인공지능:
인간의 지능이 갖고 있는 기능을 갖춘 컴퓨터 시스템, 인간의 지능을 기계 등에 인공적으로 구현한 것
머신러닝(=기계학습):
인공지능의 한 분야, 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
딥러닝:
머신러닝의 한 분야, 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화(복잡한 것에서 핵심만 간단하게)를 시도하는 기계학습 알고리즘의 집합
인공신경망을 기초로 함
ANN(Artificial Neural Network):
-
인공신경망, 사람의 신경망 원리와 구조를 모방하여 만든 기계학습 알고리즘
-
신경망은
다수의 입력 데이터를 받는 입력층(Input)
데이터의 출력을 담당하는 출력층(Output)
입력층과 출력층 사이에 존재하는 은닉층(Hidden Layer)이 존재합니다.
여기서 히든 레이어들의 갯수와 노드의 개수를 구성하는 것을 모델을 구성한다고 하는데,
이 모델을 잘 구성하여 원하는 Output값을 잘 예측하는 것이 할 일
은닉층에서는 활성화함수를 사용하여 최적의 암계값(Weight와 Bias)을 찾아내는 역할을 합니다.
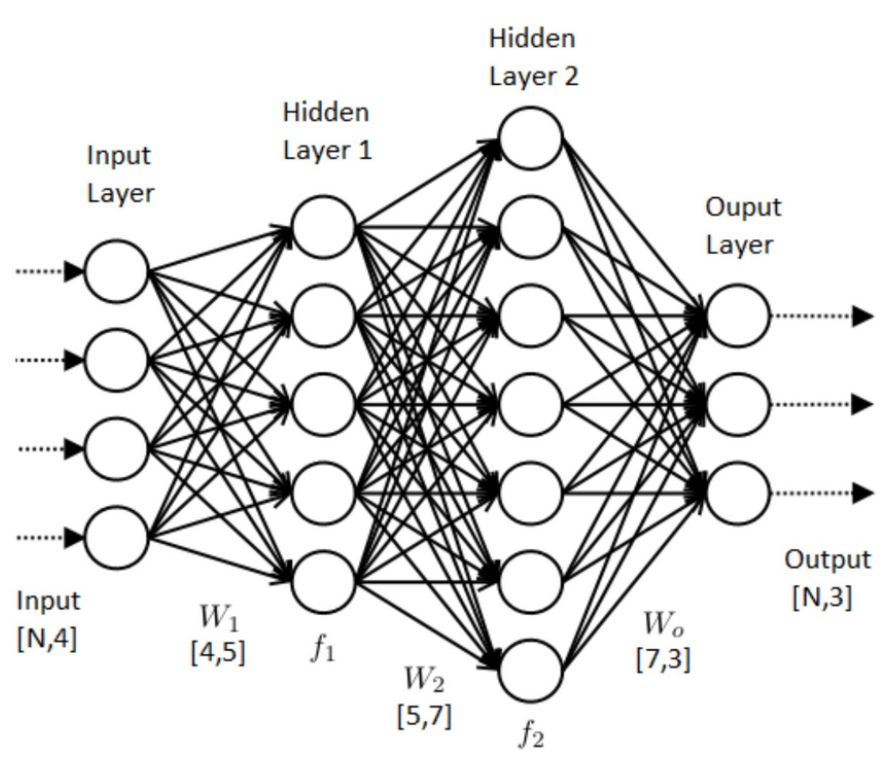
-
ANN의 문제점
-
학습과정에서 파라미터의 최적값을 찾기 어렵다.
출력값을 결정하는 활성화함수의 사용은 기울기 값에 의해 weight가 결정되었는데 이런 gradient값이 뒤로 갈수록 점점 작아져 0에 수렴하는 오류를 낳기도 하고
부분적인 에러를 최저 에러로 인식하여 더이상 학습을 하지 않는 경우도 있습니다. -
Overfitting에 따른 문제
대부분 실험 데이터(training dataset)를 데이터 전체를 대표할 수 있을만큼의 충분한 학습 데이터를 확보할 수 없다
그로인해, Dtrain에 과하게 적합되어 예측모델이 Dtrain에서는 더 낮은 예측 오차를 보이지만 실제 Dtest에서는 더 높은 예측 오차를 보이는 것
-> 사전 훈련을 통해 방지할 수 있음 -
학습시간이 너무 느리다.
은닉층이 많으면 학습하는데에 정확도가 올라가지만 그만큼 연산량이 기하 급수적으로 늘어나게 됩니다.
