1. ConvNet의 Conv 레이어 만들기
CNN introduction
기본적인 네트워크는 여러 형태가 있다.
가령 입력을 받고, 각 레이어를 쭉 이어나가서 전체가 연결되는 형태인 fully connected 가 있을 수 있다.
또 다른 형태로는, 입력을 여러 개로 나누고 하나로 합친 뒤 내보내는 형태가 있을 수 있다.
바로 이것이 Convolutional Neural Network의 기본 아이디어이다.
Convolutional Neural Network
고양이가 그림을 볼 때, 고양이의 모든 뉴런이 동시에 동작하는 것이 아니라 그림의 어떤 부분에 대해서만 반응하는 것을 알게 되었다.
⇒ 즉, 각 뉴런이 이미지의 일부분에만 반응한다. = 입력을 나누어 받는다.
시작점
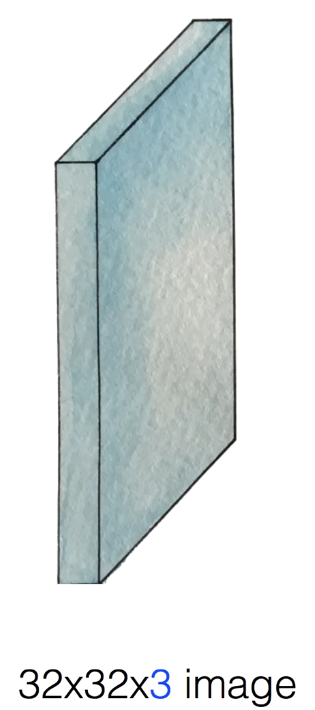
처음 이미지는 width * height * depth 3개로 이루어졌다.
여기서는 32 * 32 * 3이라고 가정하자.
이때 depth는 컬러 이미지이므로 3이다.
focus
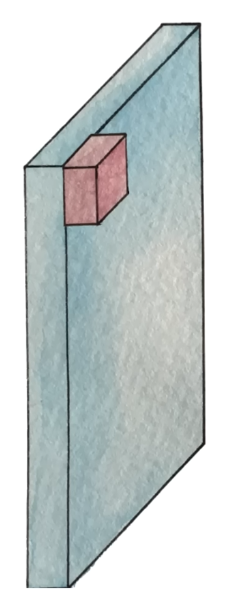
이제 이 전체 이미지를 하나의 입력으로 받지 않고, 이미지의 일부분만 가지고 처리한다.
⇒ 이 이미지의 일부분을 filter라고 한다.
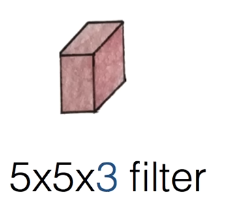
이 필터는 5 * 5 * 3의 값을 가진다.
get one number
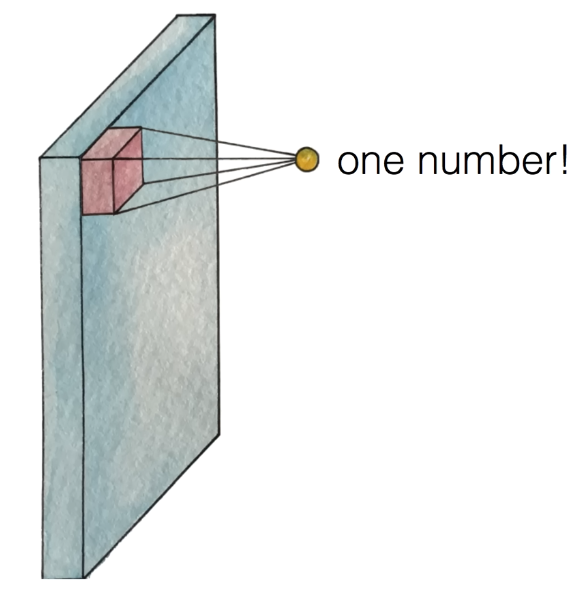
필터는 궁극적으로 하나의 값을 만들어낸다.
⇒ 그럼 5 * 5 * 3의 값을 가진 필터에서 어떻게 하나의 값을 만들어낼까?
하나의 값은 대략 다음과 같이 구할 수 있다.
one number = Wx + b- 또는
ReLU(Wx + b)
즉, Wx + b의 식
(W1x1 + W2x2 + W3x3 + ... + b)
을 계산하면 하나의 값이 나오게 되고, 여기에 추가로 ReLU를 붙여 사용할 수도 있다.
another area
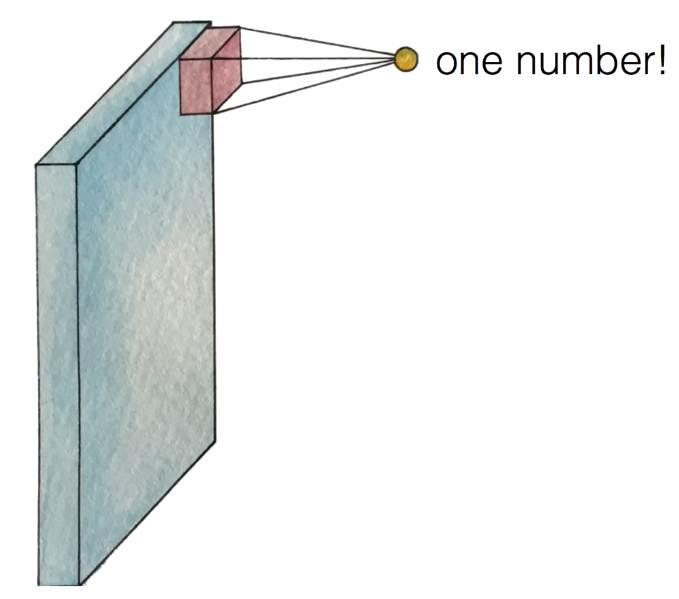
이제 동일한 를 가진 필터를 움직여 가면서 각 위치에서 값을 모으게 된다.
