Why Pandas?
: DataFrame을 사용하기 위해서!
DataFrame
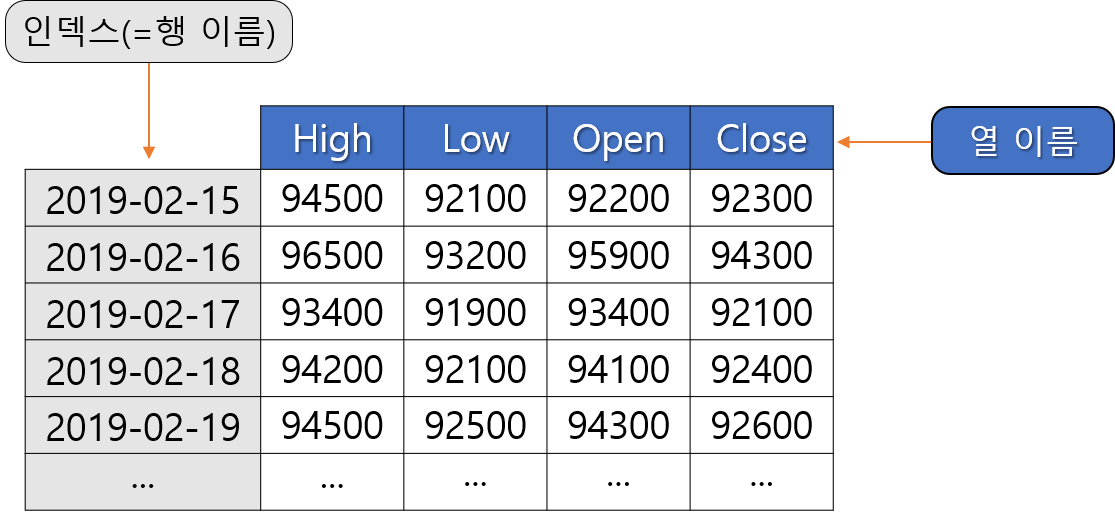 : 관계형 데이터베이스의 테이블 또는 엑셀 시트와 같은 형태로, 2차원 구조
- 행: 분석 단위, 관측치, 샘플
- 열: 정보, 변수
: 관계형 데이터베이스의 테이블 또는 엑셀 시트와 같은 형태로, 2차원 구조
- 행: 분석 단위, 관측치, 샘플
- 열: 정보, 변수
Series
: 데이터프레임에서 하나의 열을 떼어낸 형태로, 1차원 구조
: 하나의 정보에 대한 데이터들의 집합
기초 문법
데이터를 살펴보자
-
df.shape: 행과 열의 개수를 튜플로 반환. np.shape과 기능이 같을 뿐, 같은 함수는 아님 -
df.index: index 정보 확인 -
df.values: 값 확인. np.array 형태의 2차원 값으로 변환 -
df.columns: 열 이름 확인 -
df.dtypes: 열 정보 확인(열 이름, 각 열의 타입) -
df['열이름'].unique(): 열의 고유값을 볼 수 있음 -
df.value_counts(): 범주별 개수를 count해서 반환 -
df.columns.values.tolist(): dataframe의 열 이름을 list로 가져옴
`Score['Math'].value_counts()/Score.shape[0]`
# df.shape[0]: shape 함수의 결과값의 첫번째 인덱스, 즉 행의 개수. nan을 포함
# NAN 포함된 건수 비율
`Score['Math'].value_counts()/Score['Math'].count()`
# NAN 제외된 건수 비율
# count : nan은 빼고 카운트 함- 각 열의 고유값 개수 확인하기
df.columns_name = df.columns.values.tolist()
for i in df.columns_name:
print(i, len(df[i].unique()), sep=' ')df.info(): 행(인덱스) 개수, 열 개수, 열 이름, non-null 개수, 각 열의 타입df.describe(): 기초 통계량 확인- include='all' 하면, 문자인 애들은 nan으로 나옴
df.isna().sum()또는df.isnull().sum(): 결측치 세기
그 외
pd.DataFrame: 데이터프레임 만들기
import pandas as pd
a = {'Name' : ['James', 'Sujin'], 'Score': [90, 100], 'Sex': ['Male', 'Female']}
pd.DataFrame(a)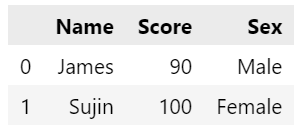
pd.read_csv()- sep: 데이터를 컬럼 단위로 구분을 해라, skipinitialspace: 데이터 행의 공백이 정렬이 되어 있지 않을때, 그 공백을 안 없애겠다
- 예: data = pd.read_csv('https://블라블라', sep = ',', skipinitialspace = True)
df.notnull(): null(na)가 아닌 값을 가져옴
df.sort_index(ascending = False): 인덱스를 기준으로 정렬df.sort_values(by = ['열 이름', '열 이름'], ascending = [False, True]): by 에 기준이 되는 열을 넣고, 이 열을 기준으로 정렬- 열 이름을 []로 하면 데이터프레임으로 출력
- ascending을 []로 열마다 다른 기준을 적용 가능
- ascending = True: 오름차순(기본값)
- ascending = False: 내림차순
DataFrame 조회
열 이름으로 조회
df['column명']: 1차원(시리즈)로 조회df[['column명']]: 2차원(데이터프레임)으로 조회. column 이름을 list로 입력한 것.
