딥러닝에서 가장 많이 사용되는 프레임워크: Tensorflow, Keras, Pytorch
-
프레임워크란?
응용 프로그램 개발을 위해 여러 라이브러리나 모듈을 효율적으로 사용할 수 있도록 하나로 묶어 놓은 것 -
Tensorflow
2015년 구글이 개발한 딥러닝 프레임워크
Python, C++, R을 지원
데이터 플로우 그래프(Data Flow Graph)구조를 사용하는 특징
데이터 플로우 그래프
데이터 플로우 그래프는 수학 연산(계산식)과 데이터의 흐름을 시각적으로 표현하는 방식이야.
쉽게 말해, 연산(Operations)은 노드(Node), 데이터(텐서, Tensor)는 엣지(Edge, 연결선)로 표현돼.
Node(노드)와 Edge(엣지)로 구성되어있는 것을 우리는 Graph(그래프)라 한다.
데이터 플로우 그래프의 기본 개념
노드(Node): 연산(예: 덧셈, 행렬 곱셈, 활성화 함수 등)을 수행하는 단위
엣지(Edge, 연결선): 노드 사이를 연결하며, 데이터를 전달하는 역할 (텐서, Tensor)
방향 그래프(Directed Graph): 데이터가 한 방향으로 흐름
Data Flow Graph에서는 Node를 하나의 Operation이라 부를 수 있고, Edge는 Data(=Tensor)라 부를 수 있다.
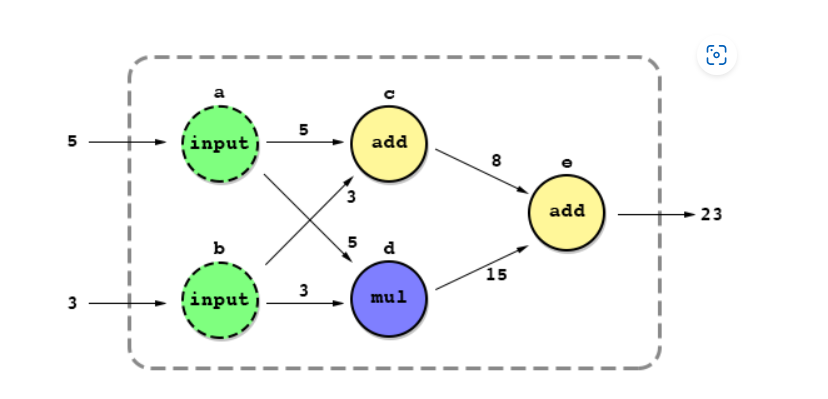
위의 그림에서 보다시피 동그라미 a, b, c, d, e는 Node, 즉 Operation을 나타내고 Edge는 Data를 나타내어 원하는 결괏값을 출력하고 있는 과정을 볼 수 있다.
이로 인해, 텐서보드라는 시각화 도구를 이용해 그래프 실행 방법에 대한 검사나 프로파일링도 가능
TensorBoard를 사용하면 딥러닝 모델의 구조와 연산 흐름을 직관적으로 확인할 수 있어.
TensorBoard를 실행하면 딥러닝 모델의 구조 및 그래프 실행 과정을 볼 수 있어!
그래프의 각 노드와 엣지가 시각적으로 표시되므로 모델을 디버깅하거나 최적화할 때 유용함.
TensorFlow 1.x에서는 이 방식을 엄격하게 사용했어.
