오픈소스 LLM 인 LLAMA에 대해서 알아보는 시간을 갖도록 하겠습니다
0.💡Abstract
7B~65B scale의 LLAMA 모델은 pubilicly available한 데이터만 모아서 훈련을 시켜서 Sota 모델을 만들었다.
LLAMA-13B는 GPT 3(175B)를 능가하고 , LLAMA65 B는 다른 chinchilla(70B)와 PaLM(540B) 과 비교했을 때도 경쟁력있는 성능을 보임
1.💡Introduction
그동안의 LLM들은 막대한 양의 텍스트 데이터를 학습하면서 새로운 task 수행할 수 있는 능력을 보여줬다.
이는 몇가지 예시와 instruction으로 가능하고 우리는 이를 "few-shot learning" 이라고 부른다.
연구들은 model의 scale이 커짐에 따라 performance가 증가한다고 주장했고 사람들은 이에따라 scale을 키우는데 집중하고 있다.
Hoffmann et al.(2022) 의 논문 "Training Compute-Optimal Large Language Models" 에서는 일정한 계산 자원 내에서 더 큰 모델이 아니라 더 작은 모델을 더 많은 데이터로 학습 시킬 때 최고의 성능을 얻을 수 있다고 주장했다
추론 속도의 중요성을 강조하고 작은 모델을 더 많은 token들로 오래 훈련시키는 것이 추론 시점에서는 더 저렴하다고 하며 LLAMA를 소개한다. (single GPU에서도 돌아간다고 한다..나중에 해봐야지)
공개 데이터를 사용하여서 자기네 만큼의 성능을 낸 모델들은 여태 없었다 한다.
2.💡Approach
기존의 패러다임에서 크게 벗어나지 않는다. 큰 트랜스포머에 엄청난 양의 데이터를 이용해서 학습시킴
2-1. Pre-training Data
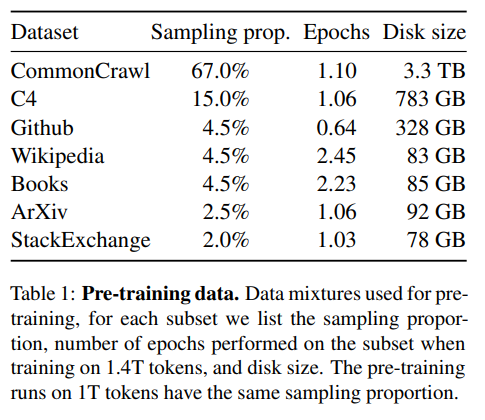
공개된 데이터들로 구성됨공개된 데이터들로 구성됨
BPE tokenizer 사용
2-2 Architecture
-
Pre-normalization (GPT-3): 입력 데이터를 각 트랜스포머 서브 레이어의 출력이 아닌 입력에서 정규화하여 학습 안정성을 향상시킴. RMSNorm 정규화 함수를 사용함.
-
SwiGLU Activation Function (PaLM): ReLU를 SwiGLU 활성화 함수로 교체하여 성능 향상. PaLM의 4d 대신 2/3 4d 차원을 사용함.
-
Rotary Embeddings (GPTNeo): 절대적 위치 임베딩을 제거하고, 각 레이어에 회전 위치 임베딩 (RoPE)을 추가함.
각 모델의 하이퍼파라미터 세부 정보는 표 2에 제공됨.
SwiGLU 함수
𝜎(x) 는 시그모이드 함수이며 B는 하이퍼파라미터다.
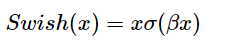
2-3. Optimizer
β1 = 0.9, β2 = 0.95 인 AdamW를 사용했으며 cosine learning rate scheduler를 사용함
Gradient가 너무커지는걸 방지해서 1.0으로 clipiing했고 초기에 learning rate를 올려주는 warmup step=2000으로 설정.
