0. Abstract
수백만 개의 웹페이지로 구성된 새로운 데이터셋 WebText로 훈련된 언어 모델은 명시적인 지도 학습 없이도 이러한 작업을 학습하기 시작한다는 것을 발견.
GPT 2는 1.5B 파라미터로 8개의 언어모델링 task중에서 7개의 Sota를 달성했고 여전히 underfit 됐다는 걸 강조.
(모델의 scale이 중요하다.)
이러한 발견은 자연스럽게 발생하는 시연(demonstrations)으로부터 작업을 수행하는 법을 배우는 언어 처리 시스템을 구축하는 유망한 path를 시사한다.
1. Introduction
요즘 시스템들은 competent generalist가 아닌 narrow experts라고 지적 (특정 task 만 잘하더라~)
그리고 종종 다양한 input에 따라 불규칙한 행동들을 ouput하는 현상이 나타남
현재 사용되는 인공지능 시스템을 더 견고하고 신뢰성 있게 만들기 위해서는, 다양한 분야와 작업에 걸쳐 모델을 훈련시키고 그 성능을 평가해야 한다는 것을 강조하며 GLEU benchmardk와 decaNLP를 언급한다.
하지만 generalization을 갖추기 위해선 많은 dataset이 필요하고 이러한 데이터를 대규모로 생성하고 그에 맞는 목적 함수(loss-function)을 설계하는 것은 현재의 기술로는 매우 어렵다.
이러한 흐름 속에, 논문에서는 parameter나 architecture의 수정 없이 바로 downstream task를 수행하는 zero-shot learning이 가능한 language model인 GPT-2를 제안한다.
2. Approach
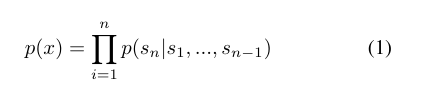
다음 조건부확률을 maximize하는 언어 모델링이 핵심 접근 방식임
다양한 task를 수행해야하는 general system의 경우 input은 같지만, input뿐만 아니라 수행되어지는 task도 같이 condition 되어야 한다고 언급
언어의 특성상 input,output,task를 유연하게 제공할 수 있음을 주목한다. decaNLP처럼. [p(output|input, task)]
unsupervised learning의 목표(다음 단어를 예측하는 것)는 supervised learning의 목표(입력과 출력 쌍을 이용해 예측하는 것)와 본질적으로 같기에
unsupervised learning에서 얻은 최적의 모델은 감독 학습에서도 최적의 모델이 될 수 있음
-
지도 학습은 명확한 입력-출력 쌍을 통해 빠르고 효율적으로 학습할 수 있다. 예측해야 할 목표가 명확하기 때문에 모델이 빠르게 수렴할 수 있음
-
비지도학습에서는 모든 맥락을 고려하기 때문에 속도가 더딜 수 있다. ( i love , i love machine, i love machine learning 매 순간 마다 weight 업데이트를 하니까 좀 더 문맥 전체를 이해하느라 시간을 쏟는 다고 생각하자)
본 논문에서는 잘 다듬어진 언어 데이터셋 (input-target label) 에서 "자연 상태의 언어(language in the wild)"로의 도약이 필요하다고 언급하고, 큰 용량의 모델이 방대한 인터넷의 정보들을 학습할 수 있다면, 이러한 모델은 비지도 멀티태스크 학습을 효과적으로 수행할 수 있다라고 말할 수 있다고 함
이를 검증하기 위해서 zero-shot setting에서 다양한 작업들에 대한 언어모델의 성능을 분석했고
결과적으로 언어모델이 방대한 데이터로 부터 스스로 유용한 패턴과 지식을 학습해 놀라운 성능을 발휘했음을 확인했다고 한다. 😲
2-1. Training Dataset
fiction book이나 위키피디아 대신 저자는 최대한 다양하고 큰 dataset을 이용하려고 했다.
Common Crawl과 같은 Web 스크랩이 그 중 하나였는데 상당한 데이터 품질 문제가 존재했음
Reddit에서 3 좋아요 이상의 글들의 outbound link들만 스크랩해서 quality 좋은 web scrape을 구성했음
이렇게 만들어진 dataset을 WebText라고 명명하였으며, 총 4천 5백만개의 link에 관한 text를 담고있다고 한다. 또한 2017년 12월 이후의 link들은 포함하지 않았으며, de-duplication과 heuristic based cleaning 과정을 거친 이후에는 8백만개의 document, 40GB의 text로 구성되었음을 밝혔음
또한, Wikipedia document의 경우 다른 dataset에서도 많이 보이는 data source이고, 이는 data overlapping 문제를 야기할 수 있기에 WebText에서 Wikipedia document는 제외하였다.
