Lec-10 1. Relu activation function
Sigmoid의 문제점
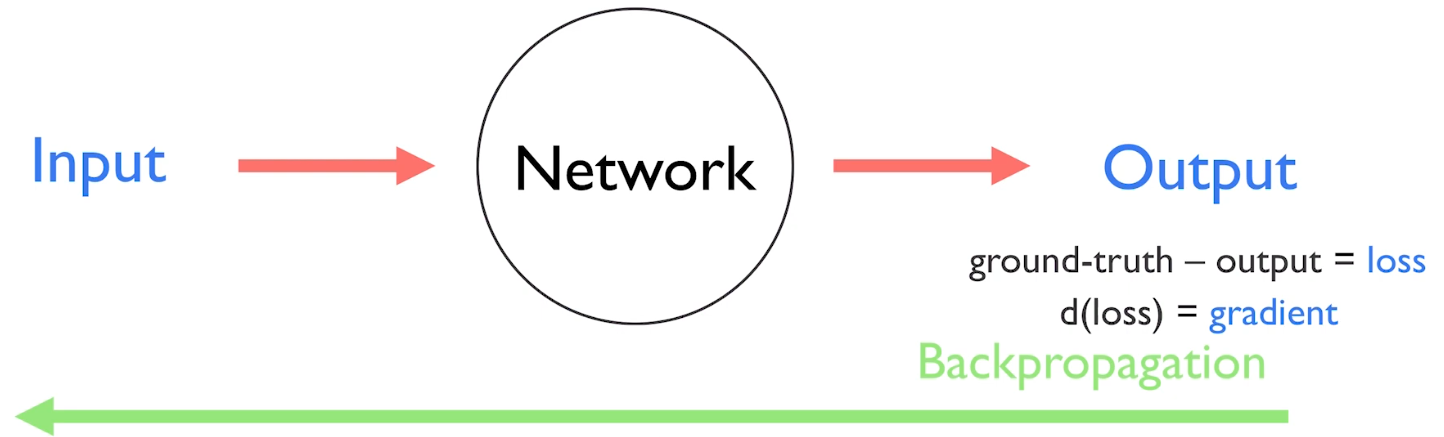
기존 NN은 다음과 같은 과정을 거친다.
input → Network → output
이때 ground-truth와 output이 얼마나 차이가 나는지를 loss라고 하고, loss를 미분한 것을 backpropagation 하면서 네트워크를 학습시킨다.
이때 backpropagation으로 전달되는 loss를 미분한 것(=d(loss))을 gradient라 부른다.

sigmoid 함수를 보면 가운데 부분은 gradient가 0보다 크지만, 양 극단으로 가면 기울기가 0에 매우 가까운 값을 가지게 된다.
⇒ 즉, 우리의 NN을 학습할 때 gradient를 전달받는데, 이 gradient가 작으면 안 된다.
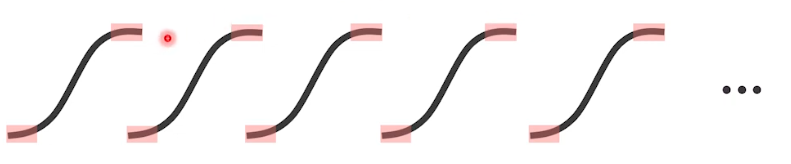
그러나 우리의 NN이 deep하여 작은 함수 여러 개가 만들어지고, 그 각각의 함수의 매우 작은 gradient가 계속 곱해진다면, 결국 gradient는 소실되어 네트워크는 전달받을 gradient가 없어지게 될 것이다.
⇒ 이러한 현상을 Vanishing Gradient라고 한다.
즉, Vanishing Gradient는 sigmoid 함수의 gradient 값들의 곱이 너무 작아 결국 전달할 gradient가 소실되어 버리는 현상이며, 이것이 sigmoid 함수의 문제점이다.
왜 Relu인가?
