0.💡Abstract
BERT같은 대규모 pre-training Language model들은 계산 비용이 너무 높다는 문제점이 있다.
=> edge device에서 사용 어려움
본문의 저자들은 model size를 줄임으로써 inference time을 줄이고 , accuracy는 그대로 가져가는 Transformer distillation 이라는 기법에 대해 소개한다.
2-stage 방식으로 학습을 진행하며 (General + specific task)
단 4개의 층으로 이루어진 TinyBERT 모델은 GLUE 벤치마크에서 BERT_base의 96.8% 성능을 유지했다고 한다.
기존 BERT모델보 다 7.5배 작으면서 9.4배 inference속도가 빠른 레전드 모델이라고 할 수 있겠다. (6개로 늘리면 성능 감소도 없다고함 )
어떤 방법을 썼길래 이렇게 야무지게 경량화가 되었을지 정말 궁금하다!
1. 💡Introduction
pre-train 이후 fine-tuning 은 NLP의 새로운 패러다임으로 자리잡았다.
그러나 Revealing the Dark Secrets of BERT라는 한 논문에서 BERT는 heavily overparametrized되어 있다는 문제를 발견했다. ( 줄여도 되겠다~~)
실제 fine-tuning task에 따라서 특정 attention head나 특정 layer를 disable 했을 때, 성능 향상이 되는 현상을 관찰했음.
경량화는 크게 세가지 1. Quantization 2. weights pruning 3. Knowledge distillation 방식이 있다.
본 논문은 3번에 대해서 주로 다룰 것이다.
네 종류의 loss function울 사용할 것임
- Embedding layer Representation
- Hidden states Representation
- Attention Matrices Representation
- prediction Loss
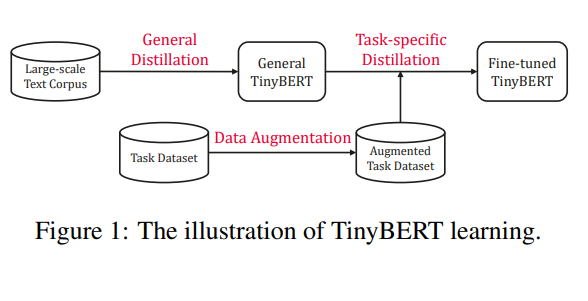
먼저 pre-trained BERT를 teacher model 삼아 학습시키고 나서 genral 한 TinyBERT 모델을 얻으면
fine-tuned모델을 teacher model 삼어
Data-augmentation을 적용해서 학습을 최종적으로 시킨다고 한다.
2.💡Preliminaries
Attention is all you need + Distilling the Knowledge in a Neural Network 논문을 언급하며 Transformer architecture 기반의 KD method를 소개함
복습하는 부분인데 이미 다 정리한 내용들이니 넘어가도록 하자.
3. 💡Method
Attention weight 을 KD를 위해서 mapping하는 것 즉 M번째 student layer가 N번째 teacher layer에 mapping될 때 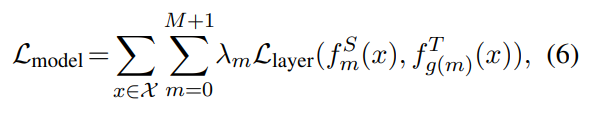
다음과 같은 L를 줄이는 것이 목표가 된다. (g(m)=n)
Transformer-layer Distillation
Transformer-layer Distillation은 attention based distillation 과 hiddenstates based distillation으로 구분된다.
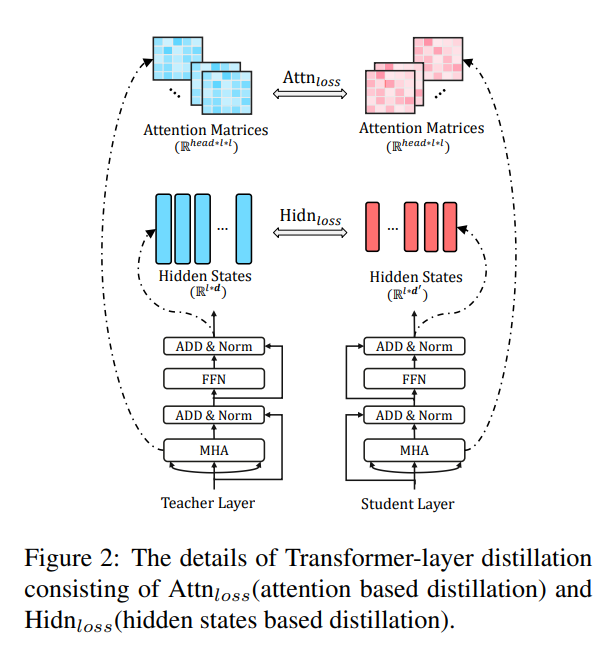
attention-based distillation은 BERT의 attention weight가 상당한 량의 linguistic knowledge를 함유하고 있다는 논문을 참고해서 실행하게 되었다고 한다.
그러면 Student model 의 선생님의 attention weight를 배우면 좋지 않겠는가?
첫번째 Loss
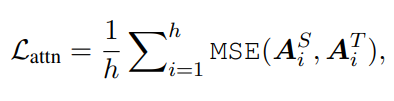
그래서 탄생한게 첫 번째 Loss다.
매우 직관적임. 특이한점은 softmax 전의 값을 대상으로 한 LOSS라는거 (logit값들로 loss구함)
로짓값을 비교하는 것이기 때문에 dimension이 달라도 MSE연산이 가능하다!
두번째 Loss
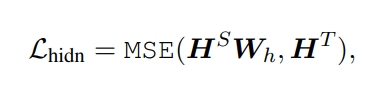
이건 최종 hidden-state들 간의 loss 인데 (BERT니까 인코더 밖에 없다는 사실을 기억하자)
Student hidden layer에 Linear layer를 하나 추가해서 Teacher model의 hidden state의 size에 맞춘뒤 MSE 함.
