하루에 한개꼴로 논문리뷰를 하니 무지 재밌다
이번엔 Encoder-decoder model로 유명한
Facebook(현 메타)에서 2019년 출간한 논문인 BART에 대해서 알아보자.
0. Abstract
BART는 고의적으로 원래의 텍스트를 망가트리고 훼손된 텍스트를 뒤돌리는 모델을 학습한다.
standard Transformer-based neural machine을 이용함
본 논문에서는 원래의 문장들을 무작위로 섞거나 텍스트의 구간을 하나의 마스크 토큰으로 대체하는 등 다양한 노이징 접근 방식을 평가하였음.
그 결과 여러 부문에서 SOTA 달성!
1. Introduction
그동안 self-supervised 방식들중 랜덤한 단어가 mask되어 있는 문장을 다시 복원하는 Masked language model과 denoising auto-encoder가 좋은 성능을 보인다.
최근 연구들은 여러가지 방식으로 특정 end task를 해결하는데 집중했지만 이는 applicability를 저해함 => General 하지 않아서 적용할 수 있는 분야 한정됨
BART는 Transformer 구조로 넓은 분야에 적용할수 있도록 만들어진 denoising auto-encoder임
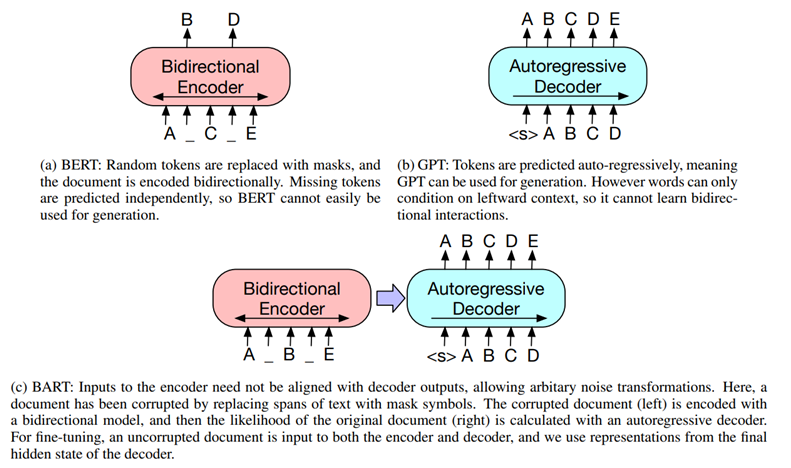
BART는 손상된 text를 입력받아 bidirectional 모델로 인코딩하고, 정답 text에 대한 likelihood를 auto-regressive 디코더로 계산한다.
이러한 설정은 noising이 자유롭다는 장점이 있다고 설명함
원래 문장의 순서를 무작위로 섞는 것과 임의의 길이(길이가 0일 수도 있음)의 텍스트 구간을 하나의 마스크 토큰으로 대체하는 새로운 인필링(in-filling) 스킴을 사용하는 것이 가장 뛰어난 성능을 보인다는 것을 발견
New fine-tuning scheme
기계 번역에서 BART모델을 몇 개의 추가적인 트랜스포머 레이어 위에 쌓아 올려서 외국어를 노이즈가 추가된 영어로 번역하도록 훈련한 후
BART를 통해 전파하면서 사전 훈련된 타겟값을 출력하도록 한다.
2. Model
2.1 Architecture
GeLU 함수를 사용하고 encoder, decoder는 각각 6개의 layer를 가지며 Large 모델은 12개씩 가지는 구조임
Encoder-decoder 구조이기 때문에 BERT와 같이 추가적인 feed-forward Network이 필요없음
2.2 Pre-training BART
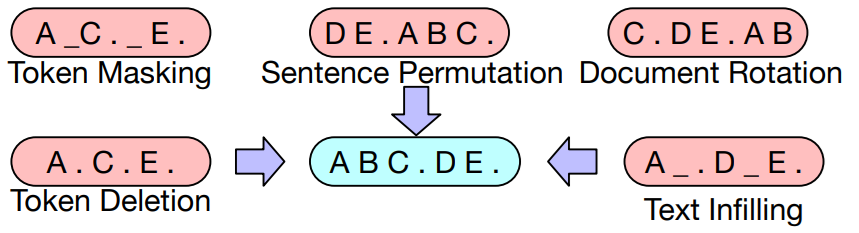
손상된 text로 pre-training을 수행한다.
논문에서는 총 5가지의 noising기법을 사용했음
1. Token Masking
- 목적: 모델이 문맥을 이해하고 숨겨진 단어를 예측하도록 학습.
- 방식: 문장에서 랜덤하게 선택된 단어를 [MASK] 토큰으로 대체.
