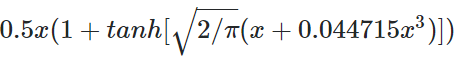Abstract
자연어 처리 분야는 textual entailmen, question answering, semantic similarity assesment와 같은 다양한 task들을 포함한다.
수많은 text corpora들이 있지만
이렇게 특정한 task를 위한 라벨링된 데이터들은 턱없이 부족하다.
그래서 본 논문에서는 unlabeled data set에 대한 generative pre-training 이후에 특정 task를 위한 fine-tuning을 함으로써 높은 성과를 냈다.
pretraining -> fine-tuning 하는 과정에서 model architecture는 최소한으로 변경하고 12개의 task 중 9개의 task에서 state of the art를 달성하는데 성공함
💡1. Introduction
raw text로부터 효과적으로 배우는 능력은 지도학습에 대한 의존을 줄이는데 중요하다.
라벨링 데이터가 부족하기 때문에 이에 의존하는 학습방식은 한계가 있음 =>라벨링되지 않은 데이터에서 언어 정보를 활용할 수 있는 모델이 데이터 부족의 대안이 될 수 있다.
심지어 충분한 데이터가 있을때도 unsupervised fashion에 대한 표현들을 배울 수 있으면 성능에 크게 기여할 수 있다.
( 그동안 pre-trained word embedding을 써와서 NLP task의 성능에 기여한 것 처럼)
근데 라벨링되지 않은 텍스트에서 정보를 학습하기엔 어렵다
- 어떤 방식으로 텍스트를 학습하는 게 제일 좋은지 아직 확실하지 않고 (모든 metric을 압도 하는 방식이 없음 다 잘하는게 다름)
- target task를 수행하기 위한 가장 effective한 transfer 모델을 만드는 consensus도 없음 (다 원래 있는 모델에 task-specific한 변화를 추가할 뿐임)
이러한 uncertantiy 때문에.
pre-training + fine-tuning
이 논문에서는 unsupervised pre-training 과 supervised fine-tuning을 결합한 반지도 접근법을 탐구한다.
우리는 다양한 task에 적은 수정으로 전이 가능한 보편적 표현을 학습하기 위해, 대규모 라벨링되지 않은 텍스트 말뭉치와 여러 주석된 데이터셋을 사용하여 두 단계의 훈련 절차를 수행한다.
트랜스포머 아키텍쳐를 이용하며 전이 과정에서 (fine-tuning)할 때는 traversal-style을 사용함
트래버설 스타일 접근법은 구조화된 텍스트 데이터를 하나의 연속된 토큰 시퀀스로 처리하는 방법이야. 예를 들어, 우리가 질문 응답 작업을 하고 있다고 해보자.
- 기존 접근법:
질문: "What is the capital of France?"
컨텍스트: "France is a country in Europe. The capital of France is Paris."
일반적으로 질문과 컨텍스트를 별도로 처리해.- 트래버설 스타일 접근법:
입력: "[Q] What is the capital of France? [C] France is a country in Europe. The capital of France is Paris."여기서 질문(Q)과 컨텍스트(C)를 하나의 긴 문자열로 이어붙여서 하나의 덩어리처럼 다루는 거야.
이렇게 하면 모델이 입력을 하나의 긴 시퀀스로 처리하면서 질문과 컨텍스트 사이의 관계를 더 잘 이해할 수 있게 돼.
12개의 작업 중 9개에서 최첨단 성능을 크게 개선함. 예를 들어, 상식 추론에서 8.9%, 질문 응답에서 5.7%, 텍스트 함축에서 1.5%, 그리고 GLUE 다중 작업 벤치마크에서 5.5%의 절대적인 개선을 달성.
또한, 사전 학습된 모델의 zero-shot performance를 분석해 유용한 언어 지식을 획득했음을 보여줌.
💡2. Related Work
라벨링, 텍스트 분류와 같은 작업에 적용되면서 semi-supervised learning이라는 패러다임은 많은 관심을 끌었음.
연구자들은 unlabeled dataset에 대해 word embeddings 를 사용하여서 성능을 입증해 왔고 이런 수준에 만족하지 않고 구문,문장 수준의 임베딩까지 사용되고 있음을 밝힘
Unsupervised pre-training을 시키는 것은 초기 좋은 representation을 찾는데 목적둔다.
이는 특정한 task를 목적으로한 supervised learning에서 보조 특징으로 사용된다.