즉, 연산을 미리 정의(Define) 해놓고, 나중에 값을 전달하여 실행하는 방식이었지. (Define and Run 방식)
Define and Run 방식
그래프를 미리 만들어 두고, 연산을 할 때 값을 전달하는 방식
코드를 실행하는 세션을 만들고 placeholder 라는 것을 선언한 후 이것을 계산 그래프 형태로 만듦
그 다음 코드를 실행할 때 데이터를 넣어서 실행하는 방법
그렇기 때문에 실행시점에 동적으로 변경이 불가능
Define by Run 방식
Define and Run 방식과 반대되는 개념
실행시점에 동적으로 변경이 가능
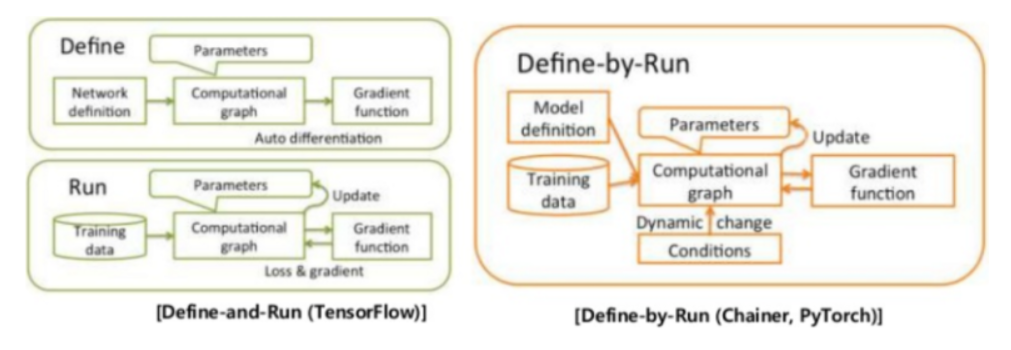
TensorFlow 2.x에서는 자동으로 실행
TensorFlow 2.x에서는 Define by Run 방식을 지원해서 즉시 실행(Eager Execution)이 가능해짐.
import tensorflow as tf
# 즉시 실행 모드 (TF 2.x에서는 기본적으로 활성화됨)
x = tf.constant(3.0)
y = tf.constant(2.0)
w = tf.constant(4.0)
z = (x + y) * w # 자동 실행
print(z.numpy()) # 20.0
여기서는 세션을 만들 필요 없이, 변수 x, y, w에 값을 할당하면 즉시 실행됨!
-
Keras
구글에서 개발된 프레임워크
Tensorflow의 사용 난이도 문제를 해결하고자 등장
Tensorflow 기반으로 설계되었음
사용하기 편하기 때문에 레이어를 쉽게 순차적으로 쌓을 수 있고, Keras 함수 API를 이용하여 복잡한 모델도 쉽게 구현 가능
Define by Run 방식으로 동작 -
Pytorch
페이스북에서 개발된 프레임워크
Torch 라는 머신러닝 라이브러리에 바탕을 두고 만들어짐
Tensorflow와 다르게 간단하고 생성된 계산 그래프가 동적으로 변할 수 있음
코드가 Python 과 유사
그래프를 만들면서 동시에 값을 할당하는 Define by Run 방식이기 때문에 코드를 깔끔하게 작성 가능
메모리 연산과 동시에 신경망 사이즈를 최적으로 바꾸면서 동작할 수 있음
동적 계산 그래프(dynamic computational graph): 파이토치는 계산 그래프를 동적으로 생성한다. 이는 코드 실행 중에 그래프가 생성된다는 의미이며 정적 계산 그래프보다 디버깅과 실험이 용이하다는 장점이 있다.
계산 그래프
계산 그래프(computation graph)는 그래프(자료구조)의 일종으로 수학적 표현을 노드와 간선으로 나타낸 그래프이다. 머신러닝 및 딥러닝 모델의 연산 과정을 시각적으로 이해하고 효율적으로 계산하기 위해 계산 그래프가 사용된다.
파이토치는 동적 계산 그래프를 사용하여 코드 실행 중에 그래프가 생성되고 변경될 수 있다. 이는 디버깅과 실험을 용이하게 한다.
텐서플로우는 기본적으로 컴파일 타임에 한 번 정의하고 이후 실행하는 정적 계산 그래프(static computational graph)를 사용하지만 최근 버전에서는 동적 계산 그래프도 지원하고 있다. 정적 그래프는 모델 최적화와 배포에 유리하다.
사용자 인터페이스
파이토치는 파이썬에 익숙한 사용자에게 직관적이고 사용하기 쉽다. 파이써닉한 문법을 제공하여 코딩과 디버깅이 간편하다.
