NLP로 왔습니다.
종합설계 할 때 정말 빡세게 공부했었는데
정리안해놓은 걸 조금 후회하고 있어요.
제가 좋아하는 part이므로 자세하게! 정리해보도록 하겠습니다.
🔄️Recurren Neural Networks
What is RNN?
기존의 DNN으로 Sequential data를 다루기엔 크게 두가지 한계점 이 있다.
첫째, 모든 데이터들이 길이가 다 다르다.이는 곧 Nerual Network 아키텍쳐 하나를 정해서 범용적으로 사용할 수 없음을 의미하고 다양한 길이의 데이터를 처리할 수 있는 새로운 신경망 아키텍처에 대한 필요성을 시사한다.
둘 째, 문장이든 주식 data든 그 데이터의 위치가 정말 중요하다. 하지만 DNN은 위치에 대한 정보를 함유하지 못한다.
그래서 등장한게 바로 RNN이다.
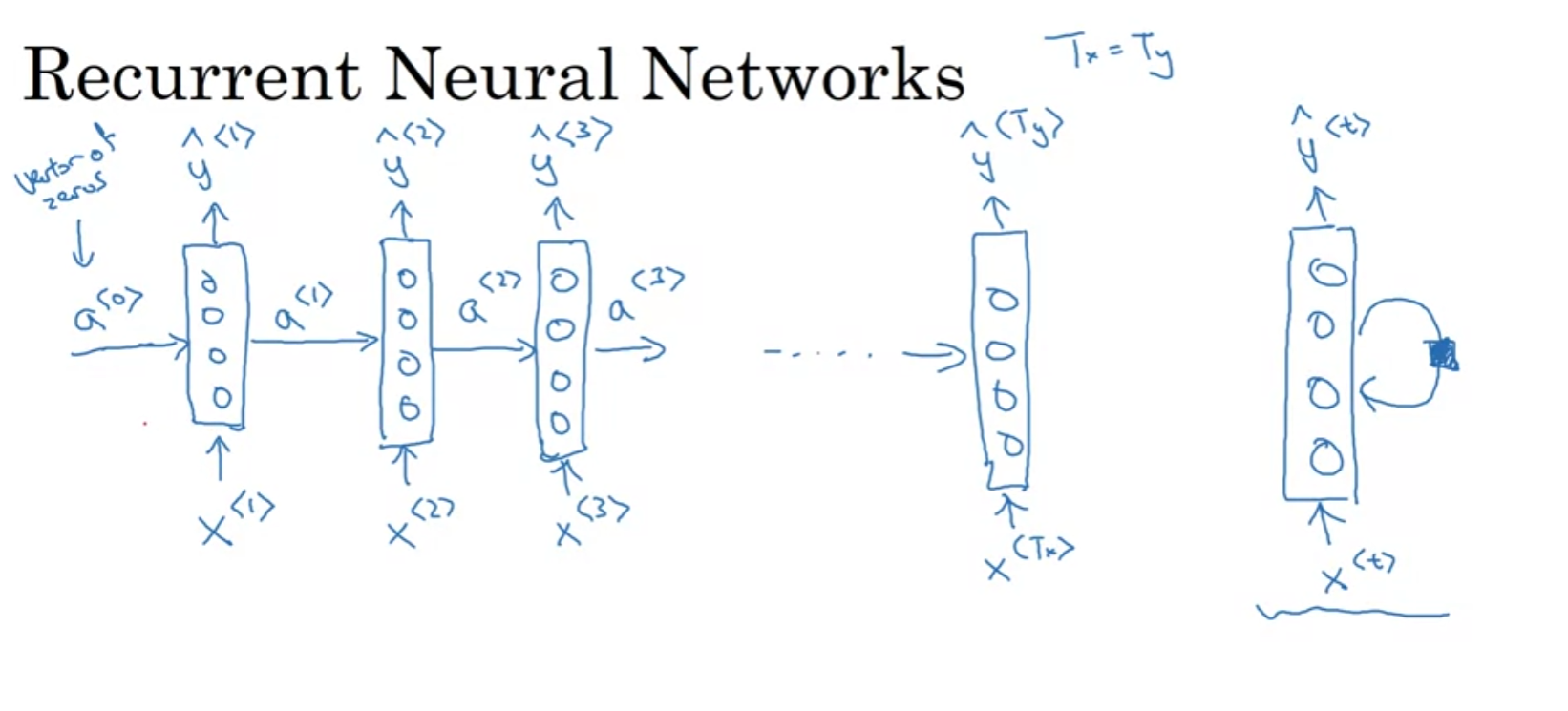
아래는 RNN cell이다.
RNN의 중요한 특징중 하나는 같은 파라미터를 공유한다는 것이다.
입력 x1이 y1,a1을 출력하고 a1은 x2와 함께 다음 layer로 전이 된다. 이렇게 시점에 따라 입력과 출력, 은닉 상태가 변화하지만, 사용되는 가중치는 동일하다.
또 위에서 제공된 아키텍쳐는 출력할때 뒤에 있는 데이터는 전혀 고려하지 않는다.
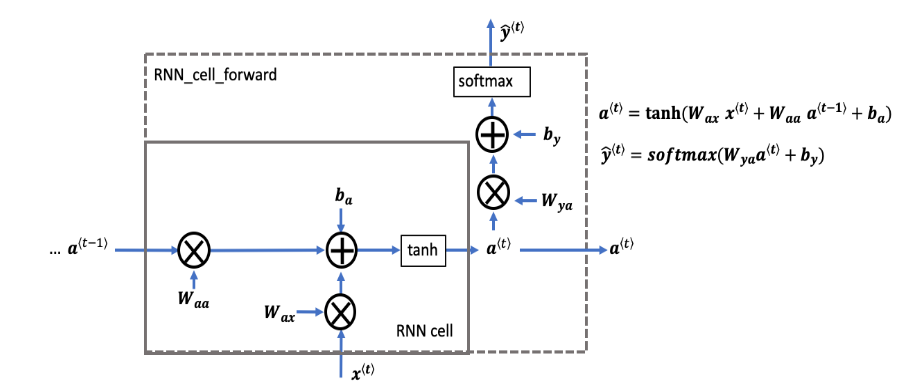
구체적인 아키텍쳐는 위와 같다.
