- dplyr 패키지의 함수들 주로 사용
- 파이프 연산자 %>% 로 연결됨 (데이터프레임%>%함수, 함수%>%함수)
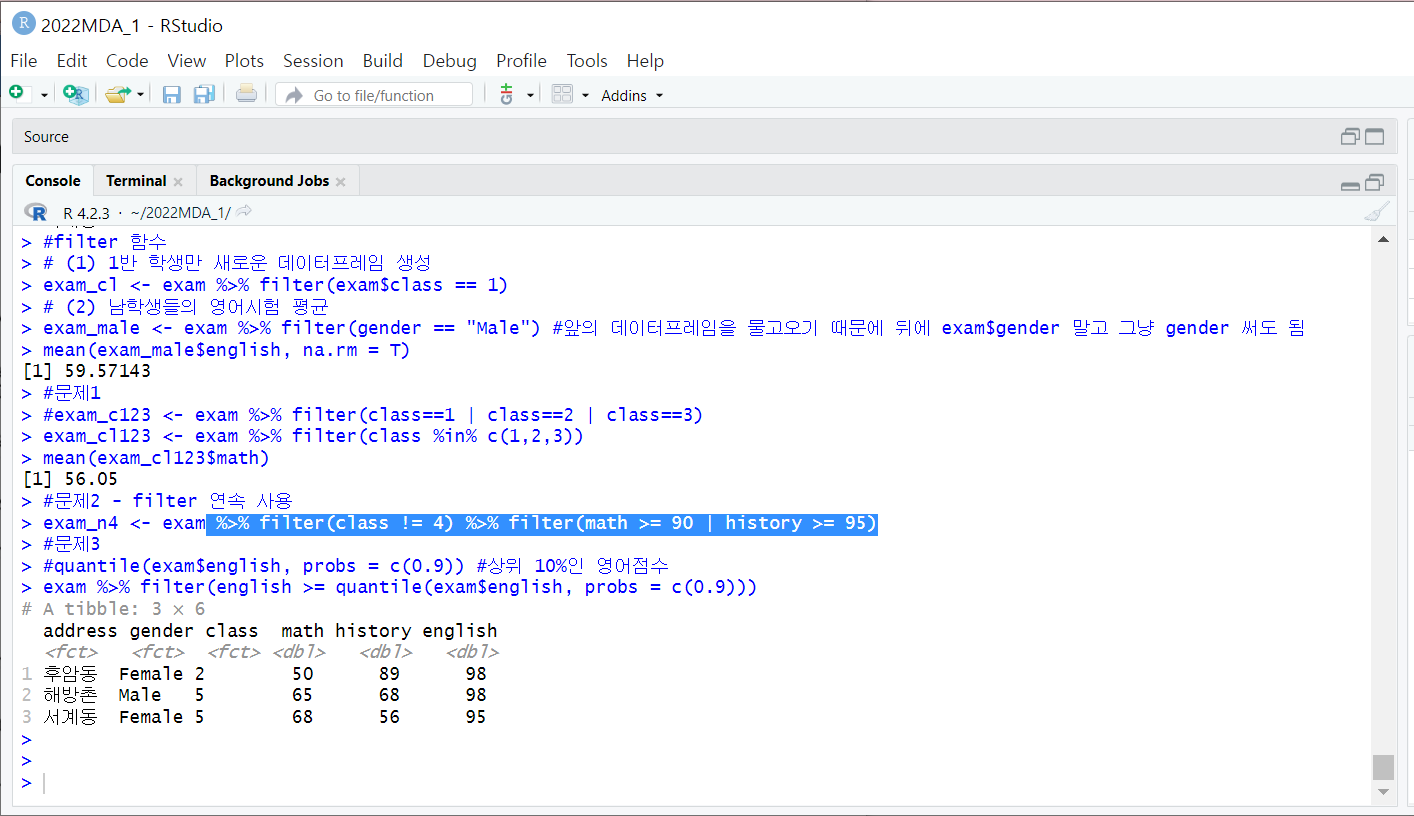
1. filter 함수
filter(조건)
- 조건에 부합하는 사례들을 추출할 때 사용
- 파이프 연산자 (%>%) 를 사용해서 filter 함수 연속 사용 가능
filter() %>% filter( )
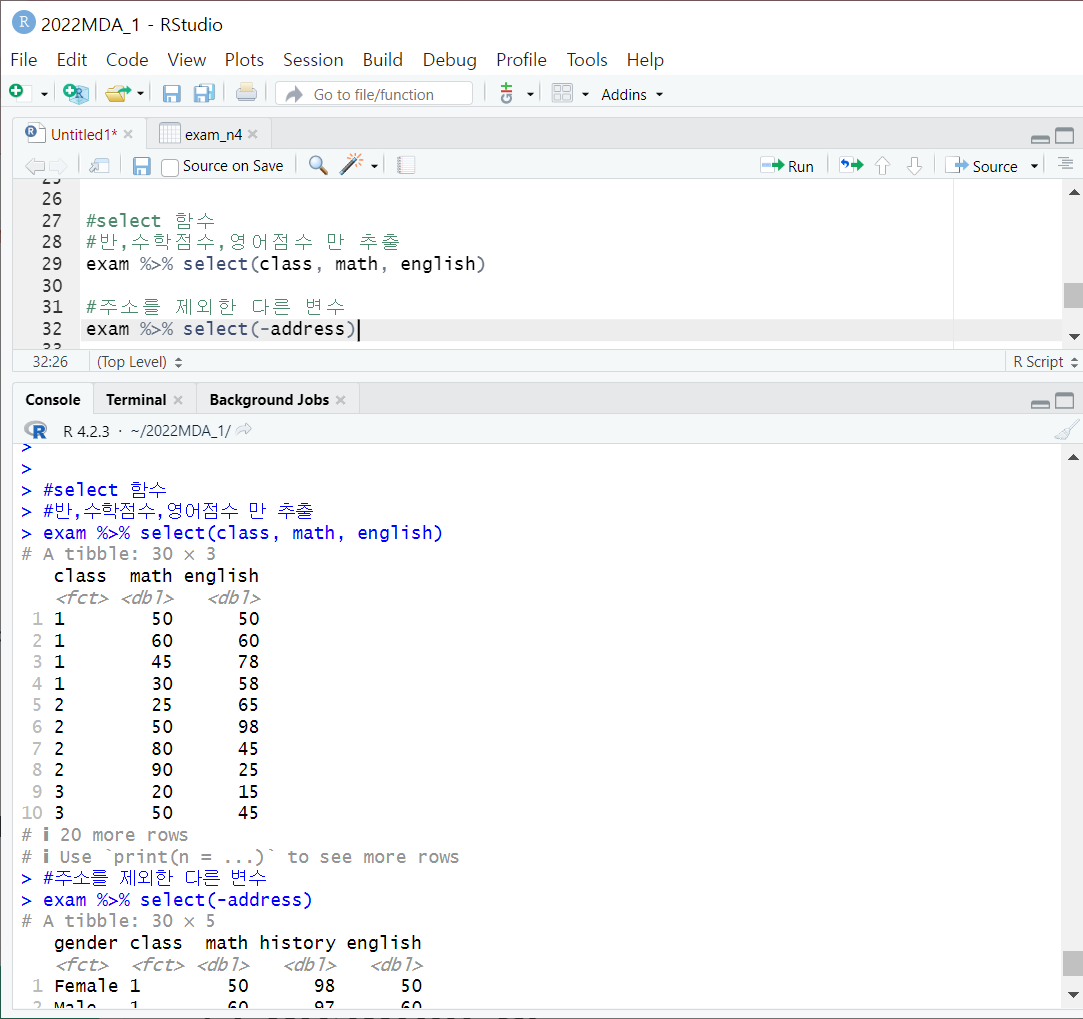
2. select 함수
select(변수, 변수, ...)
- 원하는 변수들만 추출
- 변수들은 쉼표로 연결
- - 표시를 하면 해상 변수 제외
2-1. 특정 단어가 포함된 변수 추출
select(contains("특정단어"))
- 예를 들어, contains("add") 라고 하면 변수명 중에 add가 포함된 address 가 출력되는 것
- contains 안에 " " 하나만 입력 가능, 따라서 여러개의 단어들 중 포함된 변수를 추출할 경우 => 논리연산자 | 써야 함.