텐서플로우는 과거 버전 1.x에선 다소 복잡하고 직관적이지 않은 인터페이스로 인해 사용자들이 어려움을 겪었지만, 버전 2.x부터는 비교적 쉬운 케라스(Keras) 인터페이스를 기본으로 채택하여 사용자 친화적으로 개선되었으며 파이토치와 매우 비슷한 방식으로 코딩할 수 있게 되었다.
성능 및 최적화
파이토치는 동적 그래프 덕분에 디버깅이 쉽고, 실험적인 모델링에 적합하지만, 일부 상황에서는 정적 그래프보다 최적화가 불리할 수 있다.
텐서플로우는 정적 그래프 방식으로 컴파일 타임 최적화를 통해 더 높은 성능을 제공할 수 있으며, 배포를 위한 TensorFlow Lite, TensorFlow Serving과 같은 도구를 제공하다.
파이토치의 대략적인 작업흐름(workflow)
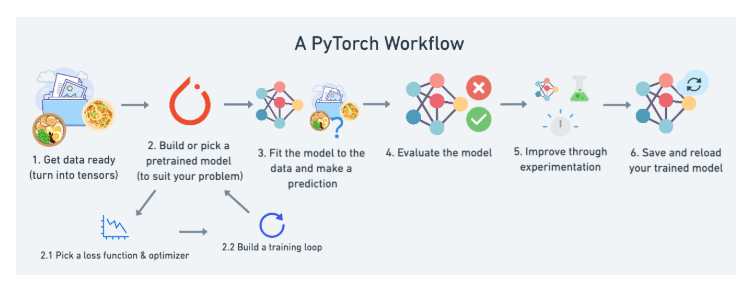
- 데이터 준비: 데이터를 모으고, 텐서(tensor)로 변환하기
모델을 만들고 학습시키는 것도 중요하지만 그전에 먼저 학습 데이터를 준비하고 텐서로 변환해야 한다. 보통 머신러닝에서는 학습할 데이터를 텐서 형태로 변환하여 사용하기 때문이다. 텐서란 스칼라, 벡터, 행렬 등을 일반화한 개념으로, 0차 텐서는 스칼라, 1차 텐서는 벡터, 2차 텐서는 행렬, 3차 이상은 다차원 배열과 같다고 볼 수 있다. 머신러닝에선 음성, 이미지, 텍스트 같은 데이터도 결국 텐서로 변환되어 학습된다. 일반적으로 텐서는 배열과 비슷하게 동일한 자료형의 데이터를 저장하며 물리적으로 연속적인 기억공간을 할당받아 연산의 효율성이 좋고 GPU 같은 효율적인 디바이스에 할당될 수 있다.
파이토치와 텐서플로우의 기본 자료형 역시 텐서이며 텐서의 연산 방식과 코딩은 넘파이 배열과 매우 비슷하다. 또한 넘파이 배열을 텐서로 변환하거나 텐서를 넘파이 배열로 변환하여 사용할 수 있다. 파이토치에서 텐서는 입력 데이터, 모델 파라미터, 계산 수행, 중간 결과 저장 등 다용도로 활용된다.
모델 학습과 추론 연산의 대부분 텐서 간의 연산이며 텐서들의 크기(shape)가 일치하지 않으면 오류를 일으키기 때문에 항상 텐서의 크기를 고려하여 모델의 레이어를 설계해야 한다. 또한 텐서 연산을 담당하는 디바이스가 서로 다르면 연산이 되지 않고 오류를 일으키므로 항상 현재에 사용 가능한 디바이스에 텐서가 할당되어 디바이스를 일치시켜주는 것이 좋다.
- 텐서(Tensor)란?
딥러닝에서는 데이터를 숫자로 표현하고, 이를 배열(Array) 형태로 다룸.
이때, NumPy의 ndarray와 비슷한 구조를 가진 텐서(Tensor)를 사용해.
스칼라(Scalar) → 0D 텐서 (ex: 3.14)
벡터(Vector) → 1D 텐서 (ex: [1.0, 2.0, 3.0])
행렬(Matrix) → 2D 텐서 (ex: [[1, 2], [3, 4]])
다차원 텐서 → 3D 이상 (ex: [[[1,2], [3,4]], [[5,6], [7,8]]])
즉, 딥러닝에서 모델을 학습하거나 추론할 때, 모든 입력과 출력을 텐서 형태로 변환해서 처리해.