본 논문에서는 전이 과정에서 최소한의 변경만으로 성능을 낼 수 있게 함
Auxiliary training objectives
본 논문은 unsupervised pre-training의 목적함수를 supervised fine-tuning할 때 auxiliary objective로 추가함
💡3. Framework
3.1 비지도 사전 학습 (Unsupervised pre-training)
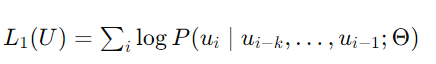
k= context window 사이즈고 Θ는 NN의 파라미터다.
저 Likelihood를 maximize하는 식을 따른다.
(그냥 Cross-entropy Loss)
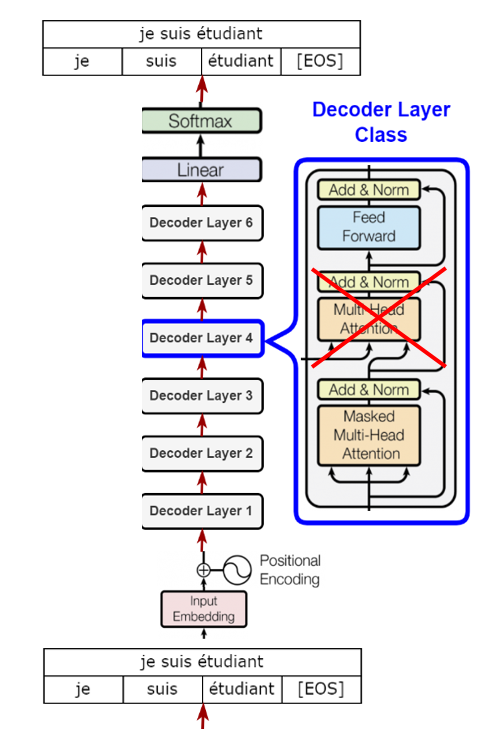
본 논문에서는 Transformer의 decoder 부분을 사용하는데, 기존의 decoder와는 좀 다른게 encoder 가 없어서 중간에 encoder-decoder attention이 사라졌다.
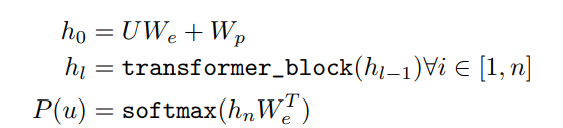
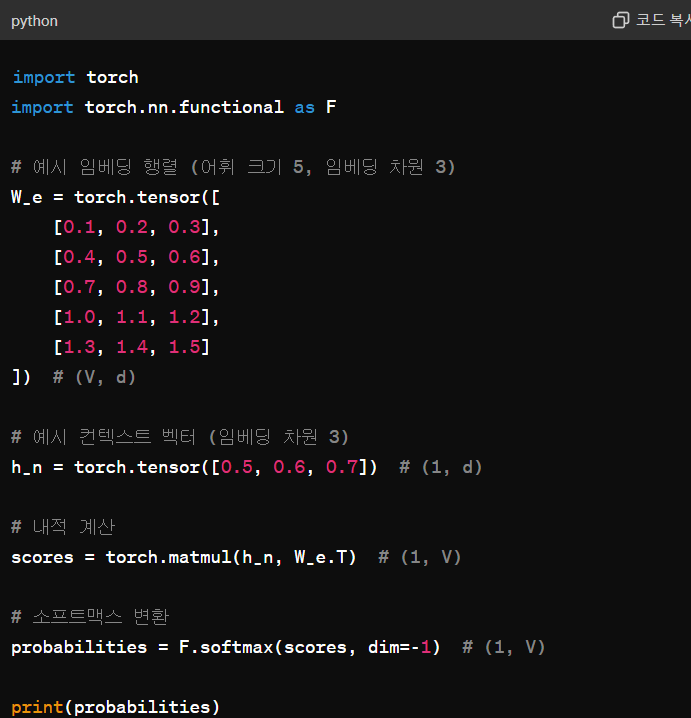
최종출력을 워드임베딩벡터의 전치행렬과 내적해서 가장 닮은 쪽의 로짓값이 가장높게 나올 수 있도록 함
(기존 트랜스포머는 모델이 알아서 마지막 layer를 학습하게 함) => 파라미터수를 꽤나 아꼈다?!
3.2 지도 전이 학습 (supervised fine-tuning)
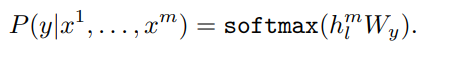
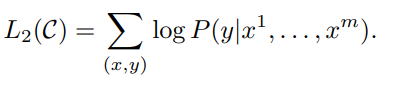
이제 학습된 모델에 라벨링된 데이터들로 fine-tuning을 실시한다.
