세상을 바꾼 Transformer에 대해 알아보자
🤔 Attention 모델의 문제점
이전 포스트 에서 알아봤던 어텐션 모델의 아쉬운 점이 있다.
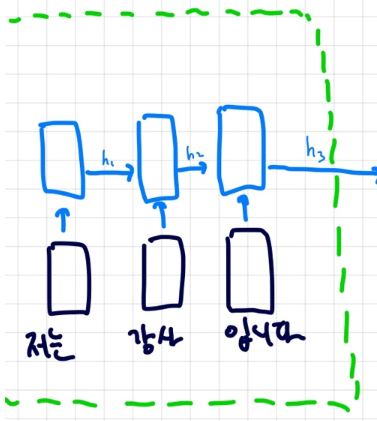
인코더 쪽을 한번보자 일반적인 LSTM 모델이다
이 모델의 hidden state를 word embedding으로 간주해서 attention을 구했는데
이 hidden state값이 정말 믿을 만할까?
뭐 아예 쓰레기같은 값은 아닐테지만 LSTM의 특징이 뭐였던가?
뒤로갈수록 앞에 있는 가중치는 업데이트 받지 못한다. 즉, 앞부분에 있는 가중치는 뒤의 단어에 영향을 받지 못하는 것이다.
"나는 무지막지하게 치킨을 많이 먹어서 몸무게가 1200kg가 된 코끼리 입니다"
라는 문장이 있다고 해보자. "나 =코끼리" 라는 정보를 LSTM이 학습할 수 있을까? 이 단어사이의 거리가 더 멀다면 어떻게 될까?
어떤 문제가 발생하는 지 대충 감이 왔을 것이다. LSTM은 치킨까지만을 보고 "나=사람"이라고 생각했을 가능성이 높지만 사실 "나"는 말을 할 줄아는 코끼리였다. 즉 부정확한 정보를 hidden state에 담은 것이다. (코끼리 대신 사람을 담음)
그리고 아무리 cell state로 장기기억을 가져간다 한들 문장이 엄청나게 길어지면 0<t<1 값이 계~속 곱해져서 뒤에 있는 단어도 앞의 단어를 기억하지 못한다.
Transformer
✅Positional Encoding
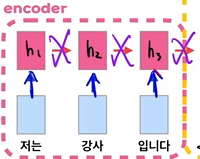
Self-Attention은 이렇게 다음 cell로 넘어가는 아키텍쳐가 RNN의 고질적인 문제점이라고 보고 이 connection을 없애 버렸다.😲
근데 이렇게 순차적인 흐름을 지워버리면 단어의 위치정보가 없어진다는 문제가 생긴다.
즉 예전에는 "나는" 뒤에 "무지막지하게" 뒤에 "치킨을" ...과 같이 모델이 순서를 인지하고 있었는데 그 연결을 끊어 버렸다!
그래서 등장한게 Positional encoding이다.
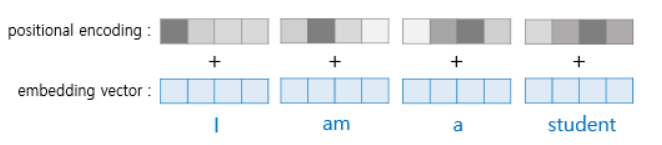
이렇게 각 워드임베딩벡터에 위치값을 나타내는 positional encoding을 해준다.
비슷한 위치에서 유사한 인코딩 값을 생성하게 해야겠지?
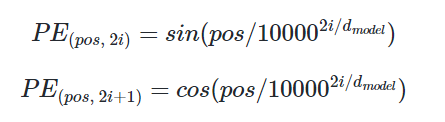
위와 같은 식을 사용하고 pos는 위치, i는 차원 d는 모델의 차원을 나타낸다.
(위의 예시론 am의 경우 pos는 1 이고 d는 3이다)
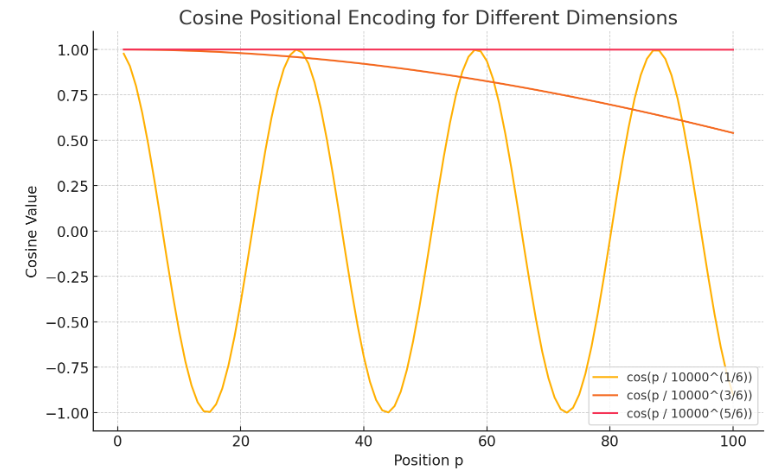
요런값들이 연속적으로 나타난다.