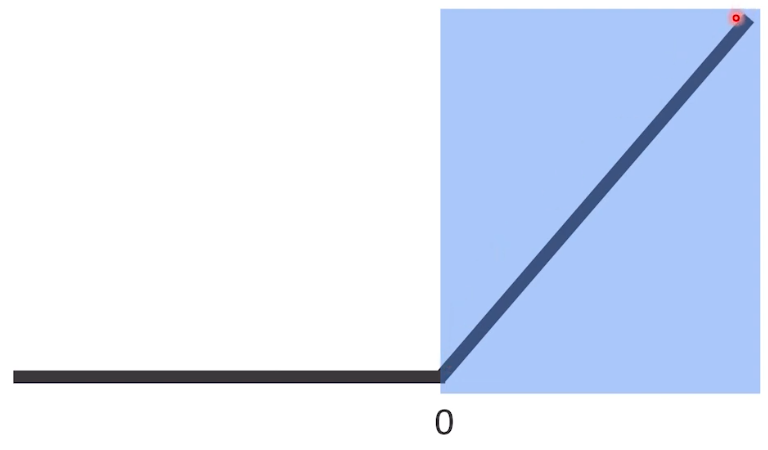
Relu는 다음과 같다.
⇒ 를 받았을 때, 가 0보다 크면 를 반환하고, 0보다 작으면 0을 반환하는 함수이다.
⇒ 즉 아무리 network가 deep하더라도 gradient가 잘 전달된다.
⇒ 그러나 Relu는 가 0보다 작을 경우 항상 0을 반환한다.
Relu 외에도 sigmoid, tanh, relu, elu, selu 등 여러 방법이 있고, 이들 모두가 tf.keras.activations에 들어있다.
⇒ 이를 보완한 것이 leaky relu 등이다.
Code
1) load dataset
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist # fashion_mnist, cifar10, cifar100
tf.enable_eager_execution()
def load_mnist():
# mnist.load_data()를 호출하면, train_data, train_labels, test_data, test_labels의 데이터를 받을 수 있다.
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
# 이 데이터를 그대로 쓸 순 없다. tensorflow가 input으로 받는 shape은
# [batch_size, height, width, channel]이기 때문이다.
# mnist는 gray scale이므로 channel이 1인 것이 생략되어 있다.
# 따라서 np.expand_dims로 채널을 하나 추가하여 shape을 바꿔야 한다.
# axis=-1은 오른쪽 끝에 채널을 추가한다.
train_data = np.expand_dims(train_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
test_data = np.expand_dims(test_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
# image normalization 과정
# dataset은 0~255의 값을 가지는데, 이를 0~1의 값을 가지도록 만든다.
# 이 과정은 normalize에서 각각 255로 나누는 것으로 간단하게 해결된다.
train_data, test_data = normalize(train_data, test_data) # [0~255] -> [0~1]
# 이후 정답들에 대한 전처리 과정은 to_categorical을 통해 진행한다.
# [N,]을 [N,10]으로 바꾸게 되는데, 이때 10은 우리가 사용하는 데이터 셋 라벨의 개수이다.
# => One Hot encoding : 각 분류에 대해서 정답은 1, 나머지는 0으로 만드는 것.
train_labels = to_categorical(train_labels, 10) # [N,] -> [N,10]
test_labels = to_categorical(test_labels, 10) # [N,] -> [N,10]
# 전처리가 끝난 데이터셋을 반환한다.
return train_data, train_labels, test_data, test_labels
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32) / 255.0
test_data = test_data.astype(np.float32) / 255.0
return train_data, test_data2) create network
# shape을 펼쳐주는 역할이다.
def flatten():
return tf.keras.layers.Flatten()
# dense layer = fully connected layer
# units : output으로 나가는 channel의 개수, use_bias : bias 사용 여부
def dense(channel, weight_init):
return tf.keras.layers.Dense(
units=channel,
use_bias=True,
kernel_initializer=weight_init,
)
# relu activation 함수를 사용함
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
# class 타입 모델. 반드시 tf.keras.Model을 상속받는다.
class create_model(tf.keras.Model):
# label_dim : 나중에 네트워크의 logit을 구할 때 최종 output 크기를 유동적으로 받기 위한 변수.
def __init__(self, label_dim):
super(create_model, self).__init__()
# RandomNormal : 평균 0, 분산 1인 가우시안 분포로 weight 생성
weight_init = tf.keras.initializers.RandomNormal()
# Sequential() : layer들을 순서대로 쌓아 두는 Keras 모델 클래스(컨테이너)
# 우리 네트워크는 convolutional 혹은 fully connected layers를 층층이 쌓아나가는 과정이다.
# 즉, list에 이것들을 계속 더해주는 과정이고, Sequential은 이를 위한 자료구조 타입이다.
self.model = tf.keras.Sequential()
