
💡Seq2Seq
이전에 봤던 RNN과 LSTM의 모델에는 몇가지 문제점이 존재했음
RNN 기반 모델은 1:1 realationship을 가정하고 학습 및 추론을 했는데 input sequence와 출력의 길이가 다를 때도 있을 수 있음
ex) vamos => Let's go
그리고 꼭 x1 이 y1에 대응되리라는 법도 없다.
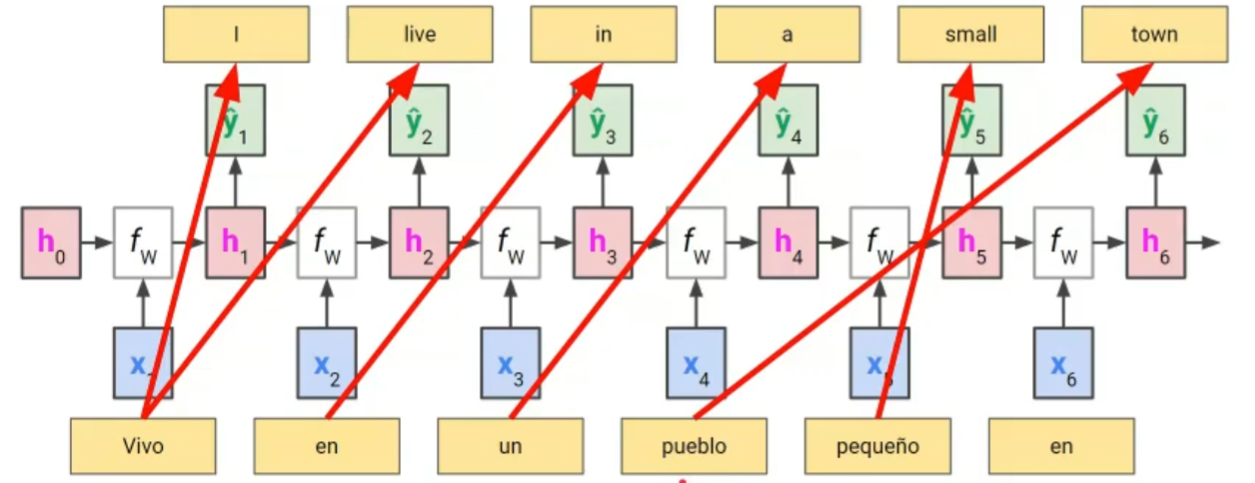
이렇게 순서가 바뀌게 되는 경우들도 허다함=> 번역문제에는 적합하지 않다.
그래서 나온게 Seq2Seq!
✅Encoder-Decoder Structure
들어올때마다 일일히 번역하지말고 일단 쭈욱 읽어라~ 히든 state에다가 문장의 내용을 기억하고 있음
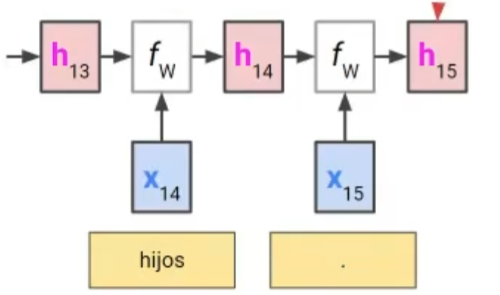
문장 전체의 내용이 저 h15에 들어가 있음 (context vector)
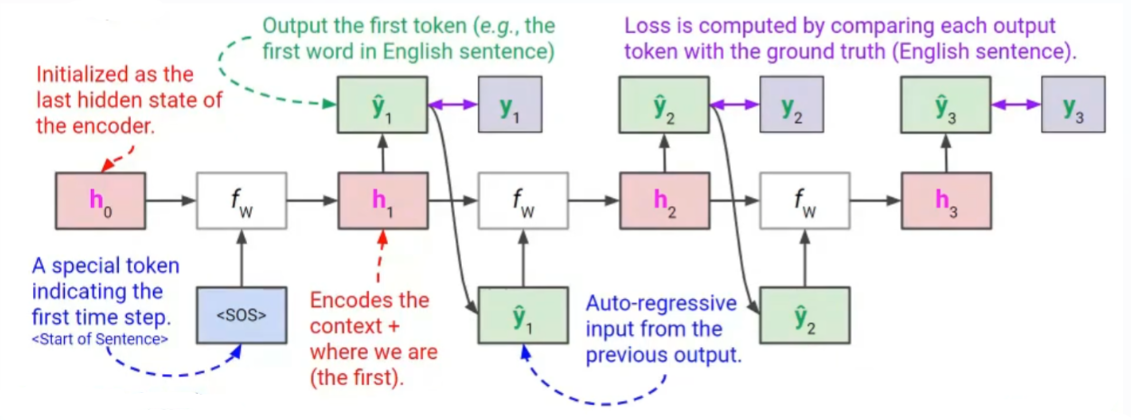
프로세스를 간략히 설명해보자면
먼저 인코더부분에서 뽑아온 hiddent state와 sos값을 연산해서 h1을 출력 => h1을 affine+softmax함수를 통과시켜서 y1 출력함
학습때는 teacher forcing을 하지만 inference할때는 y1을 그대로 가져와서 h1와 또 연산함.