⇒ 그럼 총 몇 개의 값을 가지게 될까?
small example
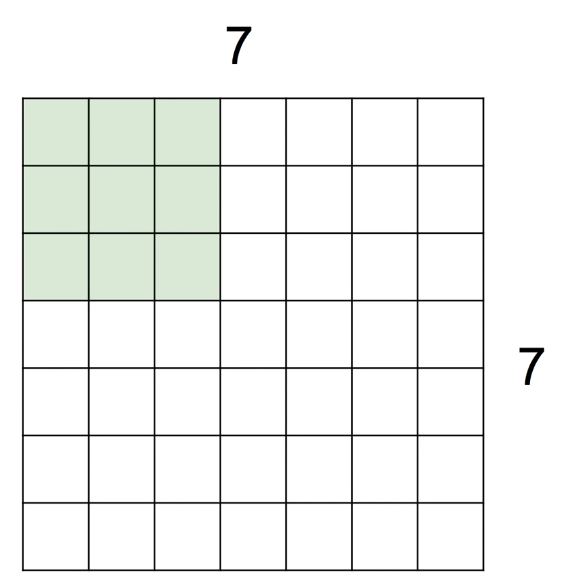
7 * 7의 단순한 이미지로 생각해보자.
여기서 필터는 3 * 3 필터를 사용한다.
이 필터를 옆과 아래로 한 번에 1칸씩 움직이면 몇 개의 output이 나올까?
이 3 * 3 필터는 옆으로 5번, 아래로 5번 갈 수 있다.
⇒ 즉, 5 * 5의 output이 나온다.
여기서 우리는 이 필터를 옆으로 1칸씩 움직였는데,
이때 움직인 거리를 stride라고 부른다.
이번에는 stride를 2로 설정해보자.
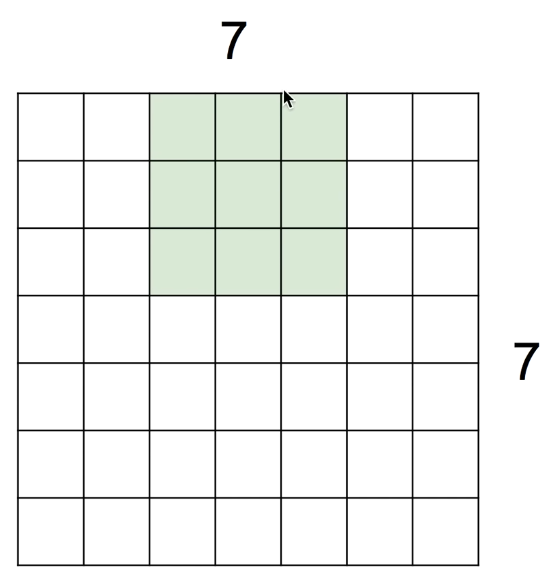
⇒ filter는 옆으로 3칸, 아래로 3칸 움직일 수 있고, 3 * 3의 output이 나온다.
output size
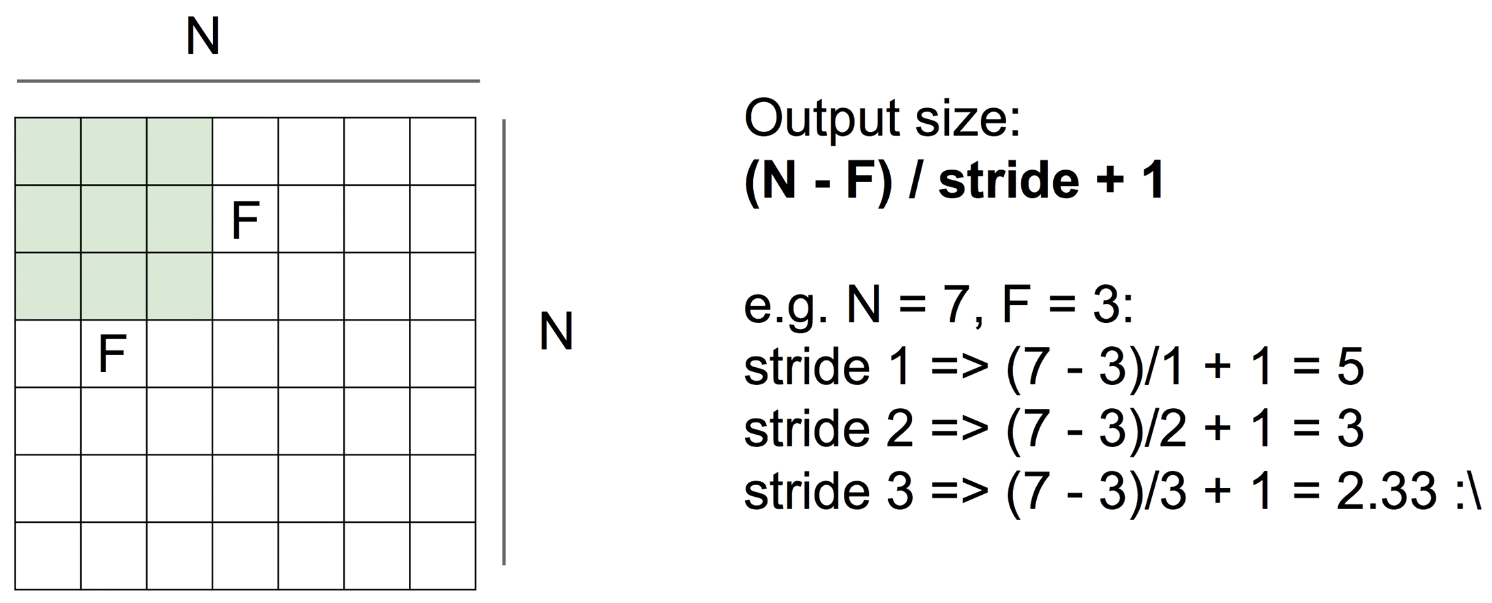
정리하자면, 의 입력에서 의 필터가 있을 때, stride 별 output의 개수는 다음과 같다.