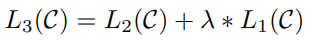
위의 Likelihood를 maximize 하는 것을 목표로하는데 이와 같이 auxiliary feature를 추가하는 방식은 GPT-1에서만 사용된다고 한다.
(이렇게 했더니 수렴을 좀 더 빨리 하고 일반화 성능이 좋더라!)
목적은 next token prediction을 통한 일반화능력과 특정 task를 수행하는 능력 두마리의 토끼를 모두 다 잡겠다는 것.
Likelihood가 나눠지는거 보이지?
3.3 Task-specific input transformations
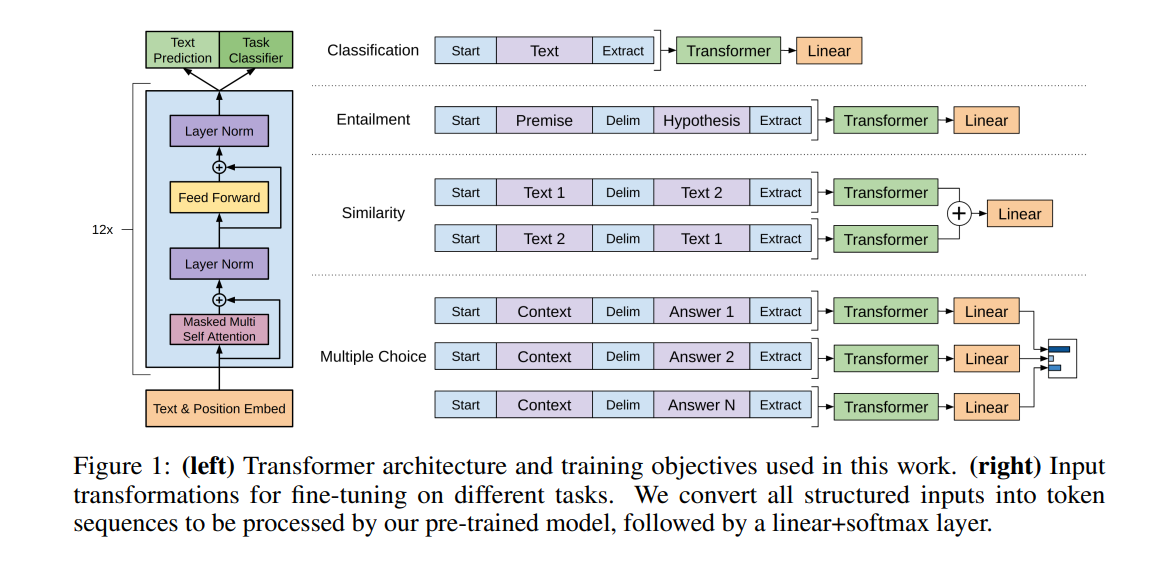
1. Classification
- 입력 텍스트 앞뒤로
<s>,<e>토큰을 붙여 Transformer의 입력으로 사용.
2. Entailment
- 형식:
<s> 전제 <$> 가설 <e> - 전제와 가설을 결합해 Transformer의 입력으로 사용.
3. Similarity
- 형식은 Entailment와 유사하지만 두 문장의 순서가 중요하지 않음.
- 두 문장의 순서를 바꿔서 각각 Transformer의 입력으로 넣음.
- Transformer 결과 벡터를 element-wise sum 후 Linear 레이어에 넣어 분류.
4. Question Answering and Commonsense Reasoning
- 형식은 Entailment와 유사함.
- Context는 동일하고, Answer N개 만큼의 벡터를 각각 Linear 레이어에 통과시킴.
- 이를 softmax 레이어에 통과시켜 출력 분포 생성.
extract 토큰은 inference할때 메인이 된다.=> 문장을 임베딩했다고 생각하자
(GPT-1을 fine-tuning할 때 특정 작업마다 다른 linear layer를 사용하는 것을 잊지 말자 -<e>==> linear layer)
💡4.Experiments
Unsupervised pre-training에서는 BooksCorpus라는 데이터셋을 사용함
이는 7000개가 넘는 다양한 장르의 출간되지 않은 책들로 Long-range정보를 학습하기에 아주 좋은 데이터셋임.