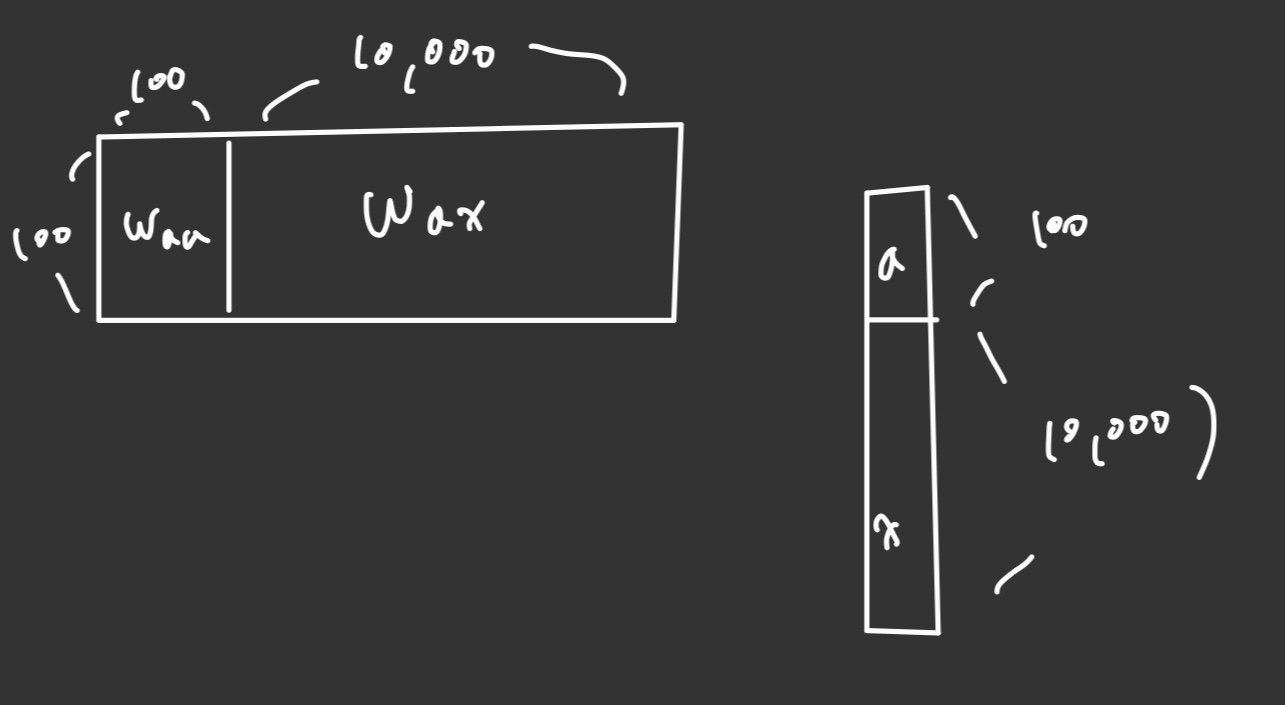
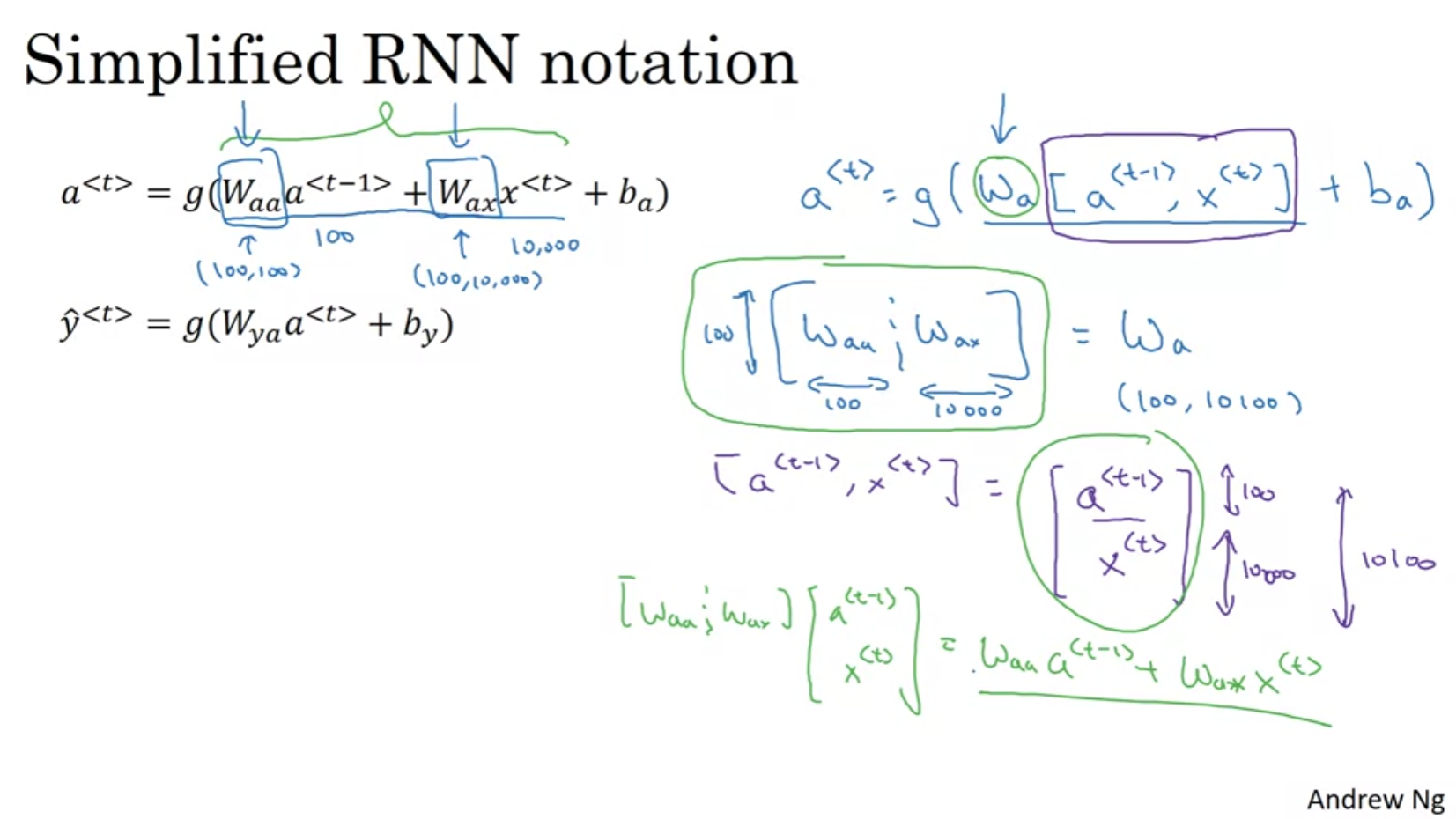