이 과정을 계속 반복해서 (auto regressive하게 돌아감) 최종적으로 나온 값들에 대해서 각 타임스텝에서의 손실을 합산하여 최종 손실을구한후 back-prop해준다.(BPTT)
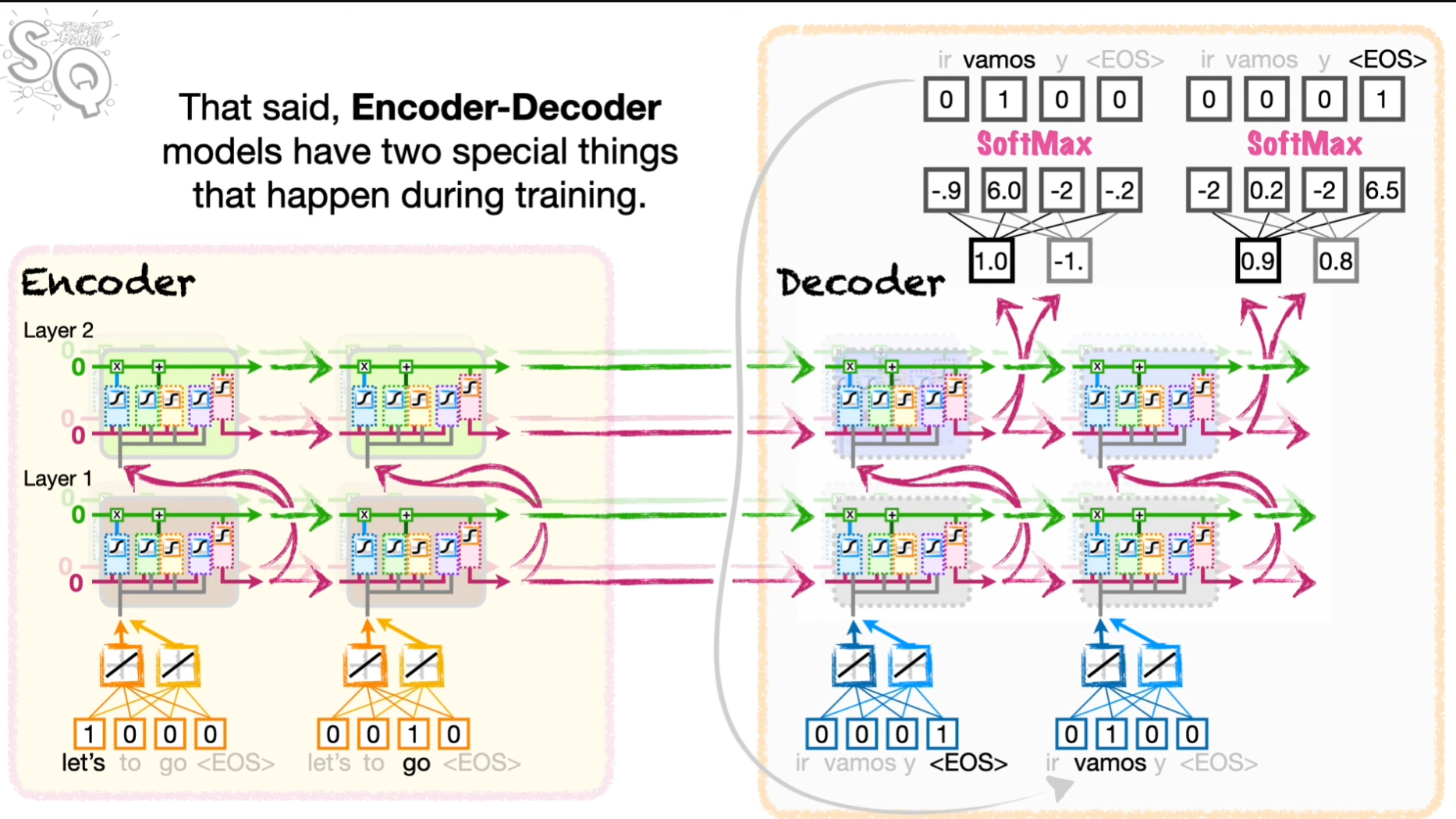
layer가 여러개일때는 다음과 같이 동작한다. layer1 => layer2 .. 다음 sequence 이렇게
weight는 인코더 부분과 디코더부분은 서로 다른 가중치를 사용한다.
