RNN의 다양한 활용법
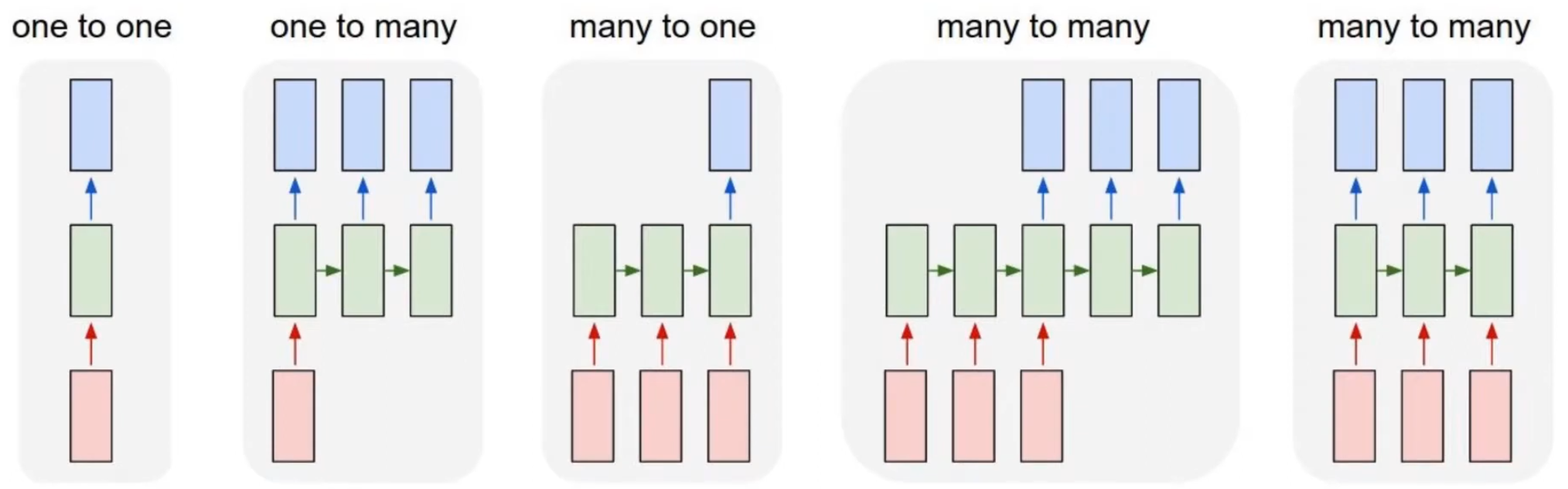
RNN은 다음과 같이 다양한 형태로 활용할 수 있다.
- One to Many : 특정 이미지를 입력으로 받아 캡션으로 만드는 이미지 캡셔닝 분야에 활용
- Many to Many : 문장을 입력으로 받아 문장을 출력하는 NN Translation, 문장을 받아 형태소를 분석하는 형태소 분석기로 활용 가능.
- Many to One : 자연어 처리 분야에서 어떤 문장 혹은 단어를 RNN으로 인코딩하고 해당 문장 또는 단어의 감정을 분류하는데 활용됨.
Many to One 이란?
만약 "This movie is good" 이라는 문장이 주어진다면, 문장의 polarity를 파악하는 문제를 푼다고 해보자.
['This movie is good']
먼저 문장을 word의 시퀀스라고 생각하고 문장을 단어 단위로 분해한다.
['This', 'movie', 'is', 'good']
=> Tokenization
이렇게 문장을 단어 단위로 토큰화 시키고 나면, RNN을 활용하여 각각의 토큰을 읽고 마지막 토큰을 읽었을 때 polarity를 classification 방식으로 활용하는 것이 Many to One 방식 중 하나이다.