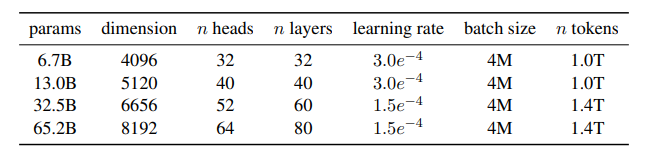
위는 모델의 크기에 따른 하이퍼파라미터들
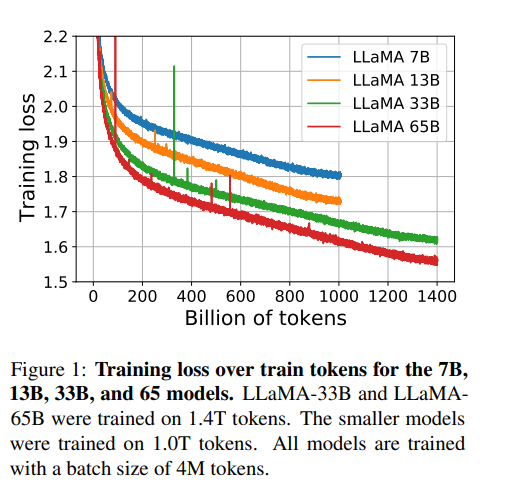
2-4. Efficient implementation
Causal Multi-Head Attention 최적화 기법을 사용함
causal attention의 특성상 미래의 단어는 참조하지 않으므로, 마스크된 key와 query 점수를 계산하지 않아도 돼. 이로 인해 계산량이 줄어든다.
이러한 최적화 과정을 통해 65B 규모의 모델에 1.4T의 토큰을 학습시키는데 약 21일이 걸린다고 한다.
(2048개의 80GB RAM A100 GPU 사용)
3. 💡Main Results
Zero-Shot, Few-Shot에 대한 성능 평가를 진행하며, Free Form Generation (자유 형식 생성)과 Multiple Choice (다중 선택) Task에 대해서 다룬다.
P(completion|context)/P(completion|“Answer:”). 를 최대화 해야함
여기서 "P(completion|“Answer:”)”"가 왜 필요한지 이해하려면, 먼저 문장이 어떤 식으로 만들어지는지 알아야 해. 우리가 AI 모델을 사용해서 답을 찾을 때, 그 모델은 주어진 상황(context)에 가장 잘 맞는 답(completion)을 고르려고 해. 그럼 보통 어떤 답이 가장 그럴듯한지 확률(P)을 계산해.
예를 들어, "강아지가 어떤 색이야?"라는 질문에 "검정색"이란 답을 모델이 제시했다고 해보자. 여기서 "P(검정색|강아지가 어떤 색이야?)"는 그 답이 얼마나 그럴듯한지를 나타내는 확률이야.
근데, OpenBookQA나 BoolQ 같은 특정 데이터셋에서는 그 답의 확률을 "Answer:"라는 단어를 기준으로도 한 번 더 나눠줘.
이게 왜 필요하냐면,
"Answer:"라는 단어가 들어가면 모델이 답을 고르는 방식이 좀 달라질 수 있어서 그래. 쉽게 말해,
"Answer:"라는 단어가 포함된 상황에서의 확률과 비교해서 더 정확한 답을 고르기 위해서야.즉, "P(completion|context)"만 사용하면 상황에 따라 모델이 잘못된 답을 고를 수도 있어.
하지만 "P(completion|“Answer:”)”"로 한 번 더 나눠주면, 답을 고를 때 좀 더 정확한 기준을 세울 수 있어. 이게 마치 시험에서 힌트를 준 상태와 아닌 상태에서 답을 맞히는 확률을 비교하는 것과 비슷해.
그래서 더 정확한 답을 찾기 위해 "Answer:"를 기준으로 확률을 한 번 더 계산하는 거야.
3-1. Common Sense Reasoning
Zero-Shot 설정을 통해 Common Sense Reasoning Task를 수행한 결과, LLaMA-65B는 BoolQ를 제외한 모든 벤치마크에서 Chinchilla-70B를 능가했다.