💡Attention model
✅기존 모델들의 문제점
Seq2Seq 모델의 첫번째 단점 => input문장의 길이와 관계없이 같은 size의 context vector를 가짐
억지로 고정길이의 벡터로 밀어 넣다보면 어느순간 한계가 찾아올 것이 분명하다. =>정보소실 가능성⬆️
사실상 히든 state 하나주고 OUTPUT 구해와~~ 하는게 너무 Decoder에게 어려운 task를 주는것이다.
또 context vector에 마지막 단어의 정보가 제일 뚜렷하게 담김 => 디코더가 마지막 단어를 제일 열심히 본다. (초반에 중요한 내용이 있을 수도 있음에도)
디코더에서 추론할때 모든 단어를 고려할 수 있게 하고 싶다! => attention mechanism
(하지만 여전히 기울기 소실 문제는 해결하지 못한다.)
✅Attention mechanism
최대한 핵심만 담아서 설명해보겠음
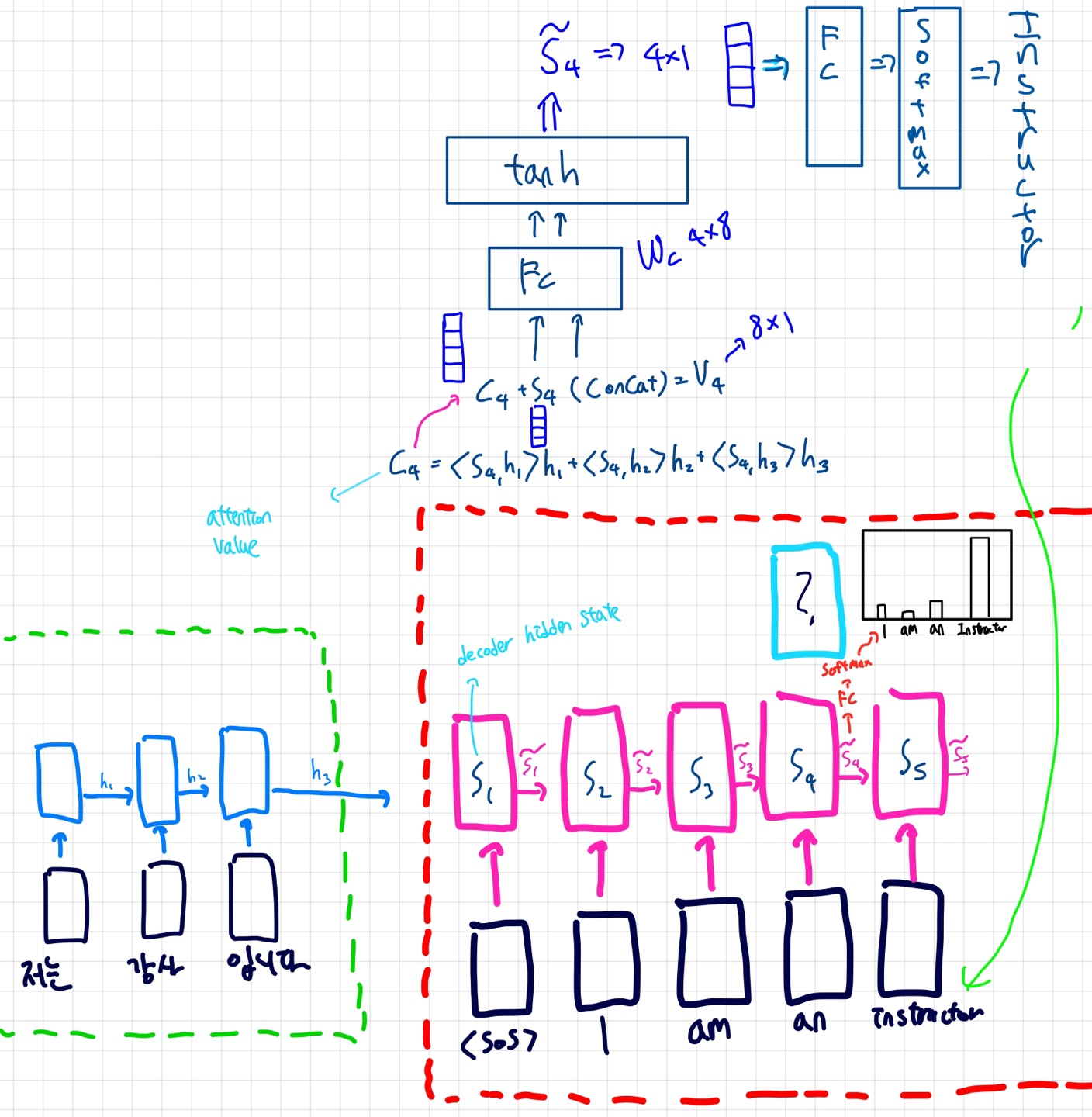
하늘색에 들어갈 단어를 맞춰보자 (여기서 S는 decoder의 hidden state임)
기존의 seq2seq모델은 S3과 an의 워드임베딩 벡터만 가지고 S4를 도출해내고 이를 이용해서 다음 단어를 추론했을 것이다.
