-
출처
- 핸즈온 머신러닝2
- 주피터 노트북 github
- 핸즈온 머신러닝2 3장 pdf
-
되도록이면 책의 내용과 코드를 그대로 옮기기 보다는 요약과 보충설명!
읽기전에
개념 정리
확률적 경사 하강법(SGD: Stochastic Gradient Descent)
경사 하강법
- 한 점에서 접선의 기울기를 알면 어느 방향으로 점을 움직여야 함수값이 증가/감소하는지 알 수 있다.
- 미분값을 빼면 경사하강밥(gradient descent): 주어진 함수를 최소화, 즉 함수의 극소값의 위치를 구할 수 있다. 이때 극값에 도달하면(즉, 미분값=0) 움직임을 멈춘다.
- 변수가 벡터라면? 이를 위해, 각 변수 별로 편미분을 계산한 gradient 벡터를 이용
- 컴퓨터 계산 시 미분이 정확히 0이 되는 것은 불가능 하므로 norm(노름)을 사용하여 종료조건을 설정한다.
경사 하강법의 단점
- 비선형회귀의 경우 목적식이 볼록하지 않을 수 있으므로 수렴이 항상 보장되지 않는다. 특히 딥러닝의 경우, 목적식은 대부분 볼록함수가 아니다.
확률적 경사 하강법의 등장
- 경사 하강법이 모든 데이터를 사용해서 업데이트 했다면, 확률적 경사 하강법은 한개(그냥 SGD) 또는 일부 데이터(미니배치 SGD. 그러나 대부분 미니배치 SGD이므로, 그냥 SGD라고 명시해도 미니배치 SGD를 의미한다)를 활용하여 업데이트 한다.
- 일부 데이터를 사용하므로 좀 더 적은 연산량과 메모리를 사용한다.
- 딥러닝의 경우, 경사 하강법보다 확률적 경사 하강법이 실증적으로 더 낫다.
결정 함수(decision function)
- 결정 함수(Decision function): 데이터에 기반한 결정을 할 때 사용
- 손실 함수(Loss function): 사용할 결정 함수를 결정할 때 사용
분류성능평가지표
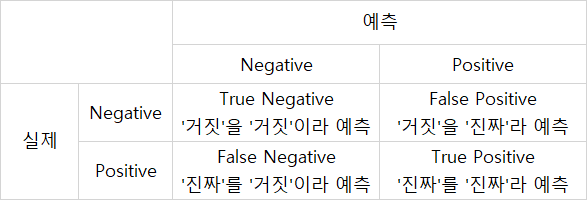
오차 행렬(confusion matrix)
: 클래스 별 예측 결과를 정리한 행렬
: 가설검정과 유사함!!
-
정밀도(precision)
: 즉 '진짜라고예측'한 것들 중에서 '진짜'의 비율 -
재현율(recall, 민감도, 진짜 양성비율(TPR))
: 즉,실제로 '진짜' 중에서 '진짜라고 예측'한 것의 비율
점수
: 정밀도와 재현율의 조화 평균(harmonic mean)
- 점수가 높을 수록 분류기의 성능을 좋게 평가하지만, 경우에 따라 조심할 필요가 있음
: 경우에 따라 재현율과 정밀도 둘 중의 하나에 높은 가중치를 두어야 할 때가 있기 때문- 예: 암 진단
: 실제로 음성지만 양성으로 오진을 포함(정밀도)
: 실제로 양성이지만 음성으로 오진을 포함(재현율)
- 예: 암 진단
정밀도와 재현율의 트레이드 오프
: 정밀도와 재현율은 상호 반비례 관계임. 따라서 적절한 비율을 찾아야 함.
- 결정 함수(decision function): 분류기가 각 샘플의 점수를 계산할 때 사용
- 결정 임계값(decision threshold): 결정 함수의 값이 이 값 이상이면 양성 클래스로, 아니면 음성 클래스로 분류.
- 임계값이 높을수록 정밀도는 높아지고 재현율은 낮아지며, 임계값이 낮을수록 재현율은 높아지고 정밀도는 낮아진다.
수신기 조작 특성(ROC) 곡선
: 거짓 양성 비율(FPR, 1 - 특이도)에 대한 진짜 양성 비율(TPR, 재현율, 민감도)의 그래프
: x축: 1-특이도, y축: 민감도
-
거짓 양성 비율(FPR)
: 양성으로 잘못 분류된 음성 샘플의 비율
: '가짜' 중에서 '진짜라고 예측'한 것의 비율
-
진짜 음성 비율(TNR, 특이도)
: 음성으로 정확하게 분류한 음성 샘플의 비율
: '가짜' 중에서 '가짜라고 예측'한 것의 비율
-
-
재현율(TPR)과 거짓 양성 비율(FPR)은 양의 상관관계를 가짐. 즉 트레이드오프가 존재. 따라서 좋은 분류기는 ROC 곡선이 y축에 최대한 근접하는 결과가 나오도록 해야함.
