Instruction-finetuning에 관한 논문을 읽어보자!
0. Abstract
137B 파라미터수로 pre-trained된 모델에 60개 정도의 NLP dataset들로 instruction tune함 =>FLAN이라 부르겠다
FLAN은 175B 의 GPT 3보다 25개중 20개의 task에서 더 뛰어난 성능을 보임
finetuning dataset의 개수랑 모델의 크기랑 natural language instructions 가 핵심이였다.
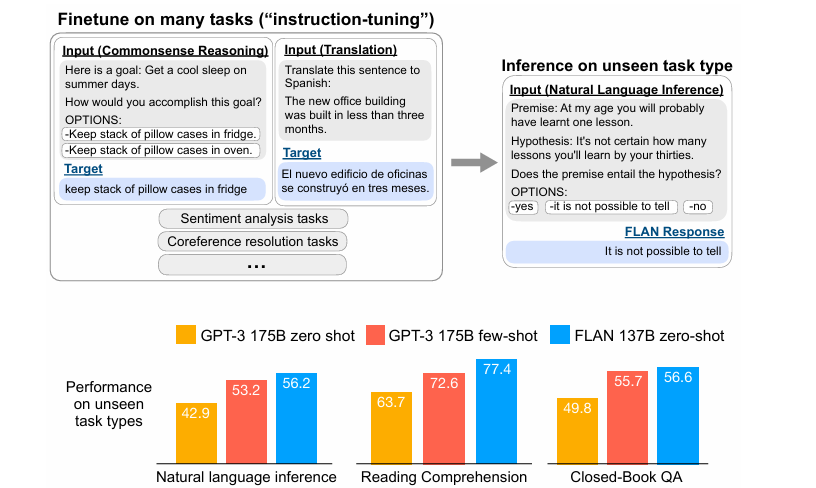
1. Introduction
본 논문에서는 GPT-3 와 같은 LLM들은 few-shot learning setting에서는 좋은 성능을 보였지만 zero-shot learning에서는 그에 훨씬 미치지 못하였다고 언급한다.
NLP task들이 instruction 형태로 변환하여 fine-tuning이 될 수 있다는 직관을 활용해서 137B parameters+instruction tuning (60 NLP datasets) 모델 FLAN을 제시한다.
Instruction 변환
Input : What's your name?
Output : wie heißen sie?
👇
Input : translate 'What's your name?' into German
Output : wie heißen sie?
zero-shot performance를 평가하기 위해서 특정 작업 유형을 학습 데이터에서 제외하고 나머지 작업으로 모델을 튜닝한 후, 제외한 작업에서 모델이 얼마나 잘 수행하는지를 평가함
저자들은 아래와 같은 특징을 발견함
- Instruction data안의 task-cluster 개수가 많을수록 unseen task에서의 성능이 향상됨
- Instruction tuning의 효과는 일정 수준 이상 크기의 model에서만 발생함
데이터셋도 깃허브에 준다..! (나중에 해봐야지..)
https://github.com/google-research/flan
2. FLAN: INSTRUCTION TUNING IMPROVES ZERO-SHOT LEARNING
Instruction tuning이 구체적으로 어떻게 진행되는지 알아보도록 하자.
2.1 TASKS&TEMPLATES
먼저 저자들은 기존에 존재하던 데이터셋들을 아래와 같은 instructional format으로 변환했다.
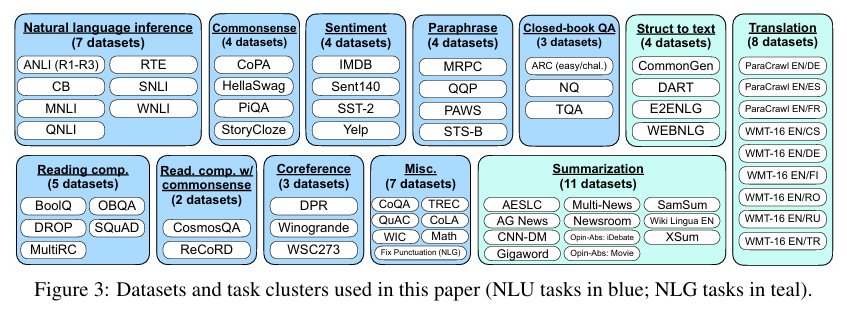
총 12개의 task-cluster로 categorized된 것을 확인 가능
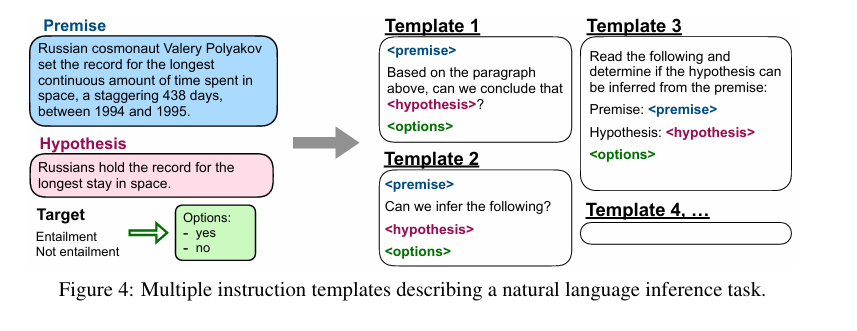
그리고 각각의 dataset에 대하여 instructional format으로 변경해주는데 10개의 template으로 변경해준다고 함
(일부 세개정도 변형된 task를 준다고도 한다)
원래 작업: "이 영화 리뷰가 긍정적인지 부정적인지 분류하세요."
