💡 주제
기존 단백질 언어 모델(PLM)에 구조 정보를 효율적으로 통합하기 위한 새로운 모델 MULAN
ESM2 등 기존 sequence-only PLM 위에
구조 정보를 통합할 수 있는 lightweight adapter를 추가하여,
구조 인식 능력을 크게 향상시키면서도 파라미터 및 연산 비용을 최소화
✅ 연구 배경 및 문제의식
단백질의 기능은 3D 구조에 의해 결정되며, 3D 구조는 아미노산 서열로부터 형성됨
단백질 서열이 텍스트처럼 다뤄질 수 있어 NLP 기반의 Protein Language Model (PLM) 적용이 가능해짐.
ESM2, ProtTrans, Ankh 같은 sequence-only PLM은 뛰어난 성능을 보였으나,
구조 정보를 내재적으로 학습하는 데 한계가 있음.
ex)
AlphaFold2 (구조 기반)는 ESMFold (서열-only 모델)보다 훨씬 더 나은 성능을 보임.
✅ 기존의 구조 기반 모델의 한계
최근 등장한 구조 기반 PLM (= SPLM) (ex. SaProt, ESM3)은 구조 정보를 포함시켜 더 높은 성능을 보임.
하지만 대부분 처음부터 학습해야 하며,
구조 encoder가 매우 크고 복잡해서 학습/추론 비용이 큼.
✅ MULAN(Multimodal Protein Language Model) 모델 제안
기존 PLM 위에 경량 구조 모듈인 Structure Adapter를 추가.
구조 정보를 torsion angle (ϕ, ψ, χ1~5) 형태로 입력 받아,
기존 PLM의 residue 임베딩에 더해주는 방식.
사전학습된 PLM을 재활용하여 학습 비용을 절감.
✅ 성능 향상 확인
MULAN을 ESM2 및 SaProt 다양한 크기의 모델에 적용.
총 9가지 downstream task에서 평가
특히 Protein–Protein Interaction (PPI) task에서 최대 AUROC 0.12 향상.
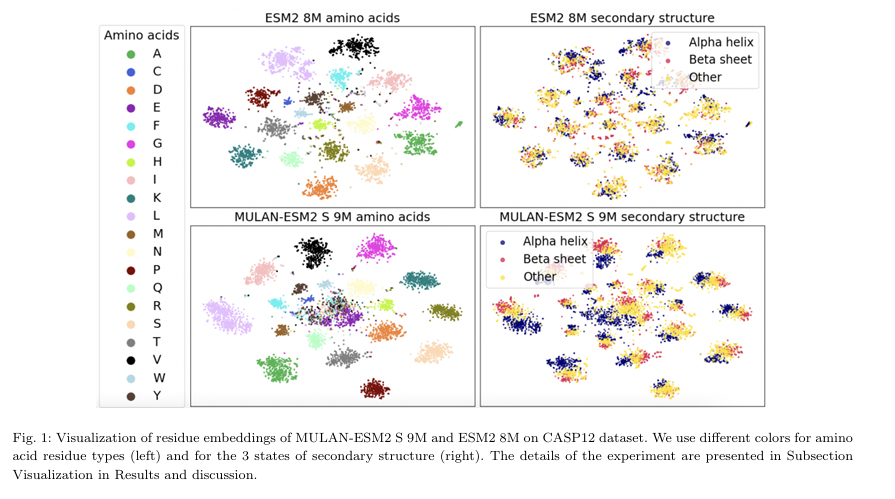
MULAN은 secondary structure가 잘 분리됨 → 구조 인식 능력이 강함
ESM2는 대부분의 구조 유형이 서로 섞여 있음
MULAN은 아미노산 구분 정보도 유지하고 있음 (기존 PLM의 sequence 인식 성능 보존)
✅ 구조 정보 입력 (Structural Information)
각 residue에 대해 다음과 같은 torsion angle vector를 생성
[ϕ, ψ, χ1 , χ2, χ3, χ4, χ5]
- ϕ, ψ: backbone torsion angles
- χ₁~χ₅: side chain torsion angles
(ex. arginine은 최대 5개)
미정의된 각도 (ex. N- or C-terminal, 존재하지 않는 χ₃~χ₅ 등)는 #으로 마스킹된 padding 값으로 채워짐.
ϕ, ψ, χ₁~χ₅ 이 각도들은 회전 및 병진 불변 (rotation & translation invariant)하므로 Transformer에 적합함.
