NLP
1.Word2vec, RNN, LSTM
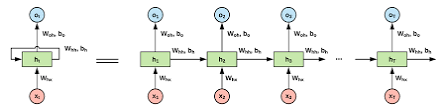
NLP 관련해서 정리를 해보려고 한다.RNN은 가변적인 Data에 Robust하며 네트워크의 weight를 공유하는 특징이 있다.=> backprop시 t번째 layer의 weight가 바뀔 시 다른 layer들의 네트워크도 바뀐다.또 tanh를 activation으로
2.Seq2Seq & Attention model

이전에 봤던 RNN과 LSTM의 모델에는 몇가지 문제점이 존재했음RNN 기반 모델은 1:1 realationship을 가정하고 학습 및 추론을 했는데 input sequence와 출력의 길이가 다를 때도 있을 수 있음ex) vamos => Let's go그리고 꼭 x1
3.Transformer
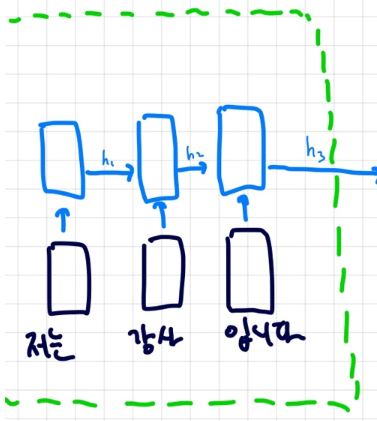
세상을 바꾼 Transformer에 대해 알아보자이전 포스트 에서 알아봤던 어텐션 모델의 아쉬운 점이 있다.인코더 쪽을 한번보자 일반적인 LSTM 모델이다 이 모델의 hidden state를 word embedding으로 간주해서 attention을 구했는데 이 hid
4.Transformer 코드 구현

나만의 뉴스번역봇을 만들면서 Transformer 를 구현해보자허깅 스페이스에서 먼저 tokenizer를 가져온다. (한,영 단어토큰들에 대해서 index mapping이 된 json파일)요런식으로 json파일로 저장되어 있음model 저장경로 지정해주고 하이퍼파라미터
5.GPT-1 : Improving Language Understanding by Generative Pre-Training (2018) 논문리뷰
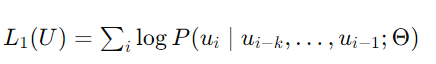
자연어 처리 분야는 textual entailmen, question answering, semantic similarity assesmet와 같은 다양한 task들을 포함한다.수많은 text corpora들이 있지만이렇게 특정한 task를 위한 라벨링된 데이터들은 턱
6.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding-(1)
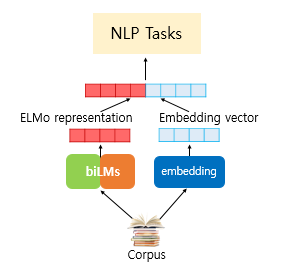
2019년에 나온 구글 BERT 모델에 대해서 알아보자.
7.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding-(2)
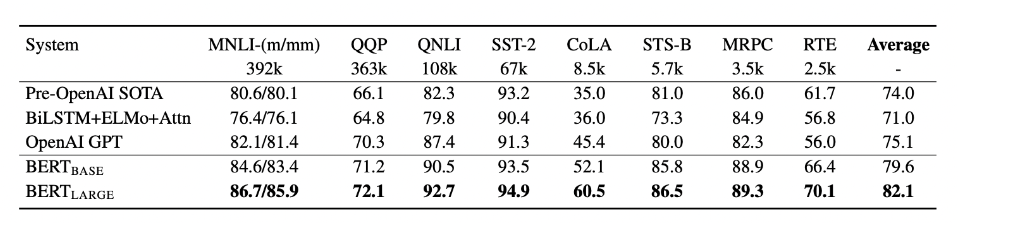
너무 길어져서 2편으로 넘겼다.