['This', 'movie', 'is', 'good']
=> Classification
Positive
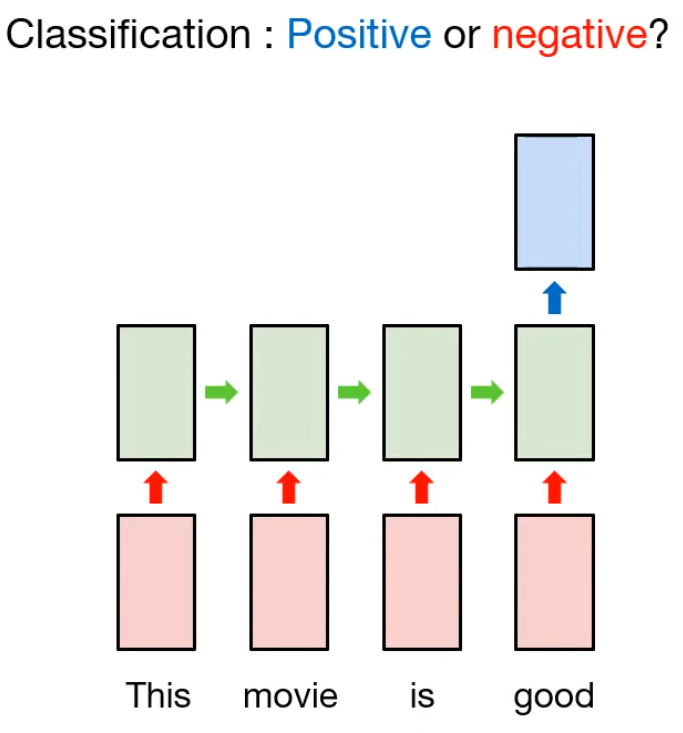
위 예제를 좀 더 자세히 살펴보자.
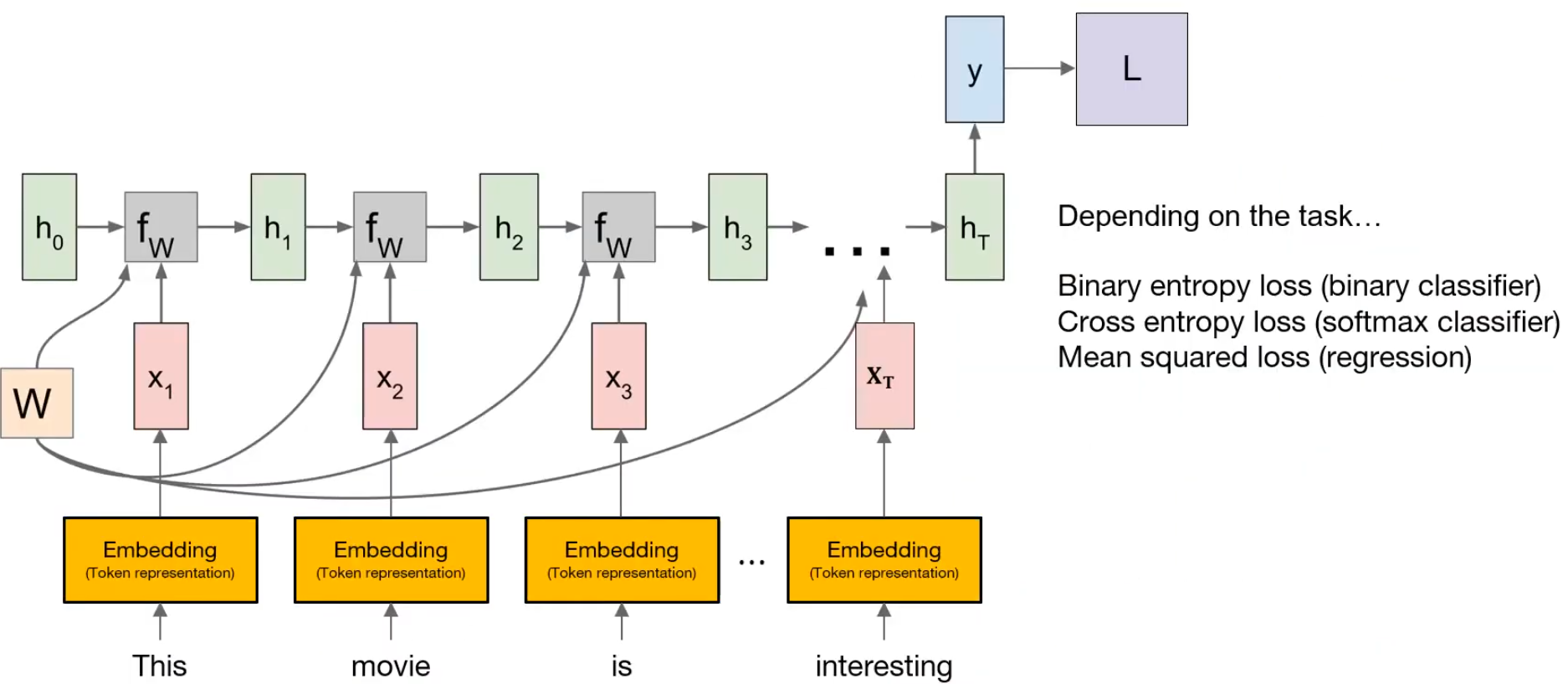
문장을 단어 단위로 Tokenization 했을 때 Token인 단어는 어떤 숫자가 아니기 때문에 RNN으로 처리할 수 없다.
