나만의 뉴스번역봇을 만들면서 Transformer 를 구현해보자
tokenizer = MarianTokenizer.from_pretrained('Helsinki-NLP/opus-mt-ko-en')허깅 스페이스에서 먼저 tokenizer를 가져온다. (한,영 단어토큰들에 대해서 index mapping이 된 json파일)

요런식으로 json파일로 저장되어 있음
BATCH_SIZE = 64
LAMBDA = 0
EPOCH = 15
max_len = 100
pad_idx = tokenizer.pad_token_id #pad token이 나와야하는시점의 loss는 무시
criterion = nn.CrossEntropyLoss(ignore_index = pad_idx)
scheduler_name = 'Noam'
warmup_steps = 1000
LR_scale = 0.5
new_model_train = True
save_model_path = '/content/drive/MyDrive/Colab Notebooks/results/Transformer_small2.pt'
save_history_path = '/content/drive/MyDrive/Colab Notebooks/results/Transformer_small2_history.pt'model 저장경로 지정해주고 하이퍼파라미터들 initialize 해주자
n_layers = 3
d_model = 256
d_ff = 512
n_heads = 8
drop_p = 0.1논문에서 제시한 값들 보다 경량화 시킨 모델을 사용해보겠다 ( resource 이슈)
data = pd.read_csv("/content/sample_data/mnist_train_small.csv")Aihub에서 문어체 뉴스 데이터를 가져옴 (20만개 데이터)
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return self.data.shape[0]
def __getitem__(self, idx):
return self.data.loc[idx, '원문'], self.data.loc[idx, '번역문']
custom_DS = CustomDataset(data)
train_DS, val_DS, test_DS, _ = torch.utils.data.random_split(custom_DS, [195000, 3000, 2000, len(custom_DS)-195000-3000-2000])
# 논문에서는 450만개 영,독 문장 pair 사용
#학습 , 검증, 테스트 데이터로더 정의
train_DL = torch.utils.data.DataLoader(train_DS, batch_size=BATCH_SIZE, shuffle=True)
val_DL = torch.utils.data.DataLoader(val_DS, batch_size=BATCH_SIZE, shuffle=True)
test_DL = torch.utils.data.DataLoader(test_DS, batch_size=BATCH_SIZE, shuffle=True)
print(len(train_DS))
print(len(val_DS))
print(len(test_DS))데이터 셋을 정의하는 클래스 생성, train,validation,test set 나누고 그거로 데이터로더 설정
for src_texts, trg_texts in train_DL:
print(src_texts)
print(trg_texts)
print(len(src_texts))
print(len(trg_texts))
# 여러 문장에 대해서는 tokenizer.encode() 가 아닌 그냥 tokenizer()
src = tokenizer(src_texts, padding=True, truncation=True, max_length = max_len, return_tensors='pt', add_special_tokens = False).input_ids # pt: pytorch tensor로 변환
# add_special_tokens = True (default)면 마지막에 <eos> 를 붙임
# truncation = True: max_len 보다 길면 끊고 <eos> 집어넣어버림
trg_texts = ['</s> ' + s for s in trg_texts]
# <sos>가 토크나이저에 따로 없길래 </s> 를 <sos> 로 사용
trg = tokenizer(trg_texts, padding=True, truncation=True, max_length = max_len, return_tensors='pt').input_idsstart of sequence 추가해주기 번역문에
자 이제 준비를 마쳤으니 본격적으로 모델을 구현해보자
Multi-head attention
class MHA(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.n_heads = n_heads
self.fc_q = nn.Linear(d_model, d_model)
self.fc_k = nn.Linear(d_model, d_model)
self.fc_v = nn.Linear(d_model, d_model)
self.fc_o = nn.Linear(d_model, d_model)
self.scale = torch.sqrt(torch.tensor(d_model / n_heads))
def forward(self, Q, K, V, mask=None):
Q = self.fc_q(Q)
K = self.fc_k(K)
V = self.fc_v(V)
Q = rearrange(Q, 'n w (h d) -> n h w d', h=self.n_heads)
K = rearrange(K, 'n w (h d) -> n h w d', h=self.n_heads)
V = rearrange(V, 'n w (h d) -> n h w d', h=self.n_heads)
attention_score = Q @ K.transpose(-2, -1) / self.scale # 마지막 두 차원 전치
if mask is not None:
attention_score[mask] = -1e10
attention_weights = torch.softmax(attention_score, dim=-1)
attention = attention_weights @ V
x = rearrange(attention, 'n h w d -> n w (h d)')
x = self.fc_o(x)
return x, attention_weights각각 Query, Key, Value를 생성하는 신경망을 만든다. einops의 rearrange 함수를 사용하여 차원을 변환한다. 여기서 n, w, h, d는 각각 number, word, head, dimension을 의미한다.