8.BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 논문 리뷰 (1)
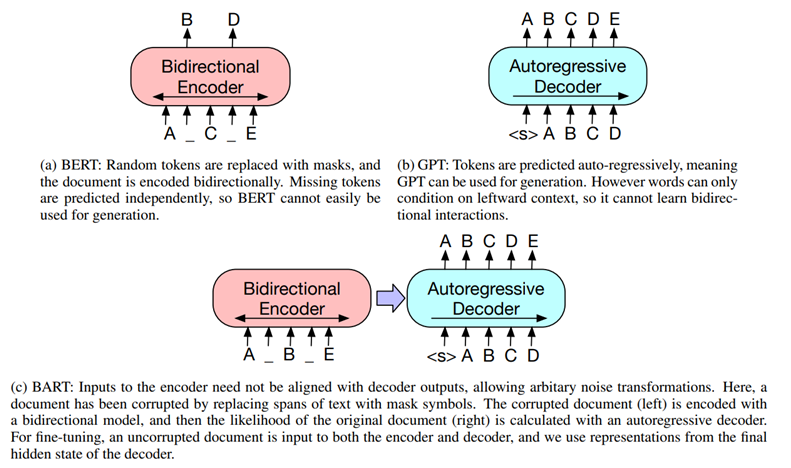
하루에 한개꼴로 논문리뷰를 하니 무지 재밌다이번엔 Encoder-decoder model로 유명한 Facebook(현 메타)에서 2019년 출간한 논문인 BART에 대해서 알아보자.BART는 고의적으로 원래의 텍스트를 망가트리고 훼손된 텍스트를 뒤돌리는 모델을 학습한다
9.[논문리뷰] Language Models are Unsupervised Multitask Learners -GPT-2
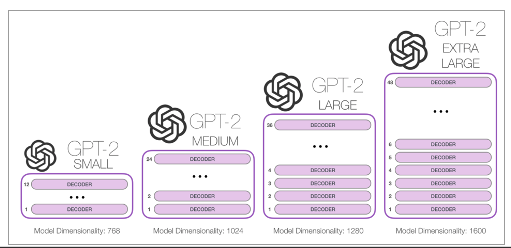
0. Abstract 수백만 개의 웹페이지로 구성된 새로운 데이터셋 WebText로 훈련된 언어 모델은 명시적인 지도 학습 없이도 이러한 작업을 학습하기 시작한다는 것을 발견. GPT 2는 1.5B 파라미터로 8개의 언어모델링 task중에서 7개의 Sota를 달성했고
10.RLHF - Reinforcement Learning from Human feedback
랭귀지 모델들은 그동안 놀라운 능력들을 보여주면서 세간의 관심을 받게 되었습니다. 허나 좋은 "텍스트"를 생성한다는 것은 굉장히 모호한 일이죠.이는 매우 주관적이고 문맥에 따라 달라지기 때문인데요.창의성이 요구되는 이야기 쓰기, 진실해야 하는 정보적 텍스트, 실행 가능
11.[논문 리뷰] Finetuned Language Models Are Zero-Shot Learners 2022
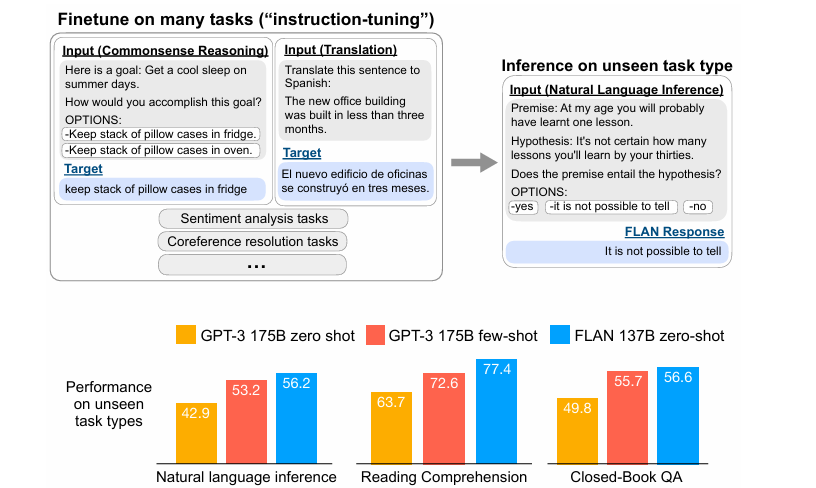
