💡SENet
2017년 1등한 친구. (파라미터수 6600만)
SE block은 아래와 같다.
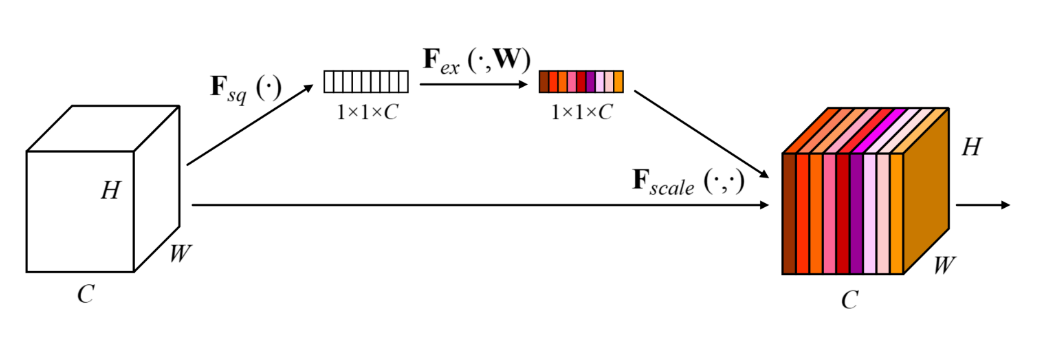
HxWxC 의 feature map을 GAP 한후 FC Layer 두층을 통과시킨 다음 그 값을 각 특징 맵 채널 에다가 곱해준다.
FC Layer는 C -> C/16->C 형태의 네트워크다.
파라미터가 너무 많이 늘어나는 것을 방지하기위해 reduction ratio 를 16으로 제안
어떤 feature가 중요한지 학습하는 것 같다.
✅성능
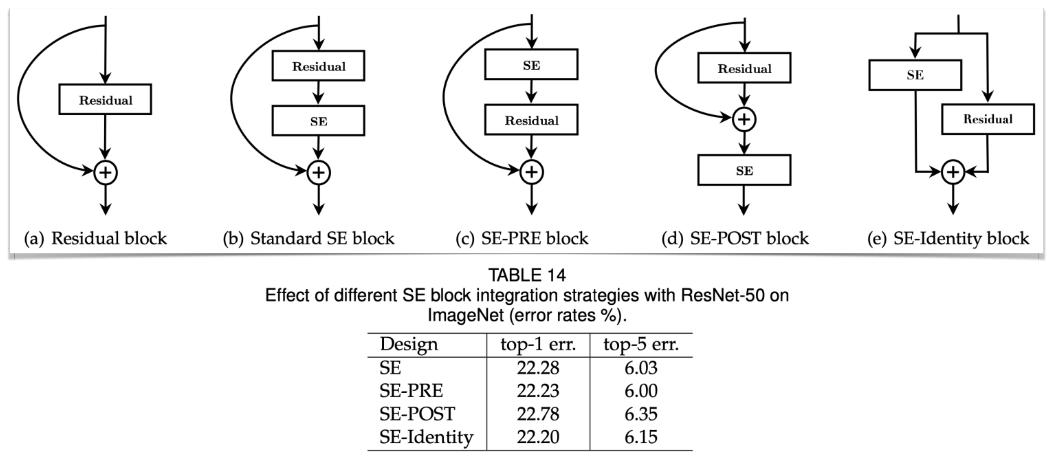
위치를 바꿔가면서 실험해봄 (b) ,(c)의 성능이 잘 나오더라~
✅1x1 conv와 비교
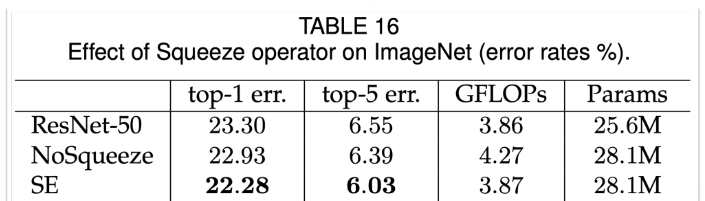
c/16, c 채널 짜리의 conv 1x1 채널을 사용하면 같은 파라미터수를 가지게 할 수 있다.