따라서 일반적으로 자연어 처리에서 RNN을 활용할 때 토큰을 Numeric vector로 바꿔주는 Embedding 레이어가 존재하며, 이 Embedding 레이어는 활용하는 방식에 따라서 학습을 할 수도 있고 아닐 수도 있다.
Embedding 레이어가 각각의 토큰을 RNN이 처리할 수 있도록 만들어주면, RNN은 토큰을 순서대로 읽어들이고 마지막 토큰을 읽었을 때 나온 출력과 정답 간의 loss를 계산할 수 있다.
이 loss를 기반으로 backpropagation을 통해 RNN을 학습할 수 있다.
구현 예제
1. 데이터 준비
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.sequence import pad_sequences
# example data
words = ['good', 'bad', 'worse', 'so good']
y_data = [1, 0, 0, 1]
# creating a token dictionary
# 각 예제 단어를 Character의 시퀀스로 간주하고 문제를 풀기 위해
# 토큰인 character를 integer index로 매핑하고 있는 토큰의 사전을 만들어야 한다.
char_set = ['<pad>'] + sorted(list(set(''.join(words))))
# pad 라는 토큰이 추가되는 이유는 워드를 character의 시퀀스로 간주했을 때 각각의 시퀀스의 길이가 다르기 때문이다.
# CNN, RNN 을 막론하고 배치 단위 연산이 효율적이다.
# 이를 위해 RNN 구현 시 데이터가 서로 다른 시퀀스의 길이를 가진 경우 길이를 맞추기 위해
# pad와 같은 특별한 토큰을 도입하여 데이터의 시퀀스를 맞춰준다.
idx2char = {idx: char for idx, char in enumerate(char_set)}
char2idx = {char: idx for idx, char in enumerate(char_set)}
print(char_set)
print(idx2char)
print(char2idx)=> 결과
['<pad>', ' ', 'a', 'b', 'd', 'e', 'g', 'o', 'r', 's', 'w']
{0: '<pad>', 1: ' ', 2: 'a', 3: 'b', 4: 'd', 5: 'e', 6: 'g', 7: 'o', 8: 'r', 9: 's', 10: 'w'} # 각각의 토큰이 integer index와 매핑되어 있다.
{'<pad>': 0, ' ': 1, 'a': 2, 'b': 3, 'd': 4, 'e': 5, 'g': 6, 'o': 7, 'r': 8, 's': 9, 'w': 10}2. 모델 생성
# converting sequence of tokens to sequence of indices
x_data = list(map(lambda word: [char2idx.get(char) for char in word], words)) # 토큰 사전을 기반으로 단어를 integer index의 시퀀스로 변환할 수 있다.
x_data_len = list(map(lambda word: len(word), x_data))
print(x_data)
print(x_data_len)