곡선 아래의 면적(AUC)
: 완벽한 분류기는 RPC의 AUC = 1, 완전한 랜덤 분류기는 0.5
다중 분류 학습
OvR(one-versus-the-rest, OvA(one-versus-all))
: 특정 숫자 하나만 구분하는 숫자별 이진 분류기 10개(0~9)를 훈련시키면, 클래스가 10개인 숫자 이미지 분류 시스템을 만들 수 있음. 이미지 분류 시, 각 분류기의 결정 점수 중에서 가장 높은 것을 클래스로 선택.
OvO(one-versus-one)
: 조합 가능한 모든 일대일 분류 방식을 진행하여 이진 분류기 훈련하고, 가장 많은 결투(duell)를 이긴 숫자를 선택(0과 1 구별, 0과 2 구별, 1과 2 구별 등)
: 분류기 각각의 결정 점수를 얻어 점수가 가장 높은 클래스를 선택
: 즉, 가장 많이 예측된 클래스를 최종 예측값으로 선택
: 클래스가 N개 일때, 분류기는 개 필요
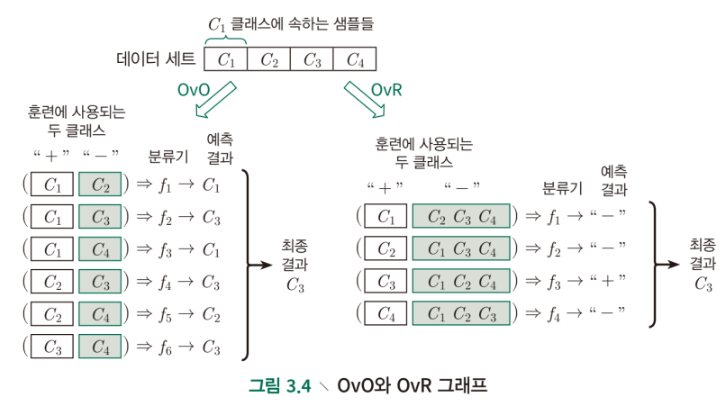
-
출처: 단단한 머신러닝: 머신러닝 기본 개념을 제대로 정리한 인공지능 교과서
-
두 학습기의 성능은 비슷
-
분류기 훈련 회수: OvR < OvO
- 즉, OvR의 메모리 사용량과 시간이 더 작음
-
훈련 단계에서 클래스 개수: OvR(모든 훈련 데이터 사용) > OvO(두 클래스의 데이터만 사용)
- 즉, 클래스가 많은 경우 OvO의 훈련 시간이 더 짧음
python 정리
fetch_openml()의as_frame매개변수: 기본 True(pandas.Dataframe이 반환), False(numpy.ndarray가 반환)변수명.reshape(): 데이터의 구조를 바꾸기plt.axis("off"): 축과 라벨을 끈다변수명.astype(np.uint8): 부호 없는 8비트 정수형으로 변환
: up.unit8 대신에 dtype=np.uint8, dtype='unit8', dtype='u1'도 가능y_train_5 = (y_train == 5): y_train 원소 각각에 대해 5라면 True, 아니라면 False를 반환하는 타깃 벡터를 생성. ndarray일 경우에 사용 가능.- 만약 list 였다면?
y_train_5 = list(map(lambda x: x == 5))
- 만약 list 였다면?
thresholds[np.argmax(precisions >= 0.90)]: precisions(정밀도)가 90% 이상인 수 중에서 최대값의 첫번째 인덱스를 찾고(np.argmax()), thresholds(임계값)에서 이 인덱스에 해당하는 값을 찾음.- 만약 list로 보고싶다면?
list((map(lambda x: x >= 0.90, list(precisions)))).index(True)
- 만약 list로 보고싶다면?
predict_proba(): 샘플이 행, 클래스가 열. 샘플이 주어진 클래스에 속할 확률을 담은 배열을 반환randint(start, stop): (start ≤ 난수 ≤ stop) 범위의 정수형(int) 난수 반환.randrange(a, b+1)와 같음np.random.randint(low, high=None, size=None, dtype='l'): high가 None이라면 (default 값임), 0에서 low까지의 값을 반환한다.
3장 분류
준비
데이터
- MNIST 데이터셋
: 70,000개의 손으로 쓴 28*28= 784 크기의 픽셀로 구성된 이미지 데이터
문제 정의
: 지도 학습, 분류, 배치 또는 온라인 학습(둘 다 가능)
- 확률적 경사하강법(stochastic gradient descent, SGD): 배치와 온라인
학습 모두 지원 - 랜덤 포레스트 분류기: 배치 학습
이진 분류기 훈련
- 5-감지기 만들기: 5와 5 아님의 두 개의 클래스를 구분하는 이진 분류기
확률적 경사 하강법(SGD) (더보기)
- 사이킷런
SGDClassifier클래스
: 매우 큰 데이터셋 처리에 효율적이며 온라인 학습에도 적합함
성능 측정
: 여러가지 방법이 존재. 회귀 모델보다 훨씬 어렵고 복잡.