transformer decoder layer는 총 12층으로 구성되어 있고, self-attention head는 각 64 차원의 Q, K, V과 총 12개의 heads로 구성되어 있음

model,training detail들이 잘적혀져 있다
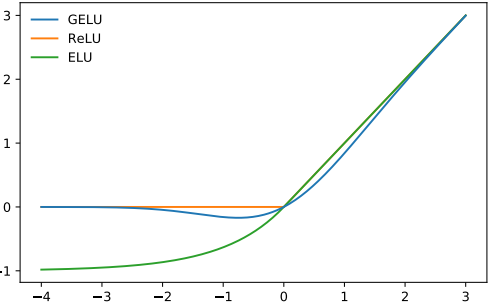
특별한건 딱히 없다 Gaussian Error Linear Unit (GELU)함수를 activation으로 사용했다는 것 정도? 그리고 기존의 sinusoidal embedding을 안씀.
우리가 학습시킴 (word embedding도 )
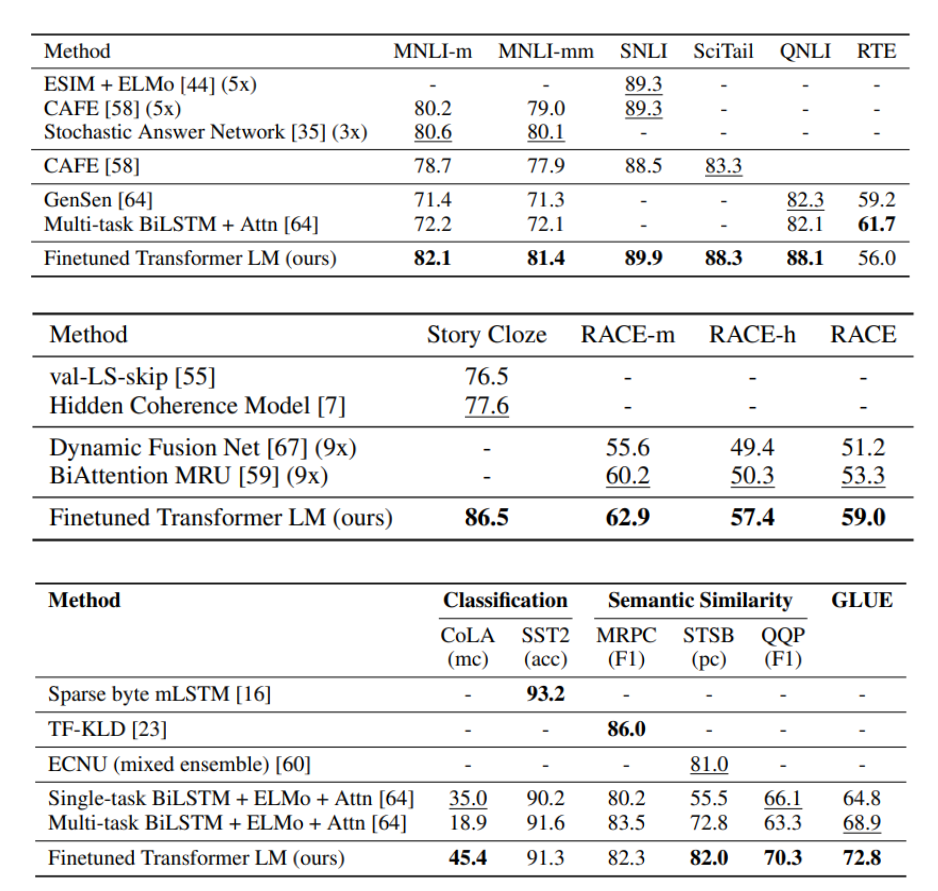
그 뒤에는 여러 벤치마크들에 대한 우수한 성능을 보여준다.

그럼 who are you <eos> 가 들어가면 who are you 랑 self attention을 해서 나온 결과값을 다음 input으로 넣는거
🤔 GELU 란?
GELU(x)=x⋅Φ(x)여기서 Φ(x)는 표준 정규분포의 CDF(Cumulative Distribution Function)임. 이를 통해 GELU 함수는 입력 x를 정규분포를 따르는 확률로 조절해서, 입력 값이 클수록 그 값에 가까운 출력을 내보내고, 입력 값이 작을수록 출력 값을 줄이는 역할을 함
위에는 정규분포에 근사한 식 (최대한 가깝게 표현하려고 한 식)장점
- 더 smooth 함 (RELU, Leaky ReLu에 비해)
- 기울기 소실 완화
기회가되면 논문을 읽어보자