이건 지양하자!
df.colimn명: method처럼 보이므로, 지양하자
조건으로 조회
-
df.loc[행 조건, 열 이름].loc안 써도 가능은 하지만, 이왕이면 쓰자!a.loc[(a['Score'] > 50) & (a['Sex'] == 'male')]: 두 열의 특정 조건을 만족하는 행 조회a.loc[:, ['Score', 'Sex']]: 두 열에 해당하는 모든 행 조회df.loc[df['num_legs'] == 4, ['num_wings']]: 조건에 만족하는 열 하나 조회
-
df.iloc[행 인덱스, 열 넘버]: 데이터가 있는 위치(순서)로 접근 -
df.isin(): True/False로 반환 -
Series.between(left, right, inclusive='both'): left 부터 right까지 범위안의 데이터를 조회- 예:
a.loc[data['Age'].between(25, 30)] - inclusive{“both”, “neither”, “left”, “right”}: 포함관계를 설정
- 예:
loc vs iloc 차이점
a.loc[:9, ['Name', 'Age', 'Sex']]`
# 0:9 면.. 파이썬 슬라이싱에서는 9 전까지지만, 여기서는 9를 포함함!
# 9가 인덱스이기도 하지만 행의 이름이기도 해서.. ㅠ
a.iloc[:10, [0, 11, 12]]`
# :10 면, loc와는 다르게, 10을 포함하지 않음!
# 슬라이싱으로 접근하기 때문에(즉, 데이터 순서로)열 이름으로 조회 vs loc로 조회 vs iloc로 조회
# 시리즈로 출력
boston['crim']
boston.loc[:, 'crim']
boston.iloc[:, 0]
# 단, boston.crim 은 method 같아 보이니까 지양하자
# 데이터프레임으로 출력
boston[['crim']]
boston.loc[:, ['crim']]
boston.iloc[:, [0]]
loc[]와 isin()을 활용해보자
df = pd.DataFrame({'num_legs': [2, 4], 'num_wings': [2, 0]}, index=['falcon', 'dog'])
df
# 출력
num_legs num_wings
falcon 2 2
dog 4 0
# 입력
df.isin([0, 2]) # df를 0, 2에 해당하는걸 True/False로 나타내줘
# 두 열에 해당하는 값을 df에서 찾은 다음 > 0, 2에 해당하하는걸 True/False로 나타내줘
df.loc[:, ['num_legs', 'num_wings']].isin([0,2])
df[['num_legs', 'num_wings']].isin([0,2])
# 출력: True/False로 나옴
num_legs num_wings
falcon True True
dog False True
# 입력
# 두 열에서 0, 2에 해당하는 값을 True/False로 나타낸 다음 > df에서 찾아줘
df[df[['num_legs', 'num_wings']].isin([0,2])]
# 출력: 값으로 나옴
num_legs num_wings
falcon 2.0 2
dog NaN 0
# 에러남: df.loc[df[['num_legs', 'num_wings']].isin([0,2])]
# 입력
df.loc[df['num_legs'].isin([0, 4])]
# 출력
num_legs num_wings
dog 4 0참고
# 조건이 되는 age를 잘라
data.loc[data['MonthlyIncome'] >= 10000, ['Age']]
# 일단 다 불러온 다음에 그 다음에 age를 잘라
data.loc[data['MonthlyIncome'] >= 10000][['Age']]
# data.loc[data['MonthlyIncome'] >= 10000]가 하나의 데이터 프레임인것.
# 여기서 [['Age']]을 잘라와(데이터 프레임으로)
data.loc[data['MonthlyIncome'] >= 10000]['Age'] # 이건 시리즈로 불러와집계 메소드
df['열 이름'].unique(): 열의 고유값 확인. ndarray 형태로 반환- unique()는 시리즈 형태로만 함수 적용이 가능함.