교차 검증을 사용한 정확도 측정
- k-겹 교차 검증: 사이킷런
cross_cal_score()
: 그 결과, 정확도가 95% 이상이 나옴...but 이게 정말일까? - 숫자 5는 이미지의 10% 밖에 안됨. 그렇기 때문에, 만약 모든 숫자를 5 아님으로 판단하는 더미 분류기를 만들어도 정확도가 90% 이상으로 나오게 됨.
: 이는 훈련 세트가 어떤 클래스가 다른 것보다 월등히 많은 '불균형한 데이터셋'이기 때문ㅇ
- 따라서, 정확도는 분류기의 성능 측정 지표로 선호되지 않음
정밀도와 재현율 조율 (더보기)
- 오차 행렬
- 점수: 정밀도와 재현율이 비슷한 분류기에서는 이 점수가 높음.
정밀도와 재현율의 트레이드 오프
: 정밀도와 재현율의 적절한 비율을 찾아보자
-
분류기의 predict() 대시에
decision_function()함수를 사용하여 예측에 사용한 점수를 확인하고, 이를 기반으로 원하는 임계값을 설정할 수 있음.- 임계값 = 0: predict()와 같은 결과: True 반환
- 임계값을 높히면: 재현율이 낮아짐(실제로는 5인데, 5가 아니라 예측): False 반환
-
재현율에 대한 정밀도 곡선을 그려보자
AUC 측정 (더보기)
-
사이킷런의
roc_auc_score()
: ROC 곡선의 AUC를 측정 -
방금까지
SGDClassifier의 ROC 곡선이어다면, 이번에는RandomForestClassifier을 훈련시켜 ROC AUC 점수를 비교해보자- 훈련 세트의 샘플에 대한 점수를 얻는다
:decision_function()이 없기 때문에,predict_proba()사용 - 결과: SGDClassifier 보다 높은 AUC 값
- 훈련 세트의 샘플에 대한 점수를 얻는다
정밀도/재현율(PR 곡선) vs ROC 곡선
-
PR 곡선
: 데이터가 불균형 할 때
: 양성 클래스가 드물거나 거짓 음성보다 거짓 양성이 더 중요할 때
(정밀도와 재현율 모두 '실제 양성' 이거나 '양성 예측'..즉 양성 위주임. 그니까 양성을 판단하는 것에 더 집중하고, 음성인 것을 판단하는 비중이 적음)
: 분류기의 성능 개선 여지를 보여줌(오른쪽 위 모서리에 가까워질 수 있는지) -
ROC 곡선 사용
: 데이터가 균형일 때
: 양성 클래스 탐지와 음성 클래스 탐지의 중요도가 비슷할 때- 예: 양성(5)이 음성(5 아님)보다 매우 적은 본문의 데이터셋의 경우, ROC의 AUC 점수가 매우 좋게 나옴.
다중 분류기(다항 분류기) (더보기)
(multiclass classifier, multinomial clasifier)
: 세 개 이상의 클래스로 샘플을 분류하는 예측기
: 이진 분류기를 여러개 사용해 다중 클래스를 분류해보자
-
다중 클래스 분류 작업에 이진 분류 알고리즘을 선택하면 사이킷런이 알고리즘에 따라 자동으로 OvR 또는 OvO를 실행함.
:sklearn.svm.SVC 클래스으로 SVM 테스트 하기 -
decision_function()으로 OvO 혹은 OvR 학습기의 클래스당 점수를 확인하기. -
사이킷런에서 OvO나 OvR을 사용하도록 강제하기:
OneVsOneClassifier또는OneVsRestClassifier
에러 분석
: 가능성이 높은 모델을 찾았다고 가정하고, 이 모델의 성능을 향상시킬 방법을 찾아보자: 에러의 종류 분석
오차 행렬 살펴보기
cross_val_predict()함수로 예측 만들고,confusion_matrix()호출- 오차 행렬의 각 값을 대응되는 클래스의 이미지 개수로 나누어 에러 비율을 비교
: 이때 에러의 절대 개수로 나누지 말것- 행: 실제 클래스, 열: 예측한 클래스
개체 살펴보기
- 예: 3과 5 샘플 비교
- 선형 모델인 SGDClassifier
: 클래스마다 픽셀에 가중치를 할당하고 새로운 이미지에 대해 단순히 픽셀 강도의 가중치 합을 클래스의 점수로 계산함. 즉 단순히 픽셀 강도에만 의존.