- Output size:
예시: , 일 때
-
stride 1 :
-
stride 2 :
-
stride 3 :
이렇게, stride가 크면 클수록 output의 개수도 줄어든다.
⇒ 이렇게 큰 이미지를 줄이면 줄일수록 어떤 정보는 잃어버리게 된다.
padding
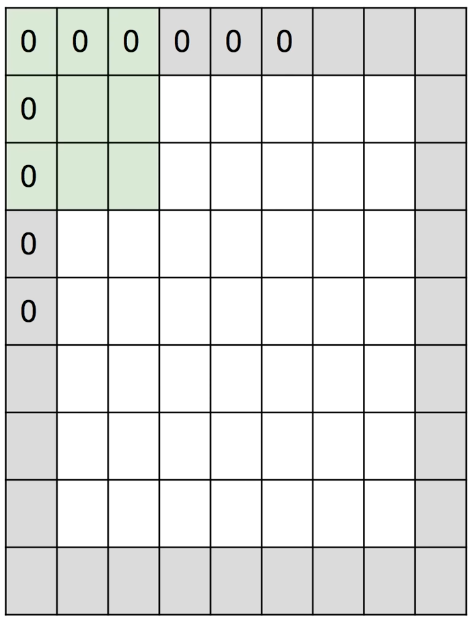
위와 같이, 이미지를 줄이면 손상이 발생하게 된다.
따라서 이러한 손상을 줄이기 위해 padding이란 걸 사용하게 된다.
padding은 가장자리를 따라 0을 두르는 것이다.
이는 다음과 같은 효과가 있다.
- 이미지가 급격하게 작아지는 것을 방지
- 여기가 모서리라는 것을 알려주는 역할
따라서 기존의 7 * 7 이미지에 3 * 3 필터, stride 1, 그리고 1의 padding을 추가하게 되면 나오는 output은 다음과 같다.
- 입력 크기:
- padding 1을 양쪽에 추가 ⇒ 실제 계산 크기:
- 식:
따라서 7 * 7의 output이 나오게 된다.
⇒ 즉, 입력과 같은 사이즈의 이미지가 나오게 된다.
swiping entire image
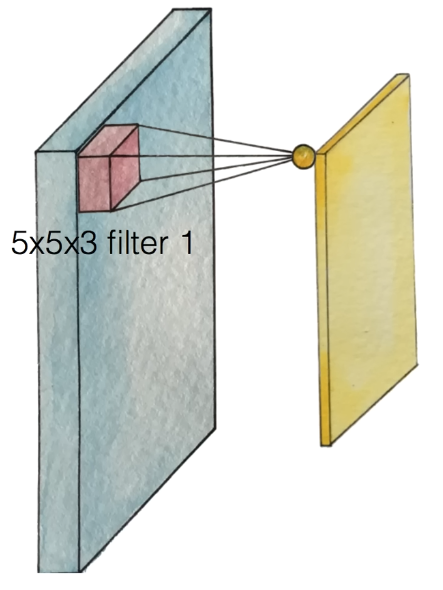
filter 1으로 다음과 같은 output을 만들어 내었다.
이제 다른 값을 가진 filter 2를 사용하자.
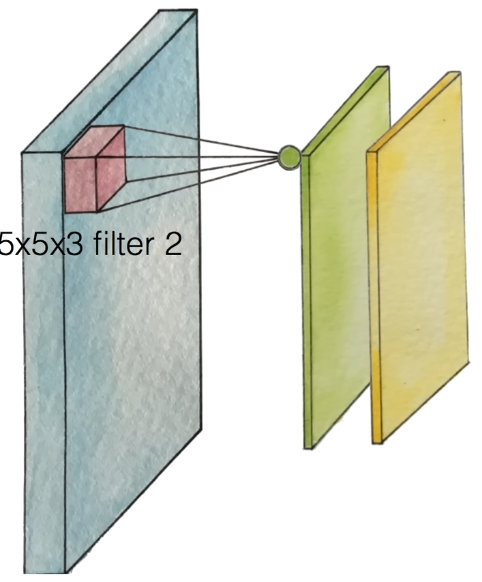
이 과정을 반복하면 다음과 같은 그림이 나온다.
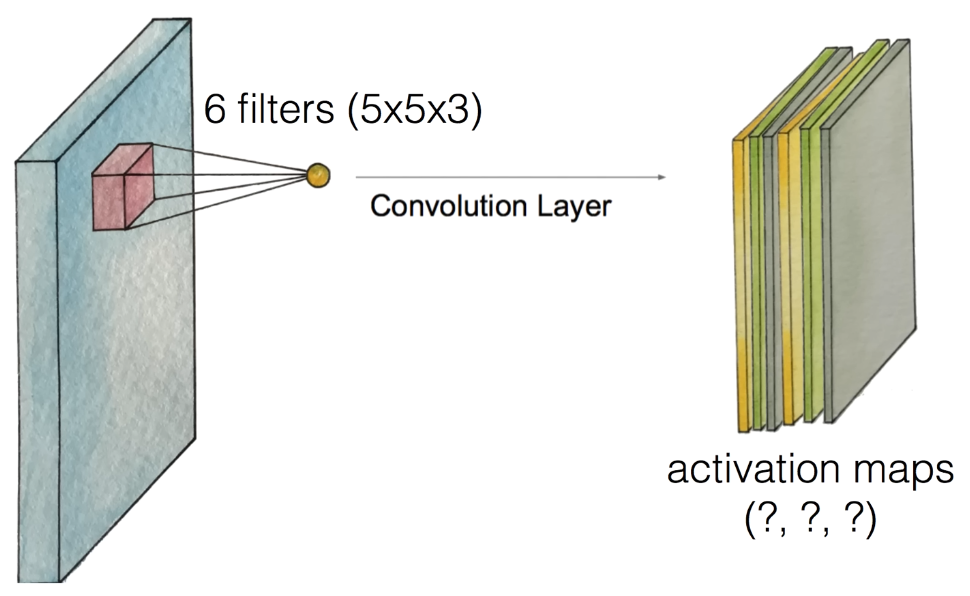
각각의 필터는 모두 다른 값을 가지고 있기 때문에
모든 convolution layer의 activation map은 서로 다른 값을 가지게 된다.