🖐 rotation & translation invariant 란?
이 각도들은 구조가 어떻게 공간상에서 회전하거나 이동하든 값 자체는 변하지 않음.
따라서 구조 자체를 Transformer에 입력할 때 절대 좌표(x, y, z) 대신에 torsion angle을 사용하는 것은
모델이 더 일반적인 구조 패턴을 학습할 수 있게 해줌
이느 좌표 시스템에 종속되지 않는 강건한 구조 표현 방식
✅ 구조 어댑터 (Structure Adapter) 구성
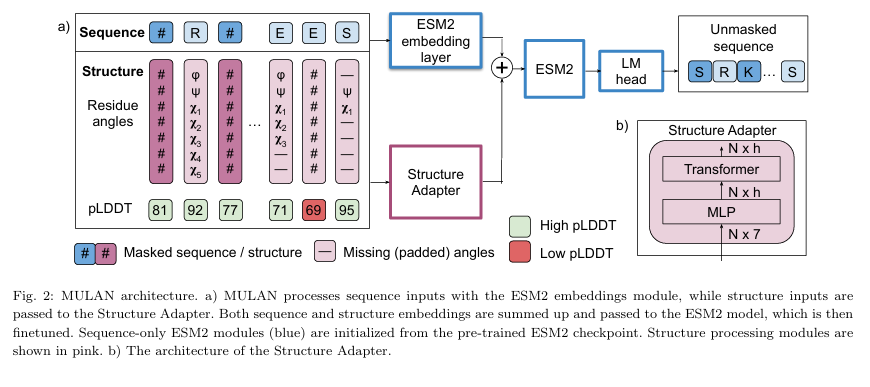
1️⃣ 입력: 서열과 torsion angle 벡터, pLDDT
2️⃣ 구조 adapter: MLP → Transformer → structure embedding 생성
- MLP: angle vector (N×7)를 h차원의 embedding으로 투영
- Transformer: Rotary positional encoding을 포함
-> 결과적으로 N × h 구조 embedding이 생성됨
3️⃣ Embedding 융합: structure embedding + ESM2 embedding → ESM2 전달
이 구조 임베딩은 ESM2의 residue embedding과 더해짐
이렇게 sequence + structure 정보를 융합한 embedding이 최종적으로 ESM2로 전달됨
4️⃣ MLM 학습: LM Head를 통해 마스킹된 residue 예측
✅ 학습 전략 (Training Procedure)
✅ Pretraining 기반
기존의 사전학습된 ESM2를 가져와 finetuning 진행
구조 정보는 추가적으로 학습되는 정보이며, 기존 PLM의 성능은 보존됨
✅ MLM (Masked Language Modeling) 사용
전체 서열 중 15% residue는 마스킹
▶ 서열 마스킹
전체 residue 중 15%는 서열(R, K, E 같은 아미노산 문자)을 마스킹
▶ 구조 각도 마스킹
이 마스킹된 서열에 대응하는 torsion angle도 함께 마스킹하거나 변형
즉, 서열과 각도 정보는 항상 짝지어서 mask 처리
마스킹된 residue의 torsion angle은 아래 세 가지 중 하나로 처리
- 각도 마스킹 (mask value 사용) -> 80%
- 랜덤 angle vector로 교체 -> 10%
- 변경 없음 -> 10%
마스킹 값은 ±4로 설정되어 실제 각도 범위 (−π~π)와 구분됨
🖐 각도 구분이란?