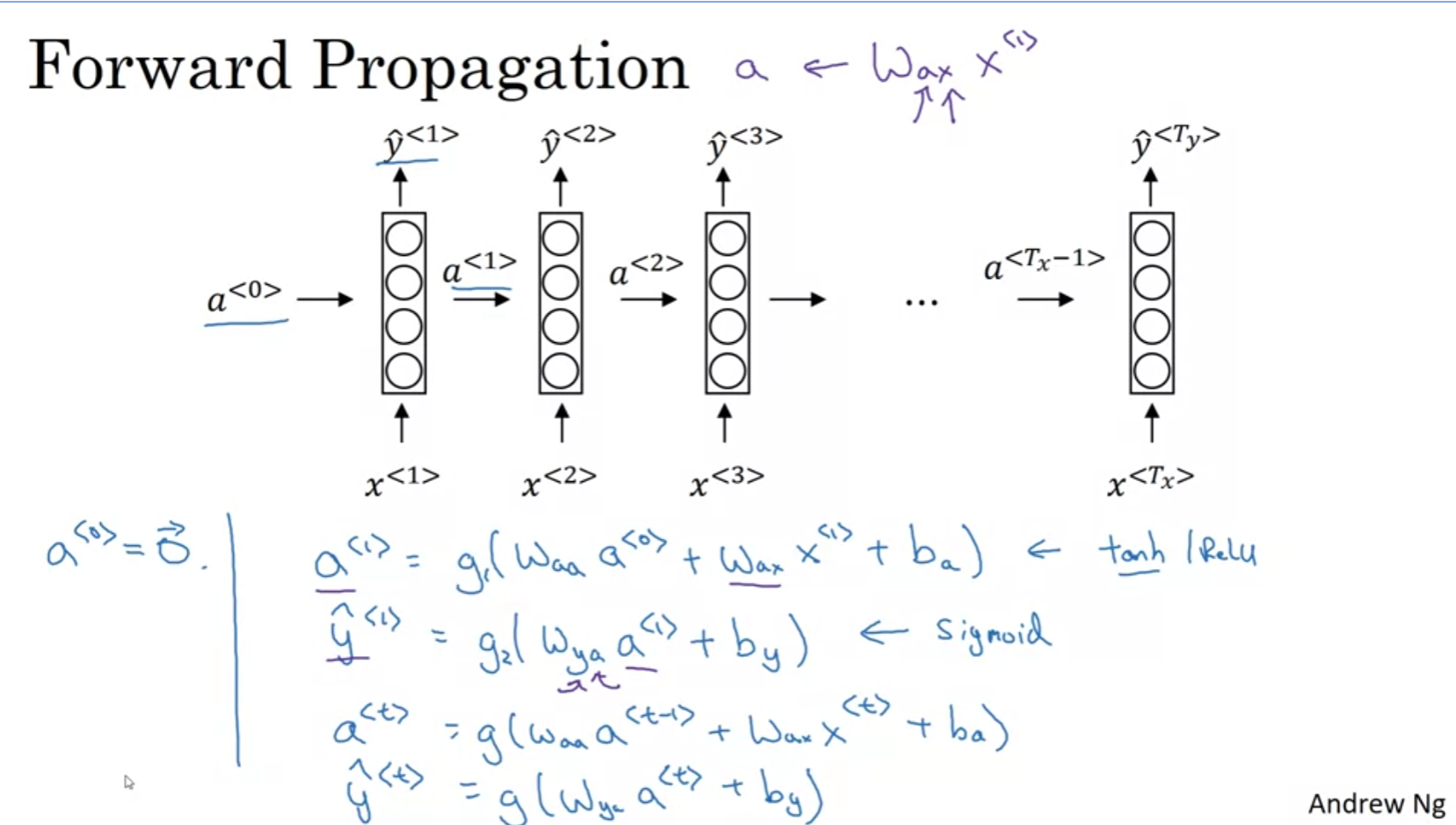
수식을 행렬의 곱으로 simplify 시킬 수 있겠다. 저 그림을 보면서 계속 가시화 해보자 머릿속으로.