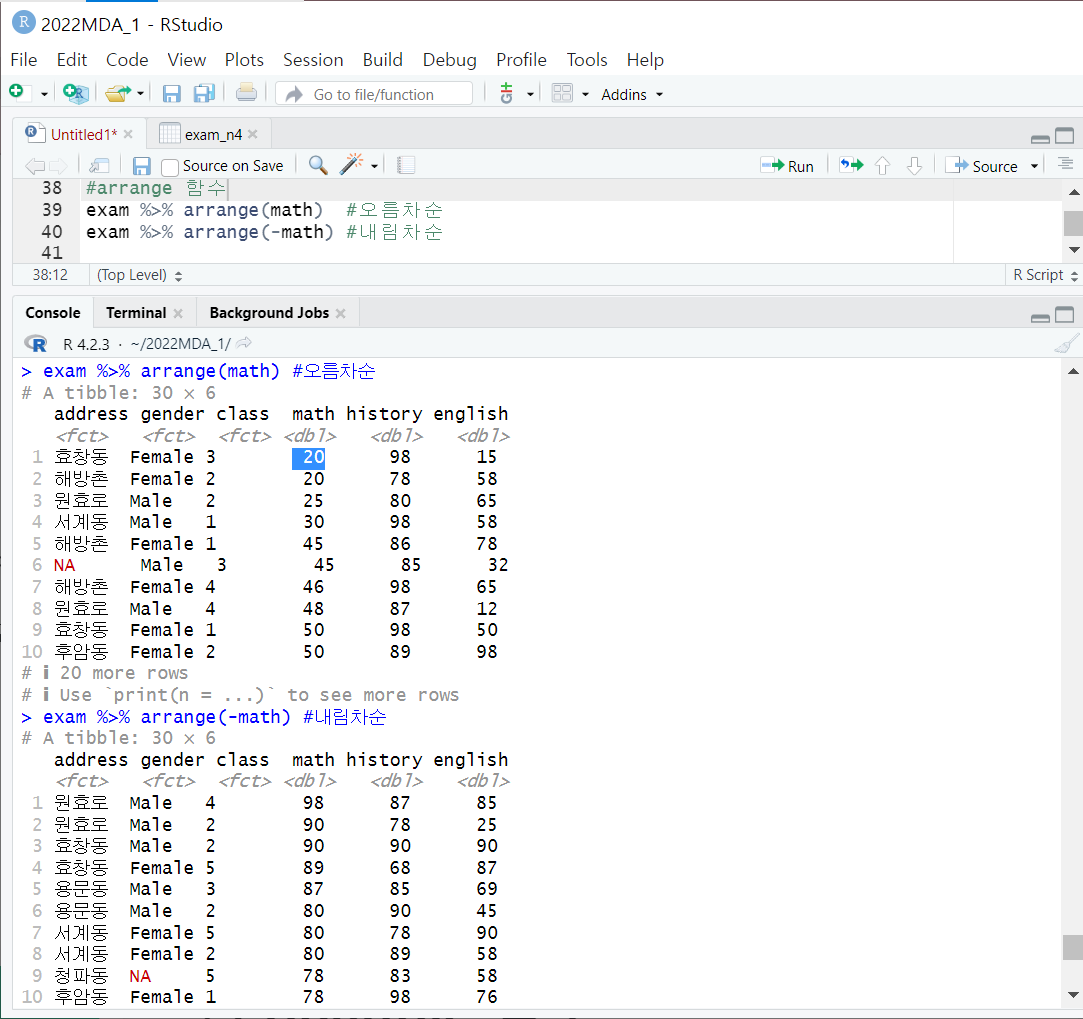
3. arrange 함수
arrange(정렬할변수명)
- 정량적 변수에 대해
- 오름차순/내림차순 으로 정렬
- - 붙이면 내림차순
- NA 값은 오름차순/내림차순에서 모두 제일 마지막으로 정렬됨
- 정렬 기준이 여러개 인 경우, 우선 순위에 따라 쉼표로 구분
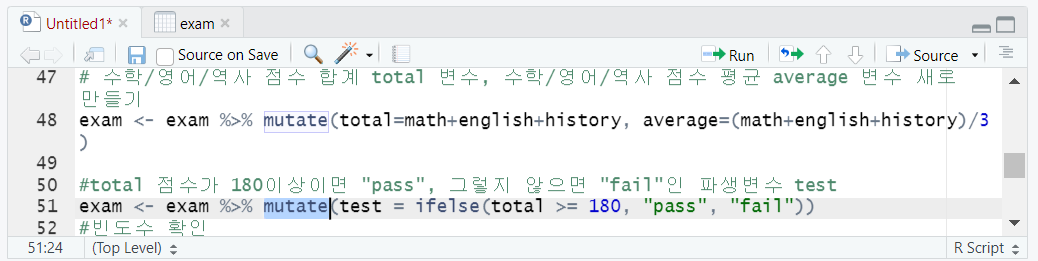
4. mutate 함수
mutate(새변수명 = 조건)
- 기존 변수를 활용하여 새로운 변수를 만들 때
- 동시에 여러개의 변수(파생변수)를 만들 수 있음, 쉼표로 구분
4-1. ifelse 함수와 함께 사용