(1 1 1 => 0.98 0.99 0.99 =>0.95 0.98 0.99,,, 인코딩 벡터가 이런식으로 나타나면 머신이 위치정보를 파악 가능)
🤔 의문점
더해지면 근데 정보가 유실되는거 아닌가
그럼 concat하는게 낫지 않나? 연산량 때문에 안하는건가?
워드임베딩 (1,2,3)에 위치 인코딩(3,2,1)이랑
워드 임베딩 (2,2,2)에 위치 인코딩 (2,2,2)랑 값이 같은데
물론 차원이 크니까 겹칠일이 거의 없겠다만 이런 반례가 하나 나온 것만 해도 이게 논리적으로 완벽한 방식은 아닌거 같다.
✅Encoder
자 이제 워드임베딩을 완료했으니 인코더 파트를 보자
아까 sequential한 흐름을 끊었다고 했지?
그럼 각 단어들은 앞뒤의 정보를 얻지 못하는 상태임
그래서 거기에 Self-Attention을 적용해줌
Self Attention을 적용해주기 전에 먼저 Q,K,V값들을 구해야 함
간단히 설명하자면
- Q는 질문하는 벡터 (너 나랑 얼마나 닮았어?)
- K는 답하는 벡터 (내 K랑 내적해봐~)
- V는 그 단어 자체의 Value (오~ 이만큼 닮았구나? 내 Value랑 곱해~) 라고 생각하면 될 것 같다.
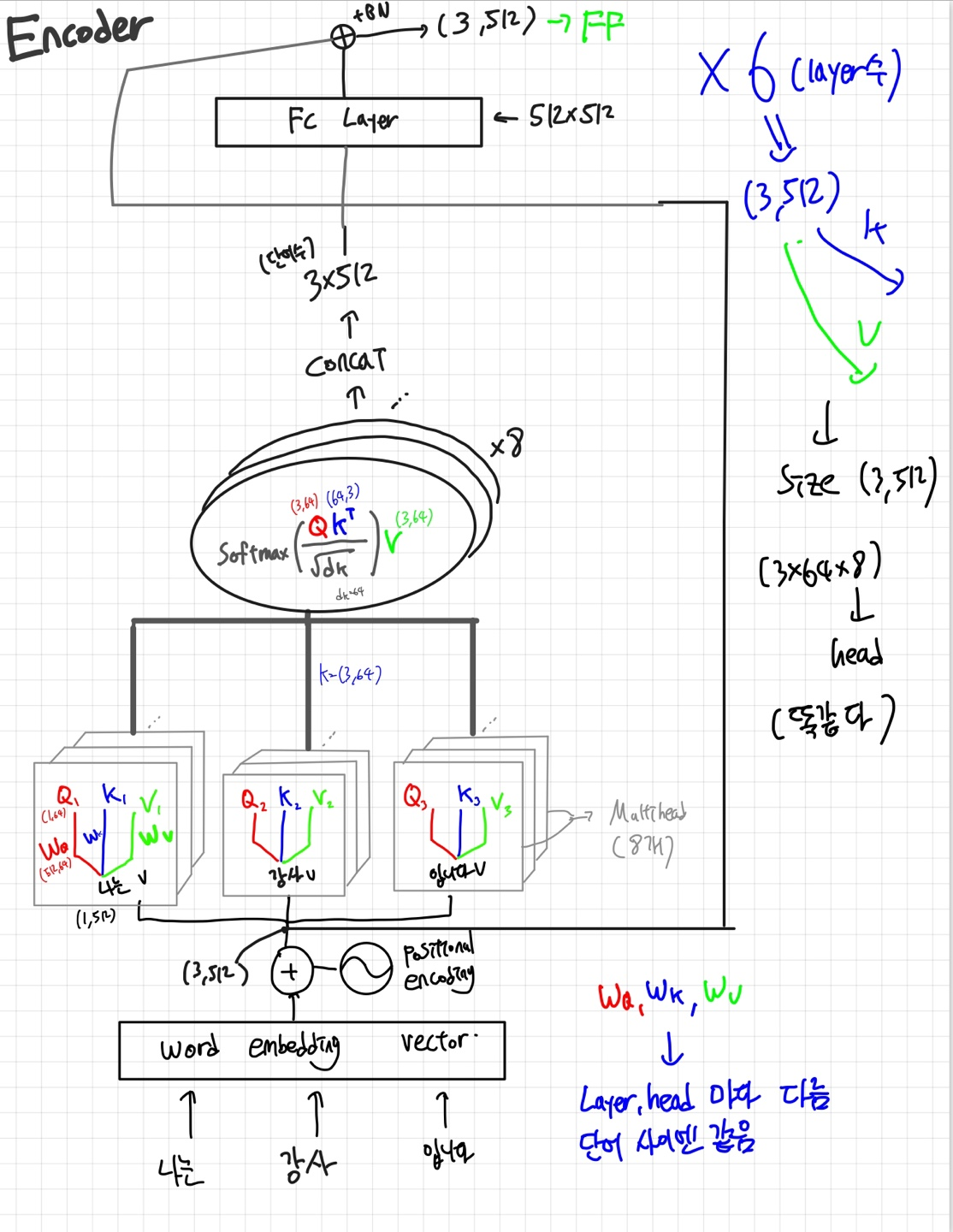
단어1 단어2 단어3 이 있다고 가정하면
단어1에 대한 더 구체적인 정보가 알고싶다! => 단어 1 자신과 2,3과 attention 연산을 수행한다