: 이때 3과 5는 픽셀이 단 몇개만 다르므로 모델이 쉽게 혼동함
다중 레이블 분류
: 여러 개의 이진 꼬리표를 출력하는 분류 시스템
: 분류기가 샘플마다 여러 개의 클래스를 출력해야 할 때
- 예: 사진 속에서 'A 있고, B 없고, C 있음'은 [1, 0, 1]을 출력할 것.
다중 출력 다중 클래스 분류(다중 출력 분류)
(multioutput-multiclass classification, multioutput classification)
: 다중 레이블 분류에서 한 레이블이 다중 클래스가 될 수 있도록 일반화한 것. 즉 값을 두 개 이상 가질 수 있음.
- 예: 이미지에서 잡음을 제거하는 시스템
- 다중 레이블: 각각의 픽셀이 레이블 역할 수행
- 다중 클래스: 레이블이 0부터 255까지 픽셀 강도를 가짐
궁금증
- 139p. 해결
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
에서
- [:-1]로 마지막 인덱스는 뺀 슬라이싱을 하는 이유
- 만약 슬라이싱을 하지 않는다면, 다음 오류가 나온다
: x and y must have same first dimension, but have shapes (59966,) and (59967,)
: 즉 x와 y의 데이터 개수가 안 맞다는것! - x(임계값)이 y보다 데이터의 개수가 1개 적으므로, [:-1] 슬라이싱을 하여 데이터의 개수를 맞춘다. 데이터의 개수만 1개 빼면 되니까 [1:] 해도 상관은 없음!
- 만약 슬라이싱을 하지 않는다면, 다음 오류가 나온다
- "b--"와 "g-"의 의미
: blue, green(선 색깔)
- 140p.
thresholds[np.argmax(precisions >= 0.90)]: precisions(정밀도)가 90% 이상인 수 중에서 최대값의 첫번째 인덱스를 찾고(np.argmax()), thresholds(임계값)에서 이 인덱스에 해당하는 값을 찾음.
-
왜 정밀도가 90% 이상인 수 중에서 '최대값'을 찾는지 궁금합니다. 본문에서는 '최소한 90% 정밀도가 되는 가장 낮은 임곗값'을 찾는다고 적혀있으니, 최솟값을 찾아야하는게 아닌가요?
: argmax()는 최댓값 중에서 첫번째 값을 반환함. 그니까 가장 작은 임계값인거지..!! -
[그림 3-4]의 그래프에서 정밀도 90%의 임곗값은 약 8,000 입니다. 그러나 threshold_90_precision의 값은 약 3370 입니다. 그래프로 나타낸 값과 같아야 하는게 아닌가요?
: 랜덤값 때문인가? 아닌가?
-
143p.
정밀도/재현율 곡선(PR)과 ROC 곡선을 비교했을 때, 왜 PR 곡선은 양성 클래스가 드물거나 거짓 음성보다 거짓 양성이 더 중요할 때 사용하는지 이해가 잘 되지 않습니다. 거짓 양성 비율에 대한 진짜 양성 비율이 곧 ROC 인데, 절대값이 아닌 비율로서 계산하니까 양성 클래스가 드문 것과 상관 없지 않을까요?
: 위에 설명 참조 -
144p.
y_probas_forest[:, 1]에서 인덱스 0은 음성 클래스일 확률, 인덱스 1은 양성 클래스일 확률을 나타내는게 맞나요?
: 네 -
146p, 147p.
본문에서decision_function()은 샘플당 10개의 점수를 반환하며, 이 점수는 클래스마다 하나씩이라고 나옵니다. 이때 점수는 무엇을 의미하나요? OvO이라면 45개의 분류기가 예측한 결과값을 각 클래스(숫자 0~9)별로 세어서 합한 값이고, OvR이라면 각 분류기의 결정 점수(0~9숫자, 총 10개)를 의미하나요?
: 이해 완료 -
148p.
본문의 입력의 스케일을 조정하여 정확도를 높히는 코드가 잘 이해되지 않습니다. float64로 타입을 변환한게 스케일을 조정한 것인가요? 왜 이 경우 정확도가 높아질까요?
: 'int 시, 전체적인 데이터 다수가 0으로 수렴하는 문제'는 int 값으로 설정시 실수로 계산할 수 없기 때문에 생기는 문제를 말하는걸까요? 다시 생각해보니, 정수형에서 실수형으로 타입을 바꾸면 소수점까지 계산 가능하니, 더 정확한 계산이 가능하다고 이해해야겠다. -
154p.
np.random.randint(0, 100, (len(X_train), 784))에서 세번째 네번째 매개변수는 무엇인가요? randint(start, stop)의 경우 매개변수를 두개만 가지지 않나요?
: 내 눈이 삐었음. 파라미터 4개 아니고 3개임..