mutate(ifelse())

4-2. case_when 함수와 함께 사용

5. relocate 함수
데이터프레임명 <- 데이터프레임명 %>% relocate(변수1, .after(또는 .before)=변수2)
- 변수1을 변수2의 뒤(또는 앞)으로 이동
- 변수의 위치를 이동시킬 때
- 맨 앞으로 이동시킬 때,
relocate(변수)만 적으면 됨

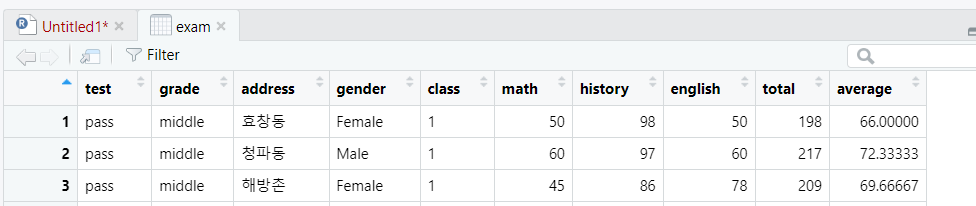
5-1.특정 척도 변수를 통채로 맨 앞으로 이동시킬 때
데이터프레임명 <- 데이터프레임명 %>% relocate(where(is.척도))
- is.charactor / is.factor / is.integer 등등

