정리
알고리즘의 원리, 개념
- 선형 판별식을 찾아서 0~1 사이로 변환
전제조건
- NaN 조치, 가변수화, feature들 간의 독립
성능
- 하이퍼파라미터 조절
- 변수 선택은?
원리
- 이진분류만 OK
로그 승산
Odds Ratio
- 그 사건이 일어날 가능성 대 사건이 일어나지 않을 가능성의 비
- 0~1 범위가 0~무한대가 됨
Log-odds
- 0~무한대가 -무한대~무한대가 됨
로지스틱 함수(시그모이드)
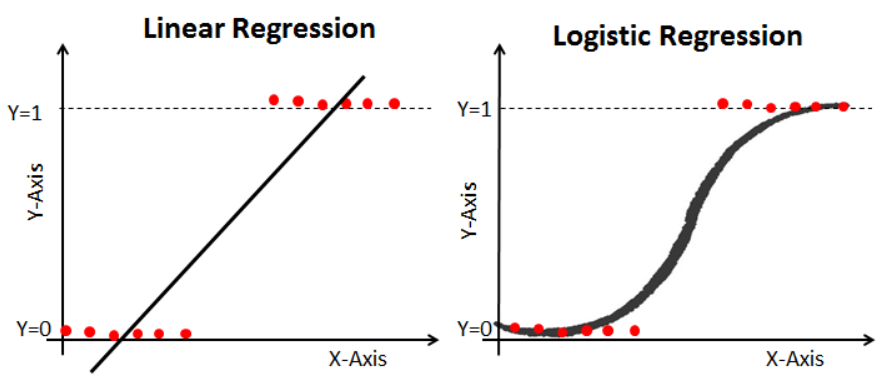
- 회귀식을 찾아서 0과 1 사이로 꺾은 듯한..
- 로그 승산 = = 선형 판별식
= w_0 + w_1x_1 + w_2x_2 + \cdots$

- 여기서 는 선형회귀, 선형판별식
회귀 계수 해석
- coefficient 음수 → ↓ → ↑ → ↑
- coefficient 양수 → ↑ → ↓ → ↓
모델링 절차
0. 데이터 준비
import numpy as np
import pandas as pd데이터 분할: x, y 나누기
target = '타겟명'
x = data.drop(target, axis = 1)
y = data.loc[:, target]NaN 조치
가변수화
데이터 분할: train, validation 나누기
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = .3, random_state = 2022)Scaling
1. 함수 불러오기
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression # 라이브러리.모듈.함수이름
from sklearn.metrics import *2. 선언(모델 설계)
model = LogisticRegression()3. 학습(모델링)
model.fit(x_train, y_train)4. 검증: 예측
pred = model.predict(x_val)5. 검증: 평가
confusion matrix
confusion_matrix(y_val, pred)classification report
print(classification_report(y_val, pred)) # print 필수- 예시:
precision recall f1-score support
0 0.87 0.98 0.92 300
1 0.67 0.24 0.35 59
accuracy 0.86 359
macro avg 0.77 0.61 0.63 359
weighted avg 0.83 0.86 0.83 359
# 정분류율
accuracy_score(y_val, pred)
# 정밀도
precision_score(y_val, pred, pos_label = 1) # pos_label: positive label의 약자. 기준 지정. default=1
# 재현율
recall_score(y_val, pred, pos_label = 1)
# f1 점수
f1_score(y_val, pred, pos_label = 1)
내 인생의 주연