비교 결과 SE성능이 훨씬 좋게 나옴
💡MobileNet
✅Depthwise separable conv
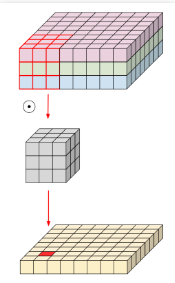
기존의 conv는 공간 축, 채널 축에 대해서 한꺼번에 정보를 엮은 것
conv filter가 3x3x3x16개의 파라미터를 사용
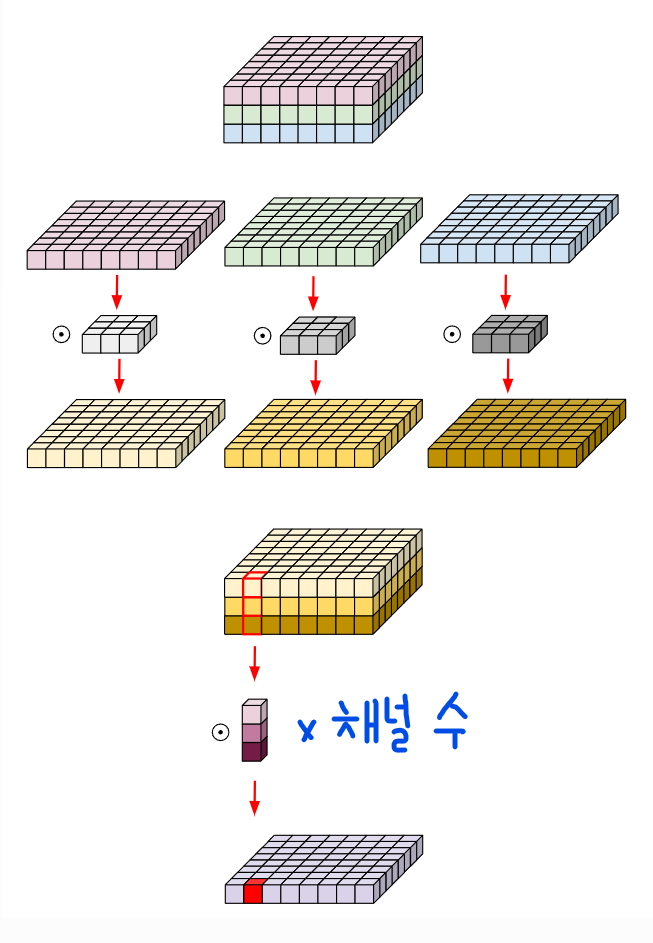
따로따로 하면 좀 더 역할 분담을 잘하지 않을까?
공간 정보를 먼저 엮고 그다음에 채널 정보를 엮자!
depth-wise conv는 3x3x3+3x16개의 파라미터를 사용한다.
6배 차이!!
✅아키텍쳐
논문에 오타가 있다..
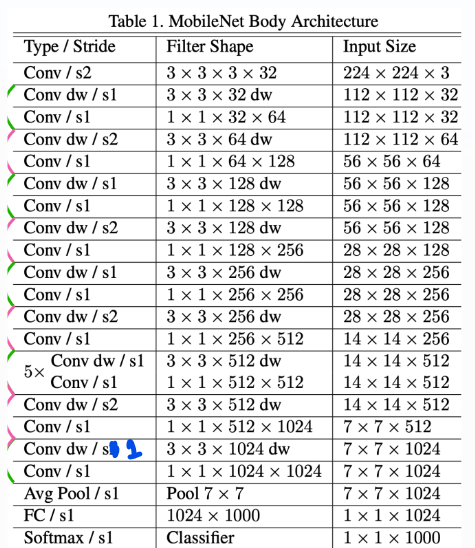
각 Conv 이후 BN+ReLU가 있다는 것을 잊지말자.
파라미터수가 엄청 적어서 regularization 및 data augmentation도 소극적으로 활용했다고 함 (Overfitting이 잘 안 일어나서)
음 깊은 네트워크(많은 파라미터)에서 오버피팅이 자주일어나는 이유는
뉴럴 넷이 딥할수록 섬세한 feature들을 잘 캐치하는데
특정 feature가 대상의 general 한 feature가 아니라 노이즈임에도 불구하고 어떠한 특정 feature의 가중치를 많이 두게 되면
노이즈 까지 학습하는 뉴럴넷이 될 수 있다.