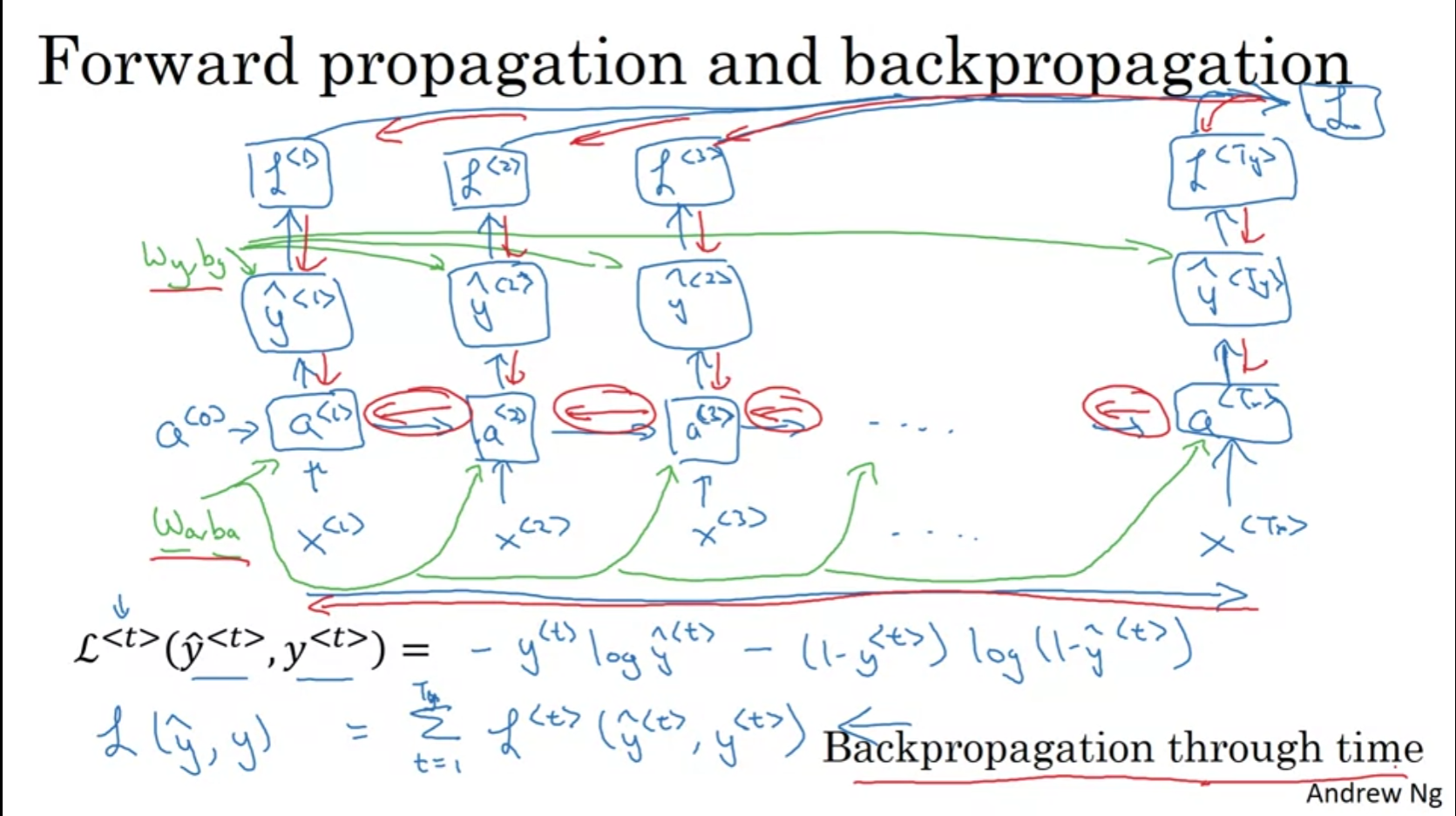
Loss는 매 순간 마다의 loss의 총합이고 역시 back prop이 가능하다.
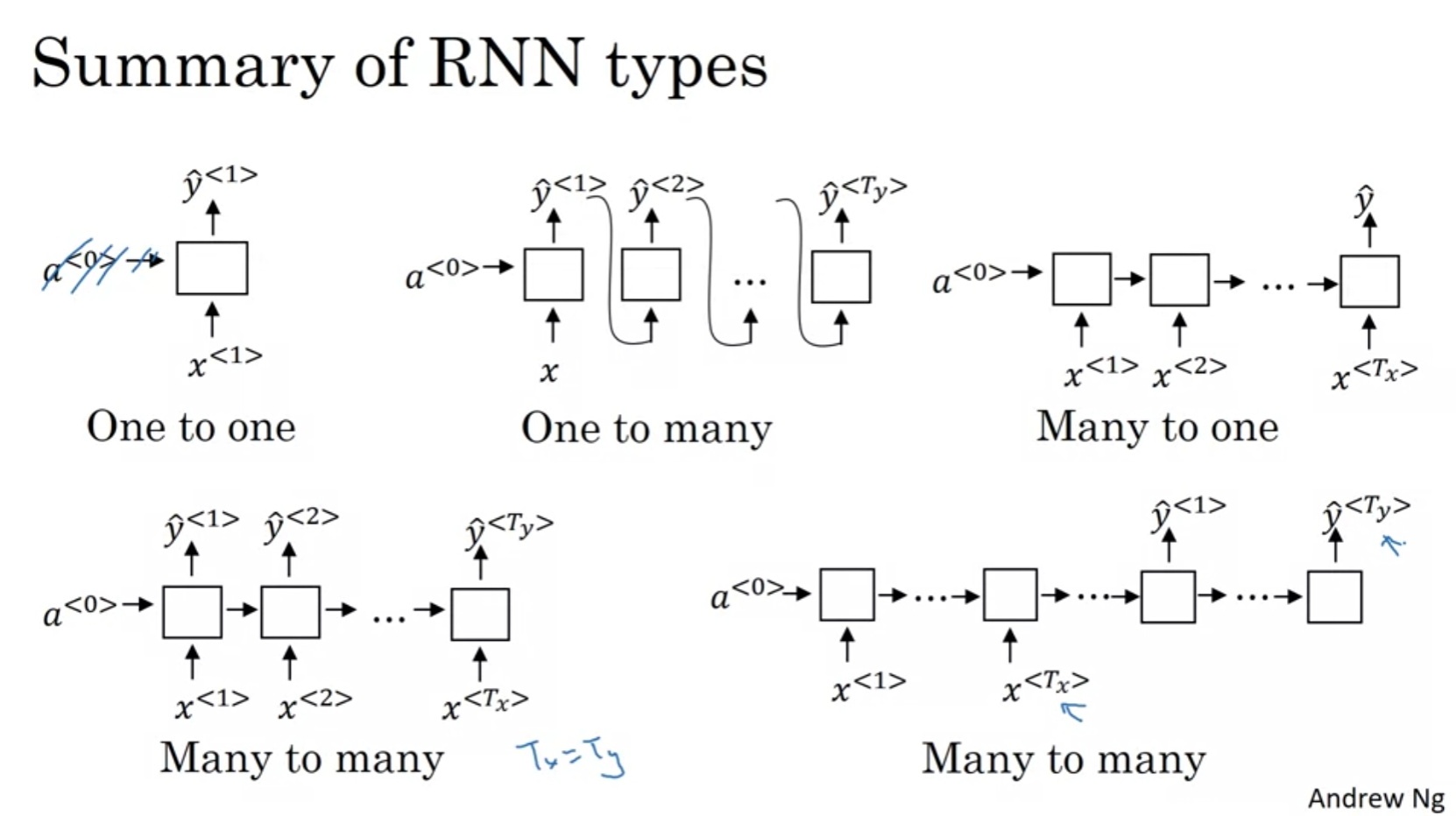
Different Types of RNNs
우리는 꼭 input 개수에 맞춰 output을 출력 할 필요는 없다.