2-2. Input representation
현재의 대규모 언어 모델은 소문자 변환, 토큰화, 어휘에 없는 토큰 등의 전처리로 인해 모델이 다룰 수 있는 문자열이 제한된다.
하지만 Unicode 문자열을 UTF-8 바이트로 처리하는 방식이 이를 우아하게 해결할 수 있음.
그러나 바이트 수준의 언어 모델이 단어 수준의 언어 모델에 비해 대규모 데이터셋에서 성능이 떨어진다는 점을 지적한다.
기존 BPE는 unicode 문자열이기 때문에 매우 큰 base vocabulary size를 가지는 것에 비해, 기본 vocabulary의 size를 256으로 줄일 수 있다는 장점이 있다며 Byte-level BPE를 제안한다.
- 유니코드 코드 포인트 기반 BPE: 전 세계의 모든 문자를 표현하기 위해 약 13만 개 이상의 기본 토큰이 필요.
- 바이트 수준 BPE: 모든 문자를 바이트 단위로 표현하기 때문에 256개의 기본 토큰만 필요. (하나의토큰은 0~255)
또 BPE가 카테고리를 넘어서 병합하지 않도록 하였음dog", "dog!", "dog? , ! , ? => dog , ! , ?
알파벳 카테고리와 기호 카테고리를 구분
2-3. Model
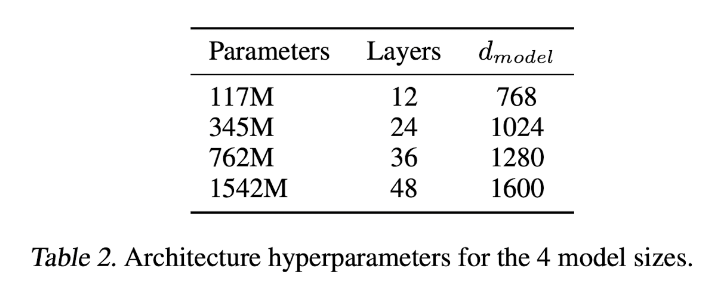
위에서부터 아래 순서대로 model의 크기가 커지며, 가장 작은 model은 GPT1의 크기와 동일하고, 2번째로 큰 model은 BERT-LARGE와 같은 크기이다. 저자들은 해당 model들 중에서 가장 큰 model을 GPT-2라고 소개한다.

- normalization layer 위치 수정 및 추가 ,
- 초기화 method 수정 (깊은 모델에서는 많은 잔차 레이어가 누적되면서 경로 상의 값이 너무 커지거나 작아질 수 있습니다)
- vocabulary size 확장 (=>50,257)
- context size 증가 (512=>1024)
- Batch size증가 (=>512)
GPT-1 구조에서 위의 정도만 바뀜
3. Experiments
3-1. Language Modeling
저자들은 zero-shot domain의 language modeling에서 어떻게 작동하는지에 대해서 관심을 가짐
이 Web text LM은 학습한 distribution에서 크게 벗어난 테스트를 해야한다.
이는 매우 표준화된 텍스트, 토크나이제이션 아티팩트(예: 분리된 구두점과 축약어), 섞인 문장, 그리고 WebText에서 매우 드물게 나타나는 <UNK> 문자열을 예측해야 함을 의미
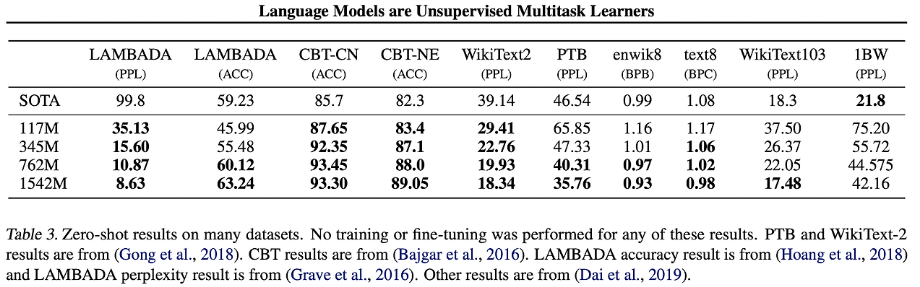
잘하더라 8개중 7개 SOTA달성
PTB나 WikiText-2와 같은 small dataset에서 큰 성능 향상
+LAMBADA나 CBT와 같이 LM의 long-term dependency를 측정하는 dataset에서도 비약적인 성능 향상
3.2 Children's Book Test
책에 등장하는 단락을 읽고 문제로 제시된 문장의 빈칸 채우기
10 개의 선택지 중에 고르는 것이기 때문에 하나씩 빈칸에 대입해서
가장 제시된 문장에 대한 확률이 크게 나오게끔 하는 선택지를 고른다!