예를 들어서 고양이를 학습하는데 딥한 네트워크를 사용한다 가정하자
점이 있는 고양이사진이 많이 들어가면 점은 고양이를 식별하는 general한 feature가 아님에도
이러한 세부정보에 큰 가중치를 주게되면 Overfitting이 발생할 수 있음
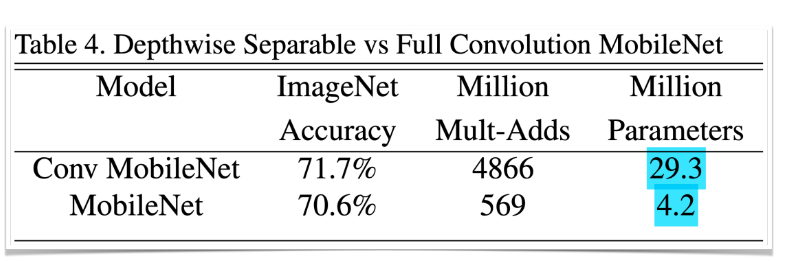
성능은 비슷한데 파라미터수는 거의 7배차이.. ㄷㄷ

width 0.75배 한거랑 레이어수 줄인거 비교
5번 반복하는 부분 없애서 깊이를 줄였더니 난리가 나더라~~ => 줄일거면 width를 줄이자
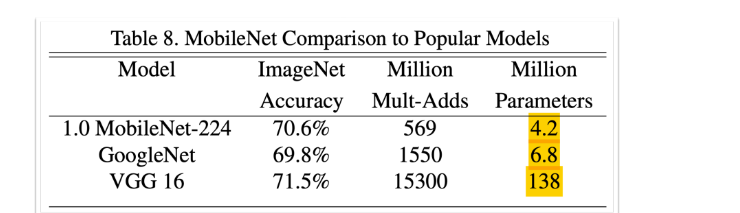
정말 미친 효율이다
MobileNet v2
ResNet에서 dim을 줄이고 ReLu까지 쓰는 BottleNeck구조는 너무 많은 정보손실을 야기한다고 주장
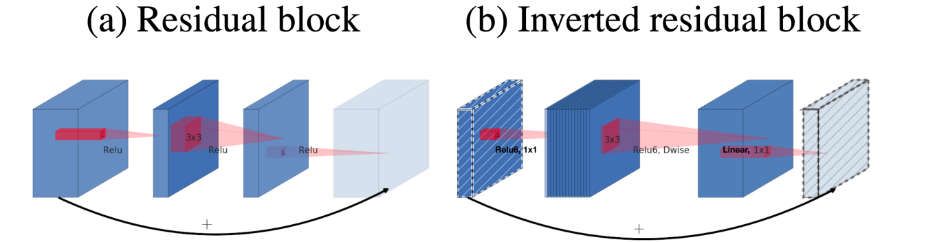
하지만 dim을 키우면 파라미터수가 늘어나니 Dep-sep Conv를 이용함
그리고 block의 마지막 부분은 ReLu없이 Linear activation 함
(정보 손실을 줄이자!)
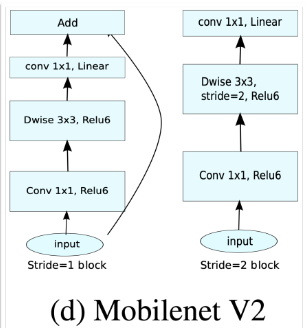
stride 2인 block에서는 skip-connection 안해버림
사이즈 키우고 Dep -Sep 하는 것을 볼 수 있다.
