0. Abstract
본 논문은 BERT의 후속연구로, 주요 하이퍼파라미터와 훈련 데이터 크기의 영향을 신중하게 측정합니다. 저자들은 BERT가 충분히 훈련되지 않았다고 주장하는데요, 개선된 모델은 GLUE ,RACE ,SQuAD에서 sota 모델에 등극했으며 이전에 간과된 디테일 한 design choice들의 중요성을 시사합니다.
1. Introduction
ELMo 부터 시작해서 GPT, BERT , XLNet 등등 다양한 모델들이 등장하면서 큰 성능향상을 가져왔지만 , 어떤 요소가 성능개선에 가장 크게 기여하는지 판단하는 것은 여전히 어렵습니다.
Training 할때의 비용이 너무큰 나머지 emperical하게 여러 하이퍼파라미터로 모델을 돌려보는 것이 거의 불가능한 수준이죠. 저자들은 기존에 BERT의 하이퍼파라미터들을 튜닝하고 , training set size를 조절함으로써 기존의 BERT보다 뛰어난 성능을 달성할 수 있었다고 합니다.
- 더 길게, 더 큰 배치사이즈로 학습
- NSP 없애기
- 좀 더 긴 sequence에 대하여 학습
- masking pattern 동적으로 바꾸기
- 새로운 dataset (CC-NEWS)
그리고 BERT의 MLM training기법이 여전히 XLNet과 같은 네트워크와 경쟁할 수 있음을 입증했습니다.
2. Background
BERT는 Adam 으로 최적화되며, 다음과 같은 매개변수를 사용합니다:
β1 = 0.9, β2 = 0.999, ǫ = 1e-6, L2 weight decay 0.01. 학습률은 처음 10,000 스텝 동안 점진적으로 증가하여 최대값 1e-4에 도달한 후 선형적으로 감소합니다.
BERT는 모든 레이어와 어텐션 가중치에 0.1의 드롭아웃을 적용하고, GELU 활성화 함수를 사용합니다. 모델은 총 1,000,000번의 업데이트 동안 사전 훈련되며, 미니배치는 최대 길이 512 토큰의 256개 시퀀스를 포함합니다.
BookCorpus + 위키피디아 데이터셋을 사용하였으며 이의 크기는 16GB정도 됩니다.
3. Experimental Setup
Implementation
저자들은 기존의 BERT 최적화 하이퍼파라미터를 따르되, 피크 학습률과 워밍업 단계 수는 각 설정에 맞게 별도로 조정했습니다. Adam 옵티마이저의 epsilon 값이 학습 성능과 안정성에 매우 민감하여 이를 조정한 후 더 나은 성능이나 안정성을 얻었습니다. 또한 큰 배치 크기로 학습할 때 β2를 0.98로 설정하면 안정성이 향상된다는 것을 발견했습니다.
Data
"Cloze-driven Pretraining of Self-attention Networks" 논문에서는 데이터 크기를 늘리면 최종 작업성능이 향상될 수 있음을 보여주었습니다.
아까 BERT는 16GB로 학습했다고 했었죠? RoBERTa는 160GB 데이터셋을 사용했다고 합니다.
BookCorpus + Wikipedia , CC- News , OPEN WEB TEXT, STORIES dataset을 사용했다고 하네요
Evaluation
GLUE: 9개의 데이터셋으로 구성된 자연어 이해 시스템 평가 벤치마크로, 단일 문장 및 문장 쌍 분류 작업을 포함합니다.
SQuAD: 문맥에서 관련된 스팬을 추출하여 질문에 답하는 태스크로, V1.1과 V2.0 버전을 사용합니다. V2.0은 일부 질문에 답이 포함되지 않아 더 어렵습니다.
RACE: 중국 중고등학생 영어 시험에서 수집된 독해 데이터셋으로, 각 질문에 대해 4개의 선택지 중 정답을 선택하는 태스크입니다.
4. Training Procedure Analysis
Static vs Dynamic Masking
BERT 모델의 훈련 과정에서 중요한 부분은 단어를 랜덤하게 마스킹하고 그 마스킹된 단어를 예측하는 것입니다.
원래 BERT 구현에서는 데이터 전처리 과정에서 한 번 마스킹을 수행하여 하나의 고정된 마스크를 사용했습니다. 그러나 이렇게 하면 각 학습 인스턴스마다 매 에포크에서 동일한 마스크를 사용하게 됩니다.
