공모전 데이터를 보고 공부를 하던 중, gradient boosting library에 새로 나온 'Catboost'를 알게 되었다. 기존의 부스팅 기법의 문제를 해결하고, 범주형 변수들이 많을 때 이용하기 좋으며 비슷한 데이터 사이즈에서 다른 gradient boosting library의 앙상블기법보다 빠른 'Catboost'를 포스팅한다!
기존 부스팅
기존 부스팅 기법 순서
- 실제 값들의 평균과 실제 값의 차이인 잔차를 구한다.
- 데이터로 이 잔차들을 학습하는 모델을 만든다.
- 만든 모델로 예측하여, 예측 값에 Learning_rate를 곱해 실제 예측 값(평균 + 잔차예측 값* lr)을 업데이트 한다.
- 1~3 반복
문제점
-
느린 학습속도와 복잡한 하이퍼파라미터 조정
배깅의 경우 여러 트리들이 병렬적으로 모델학습을 수행하고 부스팅의 경우 순차적으로 모델학습을 수행하니 배깅에 비해 훨씬 느릴 수 밖에 없으며, 하이퍼파라미터를 어떻게 조정하는지에 따라 예측률 차이가 크다. -
오버피팅
동일한 데이터로 훈련된 모델을 사용하여 잔차를 계산하기에 과적합 되기 쉽다. 부스팅 자체가 '잔차'를 줄여나가기 위해 학습 결과에 따른 가중치를 주는 모델이기 때문에 오버피팅의 위험이 있다.
Catboost 특징
- symmetric tree(Level-wise tree) 구조 사용
균형잡힌 트리구조여서 오버피팅을 방지할 수 있다.
max_depth = -1이면 둘은 같은 형태이다.light gbm은 leaf-wise고, xgboost는 대칭트리를 만든다.
2. ordered boosting
기존의 부스팅 모델이 일괄적으로 모든 훈련 데이터를 대상으로 잔차계산을 했다면, Catboost 는 일부만 가지고 잔차를 계산을 한 뒤, 이걸로 모델을 만들고, 그 뒤에 데이터의 잔차는 이 모델로 예측한 값을 사용한다.
예시)
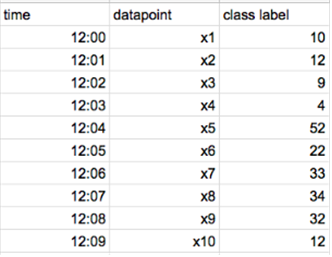
- 먼저 x1 의 잔차만 계산하고, 이를 기반으로 모델을 만든다. 그리고 x2 의 잔차를 이 모델로 예측한다.
- x1, x2 의 잔차를 가지고 모델을 만든다. 이를 기반으로 x3, x4 의 잔차를 모델로 예측한다.
- x1, x2, x3, x4 를 가지고 모델을 만든다. 이를 기반으로 x5, x6, z7, x8 의 잔차를 모델로 예측한다.
- 반복
이렇게 순서에 따라 모델을 만들고 예측하는 방식을 ‘Ordered Boosting’이라 부른다.
- 무작위 순열
Ordered Boosting을 할 때, 데이터 순서를 섞어주지 않으면 매번 같은 순서대로 잔차를 예측하는 모델을 만들 가능성이 있다. 이 순서는 사실 우리가 임의로 정한 것임으로, 순서 역시 매번 섞어줘야 한다. Catboost는 이를 감안해서 데이터를 셔플링하여 뽑아낸다. 뽑아낼 때도 모든 데이터를 뽑는게 아니라, 그 중 일부만 가져오게 할 수 있다. 이는 오버피팅 방지를 위해, 트리를 다각적으로 만들려는 시도이다.
- Handling categorical features
- Mean encoding (=target encoding, response encoding)
범주화 변수를 수로 인코딩 시키는 방법 중, 어떤 범주화 변수를 특정 범주를 가진 target의 평균으로 인코딩 하는 것이다. 이는 예측해야 하는 값이 훈련 셋에 들어가 과적합과 data leakage문제를 일으킬 수 있다. 그래서 catboost는 현재 데이터를 인코딩하기 위해 이전 데이터들의 인코딩된 값만 사용한다. (즉, 이전 데이터의 타겟값만 사용)
예를 들면, x1을 x1인 y값의 평균으로 인코딩한다. 단, 세 번째에 존재하는 x1을 인코딩할 때, 두 번째 값까지의 x1 데이터를 이용한다.
- categorical feature combinations
y 예측하기 위한 변수 중 동일한 특성을 지닌 변수들은 하나로 묶는다.
- One-hot encoding
낮은 Cardinality 를 가지는 범주형 변수에 한해서, 기본적으로 One-hot encoding 을 시행한다. Cardinality 기준은 one_hot_max_size 파라미터로 설정할 수 있다.
예를 들어, one_hot_max_size = 3 으로 준 경우, Cardinality 가 3이하인 범주형 변수들은 Mean Encoding(target encoding)이 아니라 One-hot 으로 인코딩 된다.수치형 데이터는 다른 부스팅 알고리즘과 같은 방식으로 처리한다.
- hyperparameter
기본 파라미터가 기본적으로 최적화가 잘 되어있어서, 파라미터 튜닝에 크게 신경쓰지 않아도 된다. (반면 xgboost 나 light gbm 등의 부스팅 기법은 파라미터 튜닝에 매우 민감하다.) Catboost는 이를 내부적인 알고리즘으로 해결하고 있어서, 파라미터 튜닝할 필요가 거의 없다. 굳이 한다면 learning_rate, random_strength, L2_regulariser 과 같은 파라미터 튜닝인데, 결과는 큰 차이가 없다고 한다.
catboost 한계
- 희소행렬을 지원하지 않는다,
- 데이터 대부분이 수치형 변수인 경우 학습속도가 느리다.
catboost를 사용하는 다양한 상황
- 시간이 지남에 따라 데이터가 변경되는 경우
has_time=True로 설정하고 수행 가능하다. - 짧은 시간
symmetric tree 구조이기에 일반적으로 xgboost보다 8배 정도 빠르다. - 어떤 데이터에 가중치를 더 주고 싶을 때
매개변수를 설정하여 특정 데이터에 더 많은 가중치를 부여할 수 있다. Catboost에서 더 많은 가중치를 부여하면 무작위 순열에서 선택될 확률이 높다.
모든 데이터에 선형 가중치 부여하는 방법
sample_weight=[x for x in range(train.shape[0])]
- 데이터 크기에 따라
fold_len_multiplier=1(must be>1), approx_on_full_history=True로 설정한다. 데이터가 적은 경우, Catboost는 각각의 데이터에 다른 모델을 이용해서 잔차를 계산할 수 있다.
대규모 데이터셋일 경우,task_type=GPU로 설정한다.
이 밖에 여러 가지 기능들이 더 있다!
참고
[https://hanishrohit.medium.com/whats-so-special-about-catboost-335d64d754ae][http://learningsys.org/nips17/assets/papers/paper_11.pdf]