# 출력 결과
# [[6, 7, 7, 4], [3, 2, 4], [10, 7, 8, 9, 5], [9, 7, 1, 6, 7, 7, 4]]
# [4, 3, 5, 7]
# 각각의 워드가 integer의 index의 시퀀스로 변환되었다.
# padding the sequence of indices
# 변환한 데이터를 pad_sequences 함수를 통해서 max_sequence 변수가 가진 값만큼의 길이로 변환한 데이터를 padding 한다.
max_sequence = 10
x_data = pad_sequences(sequences=x_data, maxlen=max_sequence, padding='post', truncating='post')
# checking data
print(x_data)
print(x_data_len)
print(y_data)
# 출력 결과
# [[ 6 7 7 4 0 0 0 0 0 0]
# [ 3 2 4 0 0 0 0 0 0 0]
# [10 7 8 9 5 0 0 0 0 0]
# [ 9 7 1 6 7 7 4 0 0 0]]
# [4, 3, 5, 7]
# [1, 0, 0, 1]
# 이때 pad_sequences는 기본적으로 0으로 데이터를 padding 하기 때문에 빈칸이 0으로 채워졌다.# creating simple rnn for "many to one" classification
input_dim = len(char2idx)
output_dim = len(char2idx)
one_hot = np.eye(len(char2idx))
hidden_size = 10
num_classes = 2
model = Sequential()
# 이 예제에서 Embedding 레이어는 토큰을 one-hot vector로 표현한다.
# 가령 <pad> 토큰을 0번째 index로 매핑했는데, 이를 one-hot vector로 표현하면 [1, 0, 0, ...]이 된다.
# 특히 이 예제에서 mask_zero 옵션을 통해서 전처리 단계에서 0 값으로 padding된 부분을 알아서 제외할 수 있다.
# trainable 옵션으로 one-hot vector를 training 하지 않을 수 있다.
model.add(
layers.Embedding(
input_dim=input_dim,
output_dim=output_dim,
trainable=False,
mask_zero=True,
input_length=max_sequence,
embeddings_initializer=keras.initializers.Constant(one_hot),
)
)
# SimpleRNN은 기본적으로 시퀀스의 마지막 토큰을 input으로 받아 처리한 결과를 리턴한다.
model.add(layers.SimpleRNN(units=hidden_size))
# 이후 dense를 이용하면 RNN을 Many-to-One 방식으로 활용하는 코드를 완성할 수 있다.
model.add(layers.Dense(units=num_classes))
model.summary()=> 결과
| Layer (type) | Output Shape | Param # |
|---|---|---|
| embedding (Embedding) | (None, 10, 11) | 121 |
| simple_rnn (SimpleRNN) | (None, 10) | 220 |
| dense (Dense) | (None, 2) | 22 |
| Total params | 363 | |
| Trainable params | 242 | |
| Non-trainable params | 121 |
Embedding 레이어에서 simple_rnn이 처리할 수 있도록 data를 (data dim, max seq, input dim)의 형태로 처리함.
이를 rnn이 설정한 hidden 사이즈 만큼의 벡터로 처리한다.
마지막으로 dense 레이어가 이를 classification을 한다.
3. 학습
# creating loss function
# loss function 생성
# 예제에선 classification 문제를 풀기 때문에 cross entropy 를 계산하는 함수를 활용한다.
# y가 one-hot이 아닌 integer로 들어오기 때문에 이를 처리할 수 있는 tensorflow 제공 함수를 사용한다.
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss_fn(model, x, y):
logits = model(x, training=True)
return loss_obj(y_true=y, y_pred=logits)
# creating an optimizer
lr = 0.01
epochs = 30
batch_size = 2
opt = tf.keras.optimizers.Adam(learning_rate=lr)
# generating data pipeline
tr_dataset = tf.data.Dataset.from_tensor_slices((x_data, y_data))
tr_dataset = tr_dataset.shuffle(buffer_size=4)
tr_dataset = tr_dataset.batch(batch_size=batch_size)
print(tr_dataset)
# 출력 : <BatchDataset shapes: ((?, 10), (?,)), types: (tf.int32, tf.int32)># 생성한 데이터셋과 loss 함수, 옵티마이저를 활용해서 모델을 학습한다.
# training
tr_loss_hist = []
for epoch in range(epochs):
avg_tr_loss = 0.0
tr_step = 0
for x_mb, y_mb in tr_dataset:
# 미니배치마다의 cross entropy loss를 계산하고,
with tf.GradientTape() as tape:
tr_loss = loss_fn(model, x=x_mb, y=y_mb)
# gradient를 계산하고
grads = tape.gradient(target=tr_loss, sources=model.trainable_variables)