이미지에서 보듯, 6개의 5 * 5 * 3 필터를 적용하였기 때문에 activation map의 depth는 6이 된다.
⇒ depth의 개수는 filter의 개수를 따라가게 된다.
나머지 width와 height를 계산하면 28 * 28이 된다.
Convolution layers
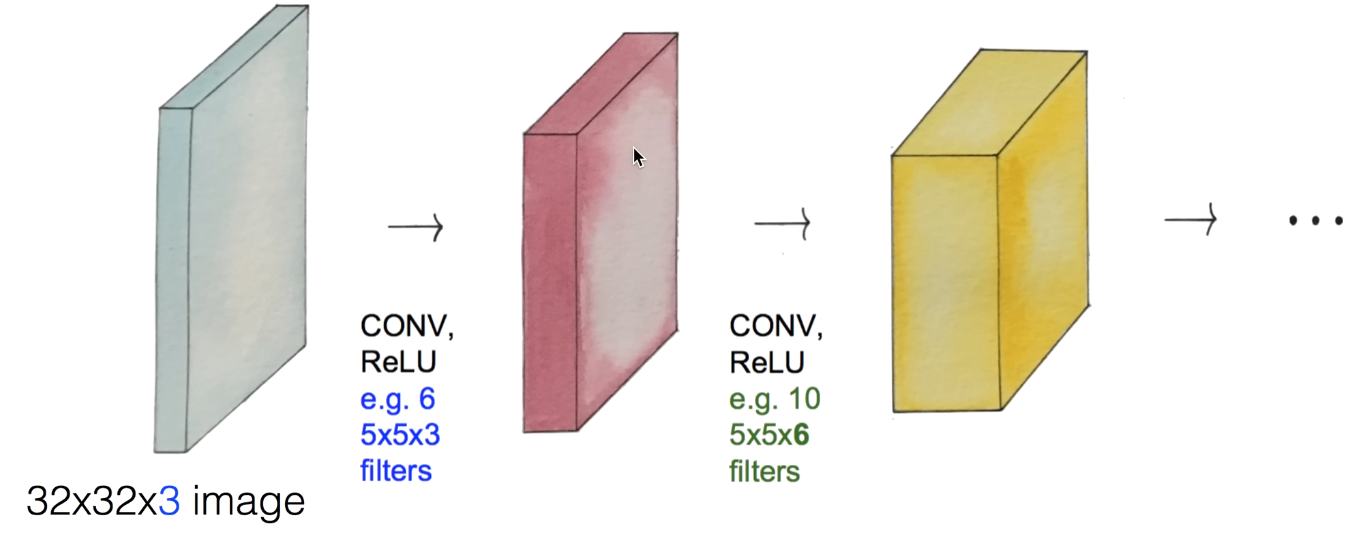
그리고 이런 과정을 한 번만 하는 것이 아닌, 여러 번 실행하게 되면 위 그림과 같은 모양이 나온다.
즉, 결과물로 나온 activation map에 다시 Conv, ReLU, filter 를 적용시켜
layer를 계속 쌓아가게 된다.
2. ConvNet Max pooling과 Full Network
pooling layer (sampling)
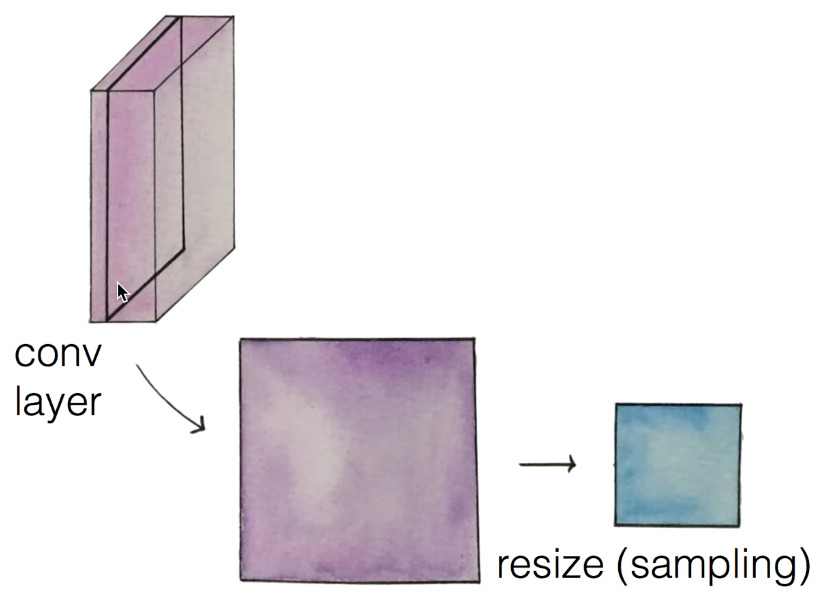
conv layer에서 층 하나(activation map)를 뽑아내어 사이즈를 작게 조절한다.
