🙂 Face recognition
Face Verification vs Face recognition
Face Verification은 input으로 이미지, name/ID 입력하면 이미지가 실제로 그 사람의 것인지를 확인하는 과정을 거친다.
반면에, face recognition은 더 복잡한 문제다. 이건 데이터베이스에 있는 여러 사람들의 얼굴 중에서 특정 인물을 식별하는 과정을 거친다.
정리하자면 face verification은 '이 사람이 맞는가?'를 확인하는 과정이고, face recognition은 '이 사람이 누구인가?'를 식별하는 과정이다.
One shot Learning
회사의 출입보안 시스템을 만든다고 생각해보자.
우리는 직원들의 사진이 하나 씩 밖에 없다. DNN을 학습시켜야 할까?
학습시켰다고 쳐보자 . 직원들의 수가 늘어난다면 어떻게 해야할까?
처음부터 다시 학습시켜야할까?
아쉽게도 사진한장가지고 좋은 face recognition 성능을 내는 것은 불가능에 가깝다. 이렇게 하나의 input으로만 학습시키는 것을 ONE SHOT Learnig이라고 한다.
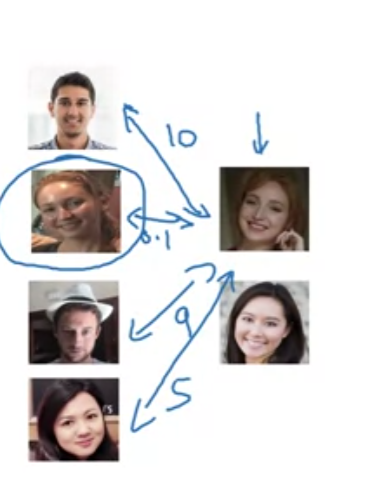
그래서 우리는 Similarity function이라는 것을 도입해 볼 것이다.
Similarity function은 새로운 사진과 기존사진의 유사성을 비교하는 metric인데 그 값이 특정 타우값을 넘는다면 다른 사람이고 넘지 않는다면 같은 사람으로 인식하는 로직이다.
위의 예시를 보면 두번째 사람과의 Similarity function값이 낮은 것을 볼 수 있다.
Siamese network
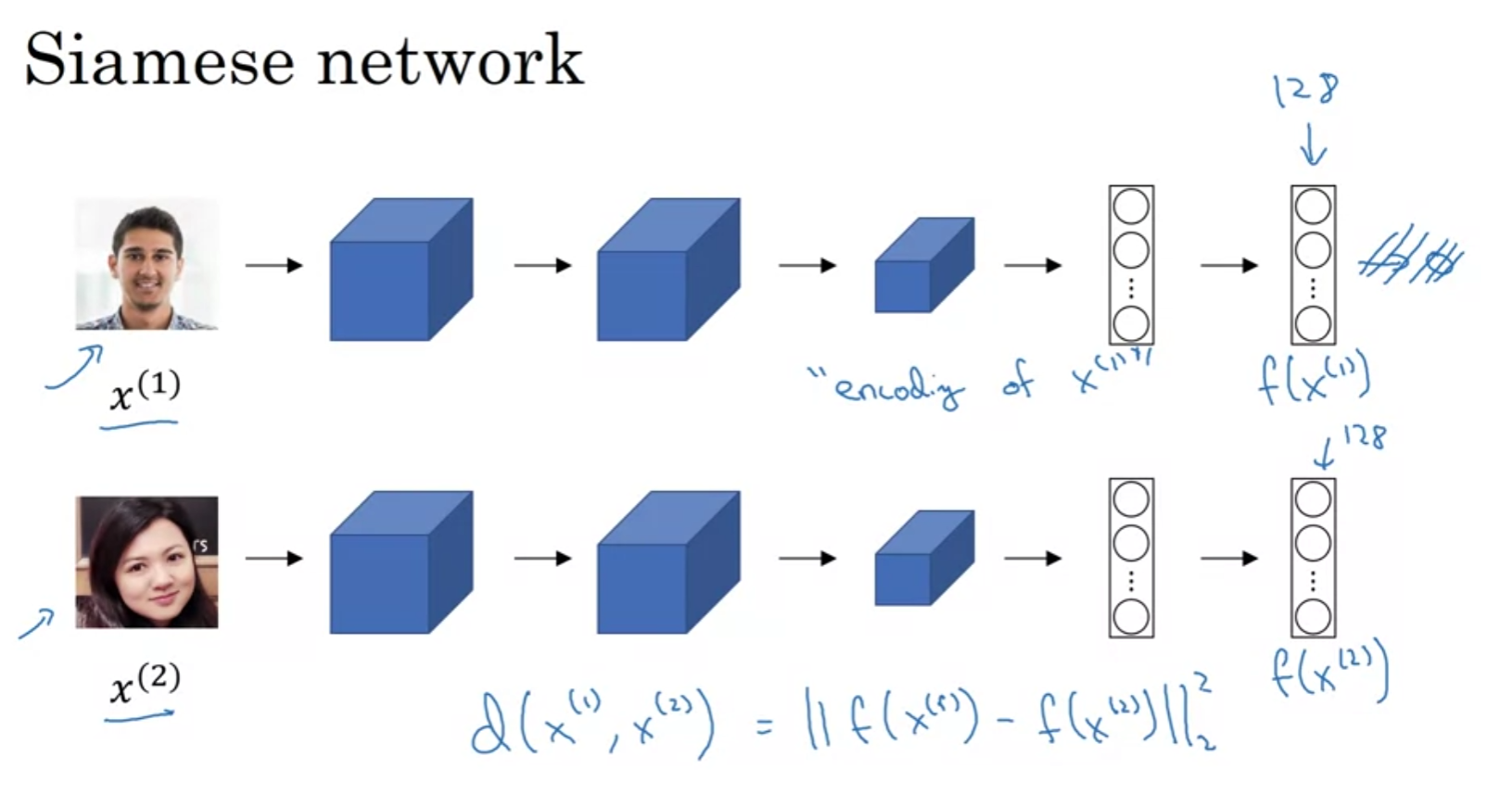
이렇게 서로 다른 입력으로 같은 네트워크에 입력시켜 그 결과를 비교하는 네트워크를 Siamese 아키텍쳐라고 부른다.