# 마지막으로 gradient descend를 한다.
opt.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
avg_tr_loss += float(tr_loss)
tr_step += 1
avg_tr_loss /= tr_step
tr_loss_hist.append(avg_tr_loss)
if (epoch + 1) % 5 == 0:
print('epoch : {:3}, tr_loss : {:.3f}'.format(epoch + 1, avg_tr_loss))4. 정확도 확인
yhat = model.predict(x_data, verbose=0)
yhat = np.argmax(yhat, axis=-1)
print('acc : {:.2%}'.format(np.mean(yhat == np.array(y_data))))=> 결과
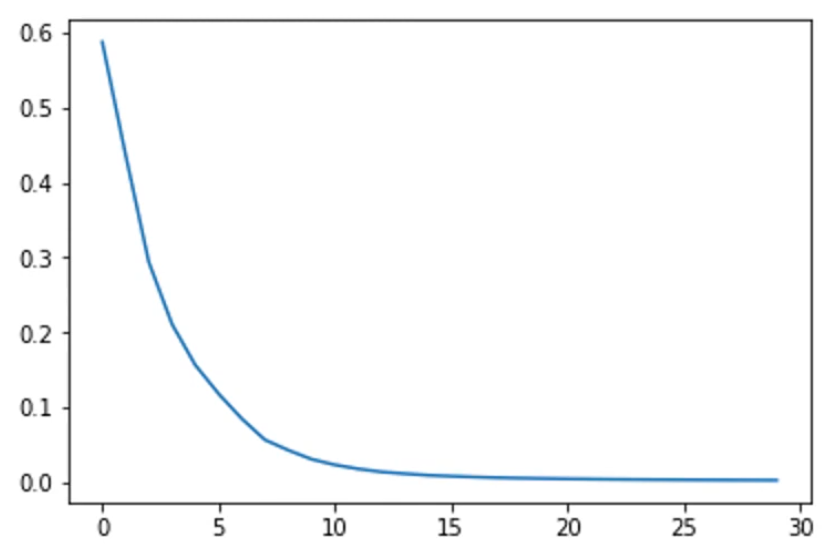
각 에폭마다 training loss가 계속 떨어지고 있는걸 확인할 수 있다.
Stacking이란?
CNN에서 Conv layer를 여러개 쌓듯, RNN에서도 RNN을 여러개 쌓을 수 있다. => 이를 Multilayered RNN 혹은 Stacked RNN이라고 한다.
CNN에서 input에 가까운 레이어는 엣지와 같은 글로벌한 feature를 뽑을 수 있고, output에 가까운 레이어는 추상적인 feature를 뽑을 수 있듯, RNN에서도 마찬가지라고 알려져 있다.
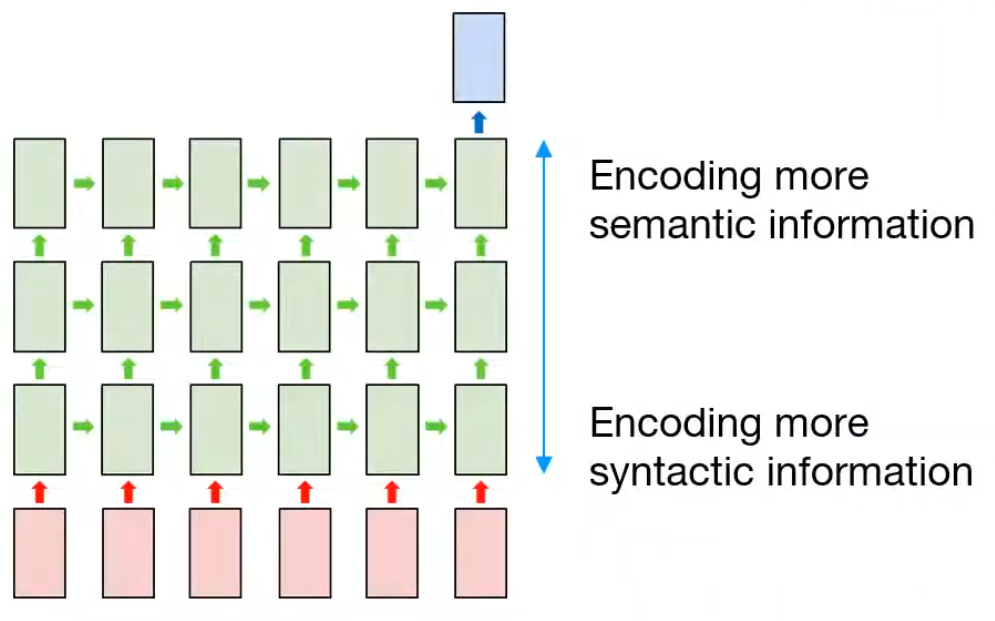
- RNN의 아래쪽 레이어는 상대적으로 문장 구조, 단어 배열 같은 형태/구분 정보를 더 많이 담고 있는 경향이 있다.