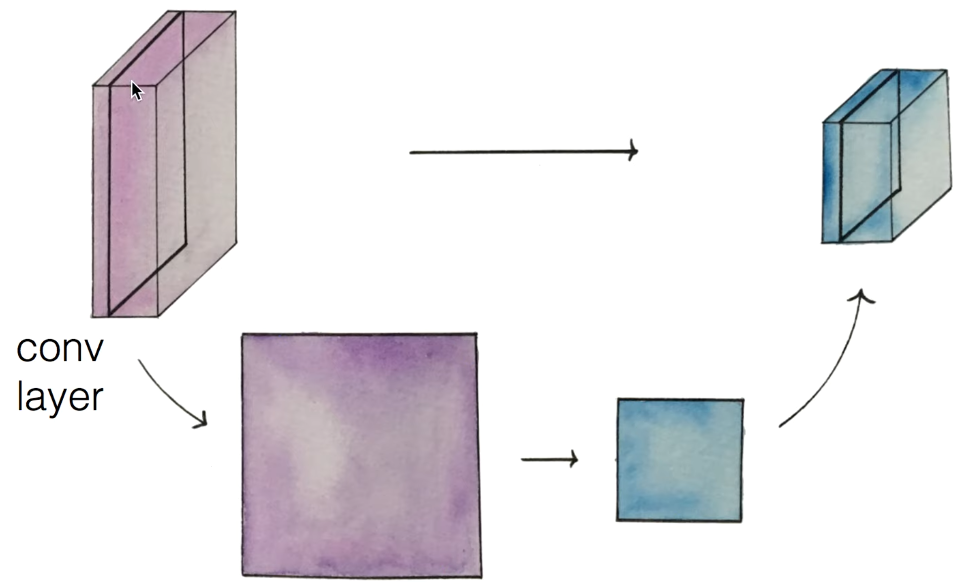
이렇게 조절된 layer를 다시 쌓아서 새로운 layer를 만든다.
max pooling
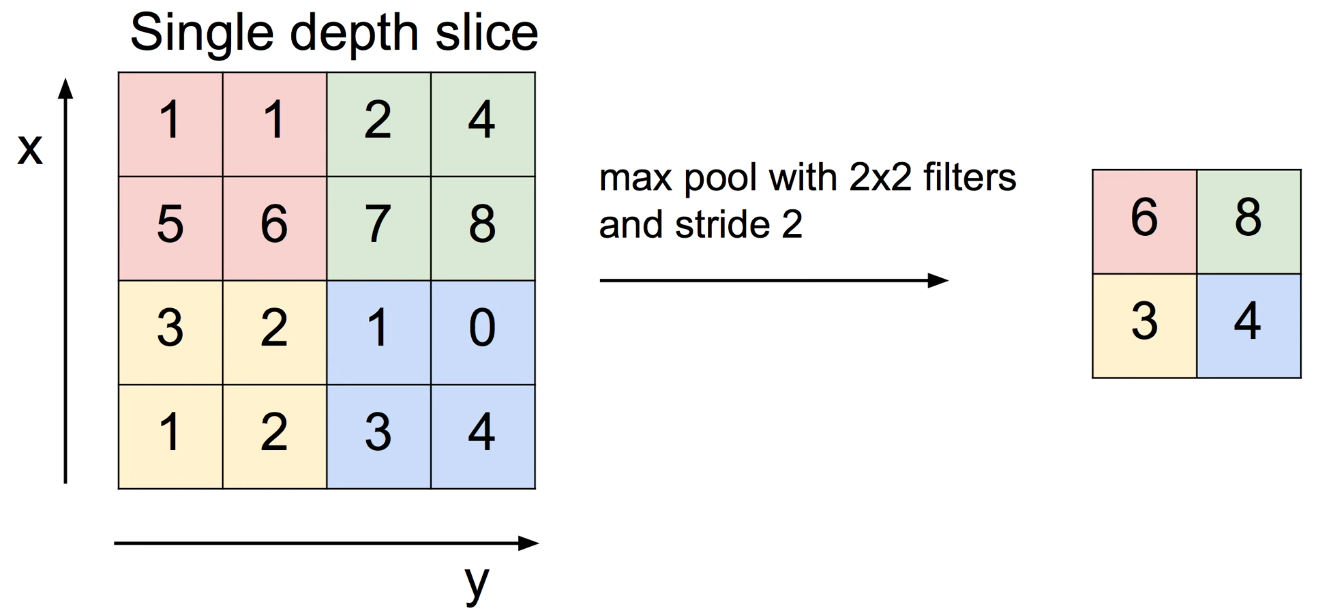
다음 이미지와 같이, 4 * 4 이미지에 2 * 2 필터, stride 2를 적용하면 2 * 2의 출력이 나온다.
그렇다면 각 필터에서 어떤 값을 output으로 옮겨야 하는가?
⇒ 가장 자주 사용되는 방법이 max pooling이라 부르는 방법으로, 각 영역에서 가장 큰 값을 옮기는 것이다.
즉, pooling layer의 값은 각 필터 영역마다 가장 큰 값인 6, 8, 3, 4를 가지게 된다.