논문에서 Query, Key, Value를 계산할 때 512x64 크기의 헤드를 8개 병렬로 처리한 다음 나중에 이를 합치는 방식을 설명한다. 처음에는 q1, q2 각각을 별도로 구현해야 한다고 생각했었지만, 사실 512x512 크기의 네트워크 하나만으로 문제를 해결할 수 있다는 걸 알게 되어 조금 허무했음 . 😂
@연산은 행렬두개의 다른부분만 행렬곱을 하는 연산이다. 말이 좀 어려운데 예를 들어서 설명해 보자면 64x8x3x64 @ 64x8x64x3 의 결과는 64x8x3x3이 나오는 것이다. (뒤에 부분만 행렬곱을 한 것)
마스크가 있다면 attention score를 0에 근사시키는 (masking하는) 예외처리 구문을 만든다. 마스크가 None이라면 아래와 같은 식으로 계산한다.
scale 값은 루트 dk 값이다. 분산이 커지면 softmax의 기울기가 작아지기 때문에 Gradient vanishing을 방지하기 위해서 존재하는 값이다.
😠 아니 Q,K,V로 변환할때 어차피 똑같은 x를 다른 네트워크 세개로 변환하는건데 그냥 input을 Q,K,V말고 x로 통일하면 안돼요?
실제로 gpt는 그렇게 구현한다. 근데 트랜스포머는 encoder decoder attention에서 x가 똑같지 않은 경우가 있어서 이렇게 specific하게 명시를 해주는거임
Feed-Forward
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, drop_p):
super().__init__()
self.linear = nn.Sequential(nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model))
def forward(self, x):
x = self.linear(x)
return xFeed-forward 네트워크는 다음과 같다
Encoder
본격적으로 인코더 부분을 구현해보자
class EncoderLayer(nn.Module):
def __init__(self, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.self_atten = MHA(d_model, n_heads)
self.self_atten_LN = nn.LayerNorm(d_model)
self.FF = FeedForward(d_model, d_ff, drop_p)
self.FF_LN = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(drop_p)
def forward(self, x, enc_mask):
residual, atten_enc = self.self_atten(x, x, x, enc_mask) # 인코더에도 마스크가?!
