0. Abstract
대규모의 pre-trained된 모델은 fine-tuing하는 것은 NLP에서 효과적인 전이 매커니즘입니다. 하지만 매번 새로운 downstream task 가 있을때마다 파라미터수 전체를 fine-tuning하는 방식은 효율이 떨어집니다.
본 논문에서는 Adapter module을 제안합니다. 이는 기존 모델의 파라미터들은 고정하고 적은 수의 파라미터를 가진 layer를 중간에 추가해서 적은 수의 파라미터만 학습시킴으로써 효율을 증대시키는 방식입니다.
이런 방식으로 Sota에 근접한 퍼포먼스를 낼 수 있었습니다. (기존 방식의 3.6% 의 파라미터만 학습)
1. Introduction
클라우드 서비스같은 환경에서 새로운 작업이 계속 들어와도 효율적으로 모델을 유지하면서 높은 성능을 낼 수 있는 방법을 제안합니다.
NLP에서 일반적인 두가지 전이학습은 feature-based transfer 과 fine-tuning 방식이 있습니다.
feature-based 전이는 사전 학습된 임베딩 모델을 사용하여 텍스트 데이터에서 특징 벡터를 추출합니다. 추출된 특징벡터는 텍스트의 의미를 잘표현하는 벡터이고 , 이를 입력으로 사용하는 다운스트림 모델을 구축하고 학습합니다.
fine-tuning 방식은 우리가 알고 있듯이 모델의 파라미터 전체를 새로운 dataset에 재 학습시키는 단계이죠. 최근 연구는 fine-tuning이 feature-based 전이 보다 더 효과가 좋다고 합니다.
Feautre-based vs Fine-tuning
특징 기반 전이 학습(feature-based transfer learning)과 미세 조정(fine-tuning)을 같은 작업에 적용하여 비교하는 예시를 들어보겠습니다. 여기서는 텍스트 분류 작업을 예로 들어 설명하겠습니다.
예시: 텍스트 분류 작업
1. Feature-based Transfer Learning
단계:
- 사전 학습된 임베딩 모델 준비:
- 예를 들어, BERT 모델을 대규모 텍스트 데이터(위키피디아 등)로 사전 학습합니다.
- 특징 추출:
- 학습된 BERT 모델을 사용하여 각 텍스트 입력을 고차원 벡터(임베딩)로 변환합니다. 예를 들어, 문장을 BERT에 입력하여 [CLS] 토큰의 벡터 표현을 사용합니다.
- 다운스트림 모델 학습:
- 추출된 임베딩 벡터를 입력으로 하는 간단한 분류 모델(예: 로지스틱 회귀, SVM)을 학습시킵니다. 이 모델은 텍스트가 긍정적인지 부정적인지를 예측합니다.
특징:
- 사전 학습된 BERT 모델은 고정되어 있고, 텍스트를 벡터로 변환하는 데 사용됩니다.
- 분류 모델만 학습하면 됩니다.
- 사전 학습된 모델의 지식을 그대로 사용합니다.
2. Fine-tuning
단계:
1. 사전 학습된 모델 준비:
- 마찬가지로, BERT 모델을 대규모 텍스트 데이터로 사전 학습합니다.
- 미세 조정:
- 사전 학습된 BERT 모델을 텍스트 분류 작업에 맞게 미세 조정합니다. 여기서는 BERT 모델의 전체 가중치를 새로운 텍스트 분류 데이터셋으로 학습합니다.
- 예를 들어, BERT의 최종 레이어 위에 분류기를 추가하고, 전체 BERT 모델을 다시 학습시킵니다.
특징:
- BERT 모델의 전체 가중치를 조정합니다.
- 사전 학습된 모델을 특정 작업에 맞게 최적화합니다.
- 더 많은 계산 자원과 시간이 필요할 수 있습니다.
비교
요소 특징 기반 전이 학습 미세 조정 모델 준비 사전 학습된 BERT 모델, 간단한 분류기 사전 학습된 BERT 모델 학습 단계 1. 특징 추출
2. 분류기 학습1. 전체 BERT 모델 미세 조정 학습할 매개변수 수 분류기만 학습 (적은 수의 매개변수) 전체 BERT 모델 (많은 매개변수) 효율성 계산 자원이 적게 듦, 빠른 학습 계산 자원이 많이 듦, 더 긴 학습 시간 성능 종종 좋은 성능 일반적으로 더 높은 성능 (작업에 더 최적화됨) 응용 새로운 작업에 빠르게 적용 가능 특정 작업에 최적화된 성능 필요 시 예시 결과
특징 기반 전이 학습:
- 설정: 대규모 텍스트 데이터로 학습된 BERT, 10,000개의 텍스트 분류 데이터
- 특징 추출: BERT에서 임베딩 벡터 추출
- 분류기 학습: 로지스틱 회귀 모델 학습
- 결과: 85% 정확도
미세 조정:
- 설정: 동일한 BERT 모델, 동일한 10,000개의 텍스트 분류 데이터
- 미세 조정: BERT 모델 전체 학습
- 결과: 90% 정확도
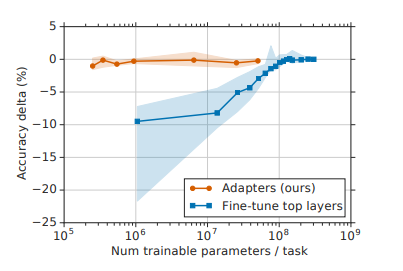
위의 그래프는 trainable parameter와 accuracy를 나타낸 그래프입니다. 파라미터수를 대폭 아끼면서 accuracy를 챙길 수 있는 것을 확인할 수 있죠.