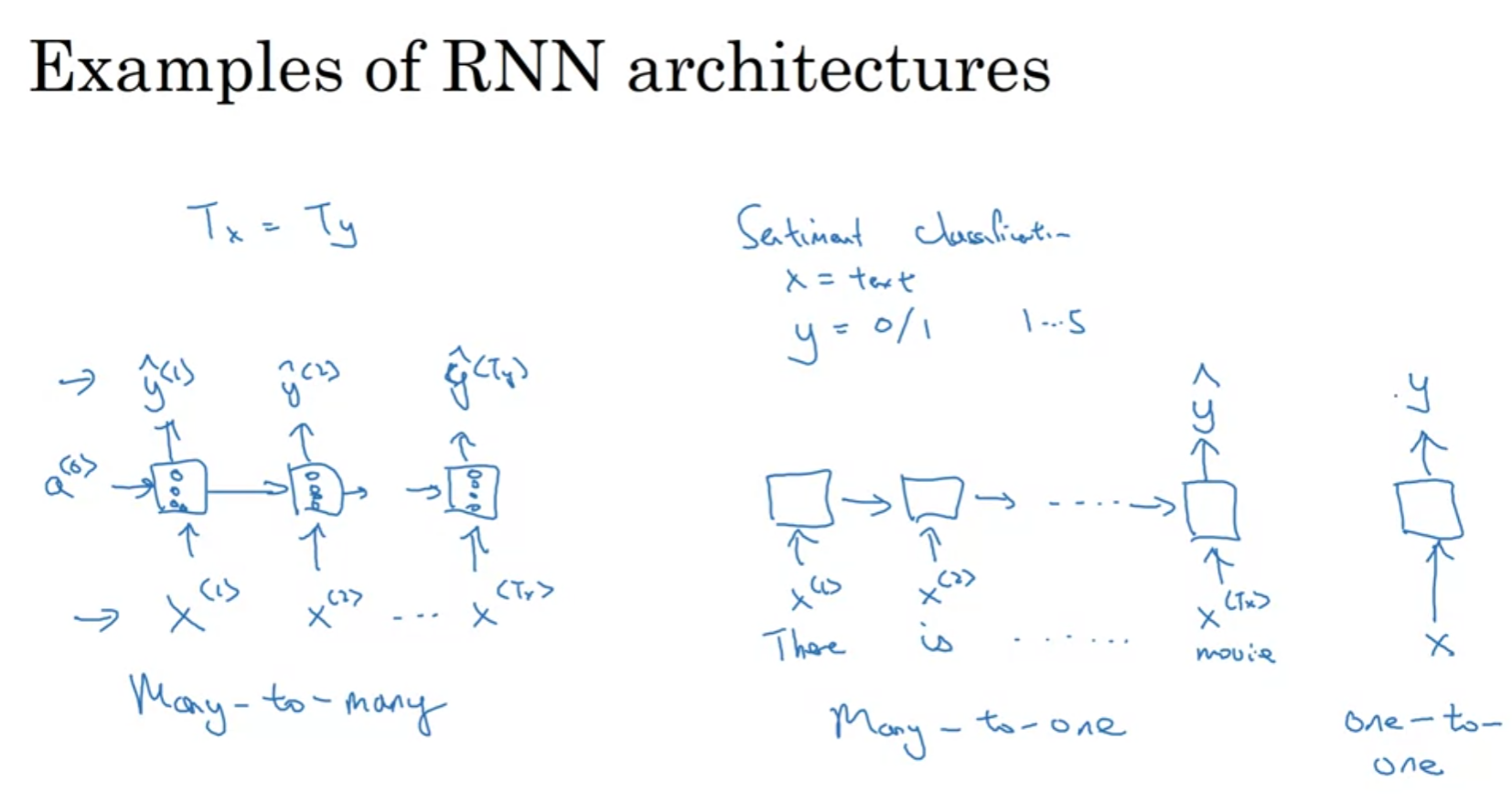
input이 바로바로 나와야할 필요도 없으며 가변적인 출력을 할 수 있어야 한다.
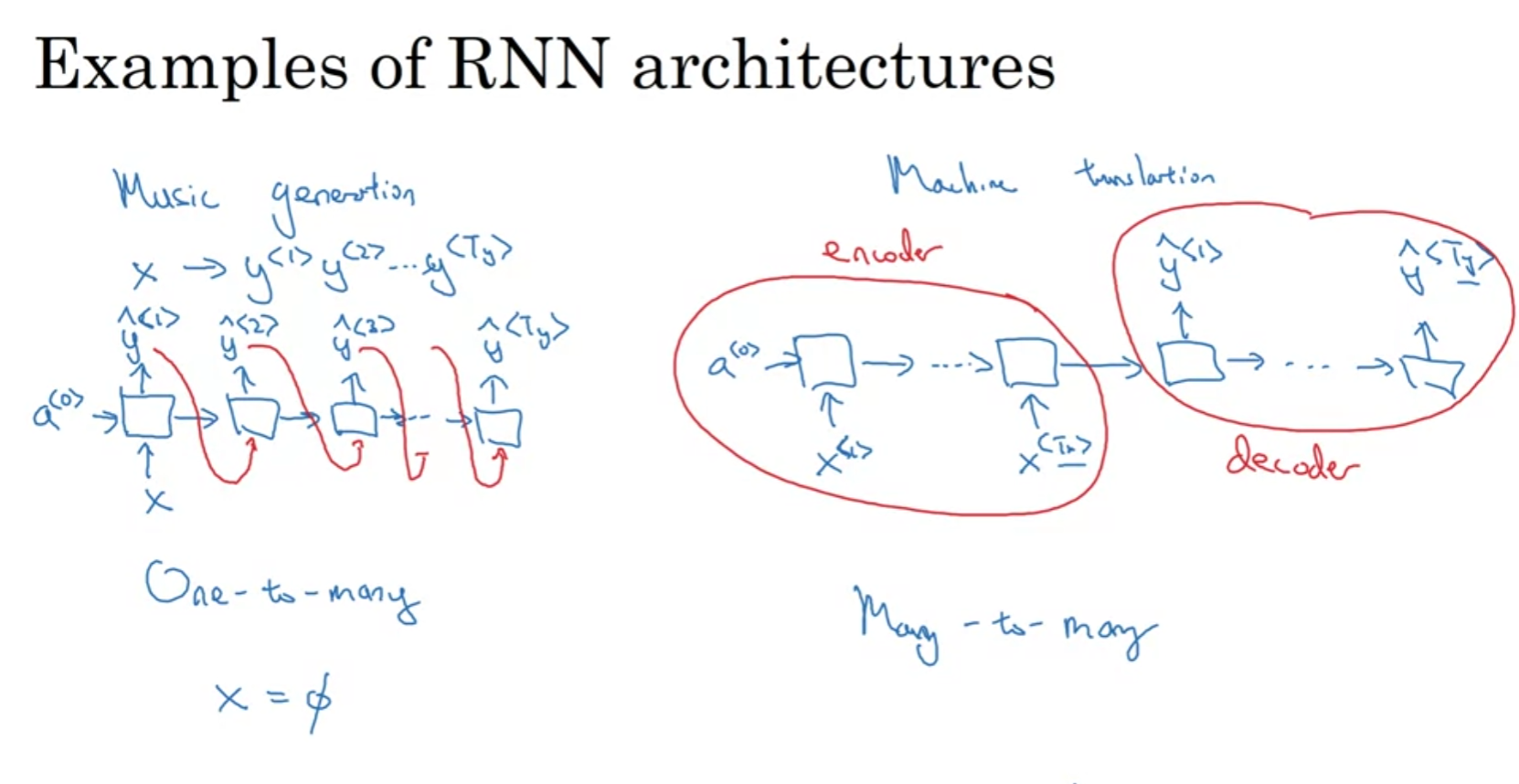
위와 같이 many-to-many , one-to-many, many-to-one 등등 다양한 형태가 있음.
Language Model and Sequence generation