- 텐서의 크기(Shape)가 중요한 이유
텐서 연산에서 크기가 일치하지 않으면 오류가 발생해!
모델을 설계할 때 입력 텐서와 출력 텐서의 크기를 항상 고려해야 해.
🔹 예제 1: 텐서 크기가 일치하는 경우
import torch
a = torch.tensor([1, 2, 3]) # (3,) 크기의 텐서
b = torch.tensor([4, 5, 6]) # (3,) 크기의 텐서
c = a + b # 크기가 동일하므로 정상 연산
print(c) # tensor([5, 7, 9])✅ 문제 없음 → a와 b의 크기가 (3,)으로 동일하므로 연산 가능
🔹 예제 2: 텐서 크기가 일치하지 않는 경우
import torch
a = torch.tensor([1, 2, 3]) # (3,) 크기의 텐서
b = torch.tensor([[4, 5, 6], # (2, 3) 크기의 텐서
[7, 8, 9]])
c = a + b # 오류 발생❌ 오류 발생 → (3,)와 (2,3)은 크기가 다르므로 연산 불가능!
올바른 크기(Shape)로 변환하는 방법
모델 설계 시 크기를 맞추는 방법:
reshape() 또는 view()를 사용해 크기 변환
Broadcasting을 활용해 연산 가능하도록 조정
텐서 연산을 담당하는 디바이스(Device)
텐서 연산을 실행하는 장치는 CPU와 GPU가 있음.
torch.Tensor()로 생성된 텐서는 기본적으로 CPU에서 연산됨.
cuda()를 사용하면 GPU에서 연산 가능.
디바이스가 다르면 오류 발생
❌ 오류 발생 → CPU 텐서와 GPU 텐서는 서로 연산할 수 없음.
파이토치에서 지원하는 디바이스 종류로는 cpu를 이용하는 'cpu'와 엔비디아의 병렬 컴퓨팅 플랫폼 CUDA를 이용하는 'cuda'가 있으며, CUDA GPU가 여러 개 있는 경우 'cuda:3'같은 방식으로 특정 디바이스를 지정할 수도 있다.
파이토치 객체의 to(device) 메서드를 통해 디바이스를 할당할 수 있으며, 디바이스를 지정하지 않으면 기본적으로 CPU로 지정된다. 텐서의 경우 .cpu()나 .cuda() 같은 메서드로 할당된 디바이스를 변경할 수 있다.
파이토치와는 다르게 matplotlib나 numpy 같은 라이브러리는 CPU에 할당된 텐서만 불러올 수 있으므로 이러한 라이브러리를 사용할 때는 디바이스를 적절하게 지정해줘야 한다.
또한 파이토치는 데이터를 처리하는 작업을 위한 Dataset과 DataLoader라는 기능을 제공한다. 이들은 데이터 불러오기, 변환, 배치 처리 등과 같은 작업을 쉽게 수행할 수 있도록 도와준다.
- 모델을 정의하거나 사전 학습된 모델 선택
학습 데이터가 준비됐다면 모델을 정의하거나 사전에 학습된(pre-trained) 모델을 선택한다. 파이토치에서 모델을 정의할 때는 대개 torch.nn.Module을 상속받은 클래스를 사용하지만, 간단히 만드는 모델은 torch.nn.Sequential만 사용할수도 있다.
파이토치에서 제공하는 사전 학습된 모델들은 해당 도메인 패키지들(torchvision, torchaudio, torchrec 등)에서 제공하고 있으며 모델의 크기나 정확도, 파라미터의 개수 등의 정보가 공개되어 있으므로 문제에 적합한 것을 선택하여 이용하면 된다.
파이토치의 nn.Module 클래스를 상속받아 모델을 정의하면 모델을 유연하게 구성할 수 있으며 코드 가독성도 좋아 복잡한 모델을 정의할 때 좋다. 단 nn.Module 클래스를 상속받은 모델은 forward()라는 메서드를 반드시 오버라이딩해야 하며 생성자 안에서 super().init()으로 부모 객체를 초기화해야 한다.
