작은 기본적인 Linear Regression이다.
- 그러나 Linear는 그 결과값이 어떤 특정한 실수값이 되기 때문에 Binary Classification에는 적합하지 않다.
- Z=H(X), g(Z)=1+e−Z1
- 따라서 H(X)를 Z로 보고, H(X)의 결과값을 압축하여 0∼1 사이의 값을 가질 수 있도록 만든다.
- 이 g(Z)를 시그모이드 혹은 로지스틱이라고 부른다.
- 현재까지의 이미지는 다음과 같다
X→(W를 가지고 계산)→Z→(Sigmoid)→Yˉ∈{0,1}
- Y: real data, Yˉ: prediction =H(X)
- 이 로지스틱 회귀는 입력변수 x1,x2의 값을 가지고 있는데, 이를 통해 데이터를 2개의 분류로 나누는 것을 목적으로 한다.
- 즉, 로지스틱 회귀의 학습이란, 두 데이터를 나누는 선을 찾아내는 것이다.
- 그리고 이 아이디어를 그대로 Multinomial classification에 적용할 수 있다.
Multinomial classification
데이터 예제
| x1(hours) | x2(attendance) | y(grade) |
|---|
| 10 | 5 | A |
| 9 | 5 | A |
| 3 | 2 | B |
| 2 | 4 | B |
| 11 | 1 | C |
One-vs-Rest 아이디어
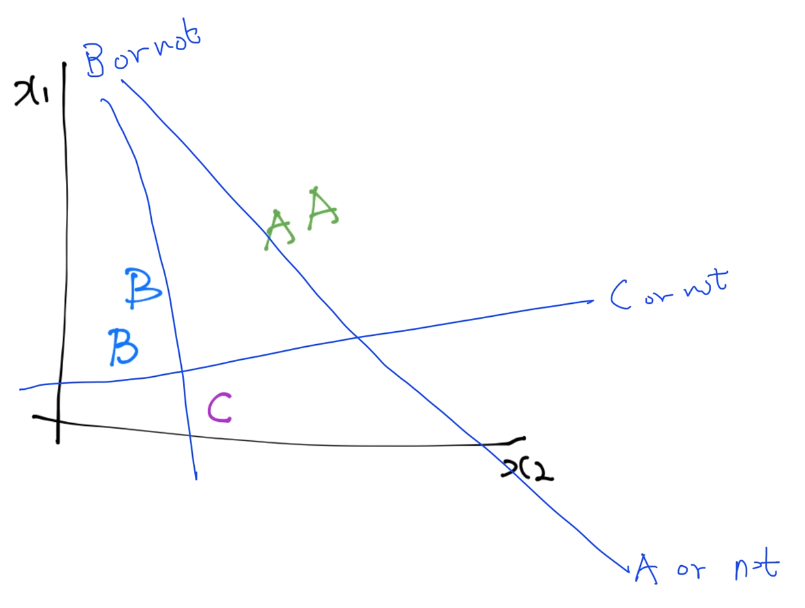
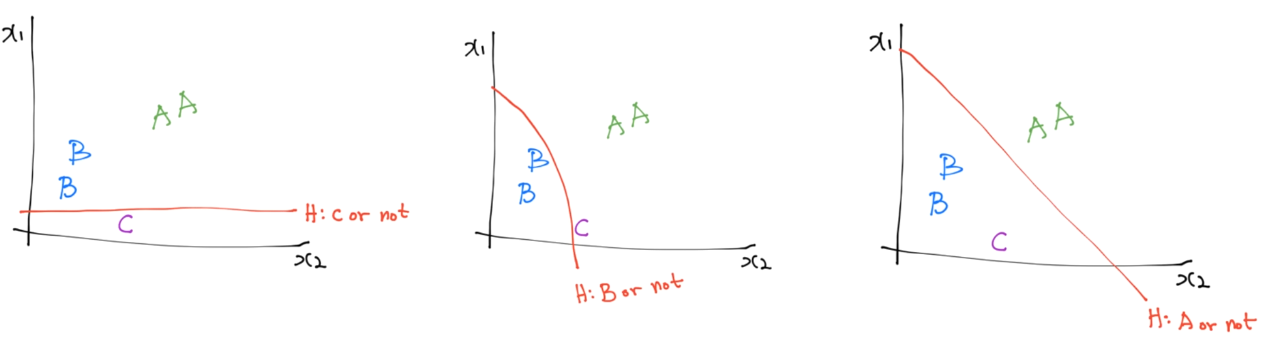
- 하나의 직선을 찾는다(가령 C).