# 1. list에 flatten()을 넣어준다.
# [N, 28, 28, 1] shape의 이미지를 [N, 784]로 바꿔준다.
# fully connected를 사용할 것이기 때문이다.
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for _ in range(2):
# [N, 784] -> [N, 256] -> [N, 256]
self.model.add(dense(256, weight_init))
self.model.add(relu())
# network의 logit을 구할 때에는 label_dim 개의 output으로 출력한다.
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
# 이 모델을 불렀을 때의 forward 결과
def call(self, x, training=None, mask=None):
x = self.model(x)
return x(참고용 함수형 버전)
def create_model_fn(label_dim):
weight_init = tf.keras.initializers.RandomNormal()
model = tf.keras.Sequential()
model.add(flatten())
for _ in range(2):
model.add(dense(256, weight_init))
model.add(relu())
model.add(dense(label_dim, weight_init))
return model3) define loss function

loss 함수. model, images, labels를 받고 model에 이미지를 넣어서 나온 logits 값을 이용해 loss를 구한다.
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits,
labels=labels,
)
)
return loss
# 정확도 함수. model, images, labels를 받아 logits를 구하고 argmax로 값을 비교한다.
# argmax : logits와 labels에서 가장 숫자가 큰 값의 위치를 알려준다.
# logits, labels shape은 [batch_size, label_dim]이다.
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
# boolean -> float32
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)4) experiments
4-1) hyper parameters
# dataset
train_x, train_y, test_x, test_y = load_mnist()
# hyper parameters
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
# Graph Input using Dataset API
# Dataset API로 각각의 데이터(이미지, 라벨)를 네트워크에 넣는 과정이다.
# train은 6만 장, test는 1만 장이므로 네트워크에 한꺼번에 넣을 수 없다.
# => batch_size만큼씩 던져준다.
# shuffle() : dataset을 잘 섞는다. buffer_size는 input data보다 크면 된다.
# prefetch() : 네트워크가 batch_size만큼 학습하는 동안, 다음 batch를 메모리에 미리 올려놓는다.
# batch() : 몇 개만큼 네트워크에 던져줄지 결정한다.
# repeat() : 반복
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()4-2) model
# Dataset Iterator
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
# Model
network = create_model(label_dim)
# Training
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)4-3) eager model
# Checkpoint() : 학습 중 끊겼을 때 다시 재학습하기 위한 역할. 즉, 학습되어서 저장된 weight를 부르는데 도움이 된다.
checkpoint_prefix = "./checkpoints/mnist_relu"
checkpoint = tf.train.Checkpoint(dnn=network)
# create_global_step() : 각 weight가 몇 번째 iteration의 weight인지 알려준다.
global_step = tf.train.create_global_step()
start_epoch = 0
start_iteration = 0
counter = 0
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
# 이미지와 라벨을 네트워크에 넣고 gradient를 구하고 이를 네트워크의 weight에 적용한다. => 학습
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(
grads_and_vars=zip(grads, network.variables),
global_step=global_step,
)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_iterator.get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print(
"Epoch: [%2d] [%5d/%5d], train_loss: %.8f, "
"train_accuracy: %.4f, test_Accuracy: %.4f"
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy)