Adapter 기반의 튜닝은 multi-task learning과 Continuous learning의 한계를 극복하며, 각 작업에 대해 소수의 작업 특화 파라미터만 추가해 높은 효율성을 달성합니다. 기존 모델의 파라미터를 고정하고 어댑터 모듈을 삽입하여 이전 작업을 잊지 않으며, GLUE 벤치마크와 여러 텍스트 분류 작업에서 거의 전체 미세 조정과 동등한 성능을 보여줍니다. 특히, 전체 파라미터의 3%만 사용하여 100% 파라미터를 사용하는 미세 조정과 유사한 성능을 달성합니다.
2. Adapter tuning for NLP
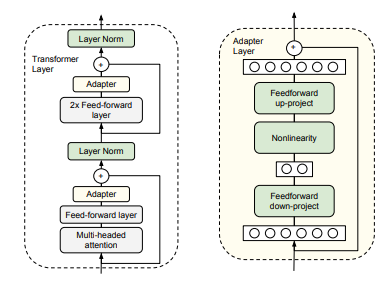
Adapter tuning은 위의 그림과 같이 구현합니다. bottleneck 구조를 채택해서 Adapter Layer를 구성한 것을 볼 수 있죠.
적은 수의 새로운 파라미터를 추가하여 다운스트림 작업에 대해 학습합니다. 기존 네트워크의 가중치는 변경되지않으며, 작업이 추가될때 모델크기가 천천히 증가합니다.
필요하지 않은 경우에 어댑터 모듈을 무시할 수 있으며 어댑터 마다 성능에 기여하는 크기가 달라집니다.
3. Experiments
Experiments setting
본 논문에서는 어댑터가 텍스트 작업에서 파라미터 효율적인 전이를 달성하는 방법을 다룹니다.
GLUE 벤치마크에서 어댑터 튜닝은 BERT의 전체 미세 조정과 성능 차이가 0.4% 이내이지만, 필요한 파라미터는 3%에 불과합니다. 추가적인 17개의 분류 작업과 SQuAD 질문 응답에서도 이 결과가 확인되었습니다.
어댑터 기반 튜닝은 네트워크의 상위 계층에 집중합니다. BERT를 기반 모델로 사용하며, 분류 작업은 첫 번째 토큰에 선형 레이어를 연결해 class label을 예측합니다.
Adam 최적화 알고리즘을 사용해 학습하며, 모든 실행은 4개의 Google Cloud TPU에서 이루어집니다. 하이퍼파라미터 sweep 을 통해 최적의 모델을 선택합니다. 우리의 목표는 전체 미세 조정과 유사한 성능을 유지하면서 총 파라미터 수를 줄이는 것입니다.
GLUE benchmark
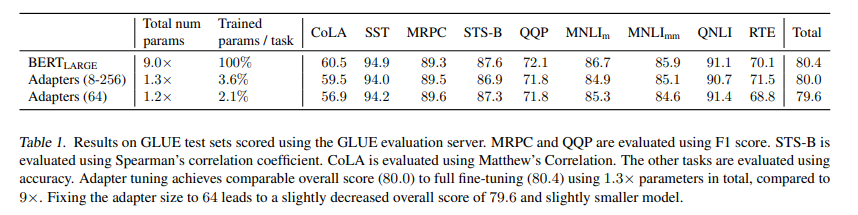
GLUE 데이터셋에서 BERTLARGE 모델을 사용하여 Adapter 튜닝을 평가합니다. 학습률과 Epoch 수, Adapter 크기를 조정하는 하이퍼파라미터 스윕을 수행했습니다. 실험 결과, 어댑터 튜닝은 평균 GLUE 점수 80.0을 달성했으며, 이는 전체 미세 조정의 80.4와 유사합니다. 최적의 어댑터 크기는 데이터셋에 따라 다르며, 예를 들어 MNLI에는 256, RTE에는 8이 선택되었습니다. 전체 미세 조정은 BERT 파라미터의 9배가 필요하지만, 어댑터는 1.3배만 필요합니다.
어댑터의 크기(또는 어댑터의 단위 수)가 8이라는 것은 어댑터 모듈의 병목(bottleneck) 층의 크기가 8이라는 의미입니다.
Additional Classification Tasks
본 저자들은 어댑터의 성능을 추가 검증하기 위해 다양한 public text classification 작업에서 테스트를 진행했습니다. 이 작업들은 900에서 330,000개의 Training example , 2에서 157개의 클래스, 평균 텍스트 길이가 57에서 1,900자에 이르는 다양한 특성을 가집니다. 배치 크기는 32로 설정하고, 다양한 학습률(1×10⁻⁵, 3×10⁻⁵, 1×10⁻⁴, 3×10⁻³)을 테스트했습니다. 각 데이터셋의 검증 세트 학습 곡선을 통해 20, 50, 100 에포크 중 최적의 값을 선택했습니다. 어댑터 크기는 2, 4, 8, 16, 32, 64를 테스트했습니다.