df.value_counts(dropna = True): 고유값과 개수 화인. Series 형태로 반환- dropna = True: NaN 값 제외
df.sum(),df.max(),df.min(),df.mean(),df.median(),df.count()
그룹으로 묶어보자
-
df.groupby(by = ['Score', 'Sex'], as_index = True): by에 지정된 열로 묶음-
이때, 뒤에 mean()이나 sum()과 같은 함수를 안 붙이면, 아무것도 출력되지 않음
-
만약, '점수'별 '성별'의 '평균'을 알고 싶다면?
:df.groupby(by = 'Score')['Sex'].mean(): 시리즈로 출력 -
as_index = True: 집계 기준이 되는 열이 인덱스 열이 됨. default
-
as_index = False: 행 번호를 기반으로 한 정수값이 인덱스가 됨.
: 실무에서 더 많이 쓰임
: 집계기준이 하나의 열이 되기 때문에, 최소 열이 두개 이상이 되어서 데이터프레임으로 반환됨. -
만약, [['Sex']]로 했다면, 데이터프레임으로 출력
-
df.groupby(['sex', 'pclass'])['survived'].mean().reset_index()- reset_index(): 그룹핑된 데이터프레임의 index를 초기화하여 새로운 데이터프레임을 생성
-
df.groupby(['sex', 'pclass'])[['survived', 'age']].mean(): 다중 칼럼
-
-
df.agg(['함수1', '함수2'..]): 함수들을 list안에 ''로 묶어서 넣음. 함수들 적용df.groupby(by = 'Score', as_index = False)['Sex'].agg(['mean', 'sum']): ['Sex']로 해도 함수가 두개기 때문에 데이터프레임으로 반환.df.groupby(by = 'Score', as_index = False)['Sex'].agg({'Age': 'mean', 'Time': 'sum'}): dict으로 지정 가능
DataFrame 변경
열 이름 변경, 추가, 삽입, 삭제
-
df.columns = ['Grade', 'Sex_male', 'Study_time']: 모든 열 이름 변경 -
df.raname(columns = {'Score': 'Grade', 'Time': 'Study_time'}): 원하는 열만 이름 변경 -
df['Money'] = df['Income'] - df['Spend']: 열 추가 -
df.insert(1, 'Money', df['Income'] - df['Spend']): 원하는 위치에 열 삽입. 그러나.. 실무에서는 열의 위치는 크게 중요하지 않다. -