어떻게? 단어 1의 Q(물어보고싶은 벡터)를 단어 1,2,3의 K와 각각 내적하고 Softmax하고 각각의 value값을 곱해준 후 더한다. 그냥 Attention mechanism인데 Q,K,V가 추가되었다고 생각하면 될 것 같다.
그리고 이 행위를 Parellel하게 하는데, 이것 때문에 우리는 Multi-head self attention이라고 부른다.
(더 다양한 특징들을 탐색하는 것 CNN에서 feature map 여러개인 것처럼)
이 모든 행위를 마치고 FC layer에 통과해주고 (각 단어별로 따로) Resiudal connection을 더해주고 BN을 적용해준다.
그리고 Feed forward layer를 통과함
(Linear(512,2048) ,Relu(),Linear(2048,512))
여기까지 끝났으면 encoder block의 한 레이어를 통과한것이다.
논문에서는 총 6개의 레이어가 있음
문장마다 길이가 다르기 때문에 pad토큰이라는 것이 들어가는데 이건 밑에서 따로 다루도록하겠다.
🤔 루트 dk 로 왜 나눌까?
softmax의 backprop값은 위와 같은거 기억하지?
Vanishing Gradient 막기 위해서=> 패파에서 계산해보자
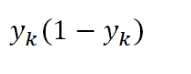
✅Decoder
디코더 부분을 한번 보자!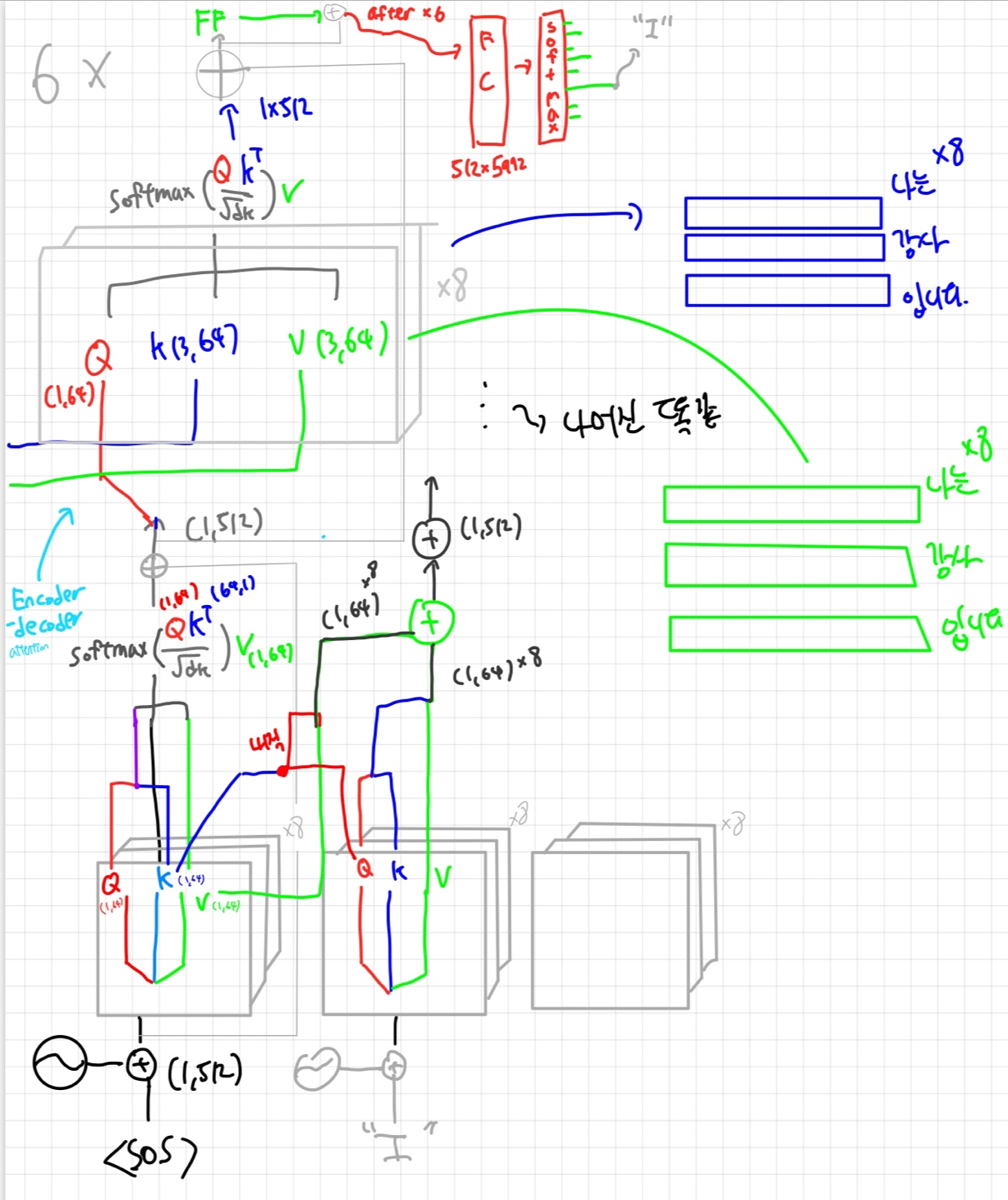