Tripet Loss
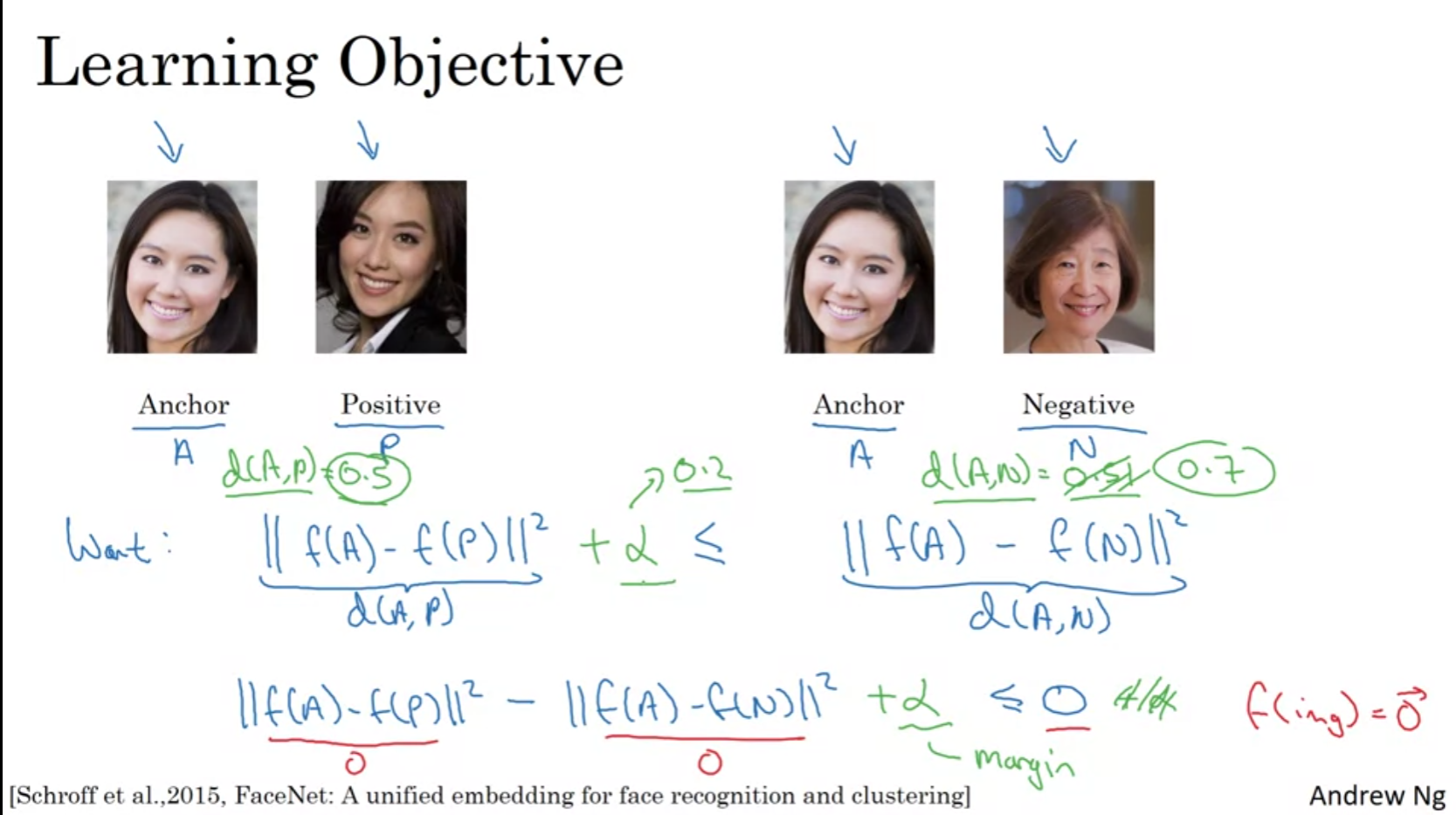
하나의 '앵커' 이미지와 비교적 유사해야 하는 '양성(positive)' 이미지(같은 사람), 그리고 크게 다르게 인코딩되어야 하는 '음성(negative)' 이미지(다른 사람)를 동시에 비교한다.
특정 마진(Alpha)을 유지하며, 트리플렛 손실을 최소화하도록 학습함.
하지만 랜덤하게 A,P,N을 구성하다보면 d(A,N) 과 d(A,P)의 차이를 늘리는 것이 너무 쉬워진다.
물론 이를 늘리는것이 목표긴하지만 신경망이 훈련 과정에서 진짜로 어려운 경우, 즉 서로 매우 비슷해 보이는 다른 사람들의 사진을 구별하는 데 필요한 더 세밀한 패턴이나 특징을 학습하지 못한다는 단점이 있다.
그래서 우리는 최소한의 마진을 유지하지만 d(A,P)와 d(A,n)이 비슷한 그러한 것들로 학습을 시켜야한다.