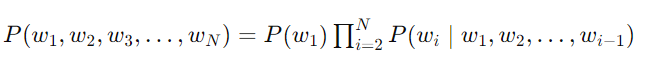
예를 들면, “The cat ___ on the mat” 에서 선택지 중 sat 를 대입했을 때
[ <sos> The cat sat on the mat ] 을 GPT 에 넣고
[ The cat sat on the mat <eos> ] => 각 시점의 label에 대한 확률을
다 곱해서 문장에 대한 확률을 얻고 다른 선택지에 대해서도 똑같이 계산 후 비교!
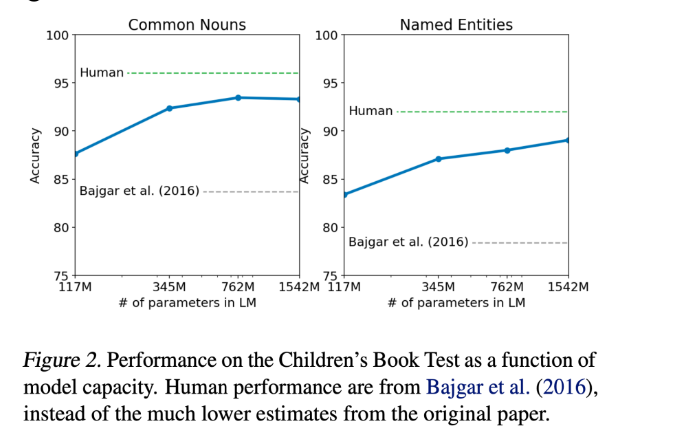
size가 커짐에 따라 성능이 steadily 증가하는 것을 볼 수 있다.
3-3. LAMBADA
• 마지막 단어를 제외한 앞의 문장들이 주어지고 마지막 단어를 맞히는 문제
• 문장들을 읽어 내려가며 문맥을 파악해서 마지막 단어를 잘 추론하는지를 평가함
• SOTA 에 비해 PPL 과 ACC 둘 다 압도 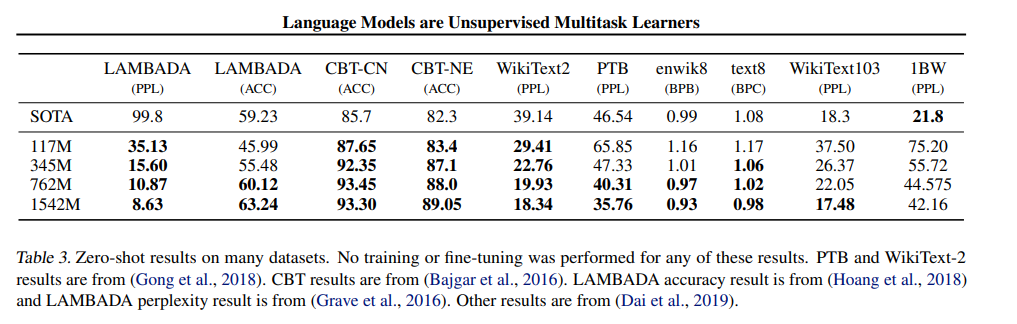
참고로 표에나온 것들은 fine-tuning을 하지 않은 것들이다.
3-4. WSC: Winograd Schema Challenge
WSC 챌린지는 대명사에 알맞은 것이 무엇인지 두 선택지 중에 고르는 문제이다
예) The trophy doesn't fit into the brown suitcase because it is too large.