)
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + "-{}".format(counter))
# Sigmoid : 81.31 %
# Relu : 85.35 %5) full code (Relu)
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist # fashion_mnist, cifar10, cifar100
tf.enable_eager_execution()
def load_mnist():
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data = np.expand_dims(train_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
test_data = np.expand_dims(test_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
train_data, test_data = normalize(train_data, test_data) # [0~255] -> [0~1]
train_labels = to_categorical(train_labels, 10) # [N,] -> [N,10]
test_labels = to_categorical(test_labels, 10) # [N,] -> [N,10]
return train_data, train_labels, test_data, test_labels
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32) / 255.0
test_data = test_data.astype(np.float32) / 255.0
return train_data, test_data
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(
units=channel,
use_bias=True,
kernel_initializer=weight_init,
)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.RandomNormal()
self.model = tf.keras.Sequential()
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for _ in range(2):
self.model.add(dense(256, weight_init))
self.model.add(relu())
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits,
labels=labels,
)
)
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)
# --- main ---
train_x, train_y, test_x, test_y = load_mnist()
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
network = create_model(label_dim)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
checkpoint_prefix = "./checkpoints/mnist_relu"
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
start_epoch = 0
start_iteration = 0
counter = 0
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(
grads_and_vars=zip(grads, network.variables),
global_step=global_step,
)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_iterator.get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print(
"Epoch: [%2d] [%5d/%5d], train_loss: %.8f, "
"train_accuracy: %.4f, test_Accuracy: %.4f"
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy)
)
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + "-{}".format(counter))Lec-10 2. Weight Initialization
Xavier Initialization (Glorot Initialization)
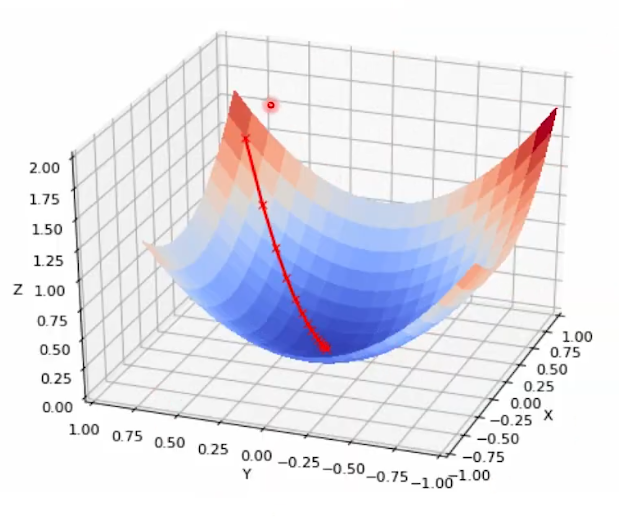
우리는 네트워크를 통해 loss가 가장 최저인 지점을 찾아야 한다.
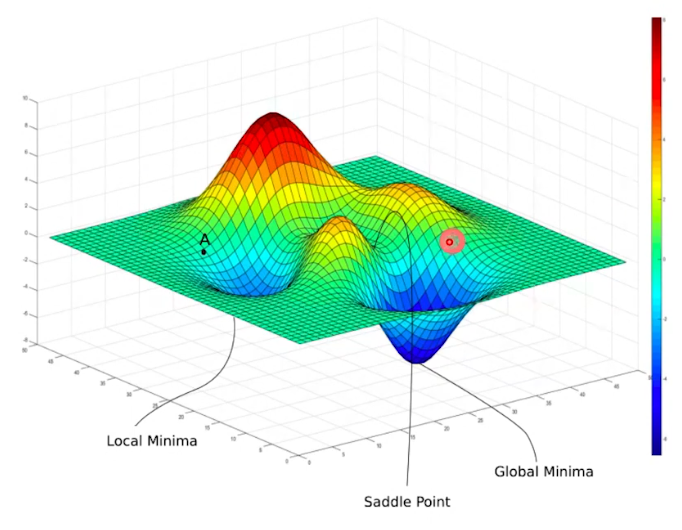
그러나 그래프가 위와 같이 되어 있다면, A에서 시작했을 때 global minima가 아닌 local 혹은 saddle point에 갇히게 된다.
⇒ 만약 우리가 A가 아닌 붉은 원에서 시작했다면 global minima를 찾을 수 있었을 것이다.
⇒ 즉, weight 초기화는 네트워크가 어떤 출발지점에서 출발할 것인지를 설정해 준다. Xavier는 이러한 출발지점을 좋게 해 준다.
처음에는 weight를 RandomNormal을 사용해서 평균이 0, 분산이 1인 weight를 설정했지만, Xavier는 평균은 0, 분산은
으로 구성된다.
He Initialization for Relu
He Initialization은 Relu에 특화된 weight 초기화 방법이다.
Xavier와 비슷하게, 평균은 0, 분산은
으로 구성된다.