일반적으로 생성자 init()에선 모델의 전체적인 구조를 정의하고, forward()는 입력 데이터를 받아서 원하는 출력으로 변환하는 과정을 수행한다. nn.Module을 이용하여 모델을 구성하는 예시 코드는 다음과 같다.
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.weights = nn.Parameter(torch.randn(1, requires_grad=True, dtype=torch.float))
self.bias = nn.Parameter(torch.randn(1, requires_grad=True, dtype=torch.float))
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.weights * x + self.bias위의 코드는 기본 파라미터 모듈nn.Parameter을 사용하여 구성한 것이며 하나의 입력 텐서을 받아 가중치를 곱하고 편향을 더해서 하나의 텐서로 출력하는 모델이다. 선형변환 모듈 nn.Linear을 사용하면 다음과 같이 더 간단하게 만들 수 있다.
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.linear(x)nn.Sequential은 인수로 받은 모듈들을 순서대로 실행하고 결과를 반환한다. 활성 함수 등 다양한 신경망 유닛이 중첩되어 신경망이 깊어지고 복잡해질수록 이 모듈을 사용하는 것이 편리하다.
# torch.nn.Sequential만 사용하여 만든 간단한 모델
simple_model = nn.Sequential(
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
# 클래스 내부에서 nn.Sequential() 사용
class LinearReLUModel(nn.Module):
def __init__(self):
super().__init__()
self.layer_1 = nn.Sequential(
nn.Linear(100, 50),
nn.ReLU(),
nn.Linear(50, 30),
nn.ReLU(),
...
)
self.layer_2 = nn.Sequential(
...
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.layer_1(x)
x = self.layer_2(x)
...
return x✅ 1. nn.Module 상속 방식 vs. nn.Sequential 방식
nn.Module 상속
모델 구조를 유연하게 정의 가능, 코드 가독성 증가, 복잡한 모델에 적합
복잡한 모델 설계 (예: ResNet, Transformer 등)
조건문, 여러 입력, 여러 출력이 필요한 경우
유연한 구조를 만들 수 있음
✅ 모델 내부에서 여러 개의 입력, 추가 연산 등을 정의 가능
❌ 코드가 길어질 수 있음
다른 서브 모듈들과 결합해야 하는 경우
추천 사용 사례
RNN, Transformer, Custom Model
nn.Sequential
짧고 간결한 코드, 순차적인 구조라 직관적
복잡한 연산(병렬 구조 등) 구현 불가
단순한 피드포워드 신경망 (MLP, CNN)
- 손실 함수(loss function 또는 criterion)와 옵티마이저(optimizer) 정의
손실 함수는 모델이 예측한 값과 실제 값 사이의 차이를 측정하는 함수이며, 옵티마이저는 모델을 최적화하는 데 필요한 알고리즘을 의미한다. 손실함수와 옵티마이저는 모델의 매개변수 값들을 최적화하기 위해 사용된다. 딥러닝의 핵심 기법인 경사하강법(gradient descent)과 역전파(backpropagation)을 활용하려면 모델을 위한 손실 함수와 옵티마이저를 정의해야 한다.
- 손실 함수(loss function 또는 criterion)와 옵티마이저(optimizer) 정의
손실 함수와 옵티마이저를 직접 만들 수도 있지만 학습에 주로 사용되는 종류들은 대부분 이미 파이토치에 구현돼있기 때문에 문제에 적합한 것을 찾아 사용할 수 있다. 파이토치에서 제공하는 손실 함수들은 torch.nn에 있고, 옵티마이저들은 torch.optim에 있다.
여기서는 간단한 회귀문제를 다루므로 손실 함수는 L1Loss와 기본적인 확률적 경사하강법(stochastic gradient descent, SGD) 옵티마이저를 사용한다.