- label: the trophy
CBT와 마찬가지로 문장의 확률을 비교하면됨
BUT!! it 다음에 올 문장만 따졌을 때 성능이 더 잘나온다고 주장한 논문이 있음

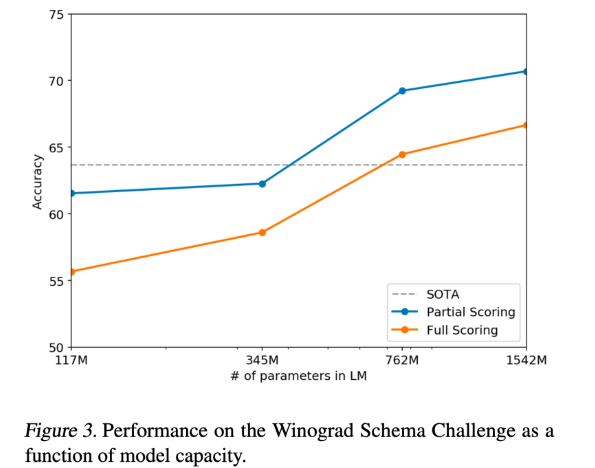
SOTA 뛰어넘어 주고~
3-5. Reading Comprehension
주어진 이야기를 듣고 문제에 답하는 것
문제와 함께 “A: ” 를 마지막 토큰으로 넣어줘서 답변을 얻었다고 함
문서, 관련 대화의 히스토리, 그리고 최종 토큰 A를 조건으로 할 때 GPT-2의 그리디 디코딩은 개발 세트에서 55의 F1 점수를 달성 (SOTA인 BERT는 89에 가까워지는 중)
GPT-2는 '누구(who)' 질문에 대해 문서에서 이름을 찾아 답변하는 등 간단한 검색 기반의 휴리스틱을 자주 사용하는 것으로 보인다
3-6. Summarization
CNN and Daily Mail dataset 을 사용함
끝에 TL;DR: 토큰을 붙여서 요약을 할 수 있게함
Top-k 랜덤 샘플링(Fan et al., 2018)로 100개의 토큰을 생성했다(k=2). 이는 다양하고 추상적인 요약을 유도한다. 이 100개의 토큰 중 처음 3개의 생성된 문장을 요약으로 사용했음
ROUGE metric에서도 별로~ random하게 뽑은 세문장과 비교했을때도 근차이 없고~
TL;DR:과 같은 task hint를 제거하면 성능이 6.4 point 만큼 떨어짐
3-7. Translation
english sentence = french sentence
english sentence =
= 토큰을 이용해서 번역시킴 ( one-shot learning)
출력의 첫번째 문장으로 평가한다.
BUT 그렇게 좋은성능은 못냈음
근데 WebText data에서 영어가 아닌 부분 거의 다 제거했는데도 번역 task에서 이정도의 성능을 뽑은건 놀라운 결과라고 주장
3-8. Question answering
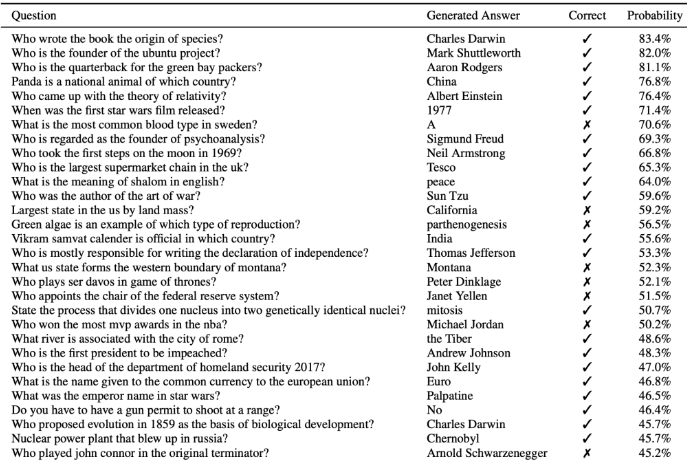
이 질문들은 학습할때 있지도 않았는데 4% 라도 맞혔다는게 신기
마무리
GPT-2의 접근 방식과 성공 요인은 다음과 같다:
-
Fine-tuning X:
- Next token prediction만으로 다양한 문제를 해결하려는 접근 방식을 채택.
- 각 문제마다 다른 fine-tuned 모델을 만들 필요가 없다는 점에서 범용적 모델로서의 장점을 보여줌.
-
성공 요인:
- 잘 걸러서 만들어진 WebText 데이터셋 덕분에 성능 향상이 가능했음.
- 인터넷의 아무 문장이나 가져다 썼다면 성능이 그다지 좋지 않았을 것.
-
기억에 의존:
- 테스트 데이터에 나오는 문장을 이미 학습할 때 본 경우에 결과를 얻었을 가능성이 있어, 이 점을 명확히 해야 함.=> 아니라는 것을 증명했음
-
파라미터 증가:
- 파라미터를 약 15억까지 키워가며 성능이 꾸준히 향상됨.
이러한 접근 방식은 범용 언어 모델의 가능성을 보여주었으며, 다양한 NLP 작업에서 높은 성능을 발휘할 수 있음을 시사한다.
후기
pre-train만으로 이러한 성능을 낸게 너무 신기했고 GPT-3 논문을 빨리 읽으러 가고 싶어졌습니다. LLAMA 논문 리뷰후에 GPT-3 논문리뷰를 해보도록 하겠습니다.
긴글 읽어주셔서 감사합니다