일반적으로 각도는 −π ~ π (약 −3.14 ~ +3.14) 범위에 존재
마스킹할 때는 이 실제 범위에 존재하지 않는 수 (예: ±4) 를 사용하면,
모델이 “이건 진짜 angle이 아니라 마스킹된 값이다”라고 명확하게 구분할 수 있음
진짜 torsion angle: -3.0 ~ +3.0 (radians)
마스킹된 angle vector: +4.0 또는 -4.0로 세팅
이렇게 하면 모델은 해당 angle을 구조 예측 학습 중 예측 대상(target)으로 처리하게 되고,
실제 angle 분포와 혼동되지 않게 됨
✅ 신뢰도 기반 구조 마스킹 (pLDDT)
AlphaFold2의 pLDDT (predicted Local Distance Difference Test) score 사용 (0–100)
pLDDT < 70인 residue의 구조 각도는 신뢰도 낮은 구조로 간주하고 masking
→ 모델이 노이즈 구조로 학습되지 않도록 방지
✅ 평가 대상 Task (총 9개 + 구조 인식)
MULAN은 다음과 같은 9가지 주요 downstream task와 부가적인 구조 인식 평가(secondary structure prediction)에 대해 성능을 평가
| 분류 | Task | 설명 |
|---|---|---|
| Binary | HumanPPI Metal Ion Binding | 단백질-단백질 상호작용 여부, 금속 결합 예측 |
| Multiclass | Localization (10-class 및 binary) | 단백질 세포 내 위치 분류 |
| Regression | Thermostability Fluorescence | 온도 안정성, 형광 밝기 |
| Multilabel | GO Annotation (Gene Ontology: CC, MF, BP) | 생물학적 기능 주석 예측 (복수 정답 가능) |
| Structural Awareness | Secondary Structure Prediction | 구조 정보를 직접적으로 반영하는 평가 지표 |
각 task는 기존 benchmark에서 가져왔으며, original data split을 유지함.
✅ 구조 정보 확보 방식
AlphaFold2 DB에서 UniProt accession 번호로 구조 정보를 조회
PDB ID → UniProt ID로 매핑하여 구조 정보를 자동 수집
없을 경우 AlphaFold2 standalone 버전으로 예측 수행
Secondary structure task의 경우는 실험적으로 확인된 PDB 구조만 사용
✅ Downstream Task 평가 방식
✅ 임베딩 추출
각 모델의 최종 레이어에서 residue-level 임베딩 추출
protein-level task의 경우 평균 풀링(average pooling) 적용
✅ 예측 모델
downstream task는 Light Attention architecture를 사용
→ MLP보다 성능이 뛰어남
→ protein embedding에 특화되어 설계된 구조
✅ 학습 세부 설정
고정된 하이퍼파라미터 그리드를 사용 (모든 task 공통)
- Optimizer: AdamW
- β₁ = 0.9, β₂ = 0.999
- learning rate = 5e−5 (일부 task에선 1e−5 ~ 1e−4 범위)
- batch size: 8192
- 학습 epoch: 최대 200 epoch
→ validation 성능 기준으로 best checkpoint 선택
🖐 Hybrid sequence–structure model 이란?
단백질 서열(sequence) 정보와 구조(structure) 정보를 동시에 사용하는 모델.
단일 modality (ex. 서열-only)보다 더 정확하게 단백질 특성을 학습할 수 있음.
-
S-PLM: sequence와 구조 contact map을 contrastive learning 방식으로 함께 학습
-
PST: Transformer와 graph encoder를 조합한 구조 인식 모델
이것들과 비교해서도 MULAN이 경쟁력 있음
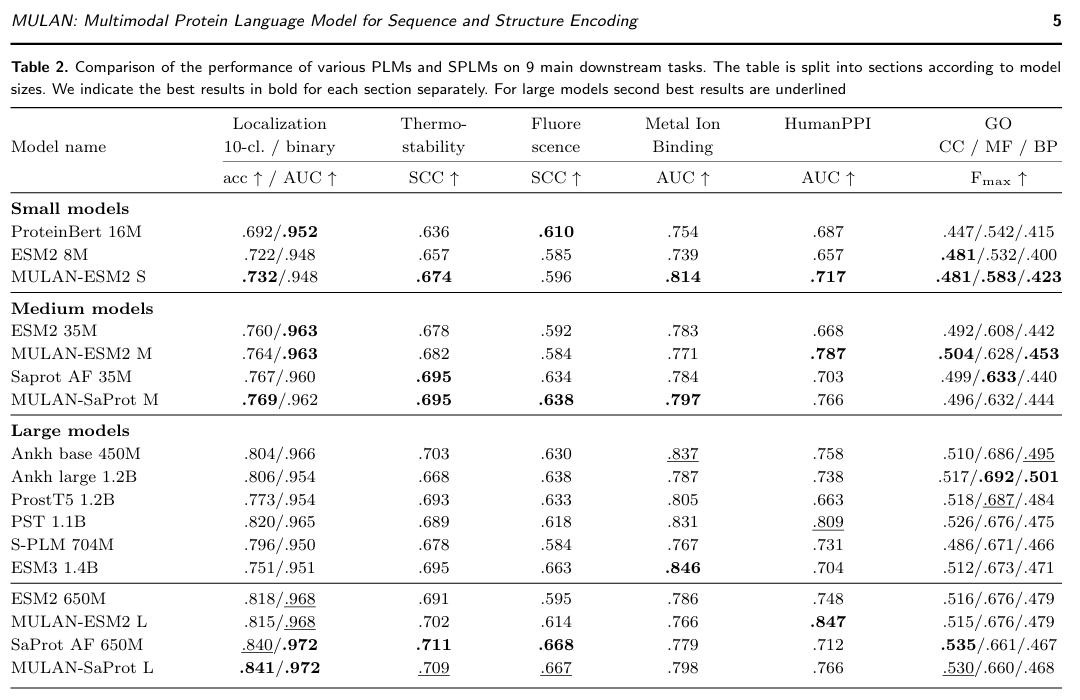
✅ MULAN은 ESM2에서 특히 효과적
MULAN-ESM (sequence-only PLM + 구조 adapter) 모델이 일반적으로 MULAN-SaProt보다 더 큰 향상 폭을 보임.