residual = self.dropout(residual)
x = self.self_atten_LN(x + residual)
residual = self.FF(x)
residual = self.dropout(residual)
x = self.FF_LN(x + residual)
return x, atten_enc
class Encoder(nn.Module):
def __init__(self, input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.scale = torch.sqrt(torch.tensor(d_model))
self.input_embedding = input_embedding
self.pos_embedding = nn.Embedding(max_len, d_model)
self.dropout = nn.Dropout(drop_p)
self.layers = nn.ModuleList([EncoderLayer(d_model, d_ff, n_heads, drop_p) for _ in range(n_layers)])
def forward(self, src, mask, atten_map_save = False):
pos = torch.arange(src.shape[1]).expand_as(src).to(DEVICE)
x = self.scale*self.input_embedding(src) + self.pos_embedding(pos)
# self.scale 을 곱해주면 position 보다 token 정보를 더 보게 된다 (gradient에 self.scale 만큼이 더 곱해짐)
x = self.dropout(x)
atten_encs = torch.tensor([]).to(DEVICE)
for layer in self.layers:
x= layer(x, mask)
return x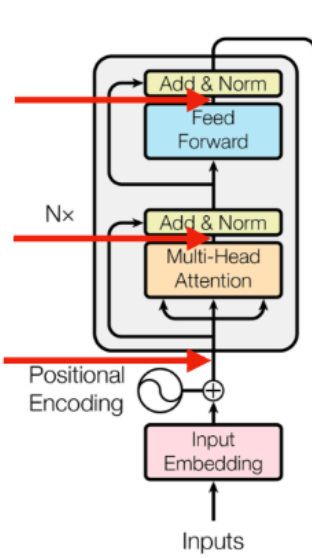
Encoder layer를 보면 그림과 정확히 동일하게 구현한 것을 볼 수 있다. (시작 전 Dropout까지)
for문 돌려서 layer수 만큼 반복하는 것도 보고 넘어가자.
그런데 인코더에도 마스크가 있다?!
그렇다. Self-attention을 수행할때 pad토큰의 정보까지 attention을 줄 필요는 없어서 우리는 뒤에 값들을 지워버리려고 한다.
어떻게 지우냐? key값만 0으로 만들면됨 softmax전에
key는 대답하는 value이기 때문에 다른 애들이 넌 나랑 얼마나 닮았어? 물어볼때 응 안닮았어라고 말해버리면 0이 되어버려서 가중치 업데이트가 안됨 encoder-decoder attention도 마찬가지 ( x0을 해버리면 back-prop할때 0이 곱해지니까)
Decoder
class DecoderLayer(nn.Module):
def __init__(self, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.self_atten = MHA(d_model, n_heads)
self.self_atten_LN = nn.LayerNorm(d_model)
self.enc_dec_atten = MHA(d_model, n_heads)
self.enc_dec_atten_LN = nn.LayerNorm(d_model)
self.FF = FeedForward(d_model, d_ff, drop_p)
self.FF_LN = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(drop_p)
def forward(self, x, enc_out, dec_mask, enc_dec_mask):
residual= self.self_atten(x, x, x, dec_mask)
residual = self.dropout(residual)
x = self.self_atten_LN(x + residual)
residual = self.enc_dec_atten(x, enc_out, enc_out, enc_dec_mask) # Q는 디코더로부터 K,V는 인코더로부터!!
residual = self.dropout(residual)
x = self.enc_dec_atten_LN(x + residual)
residual = self.FF(x)
residual = self.dropout(residual)
x = self.FF_LN(x + residual)
return x
class Decoder(nn.Module):
def __init__(self, input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.scale = torch.sqrt(torch.tensor(d_model))
self.input_embedding = input_embedding
self.pos_embedding = nn.Embedding(max_len, d_model)
self.dropout = nn.Dropout(drop_p)
self.layers = nn.ModuleList([DecoderLayer(d_model, d_ff, n_heads, drop_p) for _ in range(n_layers)])
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, trg, enc_out, dec_mask, enc_dec_mask, atten_map_save = False):
pos = torch.arange(trg.shape[1]).expand_as(trg).to(DEVICE)
x = self.scale*self.input_embedding(trg) + self.pos_embedding(pos)
# self.scale 을 곱해주면 position 보다 token 정보를 더 보게 된다 (gradient에 self.scale 만큼이 더 곱해짐)
x = self.dropout(x)
for layer in self.layers:
x = layer(x, enc_out, dec_mask, enc_dec_mask)
x = self.fc_out(x)
return x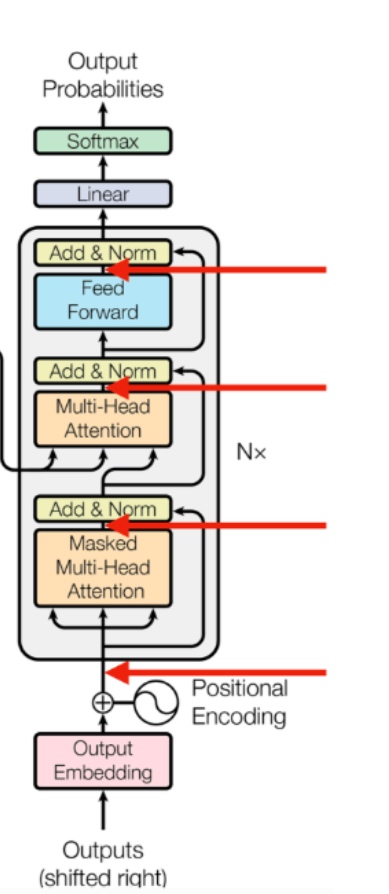
decoder 부분도똑같이 구현함
Transformer
자 이제 합쳐보자~!