- 이 직선은 C이거나 C가 아니거나 2개만 구분한다.
- 다른 A, B에 대해서도 직선을 찾는다((A/B)이거나 아니거나).
- 이 3개의 직선을 각각 로지스틱 회귀하여 독립된 classifier를 얻는다(=가설 H(X)).
- 이 classifier를 실제로 구현할 때에는 행렬로 구현한다. 즉, 3개의 행렬곱을 얻을 수 있다
[w1 w2 w3]⎣⎢⎡x1x2x3⎦⎥⎤=w1x1+w2x2+w3x3.
- 그러나 3개의 행렬은 너무 복잡하므로, 이 세 행렬을 하나로 합칠 수 있다
⎣⎢⎡w11w21w31w12w22w32w13w23w33⎦⎥⎤⎣⎢⎡x1x2x3⎦⎥⎤=⎣⎢⎡w11x1+w12x2+w13x3w21x1+w22x2+w23x3w31x1+w32x2+w33x3⎦⎥⎤=⎣⎢⎡YˉAYˉBYˉC⎦⎥⎤
Where is sigmoid?
- 이전처럼 3개의 선형 출력을 하나로 합치면 결과는 실수 벡터(점수)로 나온다.
- 각 출력을 확률로 바꾸고 싶다. 각 성분이 0∼1 범위이고 합이 1이 되게.
- 해결: 소프트맥스(softmax).
Softmax
- 선형 점수 벡터 z=(z1,…,zK)를 확률로 변환한다.
- 정의: S(z)i=∑j=1Kezjezi for i=1,…,K.
- 성질: 0≤S(z)i≤1이고 ∑iS(z)i=1.
- 예시 변환(개념):
- scores [2.0, 1.0, 0.1] ⇒ softmax ⇒ probabilities [0.7, 0.2, 0.1].
- 이후 예측 벡터를 원-핫으로 표현: 가장 큰 확률 위치만 1, 나머지 0.
Cross-Entropy
- S(y) : Softmax로 나온 예측값 = Yˉ
- L : Label. 실제값 = Y
S(y)=⎣⎢⎡0.70.20.1⎦⎥⎤,L=⎣⎢⎡1.00.00.0⎦⎥⎤,D(S,L)=−∑iLilogSi=−log0.7
- 수식
- D(S,L)=−∑iLilog(Si)=−∑iLilog(yˉi)=∑iLi⋅(−log(yˉi))
- 여기서 −log(yˉi)는 로지스틱에서 쓰인 동일한 로그 항이다.
−log(0+)=+∞, −log(1)=0.
예제
-
L=[01] (즉, 정답이 B인 레이블)
-
Yˉ1=[01]⇒ OK
[01] ⊙ (−log[01]) = [01] ⊙ [+∞0] = [00] ⇒ 최종 코스트 값:0
-
Yˉ2=[10]⇒ X
[01] ⊙ (−log[10]) = [01] ⊙ [0+∞] = [0+∞] ⇒ 최종 코스트 값:+∞
Logistic cost vs cross entropy
- C(H(x),y)=−[(y)log(H(x))+(1−y)log(1−H(x))]
- D(S,L)=−∑iLilog(Si)
- 이때 S는 예측값, L은 정답 레이블.
- 따라서 S=[H(x), 1−H(x)], L=[y, 1−y]로 표현할 수 있다.
- 이를 D(S,L)에 대입하면 −[ylogH(x)+(1−y)log(1−H(x))]가 되어 두 식은 동일하다.
출처: 모두를 위한 딥러닝 강좌 2
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
