-
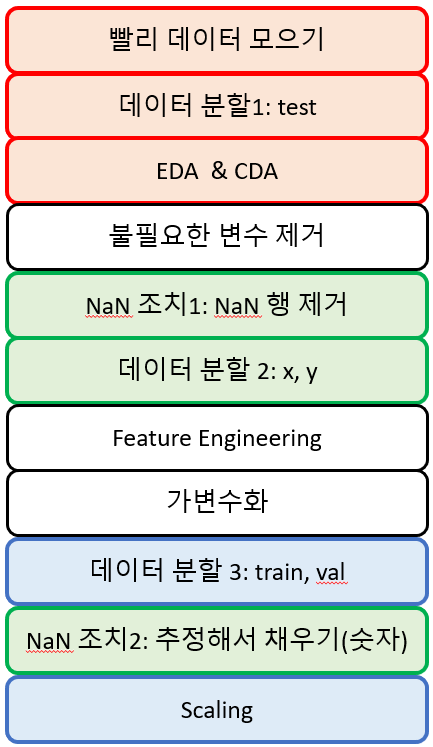
각 색깔별로는 절대로 바뀌어서는 안되는 고정된 순서이다. 그 사이에 다른 것이 끼어들 수는 있지만, 색깔안에서의 순서는 고정!
-
EDA, CDA는 test를 떼어낸 train과 val 세트로 진행한다.
-
불필요한 변수 제거: 만약 feature engineering으로 날짜요소뽑고 원래데이터는 삭제면, feature engineering 다음에 불필요한 변수 삭제가 올 수 있다.
-
feature engineering을 어떻게 하느냐에 따라 달라질 수 있다.
-
가변수화는 범주형을 숫자형으로 바꾸는거니까, 빈값이 없도록 한 다음에 하는게 맞다.
- x, y로 분할한 다음에 x에 대해서만 가변수화를 하면 된다. 아물론 y가 가변수화 대상일 수도 있..나?
-
NaN 조치는 삭제만 있는게 아니라, 추정해서 채워넣는 것도 존재. 이 경우 y가 빠져있어야해서, x와 y를 분할한 다음에 해야한다.
-
NaN 제거를 xy 분할 전에 해야하는 이유
- 열은 상관 없음.
- 행을 제거하면 x와 y가 데이터 개수가 달라지기 때문에.
-
스케일링은 다 채우고 다 준비한 다음에 옵션으로 필요에 따라서 값의 범위를 일치시켜줘야한다면 수행하는 것이다.
-
스케일링 기준: train 셋 기준으로 범위를 정의. 그래서 train과 val 구분 다음에 하는게 일반적이다.
-
이 전체 과정을 test에 대해서도 조치해야하나? 이건 11월 말 ai 서비스 파이프라인?때 답변

내 인생의 주연