3. ConvNet의 활용예
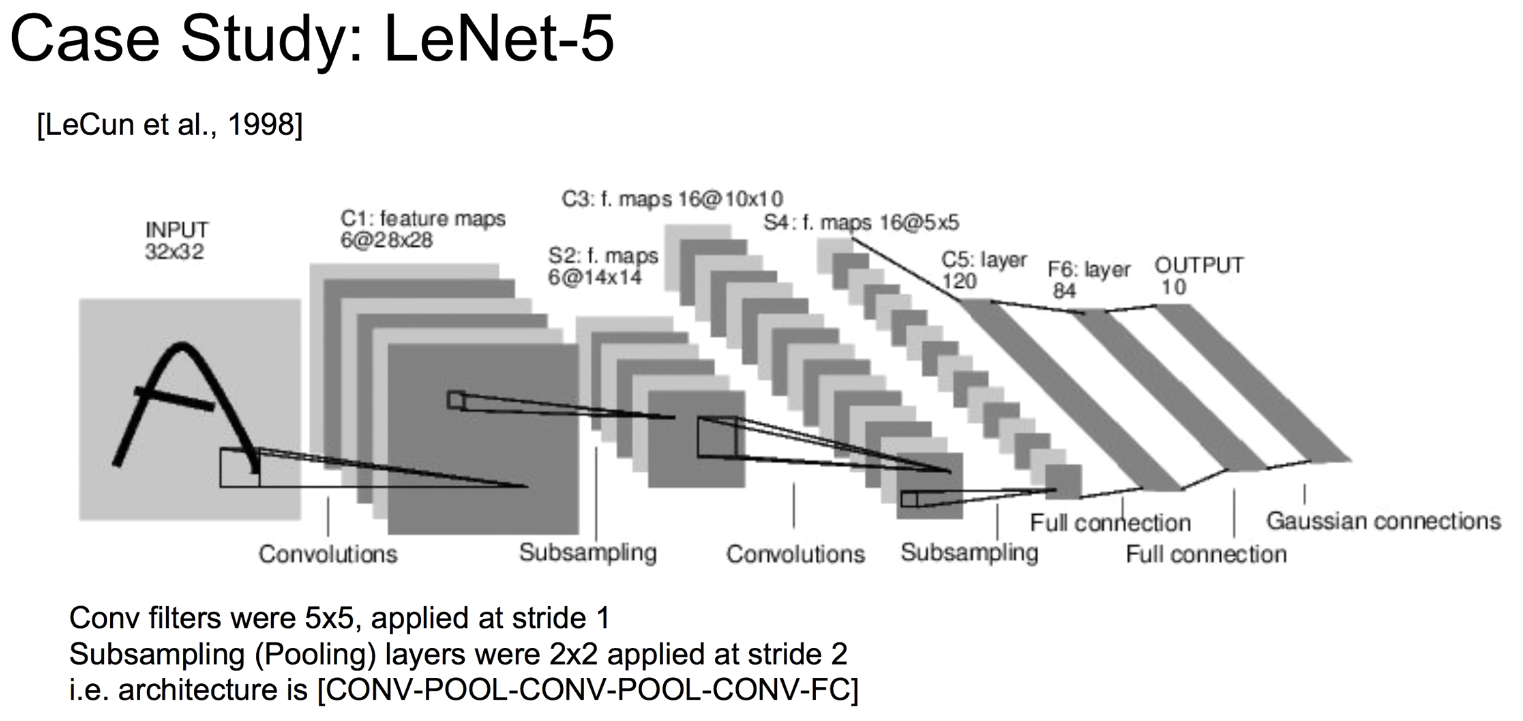
- LeNet-5
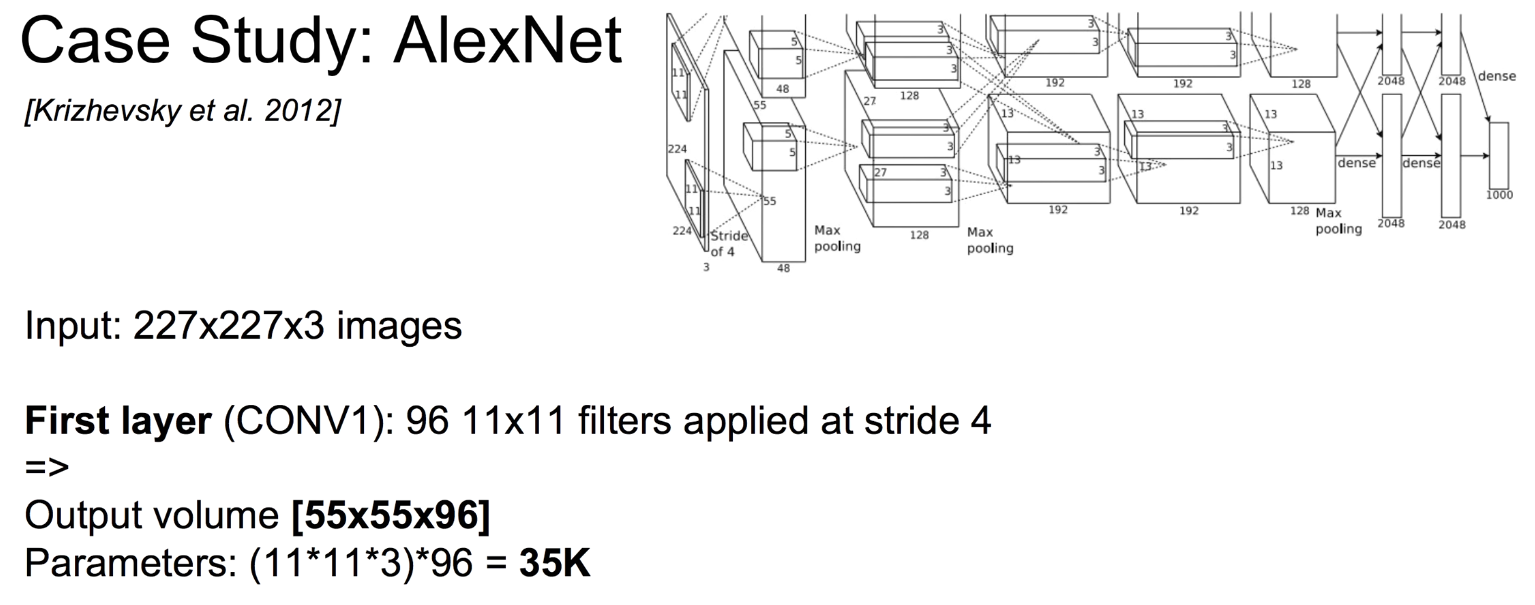
- AlexNet