(test, grade 가 문자형 척도 변수)
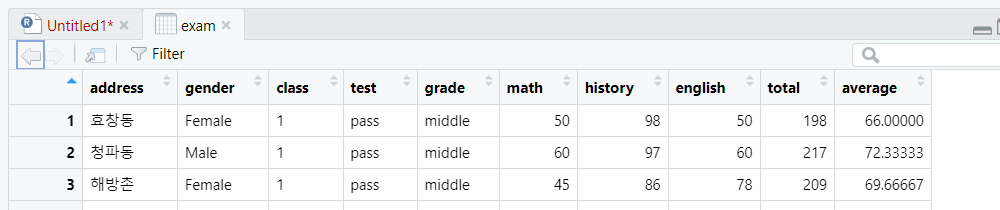
5-2.특정 척도 변수를 통채로 이동시킬 때
데이터프레임명 <- 데이터프레임명 %>% relocate(where(is.척도), .before(또는 .after) = where(is.척도))

(address, gender, class 가 범주형 척도 변수)
6. group_by 함수
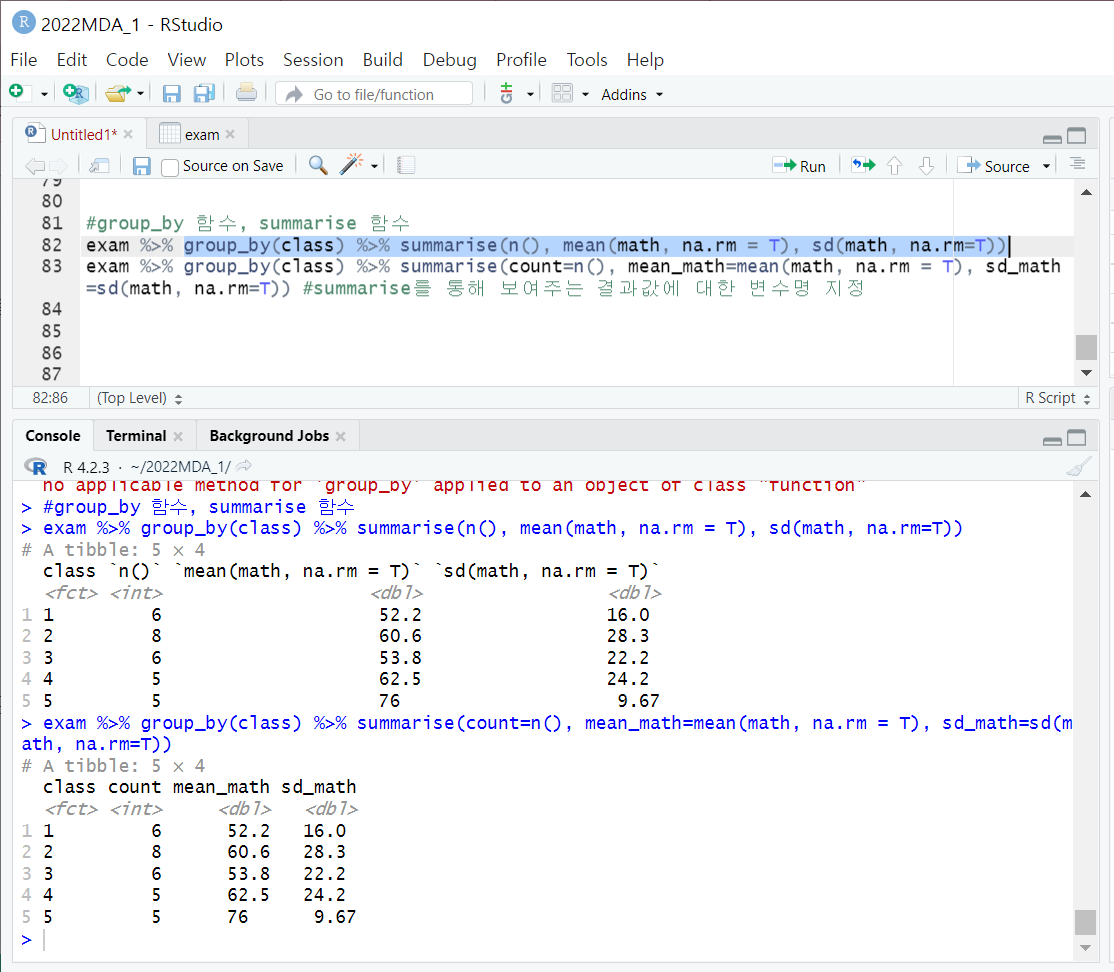
group_by(변수)
- 어떤 변수값을 기준으로 몇 개의 집단으로 구분
- 이 때 변수의 척도는 문자형, 범주형 (정량적 변수보다는 정성적 변수)이 바람직