그 이유는 SaProt은 이미 구조 정보를 사용하는 반면, ESM2는 순수 서열 모델이기 때문에 구조 adapter 추가의 효과가 더 큼.
MULAN은 기존 PLM의 구조 인식을 싸고 효율적으로 강화할 수 있음
✅ SaProt에도 추가적인 성능 향상이 존재
SaProt은 이미 Foldseek 기반 구조 표현(3Di alphabet)을 사용하는 모델이지만,
MULAN의 torsion angle 기반 구조 adapter를 추가하면
특히 PPI 예측 task에서 성능이 더 향상됨.
→ 두 방식이 서로 보완적인 구조 정보를 제공할 수 있음을 시사.
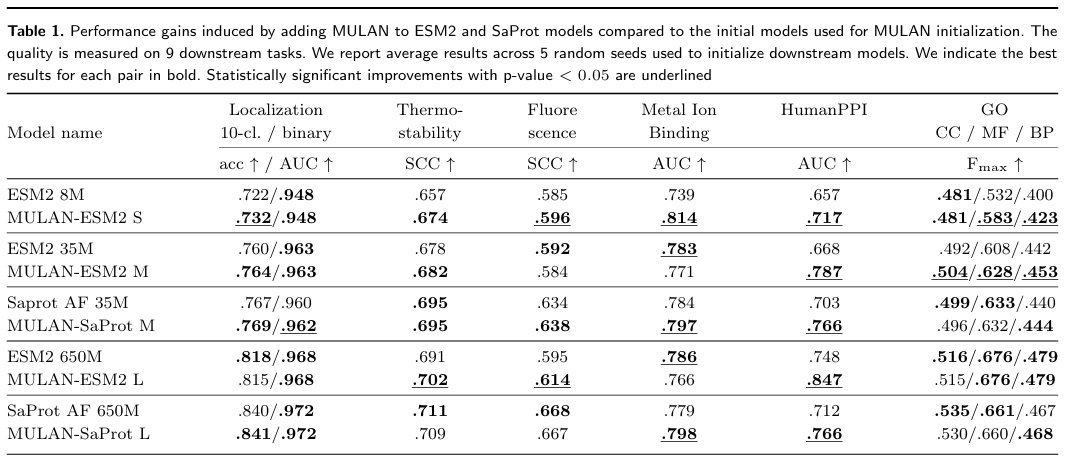
✅ MULAN은 다른 최상위 SPLM들과 경쟁 가능하다
MULAN은 ESM2 8M 위에 올려도 ProteinBert 16M보다 성능이 더 좋음.
큰 모델(MULAN-L)은 PST, ProstT5, ESM3 등 SOTA 모델들과 비슷한 수준의 성능을 보임.
각 모델이 잘하는 downstream task는 다르지만, MULAN은 전체적으로 경쟁력 있음.