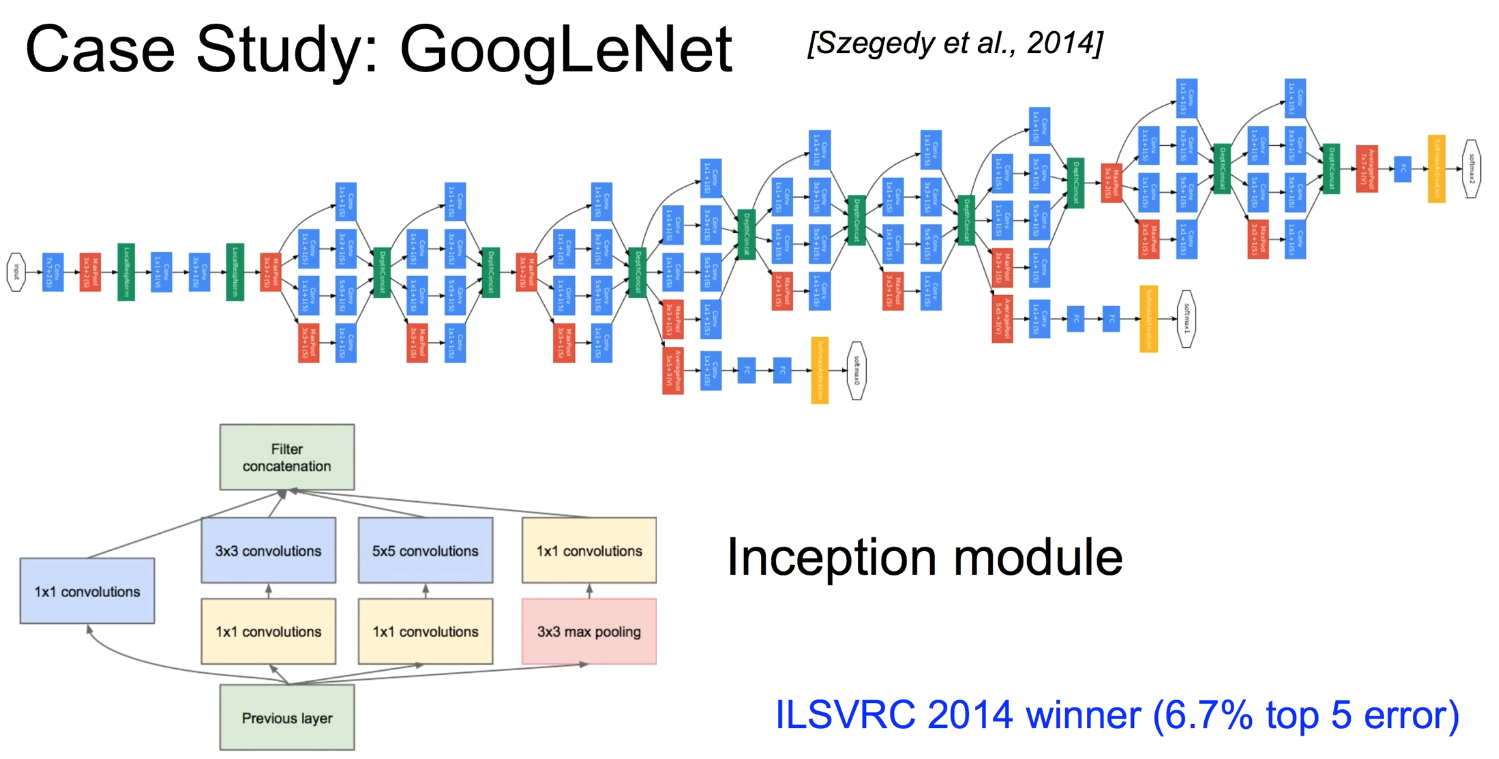
- GoogleLeNet
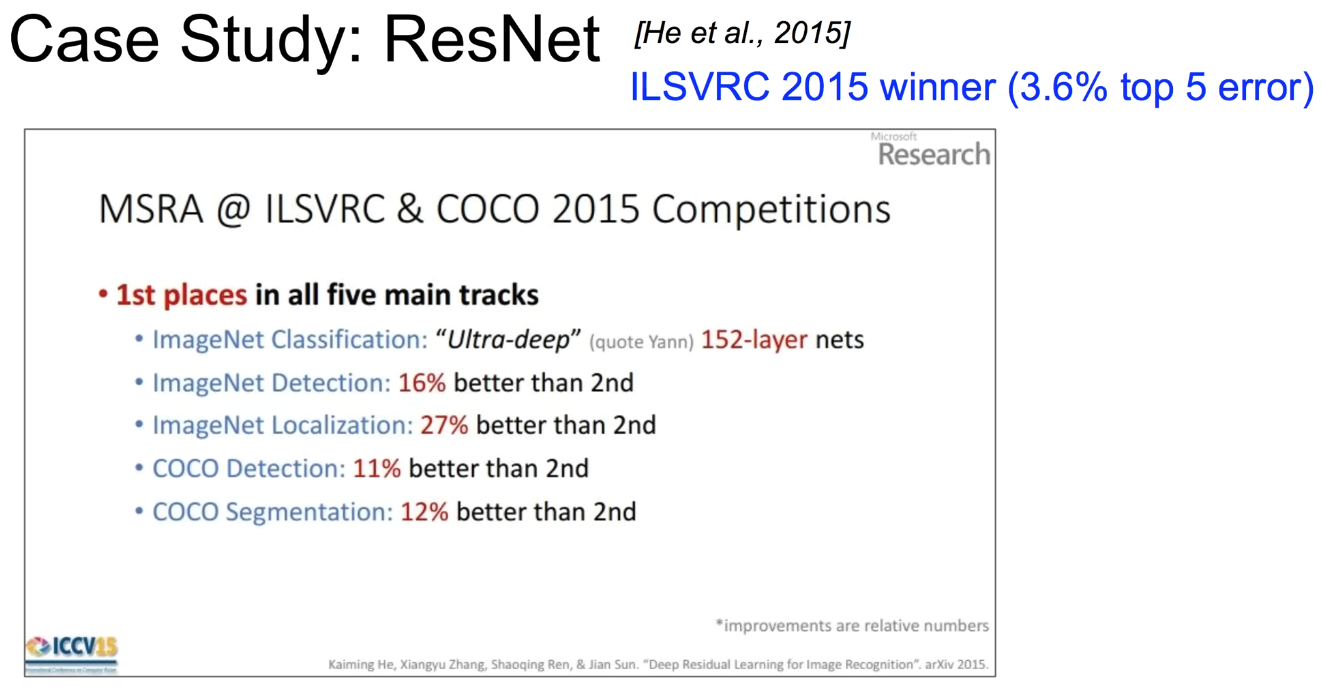
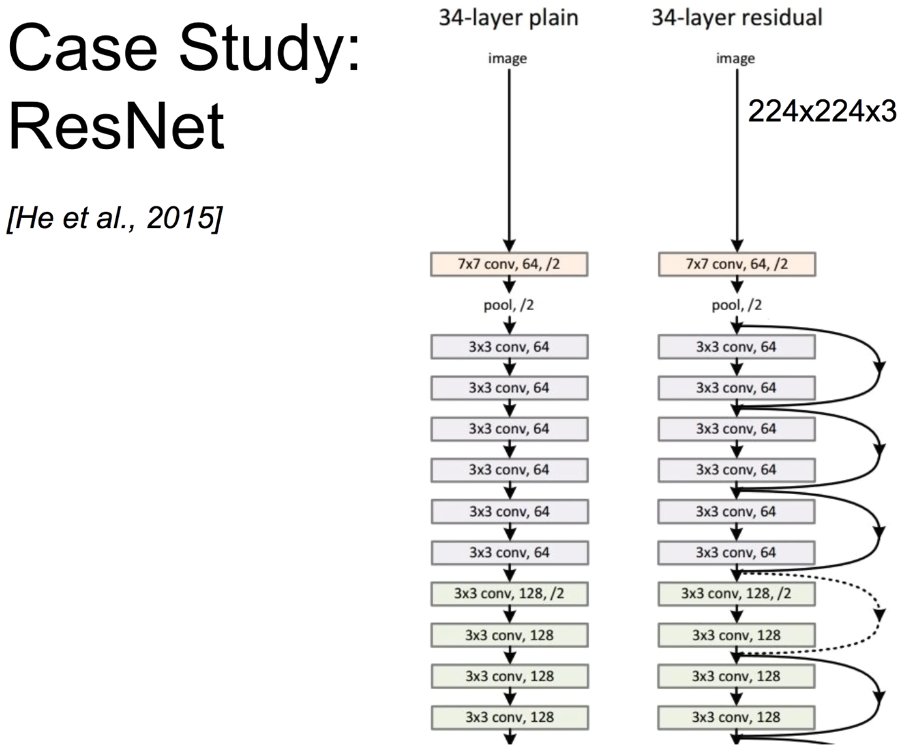