7. sumarise 함수
summarise(기술통계량)
- 어떤 변수의 기술통계량에 대한 요약 결과
- 기술통계량, 빈도수
- group_by 함수 다음에 많이 쓰임
- 보여지는 결과값에 대한 새로운 변수명 지정도 가능 (보통 새로운 데이터프레임으로 저장할 때 사용)
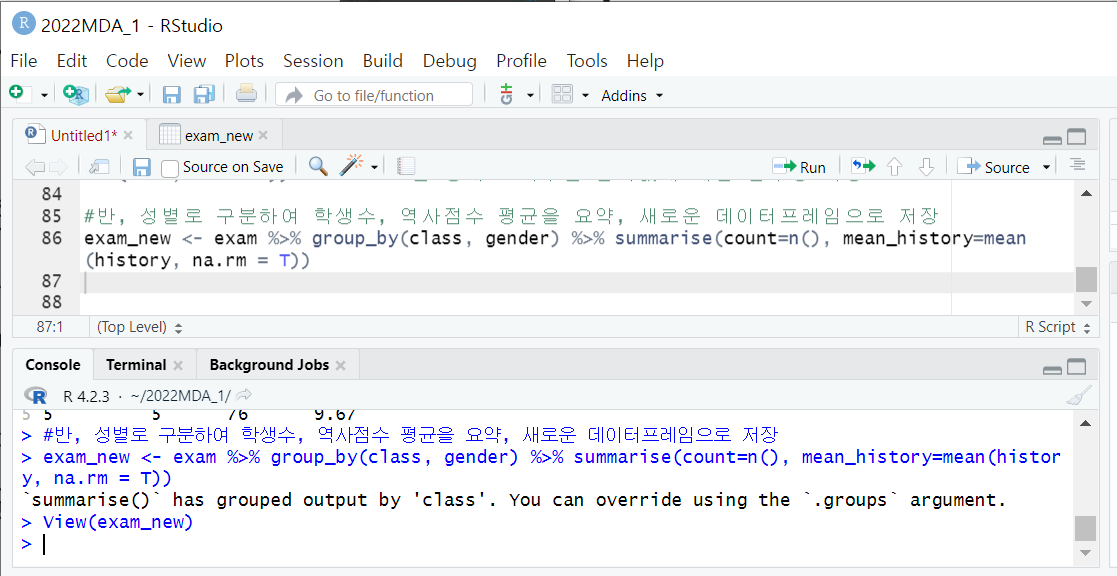
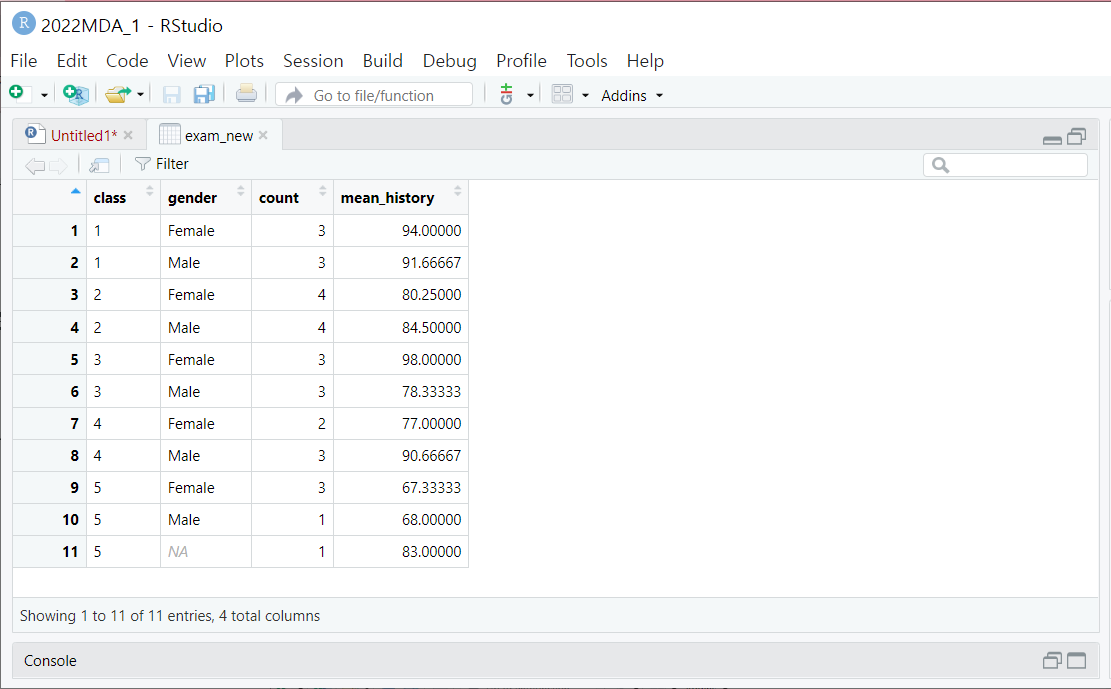
+) quantile 함수
qunatile(데이터프레임명$변수명, probs=c(비율))
- 내장함수
- 아래에서부터(하위) 비율*100% 인 지점 (비율 = 0.3, 0.9 등등)