또한, 가볍고 효율적인 구조 adapter 하나만으로도 기존의 복잡한 SPLM들과 비슷한 성능을 낼 수 있음
| 항목 | MULAN | SOTA SPLMs (PST, S-PLM, ESM3 등) |
|---|---|---|
| 학습 시간 | 1 GPU로 최대 3일 | 수 주~수 개월 |
| 파라미터 증가량 | 0.3% (MULAN-L 기준) | PST: 69%, S-PLM: 13.8% |
| 연산 속도 | 빠름 (lightweight) | 느림 (구조 encoder 크고 복잡) |
| GPU 요구량 | 낮음 | 높음 |
✅ Structure Adapter의 중요성
MULAN의 성능 향상은 단순한 finetuning 때문이 아니라 Structure Adapter 덕분
| 실험 비교 | 결과 |
|---|---|
| ESM2 (baseline) | 기본 성능 |
| ESM2 + finetuning (MULAN 데이터셋으로만 학습) | 거의 성능 향상 없음 |
| MULAN-ESM2 (ESM2 + StructureAdapter) | 명확한 성능 향상 |
단순히 ESM2를 구조 데이터셋으로 미세조정한다고 성능이 올라가지 않으며, 구조 정보를 처리하는 구조 (Adapter) 가 있어야 효과가 나타남
✅ pLDDT 마스킹의 효과 (Uncertain residue masking)
AlphaFold2 구조에서 신뢰도 낮은 잔기(pLDDT < 70)는 masking 하는 것이 좋음
| 실험 비교 | 결과 |
|---|---|
| MULAN (pLDDT < 70 masking 포함) | 더 나은 성능 |
| MULAN without pLDDT masking | 성능 감소 |
➡️ 노이즈 있는 각도 정보를 제거하면 대부분의 downstream task에서 성능 향상 → 입력의 신뢰도 필터링이 중요
마스킹을 하지 않은 경우(without pLDDT)는 일부 지표에서 낮아짐
노이즈 제거로 성능 향상 가능하다는 것을 의미
✅ Scratch부터 학습하면 성능 저하 (Pretraining 필요성)
MULAN을 random 초기화해서 구조-서열을 학습시키면 ESM2보다도 낮은 성능이 나옴
| 실험 비교 | 결과 |
|---|---|
| MULAN (ESM2 pretrain 후 구조 적응) | 매우 좋은 성능 |
| MULAN (from scratch, random 초기화) | 성능 저조 |
➡️ 사전학습(pretraining)된 서열 언어모델의 사전 지식이 매우 중요
→ 구조 정보는 기존 PLM 위에 덧붙이는 형식이 바람직
✅ Architecture Ablation (구조적 변형 실험)
다양한 구조 변형을 실험했으나, 기존 MULAN 구조보다 좋은 결과를 내지 못함
| 시도한 방식 | 결과 |
|---|---|
| Foldseek 임베딩 추가 | 큰 성능 향상 없음 |
| Contact prediction head 추가 | 동일 |
| Angle prediction head 추가 | 동일 |
➡️ 현재의 MULAN 구조가 최적 구조에 가까움, 복잡한 구조 추가는 효과 미미
✅ Secondary Structure Prediction (2차 구조 예측 능력 실험)
MULAN이 실제로 3D 구조 정보를 사용하고 있는지 검증
| 실험 세부사항 |
|---|
| CASP12, TS115, CB513 dataset 사용 |
| 실험 구조 (X-ray/NMR 기반) 사용하여 AlphaFold의 pLDDT 마스킹은 적용 안 함 |
| 각 residue의 angle 정보만 사용하여 secondary structure 예측 수행 |