아키텍쳐
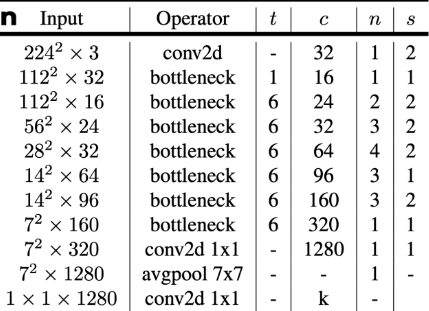
구조는 일케 생김
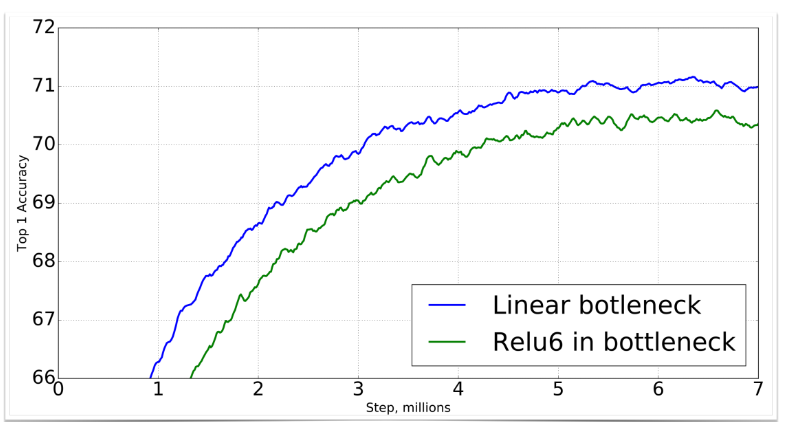
linear로 바꿔줬더니 성능이 훨씬 더 잘 나온 모습
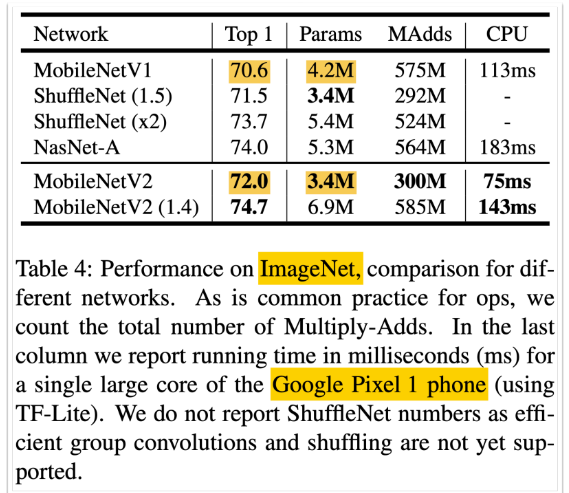
성능 짱 (작고 좋음)
MobileNet v3
SE-block 적용 + 새로운 activation 제안, 입출력 구조변경을 제안한 2019년에 나온 모델이다.
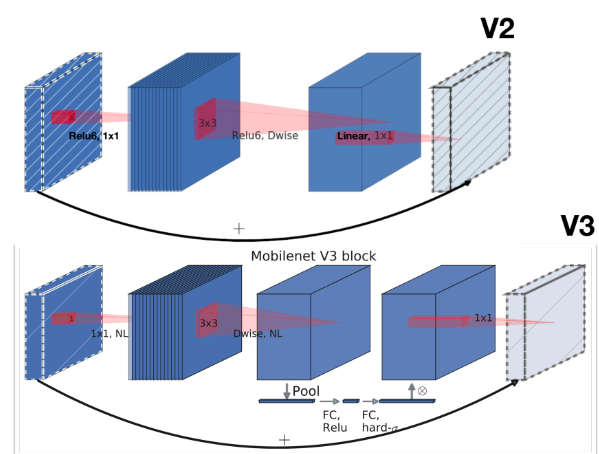
reduction ratio=4를 채용
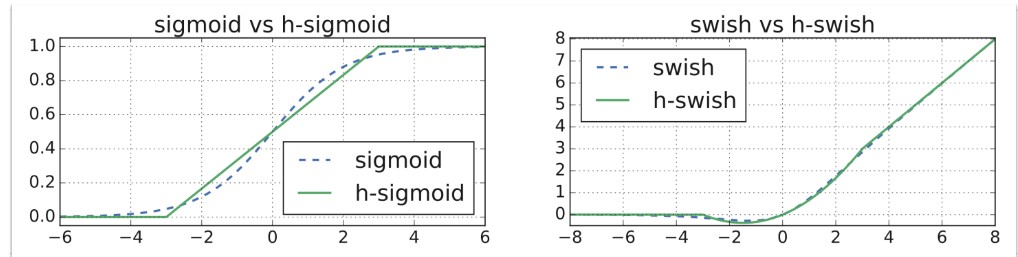
새로운 activation을 제안함
e-x 는 지수 연산을 의미하며, 이는 CPU 사용률을 높이고 더 많은 전력을 소비하게
Swish =x * sigmoid(x)인데,
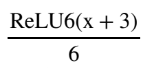
요게 hard sigmoid,시그모이드를 좀 딱딱하게 만든 모양이다.