Code
1) load dataset
# Load mnist
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist # fashion_mnist, cifar10, cifar100
tf.enable_eager_execution()
def load_mnist():
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data = np.expand_dims(train_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
test_data = np.expand_dims(test_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
train_data, test_data = normalize(train_data, test_data) # [0~255] -> [0~1]
train_labels = to_categorical(train_labels, 10) # [N,] -> [N,10]
test_labels = to_categorical(test_labels, 10) # [N,] -> [N,10]
return train_data, train_labels, test_data, test_labels
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32) / 255.0
test_data = test_data.astype(np.float32) / 255.0
return train_data, test_data2) create network
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(
units=channel,
use_bias=True,
kernel_initializer=weight_init,
)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
# 기존에는 RandomNormal()을 사용했지만, Xavier는 glorot_uniform()을 쓴다.
# Relu용 He Initialization은 he_uniform()을 사용할 수 있다.
weight_init = tf.keras.initializers.glorot_uniform()
self.model = tf.keras.Sequential()
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for _ in range(2):
# [N, 784] -> [N, 256] -> [N, 256]
self.model.add(dense(256, weight_init))
self.model.add(relu())
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
# 함수도 마찬가지이다.
def create_model_fn(label_dim):
weight_init = tf.keras.initializers.glorot_uniform() # or he_uniform()
model = tf.keras.Sequential()
model.add(flatten())
for _ in range(2):
model.add(dense(256, weight_init))
model.add(relu())
model.add(dense(label_dim, weight_init))
return model3) define loss function
변동 없음.
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits,
labels=labels,
)
)
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)4) experiments
4-1) parameters
# dataset
train_x, train_y, test_x, test_y = load_mnist()
# parameters
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
# Graph Input using Dataset API
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()4-2) model
# Dataset Iterator
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
# Model
network = create_model(label_dim)
# Training
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)4-3) eager mode
checkpoint_prefix = "./checkpoints/mnist_xavier"
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
start_epoch = 0
start_iteration = 0
counter = 0
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(
grads_and_vars=zip(grads, network.variables),
global_step=global_step,
)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_dataset.make_one_shot_iterator().get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print(
"Epoch: [%2d] [%5d/%5d], train_loss: %.8f, "
"train_accuracy: %.4f, test_Accuracy: %.4f"
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy)
)
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + "-{}".format(counter))
# Random : 85.35 %
# Xavier : 96.50 %
# weight 초기화 만으로도 10%의 성능 향상을 보임5) full code (Weight Initialization)
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist # fashion_mnist, cifar10, cifar100
tf.enable_eager_execution()
def load_mnist():
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data = np.expand_dims(train_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
test_data = np.expand_dims(test_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
train_data, test_data = normalize(train_data, test_data) # [0~255] -> [0~1]
train_labels = to_categorical(train_labels, 10) # [N,] -> [N,10]
test_labels = to_categorical(test_labels, 10) # [N,] -> [N,10]
return train_data, train_labels, test_data, test_labels
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32) / 255.0
test_data = test_data.astype(np.float32) / 255.0
return train_data, test_data
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(
units=channel,
use_bias=True,
kernel_initializer=weight_init,
)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.glorot_uniform()
self.model = tf.keras.Sequential()
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for _ in range(2):
self.model.add(dense(256, weight_init))
self.model.add(relu())
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits,
labels=labels,
)
)
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)
# --- main ---
train_x, train_y, test_x, test_y = load_mnist()
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
network = create_model(label_dim)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
checkpoint_prefix = "./checkpoints/mnist_xavier"
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
start_epoch = 0
start_iteration = 0
counter = 0
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(
grads_and_vars=zip(grads, network.variables),
global_step=global_step,
)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_iterator.get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print(
"Epoch: [%2d] [%5d/%5d], train_loss: %.8f, "
"train_accuracy: %.4f, test_Accuracy: %.4f"
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy)
)
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + "-{}".format(counter))Lec-10 3. Dropout
Dropout

가장 왼쪽은 3개, 가운데는 7개, 마지막은 모든 training sample을 전부 맞췄다.
⇒ 즉, 왼쪽부터 under-fitting, good, over-fitting이 되었다고 할 수 있다.
⇒ 따라서 under-fitting은 train 정확도가 매우 낮고, over-fitting은 그 정확도가 너무 높아서 발생하는 문제이다.
⇒ 이에 따라, under-fitting은 train 데이터도 제대로 맞추지 못했으니 test 데이터도 당연히 맞추지 못하지만, over-fitting은 train 데이터를 잘 맞췄는데도 test 데이터를 제대로 맞추지 못한다.
⇒ 따라서 dropout을 통해 적절하게 fitting 되도록 맞춰줄 필요가 있다.
Dropout
: neural network에서, network는 모든 노드를 활용해서 학습을 진행하게 된다. 이때 일부 노드를 끄고 학습을 진행하는 것을 말한다.