-> GPU의 발전으로 극복
DNN(Deep Neural Network)
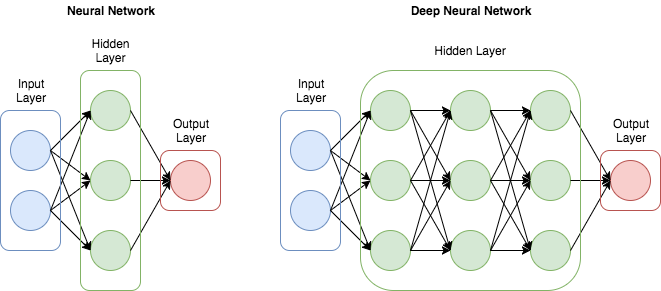
- DNN이란? ANN기법의 여러문제가 해결되면서 모델 내 은닉층을 많이 늘려서 학습의 결과를 향상시키는 방법이 등장하였고 이것이 DNN
- DNN은 은닉층을 2개이상 지닌 학습 방법을 뜻합니다.
컴퓨터가 스스로 분류레이블을 만들어 내고 공간을 왜곡하고 데이터를 구분짓는 과정을 반복하여 최적의 구번선을 도출해냅니다.
많은 데이터와 반복학습, 사전학습과 오류역전파 기법을 통해 현재 널리 사용되고 있습니다. - DNN을 응용한 알고리즘이 바로 CNN, RNN인 것이고 이 외에도 LSTM, GRU 등이 있습니다.
CNN(Convolution Neural Network)
-
기존의 방식은 데이터에서 지식을 추출해 학습이 이루어졌지만,
CNN은 데이터의 특징을 추출하여 특징들의 패턴을 파악하는 구조입니다. -
이 CNN 알고리즘은 Convolution과정과 Pooling과정을 통해 진행됩니다.
Convolution Layer와 Pooling Layer를 복합적으로 구성하여 알고리즘을 만듭니다.
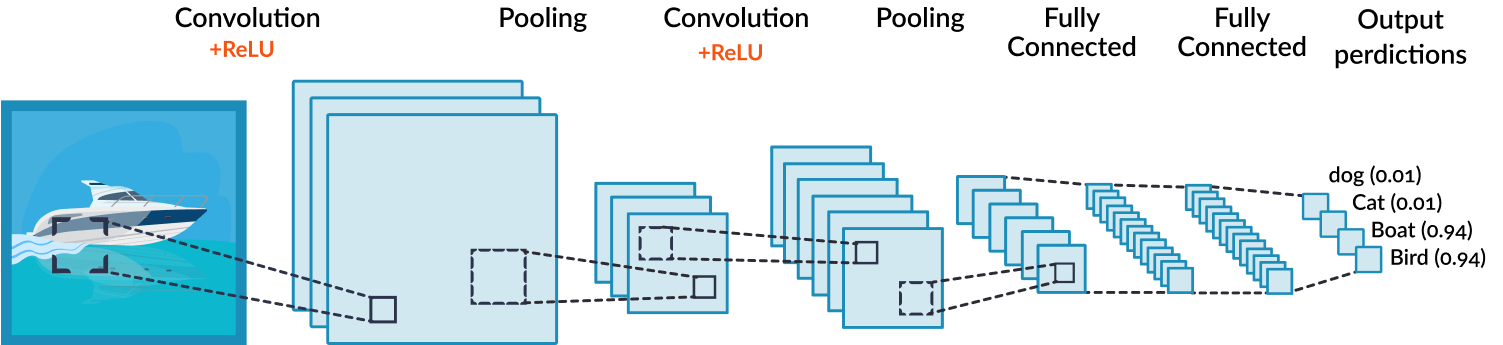
-
Convolution
데이터의 특징을 추출하는 과정으로 데이터에 각 성분의 인접 성분들을 조사해 특징을 파악하고 파악한 특징을 한장으로 도출시키는 과정이다.
여기서 도출된 장을 Convolution Layer라고 한다.
이 과정은 하나의 압축 과정이며 파라미터의갯수를 효과적으로 줄여주는 역할을 합니다.
- Pooling
이는 Convolution 과정을 거친 레이어의 사이즈를 줄여주는 과정입니다. 단순히 데이터의 사이즈를 줄여주고, 노이즈를 상쇄시키고 미세한 부분에서 일관적인 특징을 제공합니다.
CNN은 보통 정보추출, 문장분류, 얼굴인식 등의 분야에서 널리 사용되고 있습니다.
RNN(Recurrent Neural Network)
- RNN 알고리즘은 반복적이고 순차적인 데이터(Sequential data)학습에 특화된 인공신경망의 한 종류로써, 내부의 순환구조가 들어있다는 특징을 가지고 있습니다.
- 순환구조를 이용하여 과거의 학습을 Weight를 통해 현재 학습에 반영합니다.
기존의 지속적이고 반복적이며 순차적인 데이터학습의 한계를 해결하는 알고리즘 입니다.
현재의 학습과 과거의 학습의 연결을 가능하게 하고 시간에 종속된다는 특징도 가지고 있습니다.