Face Verification and Binary Classification

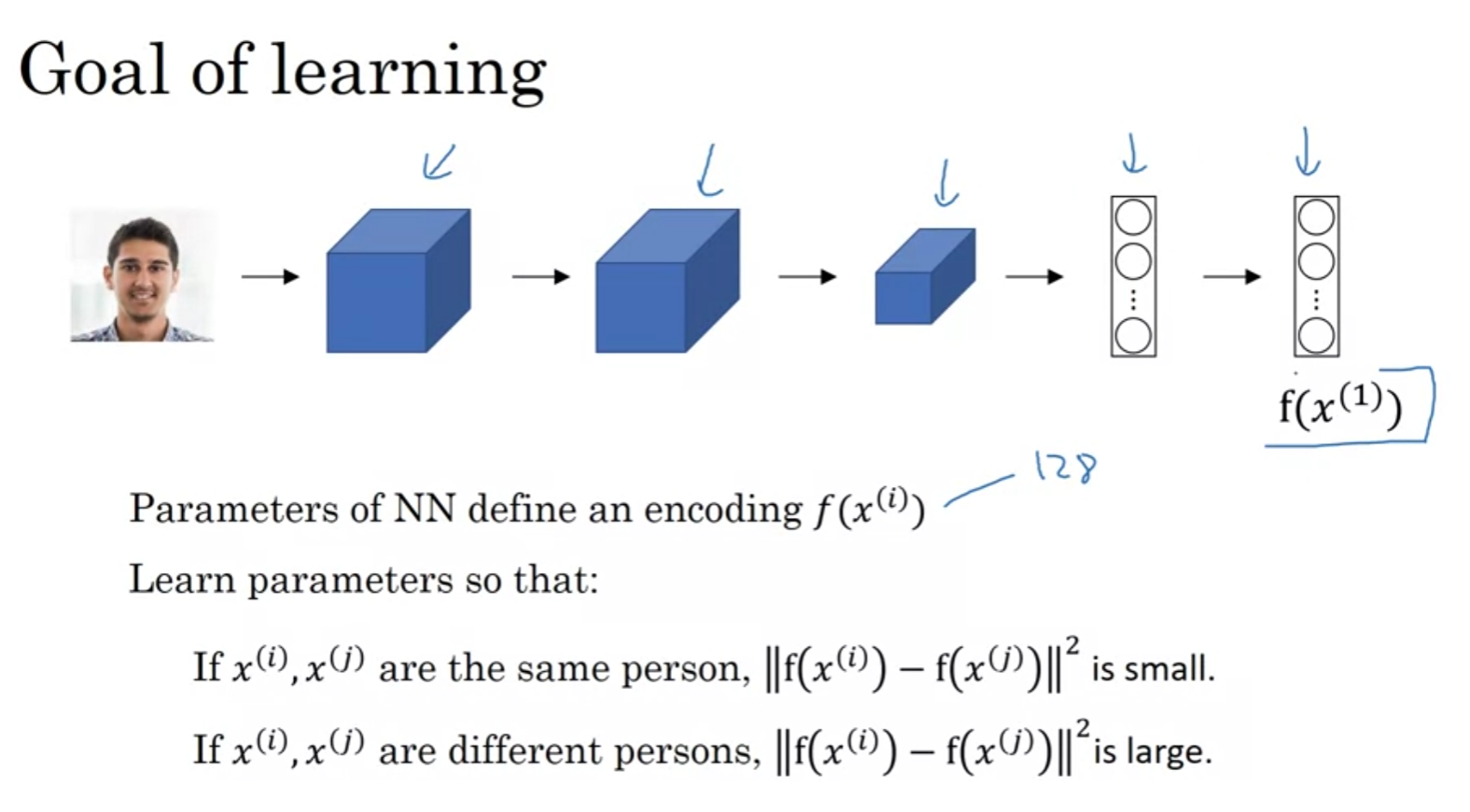
새로운 이미지가 들어왔을때 원래 데이터베이스에 있던 이미지를 같은 네트워크에 넣을 필요없이 마지막 값을 기억하고 있는게 더 효율적임
🧠Neural style transfer

요렇게 하나의 content에 style을 추가하는 것이 Neural style transfer이다.
What are deep ConvNets learning?
각 레이어의 출력인 피처맵을 시각화하면 어떤 뉴런이 강하게 반응하는지 확인할 수 있음. 뉴런을 고도로 활성화한 이미지 패치를 layer 마다 뽑아 봤음

뒤로 갈수록 receptive field가 커지면서 high-level feature들을 추출하는 것을 볼 수 있다.
Cost Function

cost function은 다음과 같다.
hyperparameter를 다르게 두는 것을 확인하자.

Gradient descent를 적용하면 점차 그럴듯하게 변해 나간다.
Content Cost function

Content cost function은 위와 같음
임의의 layer를 정한뒤 activation값의 차이를 구함
Style Cost function

각 channel들이 얼만큼의 correlation을 가지고 있는지를 측정하고
이를 비교해서 cost function을 구성한다.