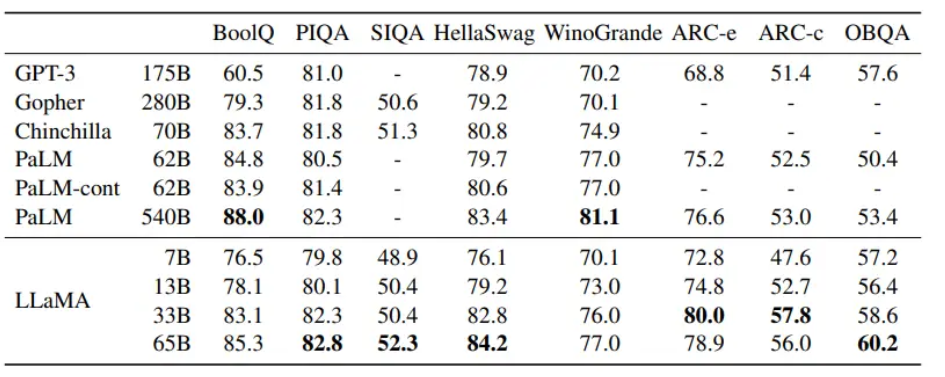
또한, BoolQ와 WinoGrande를 제외한 모든 벤치마크에서 PaLM-540B보다 뛰어난 성능을 보였다.
LLaMA-13B는 GPT-3보다 10배 작은 규모임에도 불구하고 거의 모든 벤치마크에서 더 우수한 성능을 나타냈다.
3-2.Closed-book Question Answering
LLaMA 모델을 Natural Questions와 TriviaQA라는 질문 답변 벤치마크에서 기존 대형 언어 모델과 비교했다.
이 벤치마크에서 모델들은 질문에 답하기 위한 document에 접근할 수 없는 설정에서 정확한 일치 성능을 보고했다. (closed-book setting)
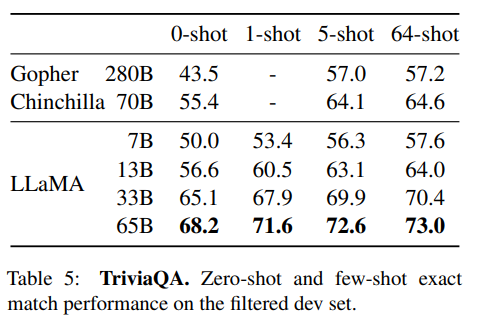
LLaMA-65B 모델은 zero-shot 및 few-shot 설정에서 두 벤치마크 모두에서 최신 성능을 달성했다.
특히, LLaMA-13B 모델은 GPT-3와 Chinchilla에 비해 5-10배 작음에도 불구하고 경쟁력 있는 성능을 보였다.
이 모델은 추론 중에 단일 V100 GPU에서 실행된다.
3-3. Reading Comprehension
중학교 및 고등학교 중국 학생들을 위한 영어 독해 시험에서 수집된 데이터 셋인 RACE를 통해 평가해 봄
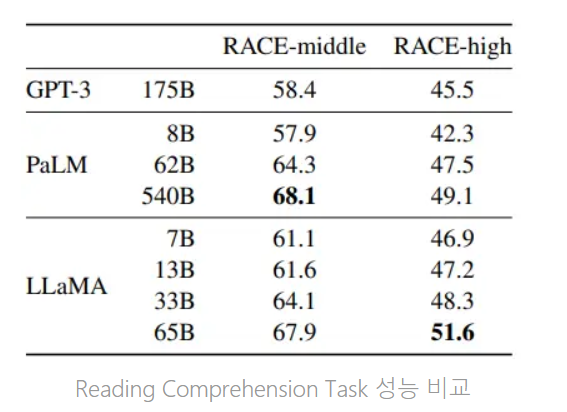
LLaMA-65B는 PaLM-540B와 비등한 성능을 보이며, LLaMA-13B는 GPT-3를 살짝 능가하네?
3-4.Mathematical reasoning
중고딩 수학문제 추론 Task.