즉, 랜덤으로 노드를 꺼서 노드의 일부분만 학습을 진행한다.
⇒ 바꿔 말하면, 기존에는 이미지 전체를 가지고 학습했다면, dropout은 이미지의 일부만 가지고 학습하는 것이다.
= regularization 기법.
Code
1) load
기존 mnist 코드와 동일.
2) create network
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(
units=channel,
use_bias=True,
kernel_initializer=weight_init,
)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
# dropout 함수 추가. rate : 노드를 끌 비율을 설정함. (0~1)
def dropout(rate):
return tf.keras.layers.Dropout(rate)
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.glorot_uniform()
self.model = tf.keras.Sequential()
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for _ in range(2):
# [N, 784] -> [N, 256] -> [N, 256]
self.model.add(dense(256, weight_init))
self.model.add(relu())
self.model.add(dropout(rate=0.5)) # 노드 dropout
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
# class가 아닌 네트워크
def create_model_fn(label_dim):
weight_init = tf.keras.initializers.glorot_uniform()
model = tf.keras.Sequential()
model.add(flatten())
for _ in range(2):
model.add(dense(256, weight_init))
model.add(relu())
model.add(dropout(rate=0.5))
model.add(dense(label_dim, weight_init))
return model3) define loss function
def loss_fn(model, images, labels):
logits = model(images, training=True) # 테스트 여부 = dropout 여부
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits,
labels=labels,
)
)
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False) # dropout 사용 X
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)4) experiments
4-1) parameters
# dataset
train_x, train_y, test_x, test_y = load_mnist()
# parameters
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
# Graph Input using Dataset API
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()4-2) model
# Dataset Iterator
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
# Model
network = create_model(label_dim)
# Training
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)4-3) eager mode
checkpoint_prefix = "./checkpoints/mnist_dropout"
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
start_epoch = 0
start_iteration = 0
counter = 0
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(
grads_and_vars=zip(grads, network.variables),
global_step=global_step,
)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_dataset.make_one_shot_iterator().get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print(
"Epoch: [%2d] [%5d/%5d], train_loss: %.8f, "
"train_accuracy: %.4f, test_Accuracy: %.4f"
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy)
)
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + "-{}".format(counter))5) full code (Dropout)
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist # fashion_mnist, cifar10, cifar100
tf.enable_eager_execution()
def load_mnist():
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data = np.expand_dims(train_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
test_data = np.expand_dims(test_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