+) round 함수
round(숫자, digit = 유효자릿수)
- digit = n 자리까지 유효숫자, n+1 자리에서 반올림
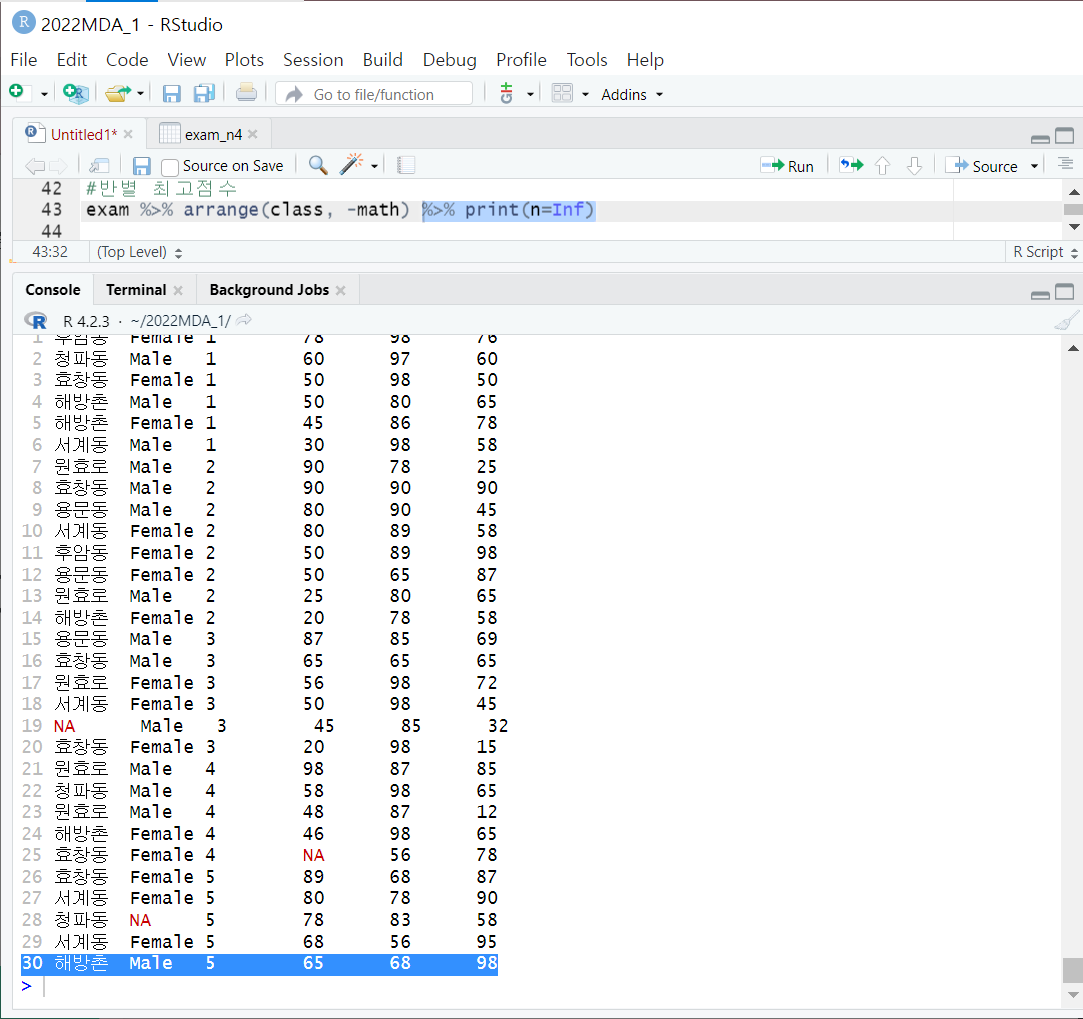
+) 콘솔창에서 전체 row 다 보기
%>% print(n=Inf)
- 맨뒤에 붙여주면 전체 결과 행(Inf = Infinity) 출력
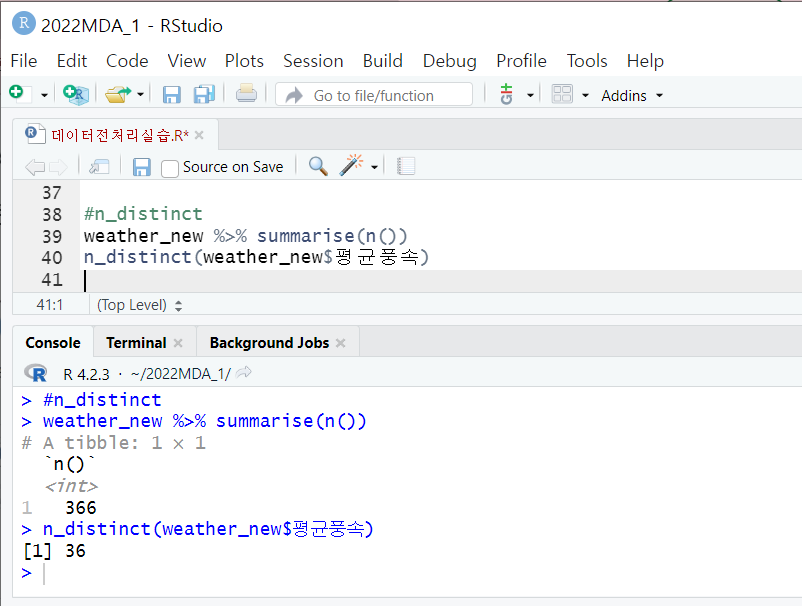
+) n_distinct 함수 - 변수 측정값 개수
- dplyr 패키지의 함수
- 어떤 변수에 대한 중복된 측정값을 제외한 고유 값의 개수 확인
- 변수의 척도와는 무관

( •̀ ω •́ )✧