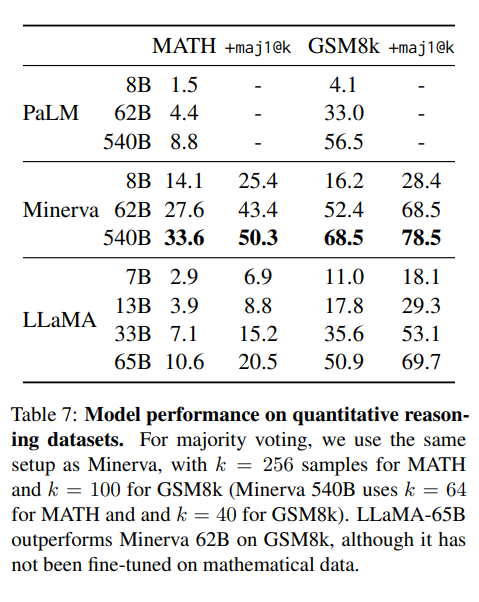
PaLM, Minerva과 비교함
Minerva는 38.5B 규모의 토큰에서 수학적 추론에 맞게 PaLM을 Fine-Tuning한 모델임
GSM8k에서는 LLaMA-65B가 수학 분야에 Fine-Tuning되지 않았음에도 불구하고 Minerva-62B를 능가하는 것을 확인함
3-5.code-generation
모델의 코딩 능력을 평가하는 HumanEval과 MBPP 벤치마크를 사용했다.
few-shot learning (input output example) +python program description 을 모델에게 알려줌
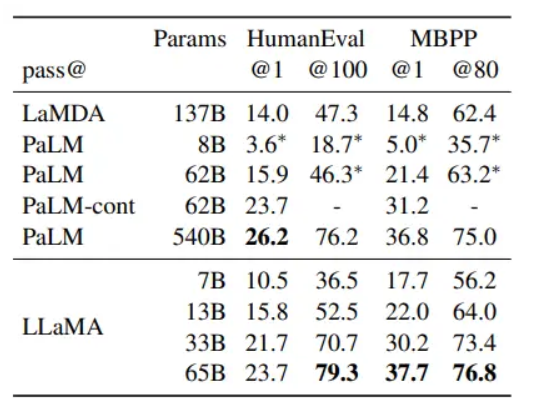
LLAMA 13B는 LaMDA를 압도하고
LLAMA 65B는 paLM을 압도함
PaLM-cont 62B: PaLM 62B 모델을 기반으로 더 많은 데이터로 추가 학습을 진행한 모델이다.
3-6.Massive Multitask Language Understanding
인문학, STEM 및 사회과학을 포함한 다양한 영역의 객관식 문제로 이뤄진 언어 이해능력 task임
역시 few-shot learning setting으로 모델을 평가함 (five- shot)
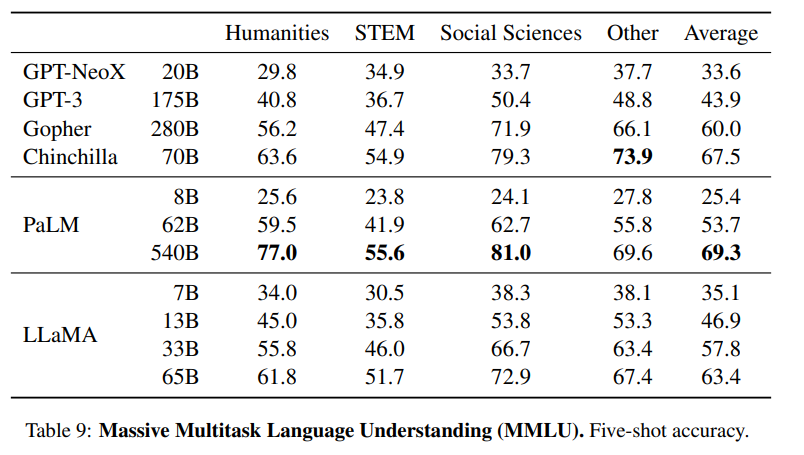
Chinchilla 랑 PaLM보다 살짝 못하는데