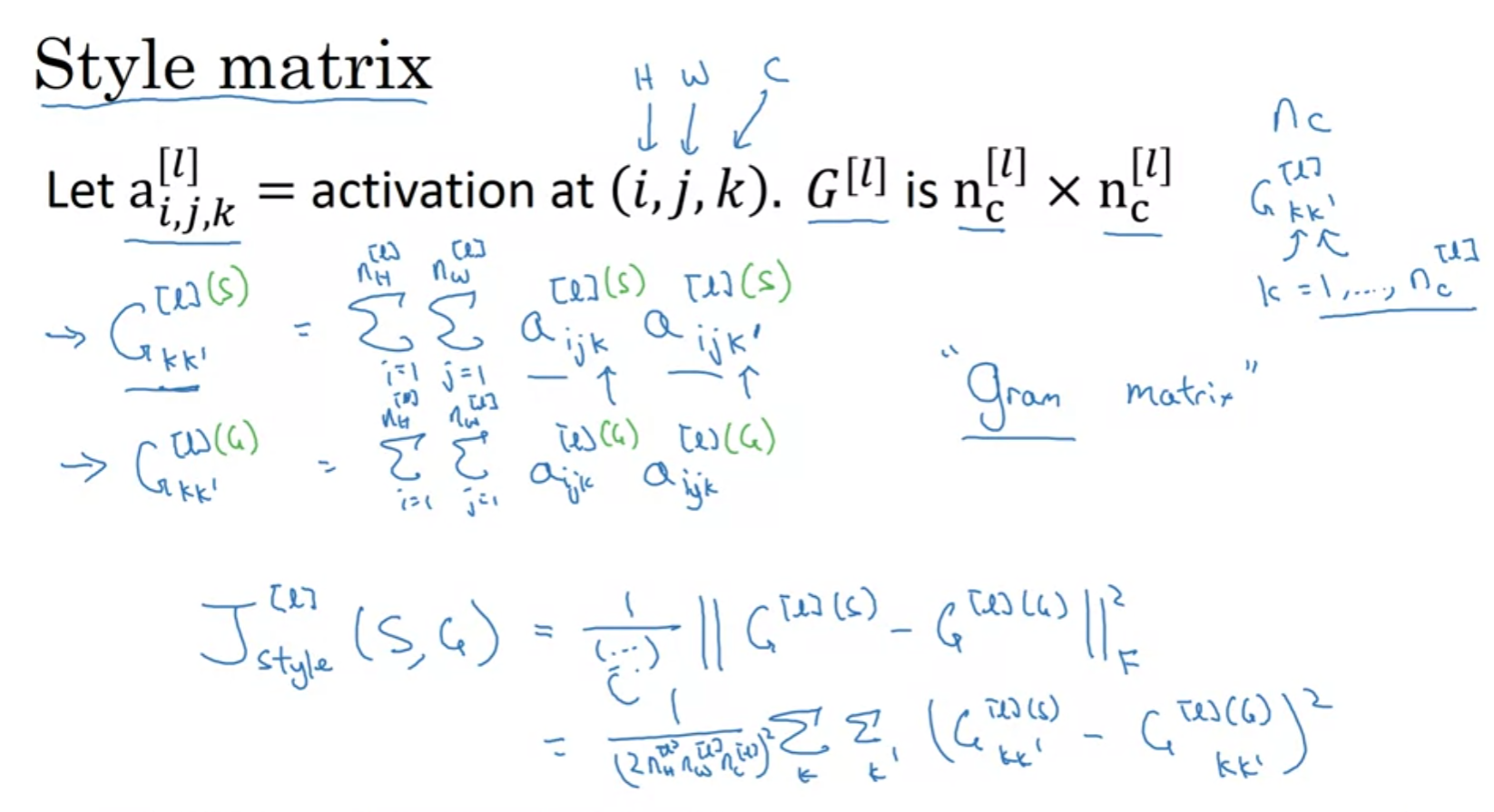
element-wise product가 아닌 2차원 배열을 1차원 벡터로 평탄화해서 dot product를 진행한다는 것을 알아두자.

layers that are not too deep capture the detailed content of the image, such as textures and specific shapes