- 반면 위쪽 층은 문장의 의미나 문맥, 주제 같은 의미 정보를 더 많이 담는 경향이 있다.
=> 즉, 층이 올라갈수록 더 추상적인 의미 표현으로 변한다.
구현 예제
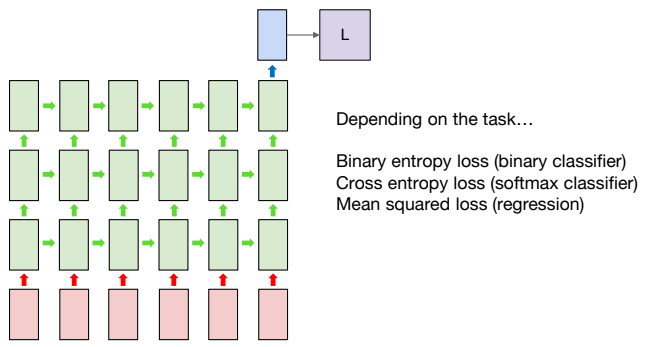
이전 RNN을 many to one으로 활용한 것과 동일하게, 이번에는 stacked RNN을 사용한다.
시퀀스를 tokenization 한 뒤, embedding layer를 거쳐서 numeric 벡터로 표현된 각각의 토큰을 stacked RNN이 순서대로 읽어들인다.
이때 t번째 시점의 토큰과 t-1번째 시점의 토큰을 받아서 t번째 시점의 hidden state를 생성하게 된다.
그리고 many to one 방식을 사용하기 때문에 마지막 토큰을 읽어서 나온 결과로 loss를 계산하고 backpropagation을 사용해 학습하게 된다.
구현 코드
1. 데이터셋 준비
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.sequence import pad_sequences
import matplotlib.pyplot as plt
# example data
sentences = [
'What I cannot create, I do not understand.',
'Intellectuals solve problems, geniuses prevent them',
'A person who never made a mistake never tried anything new.',
'The same equations have the same solutions.'
]
y_data = [1, 0, 0, 1] # 1: richard feynman, 0: albert einstein
# creating a token dictionary
char_set = ['<pad>'] + sorted(list(set(''.join(sentences))))
idx2char = {idx: char for idx, char in enumerate(char_set)}
char2idx = {char: idx for idx, char in enumerate(char_set)}
print(char_set)
print(idx2char)
print(char2idx)=> 결과
['<pad>', ' ', ',', '.', 'A', 'I', 'T', 'W', 'a', 'b', 'c', 'd', 'e', 'g', 'h', 'i', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'y']
{0: '<pad>', 1: ' ', 2: ',', 3: '.', 4: 'A', 5: 'I', 6: 'T', 7: 'W', 8: 'a', 9: 'b', 10: 'c', 11: 'd', 12: 'e', 13: 'g', 14: 'h', 15: 'i', 16: 'k', 17: 'l', 18: 'm', 19: 'n', 20: 'o', 21: 'p', 22: 'q', 23: 'r', 24: 's', 25: 't', 26: 'u', 27: 'v', 28: 'w', 29: 'y'}
{'<pad>': 0, ' ': 1, ',': 2, '.': 3, 'A': 4, 'I': 5, 'T': 6, 'W': 7, 'a': 8, 'b': 9, 'c': 10, 'd': 11, 'e': 12, 'g': 13, 'h': 14, 'i': 15, 'k': 16, 'l': 17, 'm': 18, 'n': 19, 'o': 20, 'p': 21, 'q': 22, 'r': 23, 's': 24, 't': 25, 'u': 26, 'v': 27, 'w': 28, 'y': 29}
# 각 토큰이 integer index와 매핑되었다.# converting sequence of tokens to sequence of indices
# sentence를 integer index의 시퀀스로 변환
x_data = list(map(lambda sentence: [char2idx.get(char) for char in sentence], sentences))
x_data_len = list(map(lambda sentence: len(sentence), sentences))
print(x_data)
print(x_data_len)
print(y_data)