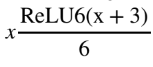
요게 Hard swish
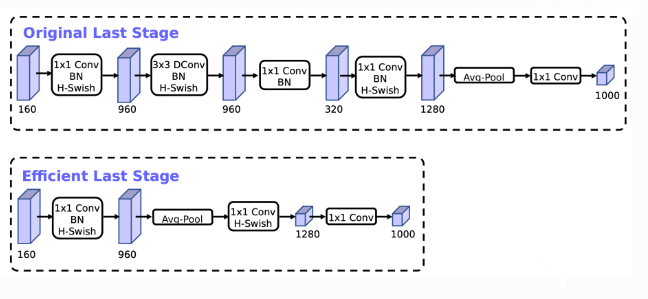
마지막 블록에 Dep-sep을 없애버림 (channel 키우고-GAP-FC-FC)
아키텍쳐
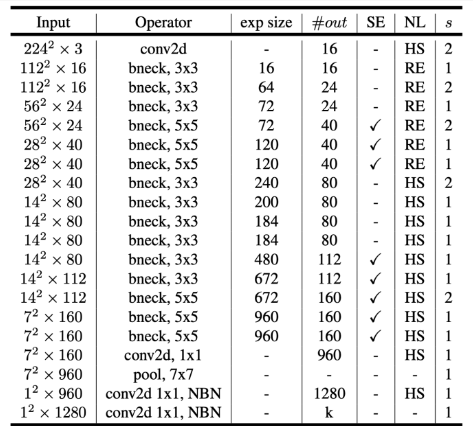
NAS(Neural Architecture Search) 사용해서 아키텍쳐를 결정함 ( 강화학습 )
NAS is a process where a machine learning algorithm is used to design new neural network architectures automatically. Instead of a human deciding how the neural network should be structured, NAS algorithms try out many different structures to find the one that works best for a specific task, like image recognition or language processing.
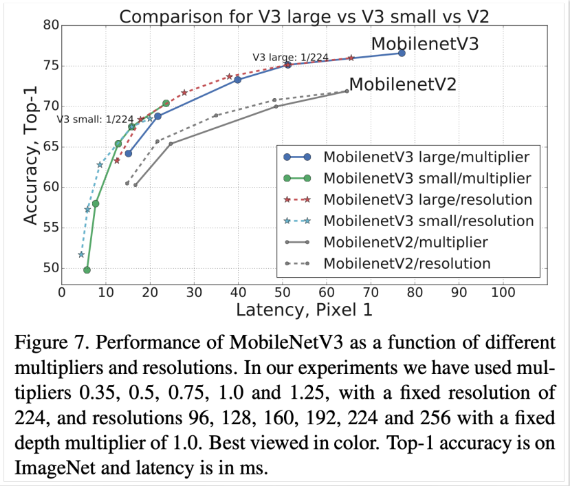