분류 모델의 경우 일반적으로 모델이 예측한 값에 대한 오차를 계산하는 정확도 평가함수를 만들지만, 여기서는 회귀 문제 모델만 다루므로 필요없다.
loss_fn = nn.L1Loss() # L1 손실함수(평균 절대 오차, MAE)
optimizer = torch.optim.SGD(params=model_0.parameters(), lr=0.01) # 확률적 경사하강법 옵티마이저- 훈련과 테스트 루프 작성
파이토치에서 모델을 훈련시키는 코드는 일반적으로 에포크(epoch)를 정하고, 정한 에포크만큼 반복하는 방식으로 작성한다. 에포크란 전체 학습 데이터셋을 모델이 한 번 학습하는 것을 의미한다. 모델을 훈련시키기 전에 모델의 train() 메서드로 모델을 훈련 모드로 바꿔줘야 하고, 모델을 평가할 때는 모델의 eval()과 with torch.inference_mode():으로 모델의 그래디언트 추적을 해제하여 평가 모드로 전환해줘야 한다. 또한 역전파를 위해서 손실함수와 옵티마이저에서 특정 메서드를 실행해야 한다. 이를 정리한 코드는 다음과 같다.
- 훈련과 테스트 루프 작성
optimizer.zero_grad()를 호출하는 이유
딥러닝에서 optimizer.zero_grad()를 실행하는 이유는 역전파(Backpropagation) 시 그래디언트(Gradient)가 누적되는 것을 방지하기 위해서야.
그래디언트(Gradient)란?
신경망을 학습할 때, 손실 함수(loss)를 줄이기 위해 역전파(Backpropagation) 를 수행함.
역전파는 각 가중치(Weight)와 편향(Bias)에 대한 손실 함수의 기울기(Gradient, 미분 값)를 계산하는 과정이야.
이 그래디언트 값은 optimizer.step()을 호출하면 가중치를 업데이트하는 데 사용됨.
그래디언트가 누적되는 문제
PyTorch에서는 기본적으로 그래디언트가 자동으로 누적되는 방식이야.
즉, loss.backward()를 여러 번 호출하면, 이전에 계산된 그래디언트 값들이 계속 더해져서 누적됨.
zero_grad()를 호출하지 않으면, 이전 학습에서 계산된 그래디언트가 누적됨!
즉, 새로운 미분값이 기존 값과 합쳐져서 잘못된 업데이트가 일어날 수 있음.
역전파를 수행하기 전에 optimizer.zero_grad()를 호출하면 이전 그래디언트를 초기화할 수 있음.
PyTorch와 TensorFlow의 차이
PyTorch에서는 loss.backward()를 호출하면 그래디언트가 누적되므로 수동으로 optimizer.zero_grad()를 호출해야 함.
반면 TensorFlow/Keras에서는 기본적으로 그래디언트가 자동 초기화되므로 별도로 zero_grad() 같은 작업을 할 필요가 없음.
PyTorch에서 zero_grad()가 필요한 이유
PyTorch는 동적 계산 그래프 방식(Define by Run)이므로, loss.backward()를 여러 번 호출하면 그래디언트가 누적됨.
TensorFlow/Keras에서 zero_grad()가 필요 없는 이유
TensorFlow/Keras에서는 매번 fit()을 호출할 때 자동으로 그래디언트를 초기화하기 때문에 zero_grad()가 필요 없음.
torch.manual_seed(42)
model_0 = LinearRegressionModel() # 모델 인스턴스 생성
epochs = 200 # 훈련의 반복 횟수, 에포크는 또한 모델의 하이퍼파라미터임
epoch_count = []
loss_values = []
test_loss_values = []
for epoch in range(1, epochs + 1):
model_0.train() # 모델의 train()으로 모델을 훈련 모드로 전환
# 모델 신경망의 전방향 진행(forward pass)
y_pred = model_0(X_train) # X_train에 대해 모델의 forward() 메서드가 실행되어 예측값들이 계산됨
loss = loss_fn(y_pred, y_train) # 예측값과 실제값을 비교하여 손실 함수값들이 계산됨
# print("Loss: ", loss)
optimizer.zero_grad() # 역전파를 수행하기 전에 반드시 그래디언트 값들을 0으로 초기화 해줘야 함
loss.backward() # 손실함수의 역전파 수행, requires_grad=True인 모든 파라미터에 대해 계산함
optimizer.step() # 위의 backward()로 계산된 그래디언트로 경사하강 수행(파라미터 값들을 업데이트)
# 모델의 eval()로 모델을 테스트 모드로 전환
model_0.eval()
with torch.inference_mode(): # inference_mode()은 모델의 그래디언트 추적을 해제하며 주로 모델을 테스트하거나 추론할 때 사용함
test_pred = model_0(X_test)
test_loss = loss_fn(test_pred, y_test)
if epoch % 10 == 0:
epoch_count.append(epoch)
loss_values.append(loss)
test_loss_values.append(test_loss)
print(f"Epoch: {epoch} | Loss: {loss} | Test loss: {test_loss}")
print(model_0.state_dict())
- 학습된 모델을 이용하여 추론
위에서 만든 학습 코드로 모델을 학습시키고 나면, 모델의 파라미터들이 학습된 값을 갖게 되고 이러한 파라미터들을 이용하여 새로운 데이터에 대해서도 추론할 수 있게 된다. 모델로 추론을 하기 위해선 위에서 테스트하는 부분의 코드와 마찬가지로 모델을 eval() 모드로 전환시키고 with torch.inference_mode():으로 추론 모드에 진입하는 컨텍스트 매니저를 사용한다.