train_data, test_data = normalize(train_data, test_data) # [0~255] -> [0~1]
train_labels = to_categorical(train_labels, 10) # [N,] -> [N,10]
test_labels = to_categorical(test_labels, 10) # [N,] -> [N,10]
return train_data, train_labels, test_data, test_labels
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32) / 255.0
test_data = test_data.astype(np.float32) / 255.0
return train_data, test_data
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(
units=channel,
use_bias=True,
kernel_initializer=weight_init,
)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
def dropout(rate):
return tf.keras.layers.Dropout(rate)
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.glorot_uniform()
self.model = tf.keras.Sequential()
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for _ in range(2):
self.model.add(dense(256, weight_init))
self.model.add(relu())
self.model.add(dropout(rate=0.5))
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits,
labels=labels,
)
)
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)
# --- main ---
train_x, train_y, test_x, test_y = load_mnist()
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
network = create_model(label_dim)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
checkpoint_prefix = "./checkpoints/mnist_dropout"
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
start_epoch = 0
start_iteration = 0
counter = 0
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(
grads_and_vars=zip(grads, network.variables),
global_step=global_step,
)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_iterator.get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print(
"Epoch: [%2d] [%5d/%5d], train_loss: %.8f, "
"train_accuracy: %.4f, test_Accuracy: %.4f"
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy)
)
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + "-{}".format(counter))Lec-10 4. Batch Normalization
Batch Normalization
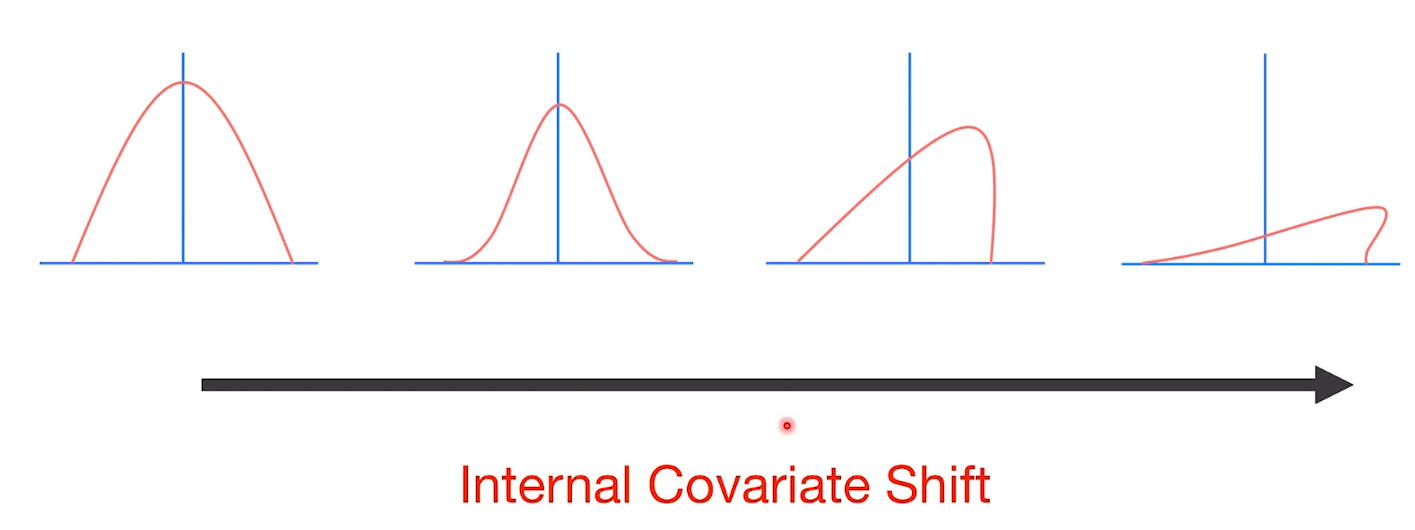
어떤 이미지가 네트워크를 지나면서, 처음 이미지의 distribution이 점차 망가지게 된다.
⇒ 이러한 분포의 변형을 Internal Covariate Shift라고 하고, Batch Normalization은 이를 방지하는 기법이다.
⇒ 즉, layer의 input으로 들어오는 distribution을 계속 Normalization 시켜서 일정한 이미지로 만든다.
배치 정규화 수식은 다음과 같다.
⇒ input 에 대해서 배치들의 평균 , 배치들의 분산 를 사용해서 Normalization한다.
⇒ 학습이 되는 데이터들로 를 만들어내서 를 layer의 input으로 다시 추가시킨다.
Code
1) load
기존 mnist 코드와 동일.
2) create network
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(
units=channel,
use_bias=True,
kernel_initializer=weight_init,
)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
# BatchNormalization() 사용
def batch_norm():
return tf.keras.layers.BatchNormalization()
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.glorot_uniform()
self.model = tf.keras.Sequential()
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for _ in range(2):
# [N, 784] -> [N, 256] -> [N, 256]
self.model.add(dense(256, weight_init))
self.model.add(batch_norm()) # batch_norm
self.model.add(relu())