df.drop(['Score' 'Sex'], axis = 1, inplace = True): 열 삭제- axis = 0: 행 삭제. default
- axis = 1: 열 삭제
- inplace = True: 진짜로 삭제해줘
- inplace = False: 삭제한 것처럼 보여줘. 원본에는 영향이 가지 않음.
cat_cols = ['Gender','JobSatisfaction','MaritalStatus','OverTime']
x = pd.get_dummies(x, columns = cat_cols, drop_first = True)
df['Sex'] = df['Sex'].map({'male': 1, 'female': 2}): 범주형 값을 다른 값으로 변경. 변수에 저장 해줘야함.pd.cut(): 값 크기를 지정한 개수의 범위로 나누어서 범주값 지정data['Income_Group'] = pd.cut(data['Income'], 4, labels=list('abcd') ): 4등분
결합하기
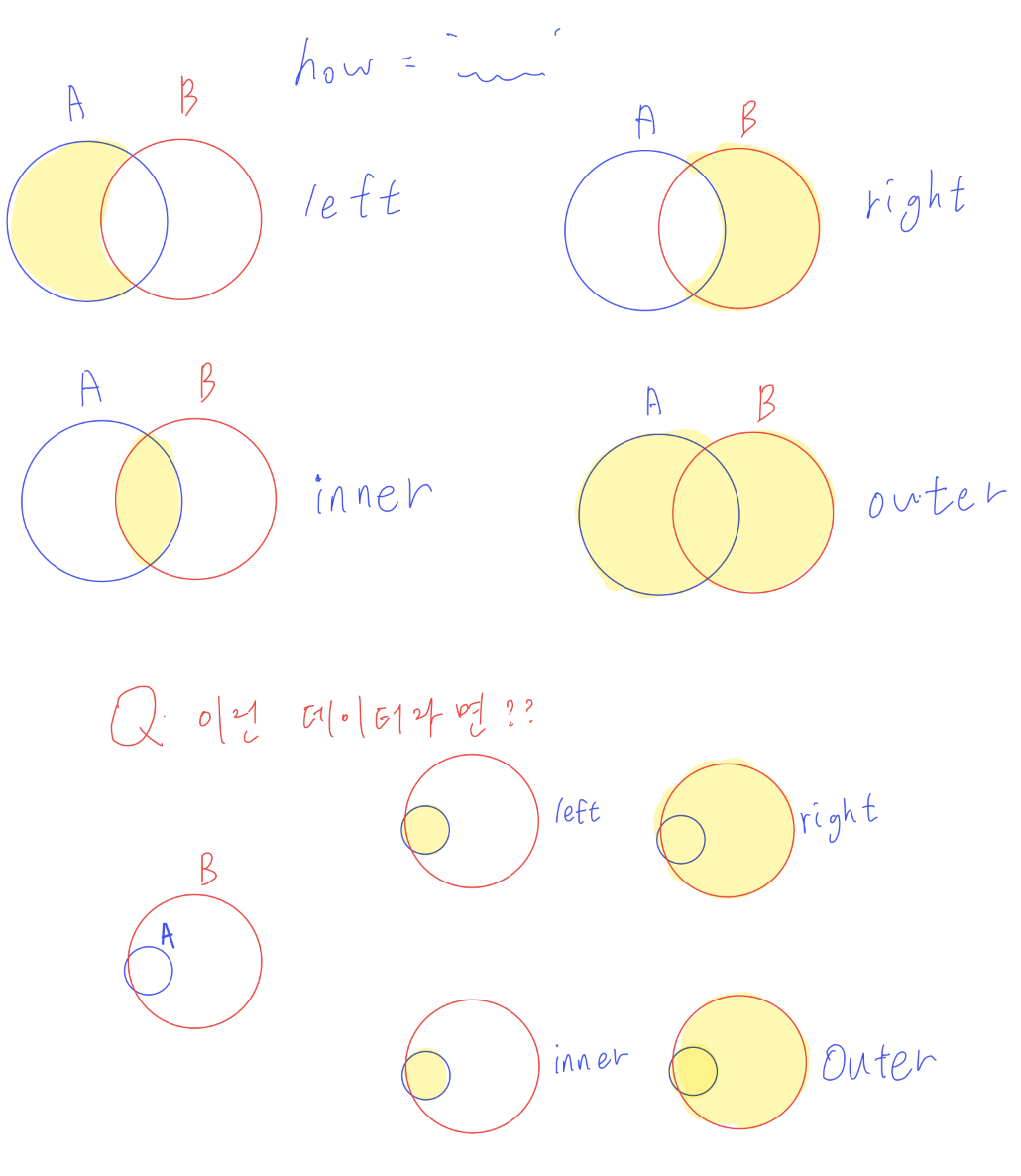
pd.merge(df1, df2, how = '방법', on = '열 이름'): 두 데이터 프레임을 j병합. 데이터프에임 사이에 겹치는 열이 있어야함!!!df1.merge(df2, how = '방법', on = '열 이름')도 가능- how: 기준이 되는 df. left, right: 왼쪽, 오른쪽 기준. inner, outer: 교집합, 합집합. inner가 default.
- on: 기준이 되는 열 이름
- 꿀팁: NaN이 존재하면, 그 열은 float64형이 된다!
pd.concat([df1, df2], axis = 0): 단순 합치기. 그냥 가져다 붙임.- 합칠 df을 list 형태로 넣어야 한다.
- axis = 0: 위 아래로 붙이기, 1: 옆으로 붙이기
행, 열 추가: 주로 시계열 데이터에서 이동평균 계산
df['new_column'] = df['column1'].rolling(n, min_periods = m).함수(): new_column을 추가하여 column1의 n개 데이터에 함수를 적용한 값을 넣는데, 이때 최소 m개 데이터이어도 적용해라.- 시계열 데이터나 행을 이동할 때 주로 사용.
- 0 < new_column < 윈도우 사이즈(n)
- 기준행 포함
- n - 1개 만큼 NaN이 생김
df['new_column'] = df['column1'].shift(n): n칸 만큼 민다.- n < 0이라면, 위로 민다.