TensorFlow/Keras에서는 모델을 eval() 모드로 전환하거나 torch.inference_mode() 같은 컨텍스트 매니저를 사용할 필요가 없는 이유는 기본적으로 추론(inference) 시 자동으로 적용되기 때문이야.
PyTorch에서는 model.eval()과 torch.inference_mode()가 필요한 이유
PyTorch에서 모델을 학습(train)할 때와 추론(eval)할 때, 일부 레이어의 동작이 달라지기 때문이야.
🔹 학습(model.train()) 모드와 추론(model.eval()) 모드의 차이
Batch Normalization (nn.BatchNorm1d, nn.BatchNorm2d 등)
학습 중에는 배치(batch) 통계를 이용해서 정규화 수행
추론 시에는 학습된 평균(mean)과 분산(variance)을 사용해야 함
Dropout (nn.Dropout)
학습 중에는 일부 뉴런을 랜덤하게 비활성화(drop)하여 정규화 수행
추론 시에는 완전히 활성화되어야 함 (즉, Dropout 비활성화)
TensorFlow/Keras에서는 eval()이 필요 없는 이유
TensorFlow/Keras에서는 모델을 학습(fit())하거나 추론(predict())할 때, 자동으로 훈련 모드와 추론 모드를 구분해.
X_new = torch.randn(1)
model_0.eval()
with torch.inference_mode():
y_preds_new = model_0(X_new)
print(y_preds_new)-
모델 평가
모델의 훈련이 완료된 후에는 모델이 새로운 데이터에 얼마나 잘 일반화되는지를 평가할 수 있으며, 이 과정에서 모델의 현재 상태를 파악할 수 있다. 모델 평가를 위해서는 일반적으로 테스트 데이터셋을 사용한다. 테스트 데이터셋은 모델이 학습하지 않은 데이터로, 모델의 예측 성능을 측정하는 데 사용된다. 이러한 평가 과정을 통해 모델의 정확도(accuracy), 정밀도(precision), 재현율(recall), F1 점수(F1-score) 등 다양한 성능 지표를 확인하며 다양한 시각화 도구들을 이용하여 모델의 성능을 시각적으로 표현하고 분석할 수 있다.
파이토치 또한 자체적인 평가 기능들을 제공하지만 평가지표를 편리하게 생성해주는 외부 라이브러리를 이용할 수도 있다. 대표적인 평가 라이브러리로는 torchmetrics가 있으며 Tenserboard같은 시각화 툴도 사용할 수 있다.
평가를 수행할 때는 모델을 eval() 모드로 전환하여 드롭아웃(dropout)이나 배치 정규화(batch normalization) 같은 레이어가 학습 시와는 다르게 동작하도록 한다. -
실험을 통해 모델 개선
모델의 성능을 향상시키기 위해서는 다양한 실험을 통해 개선하는 과정이 필요하다. 이러한 실험은 하이퍼파라미터 튜닝, 데이터 증강, 모델 아키텍처 변경 등 여러 가지 방법이 있다.