변형된 작업 (turned the task around): "이 영화 리뷰에서 긍정적인 부분과 부정적인 부분을 각각 찾아보세요."
2.2 EVALUATION SPLITS
저자들은 unseen task 를 잘 수행하는지에 관심이 있었고
instruction tuning이 이뤄지지 않은 클러스터를 evaluation에 이용했다.
만약 c task에 대해 evaulation을 진행한다고 하면,
각각의 c task를 제외하고 instruction tuning을 진행한
model로 evaluation을 진행하는 것이다.
2.3 Classification with Options
분류 task에서 이전 연구들은 예를들면 yes, no 두가지 output만 고려해서 큰 확률을 채택하는 방식을 선택했는데
FLAN 모델은 자유 텍스트 응답을 생성하는 특성 때문에 yes , no라는 두가지 출력 외에도 다양한 표현을 생성할 수 있다.
이런 다양한 표현 때문에, 모델이 "yes"에 대한 확률을 여러 표현으로 나누게 되어, 결과적으로 "yes" 자체의 확률이 낮아질 수 있다.
이를 해결하기 위해, 분류 작업에 OPTIONS 토큰과 출력 클래스 목록을 추가한다.
예를 들어, "Is this movie review positive or negative?
OPTIONS: [yes, no]"와 같이 한다.
이렇게 하면, 모델은 "yes"와 "no" 두 가지 선택지에 집중하여 확률을 계산하게 된다.
2.4 Training Details
FLAN은 LaMDA-PT model에 instruction tuning을 진행한 model이다.
LaMDA-PT는 구글에서 발표한 decoder-only model이며, 137B개의 parameter를 가지고 있다.
Instruction tuning과정에서 다양한 데이터셋들과 마주하게 되는데 dataset의 크기를 고려하지 않고 tuning한다면 model은 상대적으로 크기가 큰 dataset을 많이 보게 될 것이다. (편향)
본 논문에서는 이러한 문제를 해결하기 위해 T5 논문 에서 제안한 examples-proportional mixing scheme 을 사용한다.
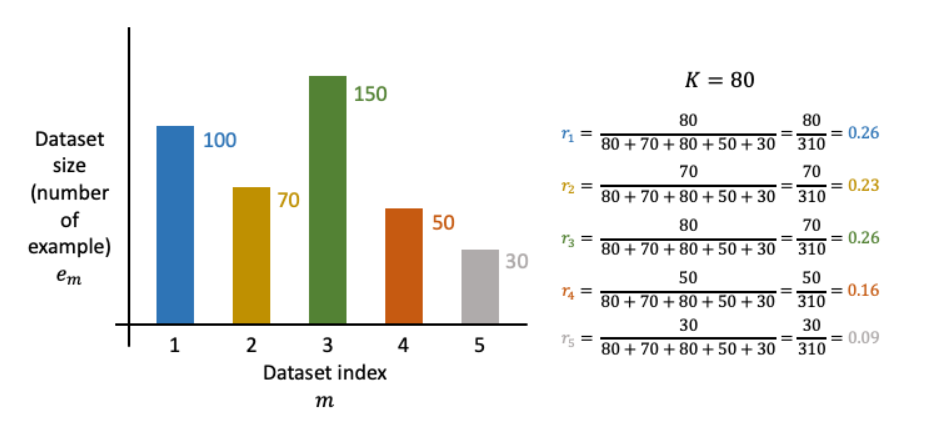
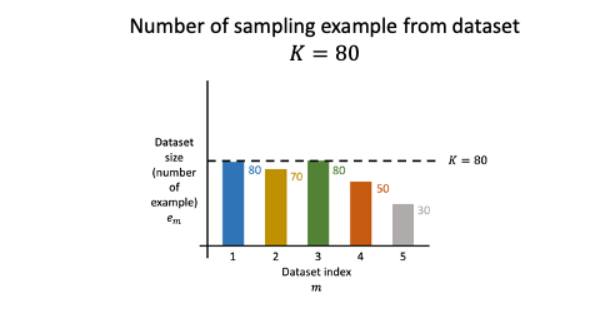
dataset size limit K를 설정하고, 해당 K
보다 큰 dataset의 경우 K개만큼만 sampling 하고, 작은 dataset은 그대로 sampling 하는 방법론이다.