Masked Multi-head attention
디코더의 Multi-head attention은 그럼 무엇이 다를까?
디코더 부분은 뒤에 부분을 Masking한 채 어텐션을 적용한다.
inference할때는 뒤의 값을 알고 있지 않기 때문에 학습할때도 마스킹을 적용해주는 것
(뒤에 것을 안보고 잘 추론할 수 있도록 학습해야함)
Encoder-decoder attention
인코더 쪽에서 넘어온 K,V를 이용해서 "나는 강사 입니다" 의 정보까지 챙기는 부분이다.
softmax통과 값과 v의 내적이 이루어지면 shape은 다시 (1,512)가 된다 ( 아름답다... )
역시 Resiudal block+BN 이후에 Feed forward network을 통과한후 다시 다음 layer로 이동한다.
마지막 layer에서는 512x5972(단어의 수) 모양의 FC Layer과 Softmax를 통과한 후 나온결과의 word embedding을 다음 sequence의 input으로 전달한다.
Dropout
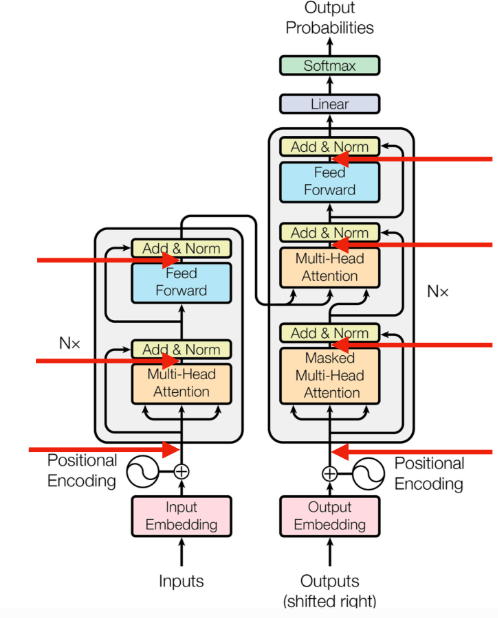
요렇게 중간중간에 Dropout probability =0.1로 해서 Dropout layer도 추가해줌
Masking method
이건 구현할때 구체적으로 설명하겠다!

아름다운 트랜스포머의 아키텍쳐에 대해서 알아보았다. 다음엔 코드를 보면서 더 세세히 분석해보도록 하자
안녕~🤚