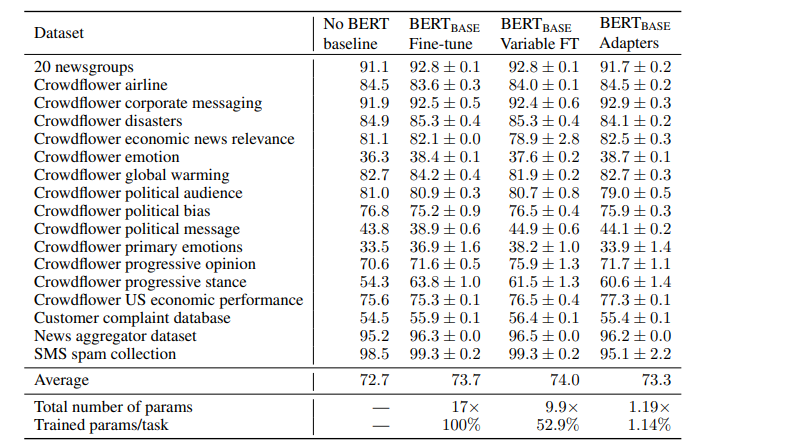
작은 데이터셋의 경우 전체 네트워크를 미세 조정하는 것이 비효율적일 수 있어, 상위 n개 레이어만 미세 조정하는 변형된 미세 조정 방식을 추가로 실험했습니다(n = 1, 2, 3, 5, 7, 9, 11, 12). 표는 n=12 일 때의 값을 나타낸 것 입니다. BERTBASE 모델을 사용하여, 모든 실험에서 최적의 하이퍼파라미터 값을 찾기 위해 하이퍼파라미터 검색을 수행했습니다. AutoML을 사용하여 수천 개의 모델을 탐색하고, 각 작업에 대해 검증 세트 정확도에 따라 최종 모델을 선택했습니다.
어댑터는 작업당 1.14%의 새로운 파라미터를 도입하여 총 1.19배 파라미터로 매우 효율적인 모델을 제공합니다.
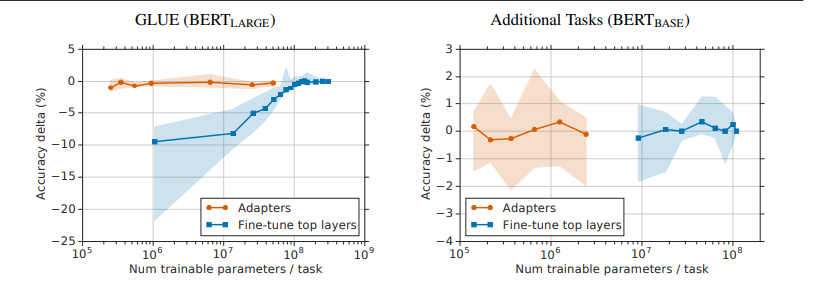
GLUE 작업인 MNLI와 CoLA에서, 상위 레이어만 미세 조정할 때 작업별 파라미터가 많아지지만 성능이 크게 감소했습니다. 예를 들어, 상위 레이어만 미세 조정하면 900만 개의 파라미터로 77.8%의 정확도를 달성하지만, 어댑터 크기 64로 튜닝하면 200만 개의 파라미터로 83.7%의 정확도를 얻습니다. 전체 미세 조정은 84.4%의 정확도를 달성합니다.
4. Conclusion
어댑터의 영향력을 평가하기 위해 일부 어댑터를 제거하고 모델을 재평가했습니다. 단일 레이어의 어댑터를 제거해도 성능 저하는 작았으나, 모든 어댑터를 제거하면 성능이 크게 감소했습니다. 이는 각 어댑터의 개별 영향은 작지만 전체적으로 큰 영향을 미친다는 것을 보여줍니다. 특히, 상위 레이어의 어댑터 제거가 더 큰 영향을 주었으며, 이는 상위 레이어가 작업별로 특화된 특징을 학습하기 때문입니다.
어댑터의 뉴런 수와 초기화 규모에 대한 실험에서는, 초기화 표준편차가 10-2이하일 때 성능이 안정적이었고, 뉴런 수가 다양한 어댑터 크기에서도 성능이 안정적이었습니다. 예를 들어, 어댑터 크기 8, 64, 256에서 평균 검증 정확도는 각각 86.2%, 85.8%, 85.7%로 나타났습니다.
어댑터 아키텍처의 여러 확장(배치/레이어 정규화 추가, 어댑터 레이어 수 증가, 다양한 활성화 함수, 어텐션 레이어 내 삽입, 병렬 어댑터 등)은 성능 향상을 크게 가져오지 않았습니다. 따라서 원래의 어댑터 아키텍처가 단순하면서도 성능이 우수하여 권장됩니다.