여기선 K=30k로 두었다.
3. RESULTS
dev set에서 일부 프롬프트 엔지니어링을 사용해 최적의 템플릿을 찾아낸 후, 이를 테스트 셋에 적용하여 성능을 평가 하였다.
그 결과, FLAN의 Zero-shot 성능은 25개의 데이터셋 중 20개에서 GPT-3의 Zero-shot 성능을 능가했으며, 그중 10개의 데이터셋에서는 GPT-3의 Few-shot 성능까지 능가하는 성과를 보였음
또한, FLAN은 19개의 데이터셋 중 13개에서 GLaM 모델의 Zero-shot 성능을 뛰어넘었으며, 11개의 데이터셋에서는 GLaM의 One-shot 성능보다 더 좋은 결과를 나타냈다.
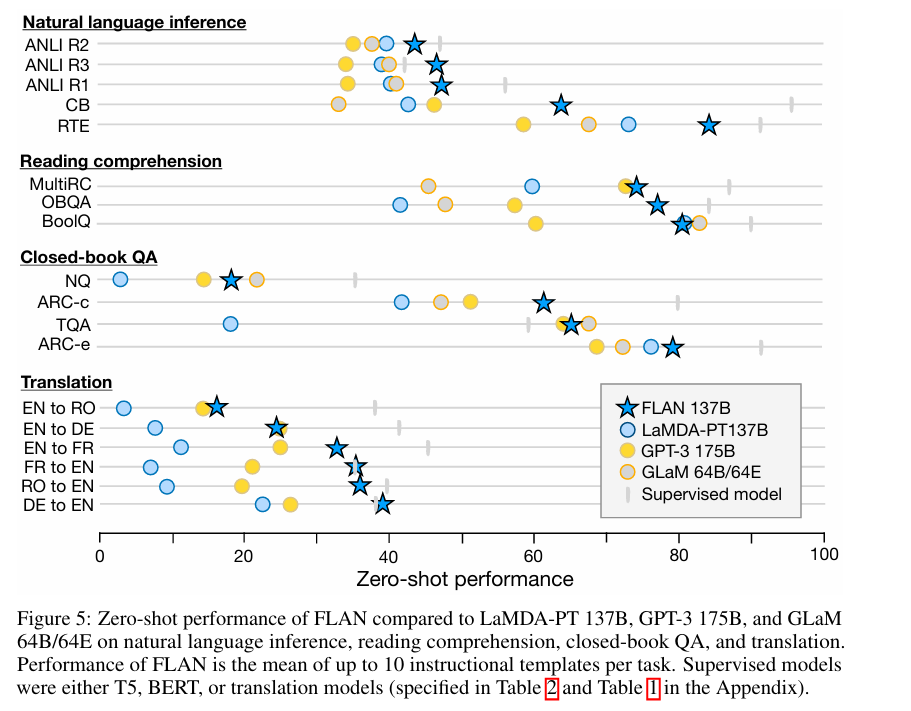
NLI, QA와 같이 자연스럽게 instruction으로 변환되는 task에서는 효과적인 성능 향상을 보였던 것과는 반대로, 불완전한 문장이나 문단을 완성하는 task인 commonsense reasoning이나 conference resolution과 같은 task에서는 효과적인 성능 향상이 이루어지지 않았다는데 이 부분은 이해가 잘 안감
의문점
문장 예시 1: "Tom tried to fix the leaking faucet, but he didn't have the right tools. He went to the store to buy some tools. When he returned, he..."
문장 예시 2: "Tom tried to fix the leaking faucet, but he didn't have the right tools. He went to the store to buy some tools. When he returned, he...라는 문장을 완성하시오."이건 별 도움이 안되는데
질문 예시 1: "애플의 창립자는 누구인가요?"
질문 예시 2: "애플의 창립자는 누군가라는 질문에 답하시오."QA와 같은 task는 효과적인 성능 향상을 올렸다는게 사실 이해가 되지 않는다.