세번째 Loss
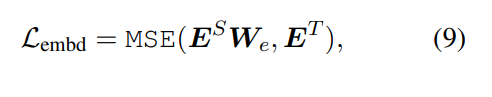
임베딩 쪽도 마찬가지로 W matrix 곱해줌.
Prediction-layer Distillation
네번째 loss
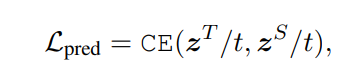
마지막 loss는 KD논문에서 나온 그대로의 Loss이다.
Temperature value는 1일때 가장 성능이 잘 나온다함.
뭐가 제일 중요할까?
Ablation study에서는 1,2번째 loss를 없앴을 때 가장큰 성능 저하를 보였다고 함
TinyBERT Learning
얘도 똑같이 두 단계로 학습했다고 언급했었지?
BERT에서 사전 학습한 방대한 양은 Compressed model 에도 잘 전달이 되어야 할 것이다.
pre-train BERT를 교사로 삼아 학습했듯이
Fine-tuning 때도 Fine tuning BERT를 교사로 삼는다.
근데 Fine-tuing할때는 data augmentation technique를 추가로 구사함

pt=0.4 ,Na =20, K=15일때 가장 성능이 좋았다고 한다.
15x0.4= 6배정도 augmentation 시켰다고 생각하면 되겠네요.
4.💡Experiments
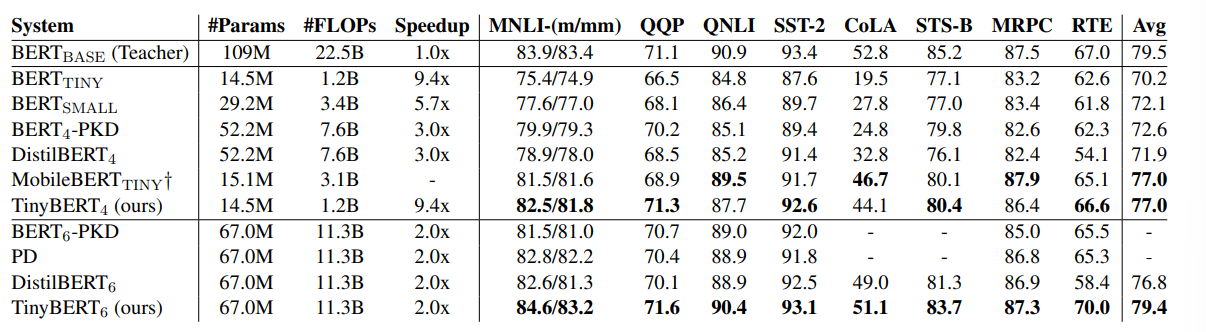
- TinyBERT는 GLUE 벤치마크에서 BERTSMALL보다 평균 6.3% 더 높은 성능을 보임
- TinyBERT는 Distilled BiLSTM보다 모델 크기는 크지만 추론 속도는 더 빠릅니다.
- CoLA Task에서 TinyBERT는 다른 모델들보다 좋은 성능을 나타냅니다.
- TinyBERT는 embedding size와 hidden size를 유연하게 조절할 수 있어 더 유연한 모델 크기 조절이 가능합니다.
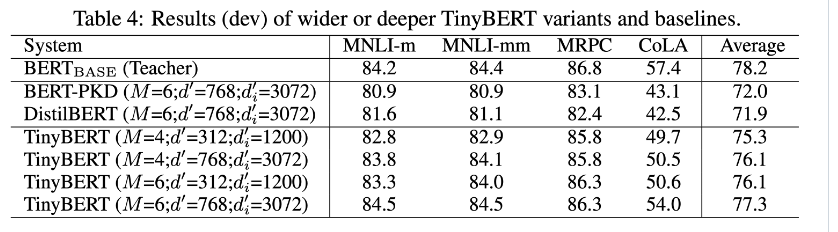
모델 사이즈 키울수록 성능 당연히 잘 나온다.
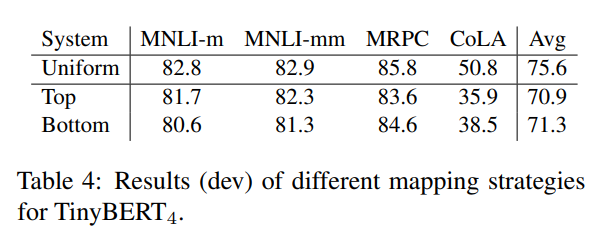
Effects of Mapping Function
uniform 하게 mapping한게 성능이 가장 좋았음어찌보면 당연하다 조기교육 빡하고 손 놓는 것(top)이랑 마지막에 벼락치기 하는 것(bottom)보다는 꾸준하게 조금씩 알려줘야지 잘 배울 것 같다.
😀 후기
1400만개의 parameter로 1억개의 parameter에 육박하는 성능을 내는건 가히 놀랍네요!
Transformer Distillation이라는 참신한 KD 기법을 제시해서 흥미로웠습니다. 1/10의 크기로 같은 성능을 내는 것도 놀라웠구요
Loss함수에 있는 inference할때는 버려지는 Wh같은 행렬들이 있음에도 불구하고 이 경량화 기법이 잘 성능을 낸다는게 놀라웠습니다. 이 부분은 살짝 직관적이지 않아서 이해하는게 힘드네요 ㅠ
대 Transformer 시대에 잘 쓰일 것 같은 경량화 기법이였어요.
인용횟수가 1700정도나 되던데 왜인지 알 것 같습니다.