Attention 모델은 다르다. Attention 모델은 Encoder의 출력에 모든 것을 맡기지 않는다.
h1,h2,h3 즉 각각의 LSTM hidden state와 S4의 내적을 구한후 (닮은 정도) Softmax를 통과시킨다.(10, 2, 2 =>0.8, 0.1 ,0.1) 여기에 인코더 측 hidden state를 곱해주고 전부 SUM 해준다. 이 결과를 Attention Value 라고 함
Attention Value를 S4와 concat해서 FC+tanh 층에 넣고 이를 또 FC+Softmax에 넣어서 단어 예측을 마친다.
FC+tanh 층을 통과한 S~를 다음 LSTM의 input state로 넣어주는 듯
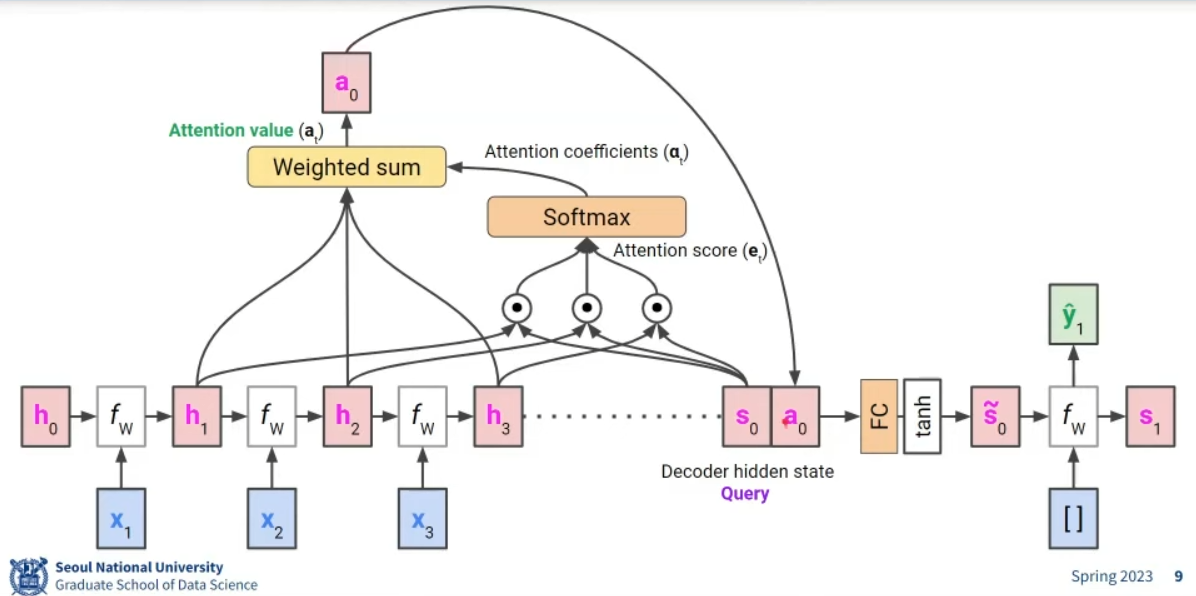
이름 그대로 input 하나하나에게 Attention을 줌 😲
학습이 이루어짐에 따라 적절한 단어에 align되게 한다. 즉, 학습이 진행됨에 따라 관련성이 높은 정보를 동적으로 선택한다.
(학습이 진행됨에 따라 S4는 h2벡터와의 내적값이 커질 것이다.=> 추론할때 강사라는 단어에 크게 영향을 받는다는 의미)
여기서 진화한게 이제 트랜스포머인데
다음 포스트에서 다루도록 하겠슴돠