class Transformer(nn.Module):
def __init__(self, vocab_size, max_len, n_layers, d_model, d_ff, n_heads, drop_p):
super().__init__()
self.input_embedding = nn.Embedding(vocab_size, d_model)
self.encoder = Encoder(self.input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p)
self.decoder = Decoder(self.input_embedding, max_len, n_layers, d_model, d_ff, n_heads, drop_p)
self.n_heads = n_heads
for m in self.modules():
if hasattr(m,'weight') and m.weight.dim() > 1: # 인풋 임베딩은 그대로 쓰기 위함
nn.init.xavier_uniform_(m.weight) # xavier의 분산은 2/(Nin+Nout) 즉, 분산이 더 작다. => 그래서 sigmoid/tanh에 적합한 것! (vanishing gradient 막기 위해)
def make_enc_mask(self, src):
enc_mask = (src == pad_idx).unsqueeze(1).unsqueeze(2)
enc_mask = enc_mask.expand(src.shape[0], self.n_heads, src.shape[1], src.shape[1])
""" src pad mask (문장 마다 다르게 생김. 이건 한 문장에 대한 pad 행렬)
F F T T
F F T T
F F T T
F F T T
"""
return enc_mask
def make_dec_mask(self, trg):
trg_pad_mask = (trg == pad_idx).unsqueeze(1).unsqueeze(2)
trg_pad_mask = trg_pad_mask.expand(trg.shape[0], self.n_heads, trg.shape[1], trg.shape[1])
""" trg pad mask
F F F T T
F F F T T
F F F T T
F F F T T
F F F T T
"""
trg_future_mask = torch.tril(torch.ones(trg.shape[0], self.n_heads, trg.shape[1], trg.shape[1]))==0
trg_future_mask = trg_future_mask.to(DEVICE)
""" trg future mask
F T T T T
F F T T T
F F F T T
F F F F T
F F F F F
"""
dec_mask = trg_pad_mask | trg_future_mask
""" decoder mask
F T T T T
F F T T T
F F F T T
F F F T T
F F F T T
"""
return dec_mask
def make_enc_dec_mask(self, src, trg):
enc_dec_mask = (src == pad_idx).unsqueeze(1).unsqueeze(2)
enc_dec_mask = enc_dec_mask.expand(trg.shape[0], self.n_heads, trg.shape[1], src.shape[1])
""" src pad mask
F F T T
F F T T
F F T T
F F T T
F F T T
"""
return enc_dec_mask
def forward(self, src, trg):
enc_mask = self.make_enc_mask(src)
dec_mask = self.make_dec_mask(trg)
enc_dec_mask = self.make_enc_dec_mask(src, trg)
enc_out = self.encoder(src, enc_mask)
out = self.decoder(trg, enc_out, dec_mask, enc_dec_mask)
return outpading 부분은 key부분을 0 으로 죽여버린다했지? => T 로 놓으면 -inf값을 넣어서 softmax를 통과하면 0이 나온다.
모델 구현은 끝
model training
자 이제 Training을 시켜보자!