# 기존과는 달리, batch_norm 다음에 relu가 오고 있다.
# 이는 일반적으로 layer -> norm -> activation 혹은
# norm -> activation -> layer 의 순서를 사용하기 때문이다.
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
# class가 아닌 네트워크
def create_model_fn(label_dim):
weight_init = tf.keras.initializers.glorot_uniform()
model = tf.keras.Sequential()
model.add(flatten())
for _ in range(2):
model.add(dense(256, weight_init))
model.add(batch_norm())
model.add(relu())
model.add(dense(label_dim, weight_init))
return model3) define loss function
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits,
labels=labels,
)
)
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)4) experiments
4-1) parameters
# dataset
train_x, train_y, test_x, test_y = load_mnist()
# parameters
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
# Graph Input using Dataset API
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()4-2) model
# Dataset Iterator
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
# Model
network = create_model(label_dim)
# Training
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)4-3) eager mode
checkpoint_prefix = "./checkpoints/mnist_batchnorm"
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
start_epoch = 0
start_iteration = 0
counter = 0
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(
grads_and_vars=zip(grads, network.variables),
global_step=global_step,
)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_dataset.make_one_shot_iterator().get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print(
"Epoch: [%2d] [%5d/%5d], train_loss: %.8f, "
"train_accuracy: %.4f, test_Accuracy: %.4f"
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy)
)
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + "-{}".format(counter))5) full code (Batch Normalization)
import tensorflow as tf
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist # fashion_mnist, cifar10, cifar100
tf.enable_eager_execution()
def load_mnist():
(train_data, train_labels), (test_data, test_labels) = mnist.load_data()
train_data = np.expand_dims(train_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
test_data = np.expand_dims(test_data, axis=-1) # [N, 28, 28] -> [N, 28, 28, 1]
train_data, test_data = normalize(train_data, test_data) # [0~255] -> [0~1]
train_labels = to_categorical(train_labels, 10) # [N,] -> [N,10]
test_labels = to_categorical(test_labels, 10) # [N,] -> [N,10]
return train_data, train_labels, test_data, test_labels
def normalize(train_data, test_data):
train_data = train_data.astype(np.float32) / 255.0
test_data = test_data.astype(np.float32) / 255.0
return train_data, test_data
def flatten():
return tf.keras.layers.Flatten()
def dense(channel, weight_init):
return tf.keras.layers.Dense(
units=channel,
use_bias=True,
kernel_initializer=weight_init,
)
def relu():
return tf.keras.layers.Activation(tf.keras.activations.relu)
def batch_norm():
return tf.keras.layers.BatchNormalization()
class create_model(tf.keras.Model):
def __init__(self, label_dim):
super(create_model, self).__init__()
weight_init = tf.keras.initializers.glorot_uniform()
self.model = tf.keras.Sequential()
self.model.add(flatten()) # [N, 28, 28, 1] -> [N, 784]
for _ in range(2):
self.model.add(dense(256, weight_init))
self.model.add(batch_norm())
self.model.add(relu())
self.model.add(dense(label_dim, weight_init)) # [N, 256] -> [N, 10]
def call(self, x, training=None, mask=None):
x = self.model(x)
return x
def loss_fn(model, images, labels):
logits = model(images, training=True)
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits_v2(
logits=logits,
labels=labels,
)
)
return loss
def accuracy_fn(model, images, labels):
logits = model(images, training=False)
prediction = tf.equal(tf.argmax(logits, -1), tf.argmax(labels, -1))
accuracy = tf.reduce_mean(tf.cast(prediction, tf.float32))
return accuracy
def grad(model, images, labels):
with tf.GradientTape() as tape:
loss = loss_fn(model, images, labels)
return tape.gradient(loss, model.variables)
# --- main ---
train_x, train_y, test_x, test_y = load_mnist()
learning_rate = 0.001
batch_size = 128
training_epochs = 1
training_iterations = len(train_x) // batch_size
label_dim = 10
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=batch_size).\
batch(batch_size).\
repeat()
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).\
shuffle(buffer_size=100000).\
prefetch(buffer_size=len(test_x)).\
batch(len(test_x)).\
repeat()
train_iterator = train_dataset.make_one_shot_iterator()
test_iterator = test_dataset.make_one_shot_iterator()
network = create_model(label_dim)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
checkpoint_prefix = "./checkpoints/mnist_batchnorm"
checkpoint = tf.train.Checkpoint(dnn=network)
global_step = tf.train.create_global_step()
start_epoch = 0
start_iteration = 0
counter = 0
for epoch in range(start_epoch, training_epochs):
for idx in range(start_iteration, training_iterations):
train_input, train_label = train_iterator.get_next()
grads = grad(network, train_input, train_label)
optimizer.apply_gradients(
grads_and_vars=zip(grads, network.variables),
global_step=global_step,
)
train_loss = loss_fn(network, train_input, train_label)
train_accuracy = accuracy_fn(network, train_input, train_label)
test_input, test_label = test_iterator.get_next()
test_accuracy = accuracy_fn(network, test_input, test_label)
print(
"Epoch: [%2d] [%5d/%5d], train_loss: %.8f, "
"train_accuracy: %.4f, test_Accuracy: %.4f"
% (epoch, idx, training_iterations, train_loss, train_accuracy, test_accuracy)
)
counter += 1
checkpoint.save(file_prefix=checkpoint_prefix + "-{}".format(counter))모두를 위한 딥러닝 강좌 2
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