latency(연산량)는 비슷하지만 accuracy가 더 크다!
EfficientNet
대망의 EfficientNet이다.
depth, width, resolution 모두 늘려보자!
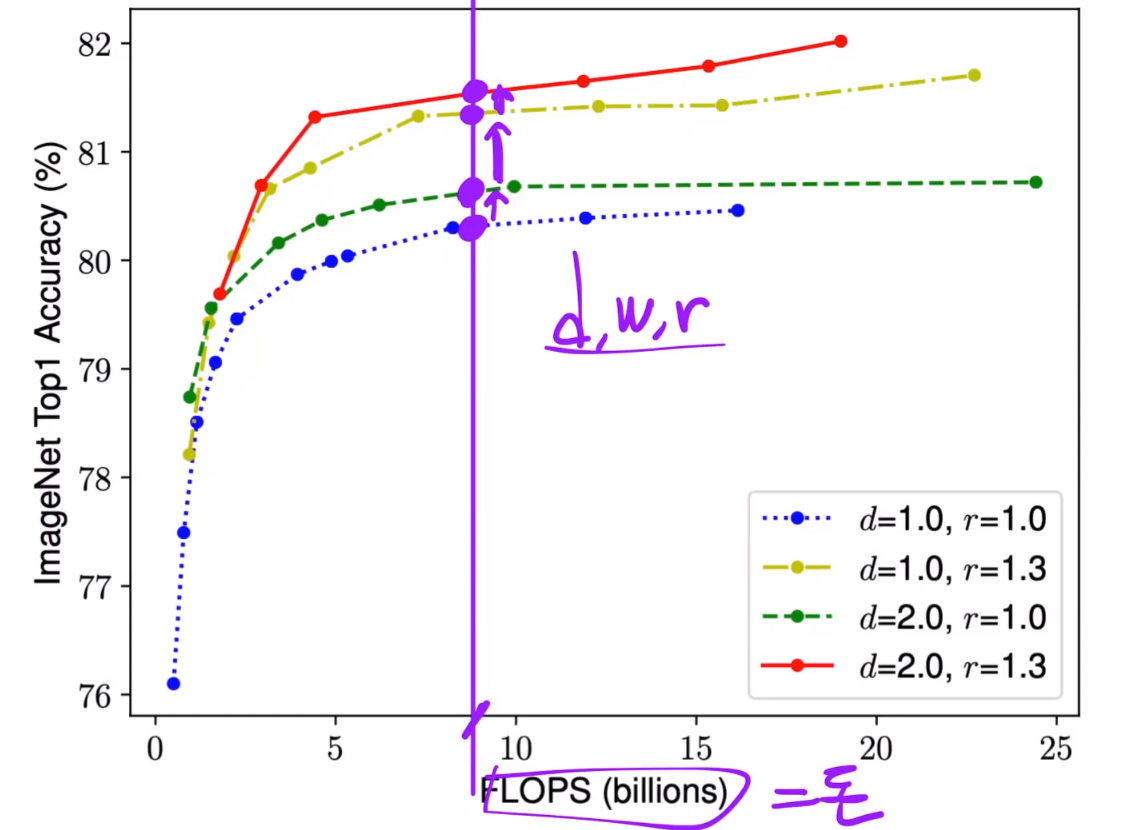
알맞은 d , w, r을 찾아보자 !
d를 2배 키우면 연산량 2배,
width를 2배 키우면 연산량 4배, (4=>8 -> 8=>16)
resoltion을 2배 키우면 연산량이 4배 늘어남
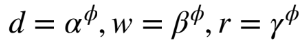
다음과 같이 놓고
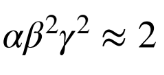
이게 2를 만족하게 조절을 하는데 이는 연산량을 2배 키운 모델을 의미한다.
최적의 a,b,r을 구하고 파이값을 천천히 올려서 Optimal한 모델을 찾음
아키텍쳐
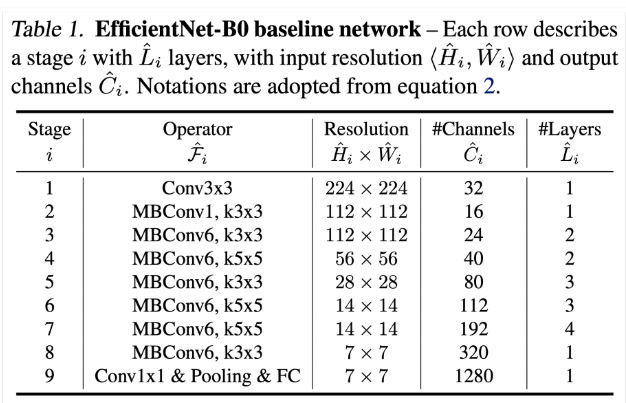
랜덤하게 residual을 skip하는 stochastic Depth 기법 사용
activation은 전부 Swish를 사용함
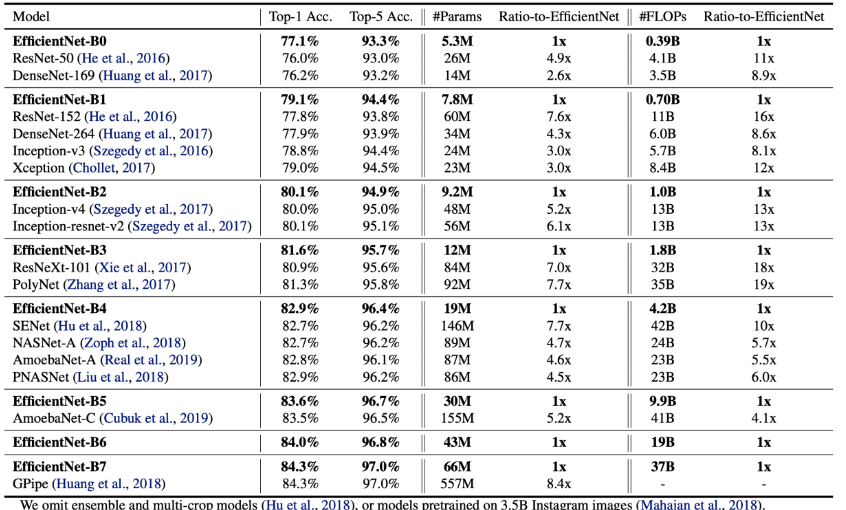
엄청한 효율입니다.