Instruction-finetuning에 관한 논문을 읽어보자!137B 파라미터수로 pre-trained된 모델에 60개 정도의 NLP dataset들로 instruction tune함 =>FLAN이라 부르겠다FLAN은 175B 의 GPT 3보다 25개중 20개의 t
12.[논문 리뷰] LLAMA: Open and Efficient Foundation Language Models (2023)
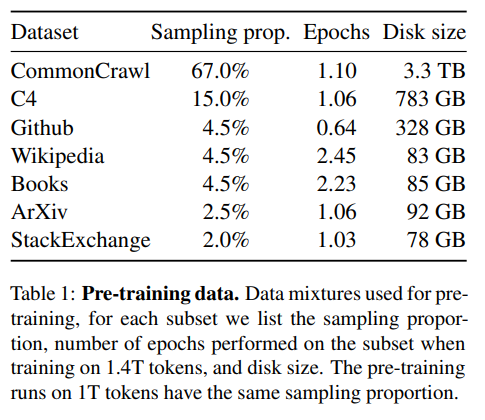
오픈소스 LLM 인 LLAMA에 대해서 알아보는 시간을 갖도록 하겠습니다7B~65B scale의 LLAMA 모델은 pubilicly available한 데이터만 모아서 훈련을 시켜서 Sota 모델을 만들었다. LLAMA-13B는 GPT 3(175B)를 능가하고 , LL
13.[논문리뷰]-TinyBERT: Distilling BERT for Natural Language Understanding
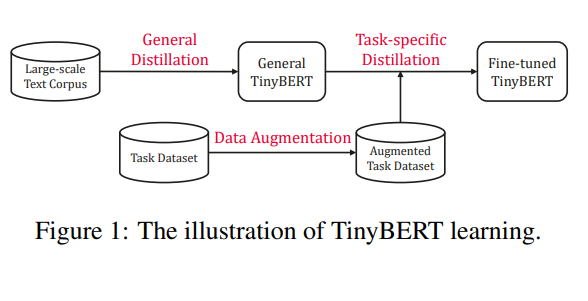
BERT같은 대규모 pre-training Language model들은 계산 비용이 너무 높다는 문제점이 있다. => edge device에서 사용 어려움본문의 저자들은 model size를 줄임으로써 inference time을 줄이고 , accuracy는 그대로
14.[논문 리뷰]- Parameter-Efficient Transfer Learning for NLP (2019)
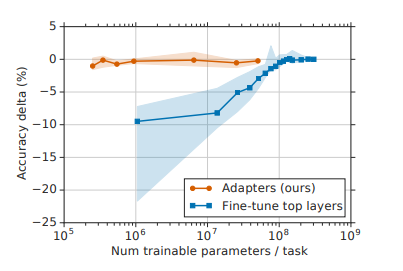
Citation 3096 / Google Deepmind researcher
15.[논문 리뷰] RoBERTa: A Robustly Optimized BERT Pretraining Approach
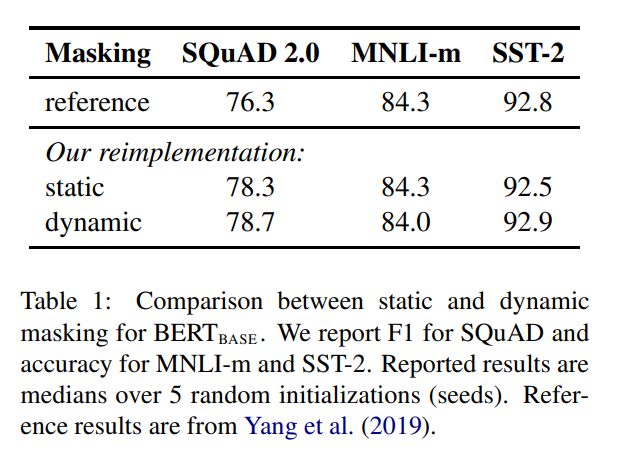
citation 13000 Meta AI