먼저 language model을 이용해서 학습을 시킬때는 먼저 target들을 토큰화 시켜야 한다.

단어 set에 없는 토큰들은 unk로 따로 분류된다는 것을 takeaway하자.
단어들을 tokenize했으면 이제 학습을 진행해야된다.
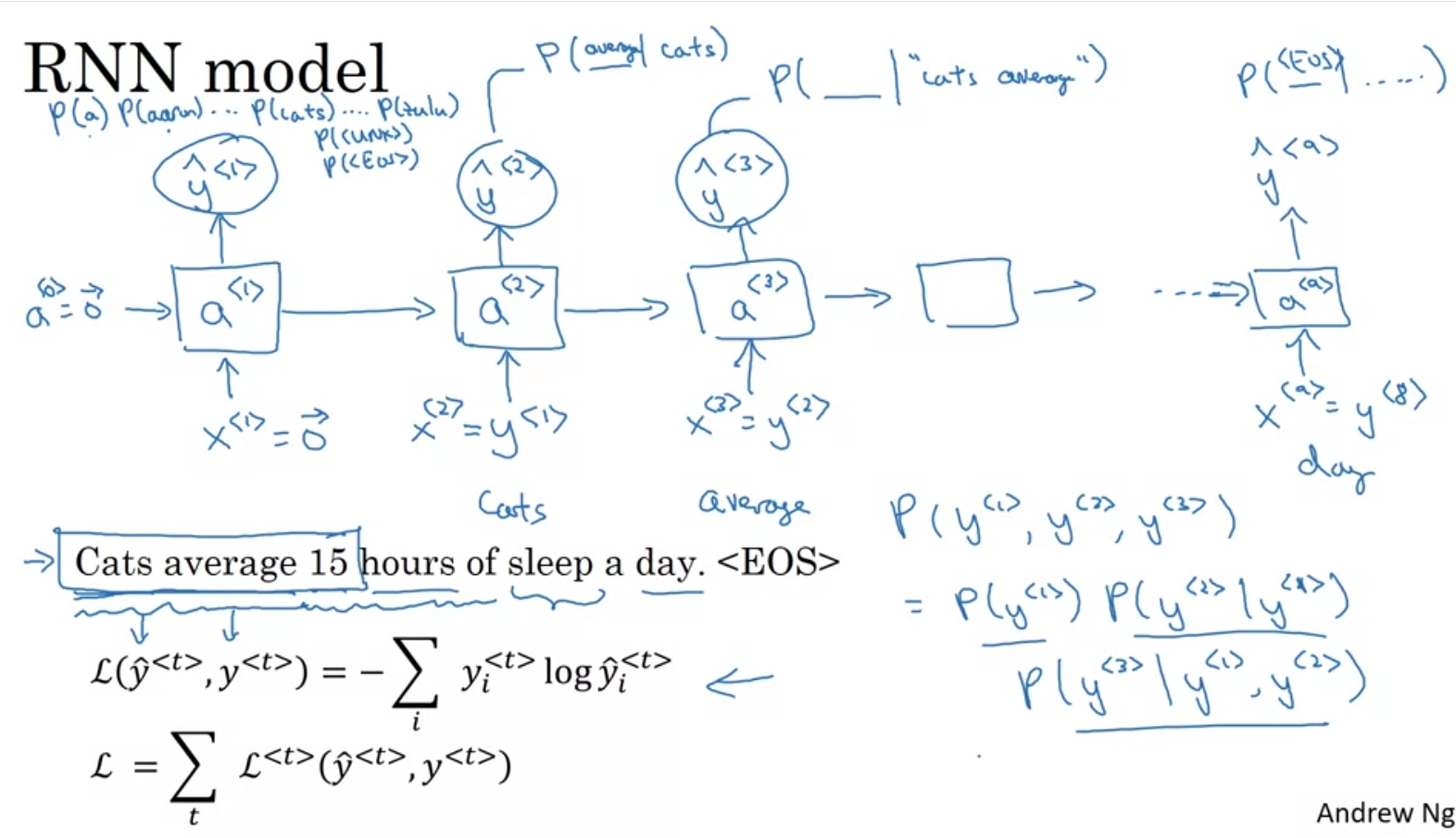
각 input에 대한 output이 정답일경우 다음 input으로 넣는다.