오히려 후자 task 질문 자체가 지시문의 역할을 해서 필요 없을 것 같은데 이 부분에서 성능이 더 잘 나왔다는 부분이 조금 의아하다.명확한 질문과 답변을 요구하는 부분에서는 Instruction tuning을 통한 성능향상이 잘 이루어졌고
문맥을 기반으로 추론하는 작업에는 별 도움이 안되었다고 생각하고 넘어가자
4. Ablation Studies
4-1. Number of Instruction tuning Clusters
자연어 추론(NLI), 클로즈드북 질문 응답(QA), 그리고 상식 추론을 평가 클러스터로 제외하고, 나머지 7개의 클러스터를 instruction tuning에 사용해 봤더니
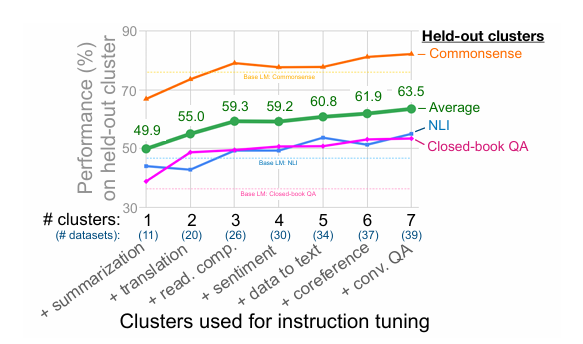
위와 같은 결과가 나옴.
이는 새로운 작업에서 zero-shot 성능을 향상시키는 우리의 제안된 instruction tuning 접근법의 이점을 확인시켜줌
더욱 흥미로운 점은, 테스트한 7개의 클러스터에 대해 성능이 포화되지 않는 것으로 보인다는 점
다만, 감정 분석 클러스터는 추가적인 가치가 거의 없음😅
4-2. SCALING LAWS
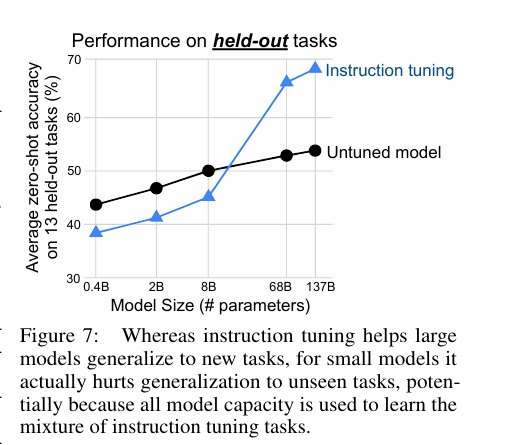
Instruction 주입하는 것도 결국엔 정보임
정보를 받아들이려면 모델 scale이 커야겠지?
4-3. Role of Instruction
저자들이 수행한 마지막 비교 실험은, FLAN의 성능 향상이 과연 fine-tuning으로부터 오는 것인지, instruction으로부터 오는 것인지에 대한 측정이다.
이를 측정하기 위해 instruction 없이 fine-tuning 한거 , dataset name 넣은거 (“[Translation: WMT’14 to French] The dog runs.” 이런식으로) , instruction tuning한거 세개를 가지고 비교를 해봄

FLAN 성능이 월등하더라
4-4. Instruction with Few-Shot Exemplars
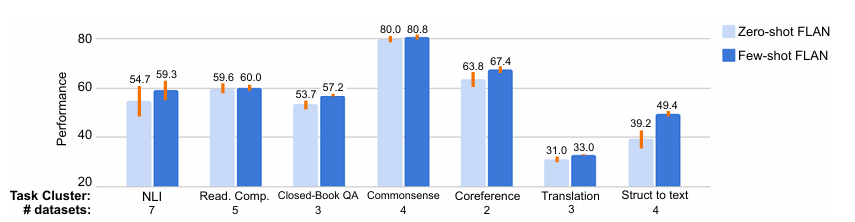
대충 inference 할때 few-shot을 추가하면 성능이 좋아진다는 얘기
4.5 INSTRUCTION TUNING FACILITATES PROMPT TUNING
FLAN 모델은 프롬프트 튜닝을 통해 SuperGLUE 작업에서 더 나은 성능을 보였음.
프롬프트 튜닝 시, 동일 클러스터의 작업은 지시문 튜닝에서 제외된다. 실험 결과, FLAN이 LaMDA-PT보다 성능이 우수했으며, 특히 저자원 설정에서 FLAN의 프롬프트 튜닝 성능이 LaMDA-PT를 10% 이상 능가했다.

후기
중간에 모호한 부분이 있긴했지만
Instruction을 추가하여 학습시키는 것만으로도 zero-shot 성능이 크게 향상되는 것이 인상적이었습니다.
또한, few-shot inference에서도 이전 모델들을 뛰어넘는 성과를 보면서, 왜 2022년 이후로 Instruction-fine tuning이 대세가 되었는지 이해할 수 있었습니다.
RLHF와 관련된 article을 하나 읽고 오픈소스 모델인 LLAMA 논문을 읽어볼건데 기대가 되네요
감사합니다.

유익하네요. 많이 배우고 갑니다.