- 예시:
- 원문: "The cat sits on the mat."
- 변환 후: "The cat [MASK] on the mat."
- 모델의 목표: [MASK] 부분이 "sits"임을 예측.
2. Token Deletion
- 목적: 모델이 입력의 어느 위치에 단어가 없는지를 결정하도록 학습.
- 방식: 문장에서 랜덤하게 선택된 단어를 삭제.
- 예시:
- 원문: "The cat sits on the mat."
- 변환 후: "The cat on the mat."
- 모델의 목표: 삭제된 단어("sits")의 위치를 예측.
3. Text Infilling
- 목적: 모델이 연속된 단어나 문구의 복원과 몇 개의 단어가 빠져 있는지 예측하도록 학습.
- 방식: 문장에서 연속된 텍스트 스팬을 샘플링하고, 각 스팬을 하나의 [MASK] 토큰으로 대체. 스팬 길이는 포아송 분포에서 추출.
- 예시:
- 원문: "The quick brown fox jumps over the lazy dog."
- 변환 후: "The quick [MASK] jumps over the lazy dog."
- 모델의 목표: [MASK] 부분이 "brown fox"임을 예측.
4. Sentence Permutation
- 목적: 모델이 문서의 문장 순서를 예측하도록 학습.
- 방식: 문서를 문장 단위로 나누고, 이 문장들을 무작위 순서로 섞음.
- 예시:
- 원문: "The cat sits on the mat. It is a sunny day."
- 변환 후: "It is a sunny day. The cat sits on the mat."
- 모델의 목표: 문장의 원래 순서를 예측.
5. Document Rotation
- 목적: 모델이 문서의 시작 부분을 식별하도록 학습.
- 방식: 문서에서 임의의 토큰을 선택하고, 이 토큰을 문서의 시작으로 하여 문서를 회전.
- 예시:
- 원문: "The quick brown fox jumps over the lazy dog."
- 변환 후: "over the lazy dog. The quick brown fox jumps."
- 모델의 목표: 문서의 원래 시작 부분을 식별.
이렇게 각 기법의 목적과 방식, 예시를 통해 모델이 다양한 방식으로 입력을 다루고 이해할 수 있도록 돕는 것이 목표임.
3. Fine-tuning BART
3-1. Sequence Classification tasks
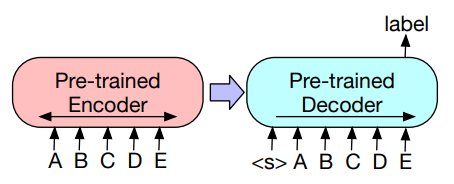
같은 input을 넣어준다. 마지막에 토큰을 추가해서 final hidden state를 구하고 이걸로 inference한다.
3-2. Token Classification Tasks
전체 document를 인코더와 디코더에 입력함.
디코더의 top hidden state를 각 단어에 대한 representation으로 사용하고 이걸 token classification에 사용한다.
3-3. Sequence Generation Tasks
BART는 auto-regressive한 디코더도 있기 때문에 문장을 생성하는 task에도 직접적으로 fine tuning 될 수 있다.
ex) 질문 응답 , 요약
많은 문서-질문-답변 쌍을 통해 모델을 학습시켜, 모델이 질문에 적절히 답변할 수 있도록 함.
3-4. Machine translation
BART 모델 전체를 기계 번역을 위한 사전 학습된 디코더로 사용하고, 새로운 인코더를 추가하여 인코더-디코더 구조로 파인 튜닝한다. 새로운 인코더는 외국어 입력을 BART가 학습한 언어(예: 영어)로 디노이징할 수 있는 형태로 매핑한다.
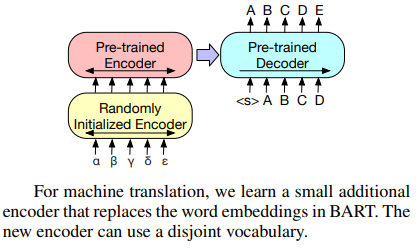
이 새로운 인코더는 BART와 다른 어휘(vocabulary)를 사용할 수 있다. 새로운 인코더는 두 단계로 학습되며, 두 단계 모두 교차 엔트로피 손실(cross-entropy loss)을 사용하여 역전파(backpropagation)한다.
첫 번째 단계에서는 대부분의 BART 파라미터를 고정하고,새로 붙인 인코더와 BART의 위치 임베딩(position embedding), BART 인코더의 첫 번째 레이어의 셀프 어텐션 입력 투영 행렬(self-attention input projection matrix)만 학습시킨다.
두 번째 단계에서는 모든 파라미터를 학습시킨다.