이를 피하기 위해 데이터가 10번 중복되었고, 40 에포크 동안 각 시퀀스가 10가지 다른 방식으로 마스킹되었습니다. 따라서 각 학습 시퀀스는 훈련 중에 동일한 마스크로 4번씩 보게 되는 것입니다.
이것을 예로 들어 설명해보겠습니다
-
원래 문장:
- "I love machine learning."
-
전처리 과정에서 10번 마스킹된 문장들 (10개의 다른 방식으로 마스킹):
- "I love [MASK] learning."
- "I [MASK] machine learning."
- "I love machine [MASK]."
- "I [MASK] machine [MASK]."
- ...
- 총 10개의 다른 마스크된 문장들
-
학습 과정:
- 40 에포크 동안 학습을 진행합니다.
- 각 에포크에서는 위의 10개의 마스크된 문장들 중 하나를 사용합니다.
- 즉, 첫 번째 에포크에서는 "I love [MASK] learning."을 사용하고, 두 번째 에포크에서는 "I [MASK] machine learning."을 사용하는 식입니다.
- 40 에포크 동안 각 마스크된 문장은 4번씩 사용됩니다. 예를 들어 "I love [MASK] learning."은 4번의 에포크에서 사용됩니다.
이렇게 함으로써 동일한 시퀀스가 훈련 동안 다양한 마스킹 방식을 경험하게 되어 모델이 더 일반화된 성능을 갖게 됩니다.
이게 Static masking 방식이고 , 마스킹이 매번 실시간으로 다른방식으로 되는 방식을 Dynamic masking 이라고 합니다.
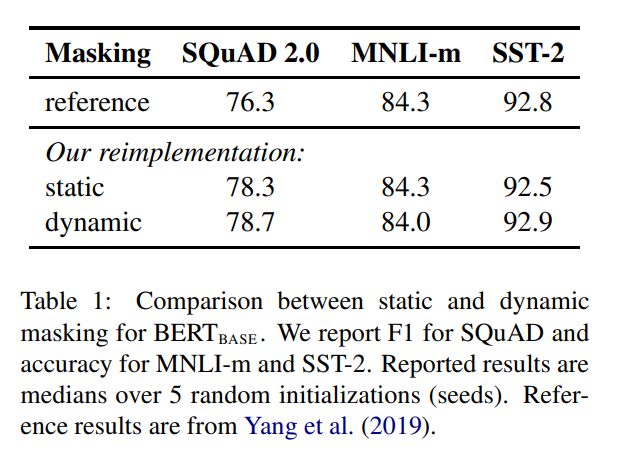
성능은 위와 같습니다. SQUAD performance가 크게 상승한걸 볼 수 있습니다.
Model Input Format and Next Sentence
NSP가 진짜 필요한 것인지 의문을 가지는 연구들이 생기고 있는 와중에 본문의 저자들은 여러가지 실험을 통해 결론을 짓고 새로운 Format을 결정하고자 했습니다.
SEGMENT-PAIR+NSP (기존 BERT 방식)
- 두 문장이 하나의 입력으로 결합되며, 하나의 문서에서 연속적이거나 별개의 문서에서 샘플링됩니다.
- 최대 512 토큰을 사용하며, NSP 손실을 사용합니다.
SENTENCE-PAIR+NSP
- 두 문장이 하나의 입력으로 결합되지만, 입력이 더 짧기 때문에 배치 크기를 늘립니다. (single sentence)
- 최대 512 토큰을 사용하며, NSP 손실을 사용합니다.
FULL-SENTENCES
- 여러 문서에서 연속적으로 샘플링된 문장을 하나의 입력으로 결합하고, 문서 경계를 [SEP]로 표시합니다.
- 최대 512 토큰을 사용하며, NSP 손실을 사용하지 않습니다.
DOC-SENTENCES
- 하나의 문서에서만 샘플링된 문장들로 입력을 구성하며, 문서 경계를 넘지 않습니다.
- 입력이 512 토큰보다 짧을 수 있어 배치 크기를 동적으로 조정하고, NSP 손실을 사용하지 않습니다.