# 1. 열을 추가하여 mean을 해서 rolling 해라
# 2행부터 시작. 기준일 포함. NaN: 2개
stock['Close_rolling'] = stock['Close'].rolling(3).mean()
# 2.열을 추가하여, mean을 해서 rolling 하는데, 1칸 아래로 shift 해라
# 3행부터 시작. 기준일 포함하지 않은 꼴이 됨. NaN: 3개
stock['Close_rolling_shift'] = stock['Close'].rolling(3).mean().shift()
# 3. 열을 추가하여 mean을 해서 rolling 하는데, 최소 1개 행이어도 적용해라
# 0행부터 시작. 기준일 포함. NaN: 0개
stock['Close_rolling_min'] = stock['Close'].rolling(3, min_periods=1).mean()
# 4. 열을 추가하여 mean을 해서 rolling 하는데, 최소 1개 행이어도 적용하고, 1칸 아래로 shift 해라
# 1행부터 시작. 기준일 포함하지 않은 꼴이 됨. NaN: 1개
stock['Close_rolling_min_shift'] = stock['Close'].rolling(3, min_periods=1).mean().shift()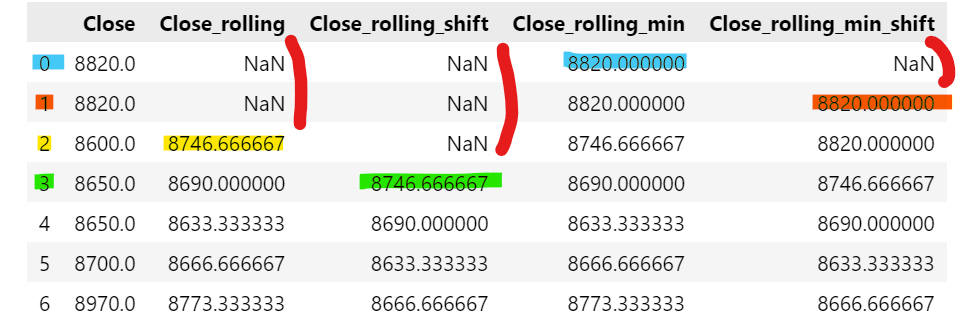
범주형 볌수 교차표 만들기
pd.crosstab(df['column1'], df['column2'], normalize = False): 범주형 변수일 때, 교차표를 만들어줌- 순서대로 행, 열로 만듦
- normalize: 비율로 나타냄. 기본은 False.
- 'columns': 열끼리. 즉 각 열마다 비율 100%로, 아래 방향
- 'index': 해끼리. 즉 각 행마다 비율 100%, 옆 방향
- 'all': 행열 모두. 즉 모두 합쳐야 비율 100%.
날짜, 시간
df['date'] = pd.to_datetime(df['date']): 시간을 다루는 자료형으로 변환- df['date']의 type: datetime
df['date'].dt.date: YYYY-MM-DD 형태로(str)df['date'].dt.year: 연(4자리)df['date'].dt.month: 월(숫자)df['date'].dt.weekday: 각 요일을 숫자로. 월=1, 화=2,...
시각화
df.plot(kind = 'kde'): 밀도함수 그래프 시각화.df.plot.bar(stacked = True): 100% stacked bar chart- 비율만 비교
- crosstab 할 때, x y 순서 꼭 지켜야한다.
temp = pd.crosstab(data['열이름1'], data['열이름2'], normalize = 'index')
temp.plot.bar(stacked=True)
plt.show()
통계 분석
df.corr(): 데이터프레임으로부터 수치형 데이터에 대한 상관계수 구하기
그외
df.diff(n): n칸 차이나는 데이터 간의 차이 구하기.- 예:
data['diff1'] = data['sales'].diff()
= `data['sales'] - data['sales'].shift(1)
: 1칸 차이나는 행끼리 차이. NaN: 1칸
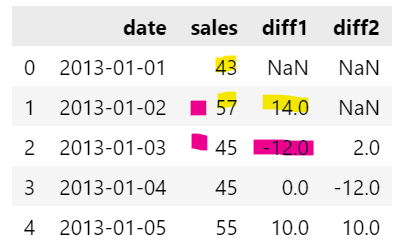
- 예:
data['diff2'] = data['sales'].diff(2)
=data['sales'] - data['sales'].shift(2)
: 2칸 차이나는 행끼리 차이. NaN: 2칸
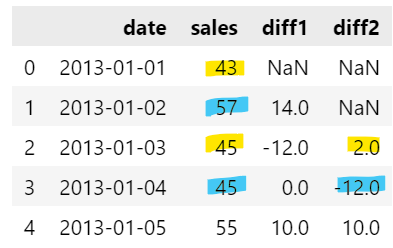
- 예:
tip
- OrderDate가 object형인데 어떻게 표현할 것인가?!
- 문자열인데 크기 비교가 되는 것인가?! YES! pandas의 좋은 기능 중 하나임~