다음과 같이 CE Loss를 전부 다 합친다. (teacher forcing 은 안나오나..?)
Sequencing은 단어 단위로 할 수 있고 글자 단위로 할 수 있는데
계산비용 측면에나 의미추출 측면에서나 전자를 쓰는게 더욱 좋다.
🧑💻 GRU
RNN의 문제는 초기의 정보를 뒤로 갈수록 잃는다는 것이다. (activation이 곱해질 수록 초기의 정보는 0에 수렴하게 됨)
이것을 해결하기 위해 나온게 GRU이다.
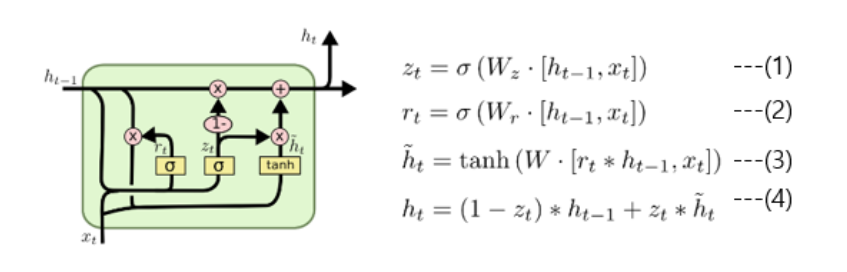
reset gate를 구하는 공식은 위 그림에서 (2)식에 해당된다. 이전 시점의 hidden state와 현 시점의 x를 활성화함수 시그모이드를 적용하여 구하는 방식이며 결과값은 0~1 사이의 값으로 이전 hidden state의 값을 얼마나 활용할 것인지에 대한 정보로 해석가능
4번의 Update gate는 과거와 현재의 정보를 각각 얼마나 반영할지에 대한 비율을 구하는 것이며 z=0일때는 현재의정보를 무시하겠다는 의미이다.
💡LSTM
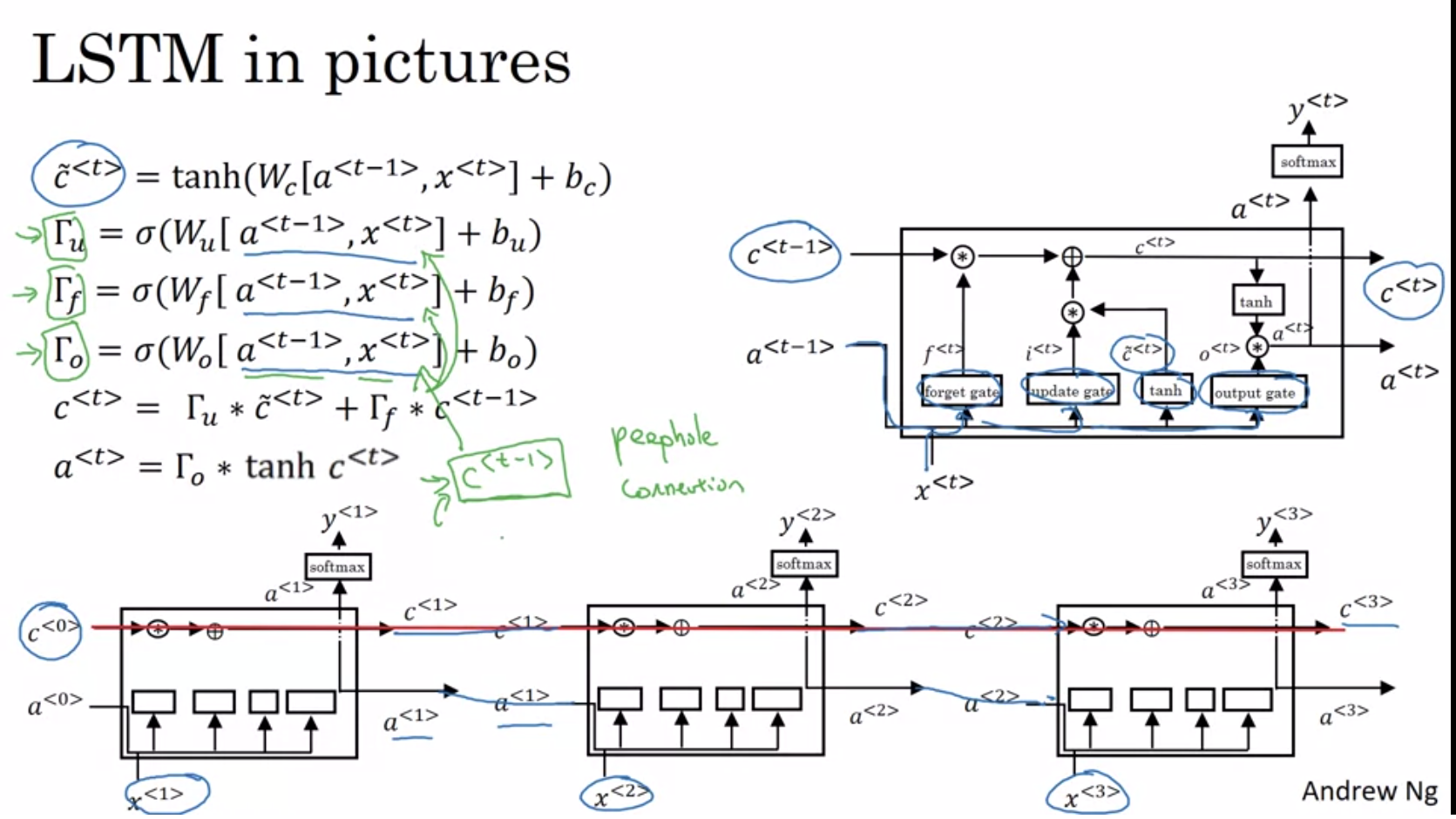
LSTM은 Cell state라는 장기기억메모리 역할을하는 값이 있다.
Bidirectional RNN
He said Teddy 라는 문장을 봐보자.
우리는 이 맥락만 보고서는 다음에 나와야 할 단어가 bear인지 Rousebelt인지 알 수가 없다. 근본적인 RNN의 문제점이기도 한데, 이를 해결하기 위해서 고안된게 Bidirectional RNN이다.