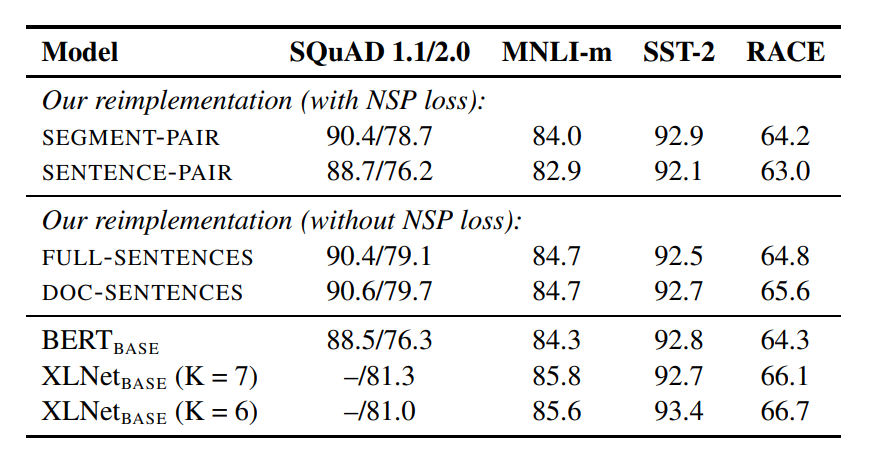
표를 봅시다 DOC-SENTENCES 성능이 가장 좋습니다 =>
NSP 빼도 되겠는데?
BATCH
배치사이즈가 클수록 성능이 잘 나온다는 연구들이 있음 , learning rate만 잘 만져준다면
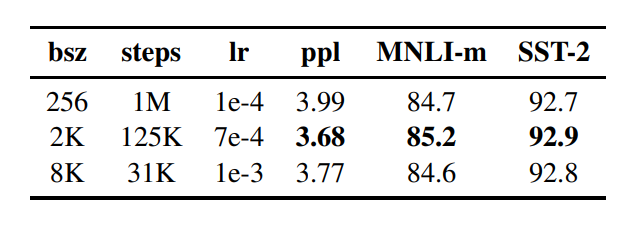
=> 2k 로 키운게 가장 잘하더라~
Text Encoding
BBPE로 바꿈
5. RoBERTa
XLNET 보면 더 많은 dataset, 더 긴 시간동안 training시켜서 BERT 성능을 능가함.
본문의 저자들은 이 두가지 Factor들의 중요성을 알아보기 위해서 BERT Base모델 설정을 그대로 가져와서 실험을 진행했다고 한다.
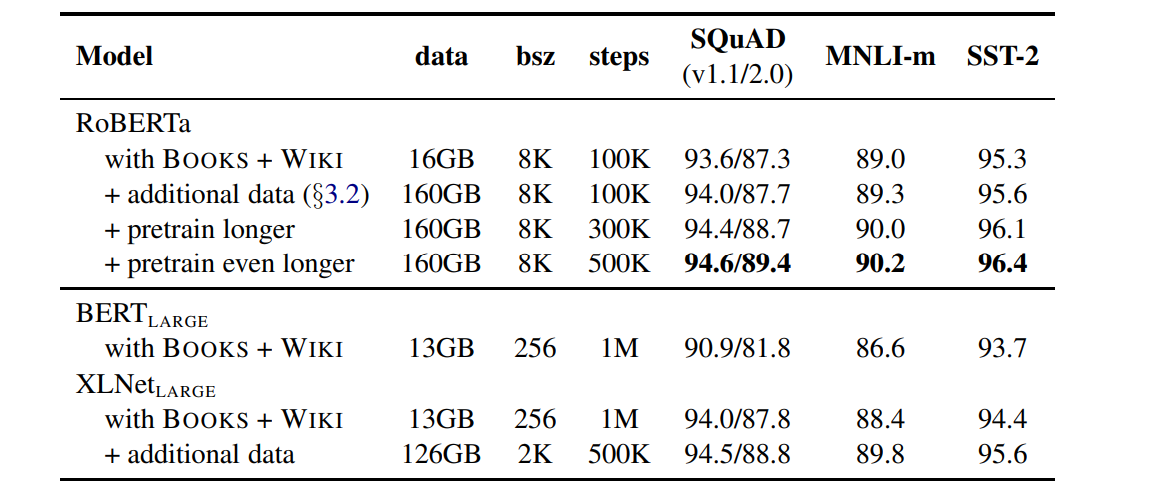
training step과 data size에 대한 performance는 위와같다.