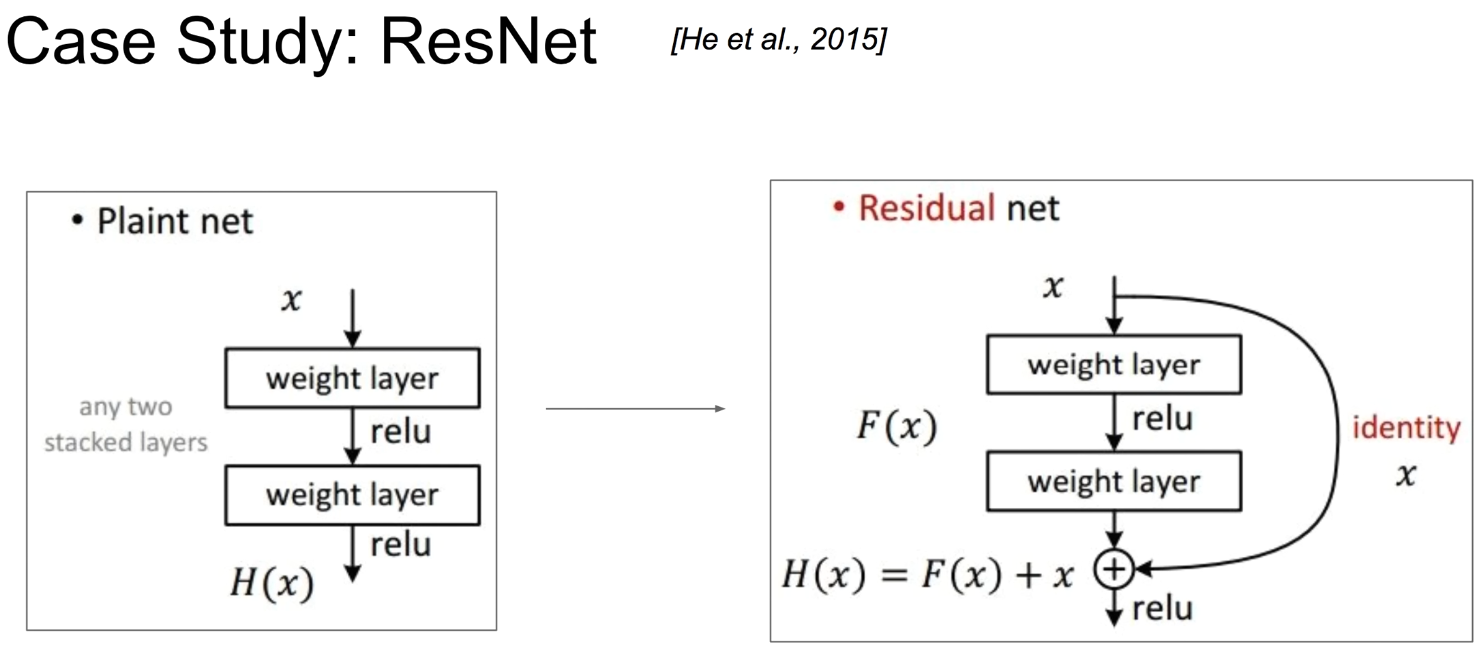
- ResNet
모두를 위한 딥러닝 강좌 2
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