연구진들은 비교모델에 비해 현저히 적은 사전 학습 데이터의 양 때문이라고 했다. (177GB vs 2TB)
3-7. Evolution of performance during training
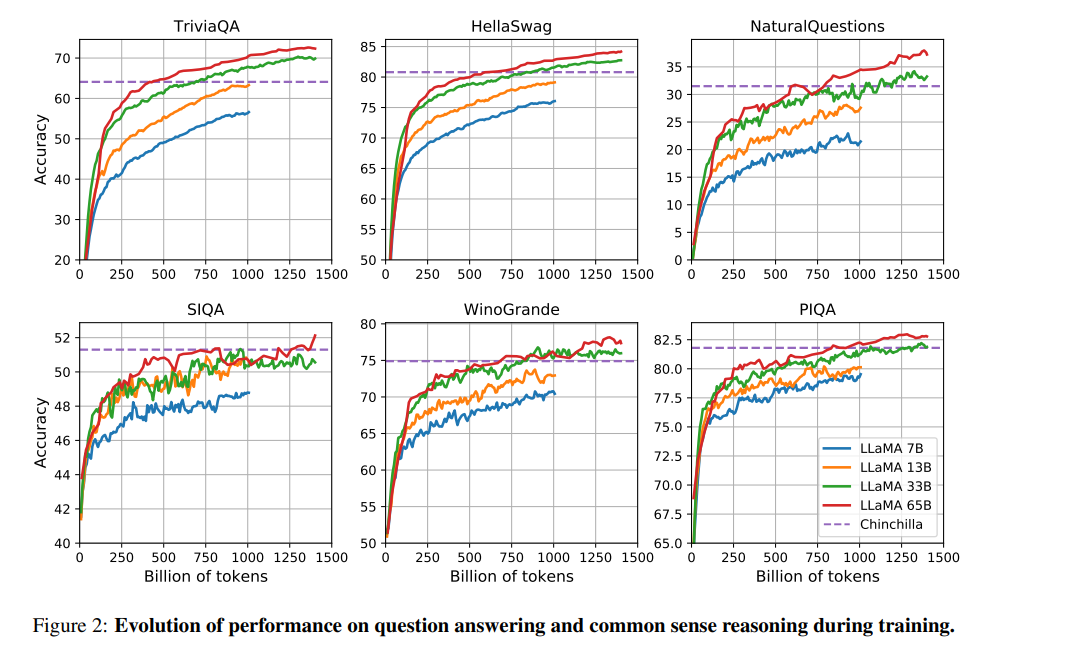
다음은 벤치마크별 학습 성능 변화 그래프
SIQA and WinoGrande 빼고 다 꾸준히 오른다.
SIQA에서 성능에 많은 분산이 관찰되어 이 벤치마크의 신뢰도에 의문을 가졌음
4. 💡Instruction Finetuning
소량의 fine-tuning만으로도 MMLU에서 유의미한 성능 증진을 이루어냈다고 한다.
(BUT, 논문의 주된 내용이 아니므로 가볍게 언급하고 넘어감)
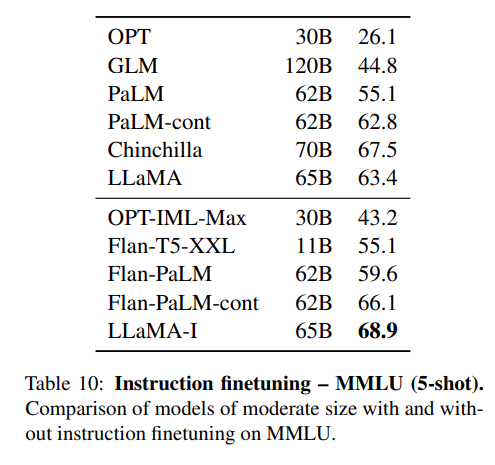
여러 fine-tuned version의 모델들을 능가하지만 Sota인 GPT code-davinci-002 에는 한참 못미친다.
😎 논문 후기
모델의 Scale에 집중한게 아닌 Dataset의 quality와 scale에 집중한것이 흥미로웠습니다.
그리고 작은 모델에서 많은 양의 데이터로 오래학습하면 모델이 작은만큼 inference시간도 적다는 관점이 새로웠어요 😀
간단한 Fine-tuning에 대한 언급으로 성능향상에 대한 가능성도 열어두고 steady하게 성능이 증가하는 것도 확인해서 LLAMA-2 논문을 빨리 읽으러 가고싶게 만드는 논문이였습니다.