하이퍼파라미터 튜닝
하이퍼파라미터는 모델 학습 과정에서 데이터와 관계없이 직접 설정해줘야하는 매개변수들이다. 딥러닝에선 학습률, 배치 크기, 에포크 수 등이 대표적인 하이퍼파라미터이다. 하이퍼파라미터 최적화는 실험을 통해 모델의 성능을 극대화하는 중요한 과정이다.
데이터 증강(data augmentation)
데이터 증강은 훈련 데이터에 작은 변형을 가하여 데이터셋의 다양성을 증가시키는 기법이다. 이를 통해 모델의 일반화 성능을 향상시킬 수 있다. 예를 들어 이미지 데이터를 다룬다면 이미지에 대해 회전, 자르기, 색상 변화 등을 적용할 수 있다.
모델 아키텍처 변경
모델의 구조를 변경하여 더 깊은 레이어를 추가하거나, 새로운 유형의 레이어를 도입함으로써 성능을 개선할 수 있다.
- 모델을 파일로 저장하고 불러오기
모델 학습과 평가가 완료된 후에는, 모델을 파일로 저장하여 나중에 재사용하거나 배포할 수 있다. 파이토치에선 torch.save()와 torch.load() 함수를 통해 모델을 저장하고 불러오는 기능을 제공한다.
모델 저장하기
torch.save()는 모델의 전체 상태(모델의 구조, 파라미터 등)를 저장한다. 모델의 state_dict()메서드로 모델의 파라미터 값들만 저장할 수도 있다. 모델 파일은 파이썬의 내장 모듈인 pickle 포맷으로 저장되며 파일의 확장자는 보통 .pt 또는 .pth를 사용한다. 모델의 파라미터만 저장할 경우 모델 파일의 크기를 줄일 수 있지만 모델을 불러올 때 추가적인 코드가 필요하다.
결론
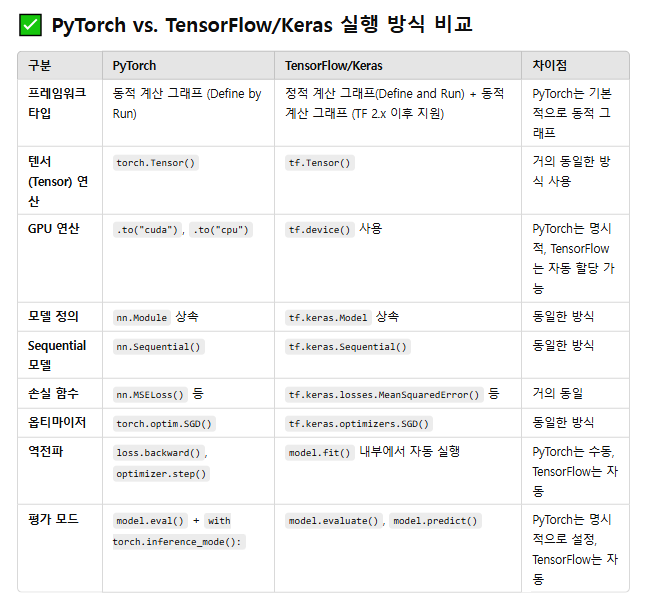
지금 정리한 내용에서 예제 코드는 PyTorch 기준으로 되어 있지만, TensorFlow/Keras에서도 거의 동일한 방식으로 실행 가능해.
PyTorch와 TensorFlow/Keras는 기본적인 실행 방식이 비슷하지만, PyTorch는 수동 설정이 필요하고 TensorFlow는 자동화되어 있음.
모델 정의, 텐서 연산, 옵티마이저, 손실 함수는 거의 동일한 방식으로 사용 가능.
단, PyTorch는 zero_grad(), loss.backward() 등을 직접 호출해야 하고, 평가할 때 eval()과 torch.inference_mode()를 사용해야 함.
TensorFlow/Keras는 model.fit(), model.evaluate(), model.predict() 등으로 모든 과정이 자동 실행됨.
📌 즉, PyTorch 기준으로 학습했어도 TensorFlow/Keras에서 거의 동일한 실행 방식이 적용되지만, 일부는 자동화 차이가 있어! 🚀