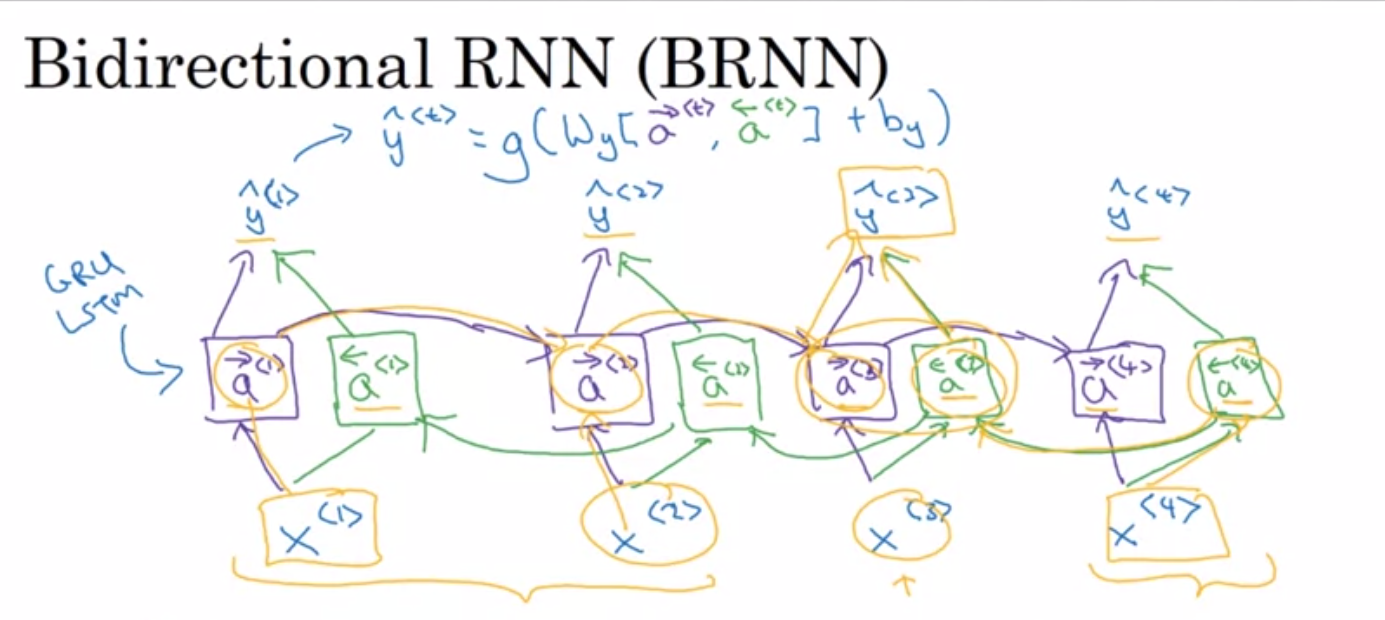
위와 같이 역방향으로 학습되는 네트워크도 둔다음 그 둘을 합산해서 출력을 결정한다. 문장이 통째로 전부 필요하기 때문에 real-time speach recognition problem에는 적절치 않겠죠.
Deep RNN
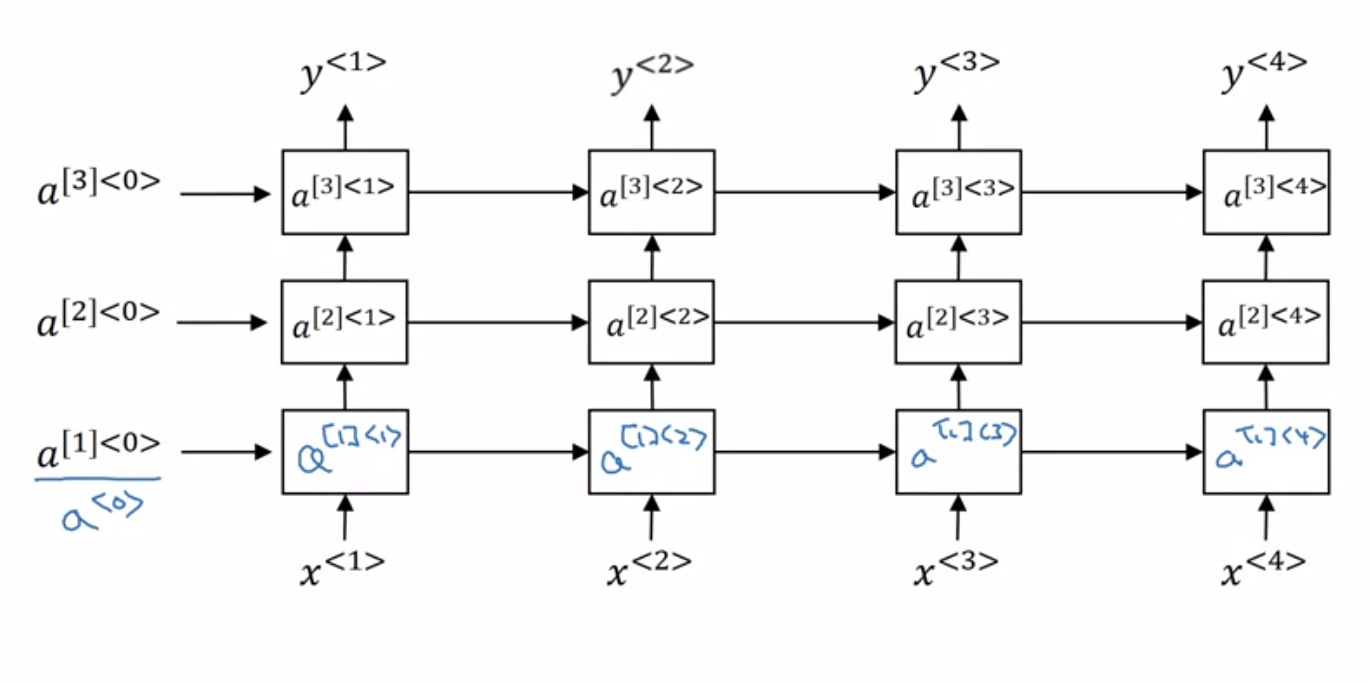
다음과 같이 layer각 겹겹이 쌓인 Deep RNN 아키텍쳐도 있다.
트랜스포머가 생각나네요