# (출력 생략)
# 문장의 길이가 길어졌기 때문에 단순한 RNN 보다는 LSTM, GRU을 활용할 수 있다.
# padding the sequence of indices
max_sequence = 55
x_data = pad_sequences(sequences=x_data, maxlen=max_sequence, padding='post', truncating='post')
# checking data
print(x_data)
print(x_data_len)
print(y_data)2. 모델 생성
# creating stacked rnn for "many to one" classification with dropout
num_classes = 2
hidden_dims = [10, 10]
input_dim = len(char2idx)
output_dim = len(char2idx)
one_hot = np.eye(len(char2idx))
model = Sequential()
model.add(
layers.Embedding(
input_dim=input_dim,
output_dim=output_dim,
trainable=False,
mask_zero=True,
input_length=max_sequence,
embeddings_initializer=keras.initializers.Constant(one_hot),
)
)
model.add(layers.SimpleRNN(units=hidden_dims[0], return_sequences=True))
# stacked RNN은 기존 RNN에 비해서 모델의 캐퍼시티가 크므로, 오버피팅될 가능성이 있다.
# 따라서 TimeDistributed와 Dropout을 활용하게 된다.
model.add(layers.TimeDistributed(layers.Dropout(rate=0.2)))
model.add(layers.SimpleRNN(units=hidden_dims[1]))
model.add(layers.Dropout(rate=0.2))
model.add(layers.Dense(units=num_classes))
model.summary()=> 출력 결과
| Layer (type) | Output Shape | Param # |
|---|---|---|
| embedding (Embedding) | (None, 55, 30) | 900 |
| simple_rnn (SimpleRNN) | (None, 55, 10) | 410 |
| time_distributed (TimeDistributed) | (None, 55, 10) | 0 |
| simple_rnn_1 (SimpleRNN) | (None, 10) | 210 |
| dropout_1 (Dropout) | (None, 10) | 0 |
| dense (Dense) | (None, 2) | 22 |
| 항목 | 값 |
|---|---|
| Total params | 1,542 |
| Trainable params | 642 |
| Non-trainable params | 900 |
3. 모델 학습
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss_fn(model, x, y):
logits = model(x, training=True)
return loss_obj(y_true=y, y_pred=logits)
# creating an optimizer
lr = 0.01
epochs = 30
batch_size = 2
opt = tf.keras.optimizers.Adam(learning_rate=lr)
# generating data pipeline
tr_dataset = tf.data.Dataset.from_tensor_slices((x_data, y_data))
tr_dataset = tr_dataset.shuffle(buffer_size=4)
tr_dataset = tr_dataset.batch(batch_size=batch_size)
print(tr_dataset)# training
tr_loss_hist = []
for epoch in range(epochs):
avg_tr_loss = 0.0
tr_step = 0
# 학습 시작. 이전과 동일하다.
for x_mb, y_mb in tr_dataset:
with tf.GradientTape() as tape:
tr_loss = loss_fn(model, x=x_mb, y=y_mb)
grads = tape.gradient(target=tr_loss, sources=model.trainable_variables)
opt.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
avg_tr_loss += float(tr_loss)
tr_step += 1
avg_tr_loss /= tr_step
tr_loss_hist.append(avg_tr_loss)
if (epoch + 1) % 5 == 0:
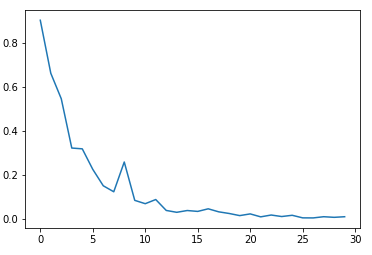
print('epoch : {:3}, tr_loss : {:.3f}'.format(epoch + 1, avg_tr_loss))=> 학습 결과
epoch : 5, tr_loss : 0.319
epoch : 10, tr_loss : 0.084
epoch : 15, tr_loss : 0.038
epoch : 20, tr_loss : 0.015
epoch : 25, tr_loss : 0.016
epoch : 30, tr_loss : 0.010
4. 정확도 확인
yhat = model.predict(x_data, verbose=0)
yhat = np.argmax(yhat, axis=-1)
print('accuracy : {:.2%}'.format(np.mean(yhat == np.array(y_data))))
plt.plot(tr_loss_hist)
plt.show()=> 최종 결과
모두를 위한 딥러닝 강좌 2
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