MULAN이 ESM2보다 2차 구조 예측 성능이 월등히 높음
Foldseek 기반 모델(SaProt)처럼 구조 인식 가능
➡️ 구조적 awareness 확인 완료
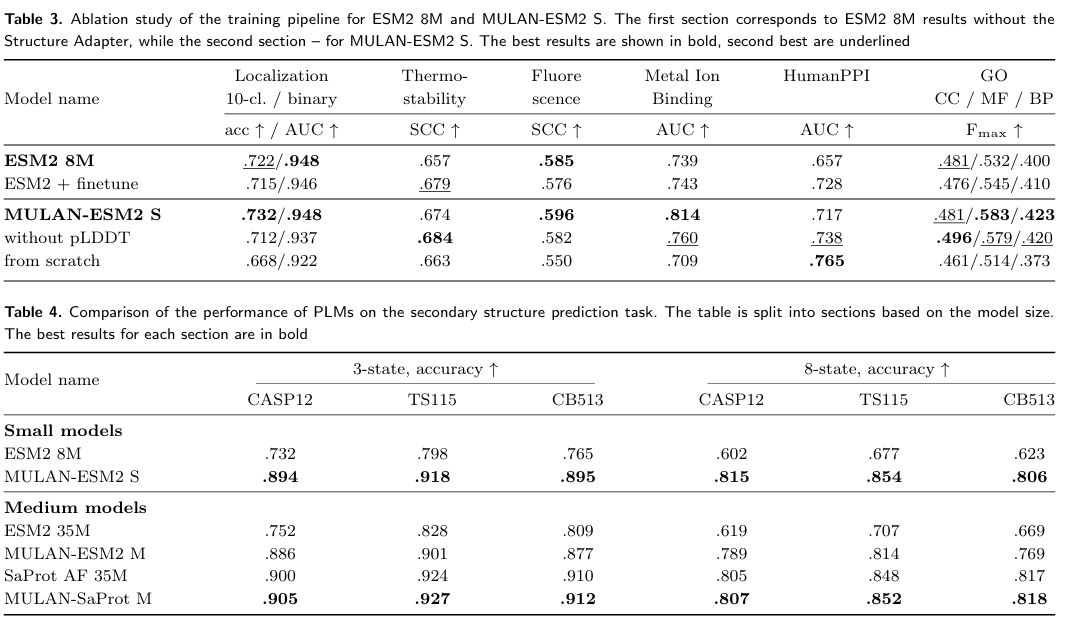
✅ ESM2 / SaProt / MULAN 모델이 2차 구조 예측 (secondary structure prediction)을 얼마나 잘 수행하는지 비교
세 개의 데이터셋 사용: CASP12, TS115, CB513
평가 지표: 3-state accuracy (H/E/C 구분)와 8-state accuracy
→ SaProt 기반 MULAN이 ESM2보다도 성능 좋음
→ 사전학습된 SaProt + StructureAdapter 조합이 매우 강력
✅ 1. Visualization: 구조 인식 능력 시각화 (t-SNE)
t-SNE 시각화를 통해 각 모델이 구조/물리적 특성을 얼마나 잘 인식하는지를 시각적으로 평가
- 데이터셋: CASP12
- ESM2 8M vs. MULAN-ESM2 S 비교
- 시각화 방법: t-SNE
1️⃣ 실험 구성
마지막 레이어의 residue-level embedding 사용
왼쪽 그림: 아미노산 타입으로 색칠
오른쪽 그림: 3-state secondary structure 타입으로 색칠
2️⃣ 결과 해석
MULAN은 secondary structure를 더 잘 인식함
같은 아미노산 그룹 내에서도 helix/sheet/coil 등이 분리됨
ESM2는 그런 구분이 잘 안 됨
하지만 MULAN도 ESM2에서 학습한 아미노산 특성은 유지
즉, 서열 정보와 구조 정보 모두 학습됨
✅ 2. Sequence-based vs. Structure-informed Models 비교
1️⃣ Sequence-based PLMs
아미노산 서열 = 언어의 문장 → 자연어처리(NLP) 기법이 효과적
대부분의 PLM은 Masked Language Modeling (MLM) 방식으로 사전학습됨
주요 모델들: ESM2, Ankh, ProtT5, TAPE, 등
수행 가능한 작업: 2차 구조 예측, 접촉 지도(contact map), 위치 예측, 돌연변이 영향 예측 등
2️⃣ 구조 인식(Structure-informed) PLMs
아미노산 서열만으로는 3D 구조와 기능 정보를 완전히 추론하기 어렵다
구조 정보는 서열보다 더 보존성이 높다
| 모델명 | 방법 | 특이점 |
|---|---|---|
| ProstT5 | Foldseek의 3Di structural alphabet 사용 | 구조 문자를 서열처럼 변환하여 학습 |
| SaProt | Amino acid + 3Di alphabet 조합 사용 | 구조 인식 향상, ESM2보다 좋은 성능 |
| SES-Adapter | Adapter 방식 + 구조 주석 사용 | general PLM 아님, task별 재학습 필요 |
| ESM3 | Sequence + Structure + Function 통합 사전학습 | 완전한 multi-modal pretraining |
3️⃣ Hybrid Models (구조 기반 GNN 통합형 모델들)
단백질의 3차 구조는 그래프 형태로 해석 가능
→ 이를 활용해 PLM + GNN 통합 시도
이러한 모델들을 "하이브리드 모델"이라 부르며, 다양한 전략으로 구조 정보를 모델에 주입
| 전략 | 설명 | 예시 |
|---|---|---|
| MLM only + GNN | 서열만 MLM으로 학습, 구조는 GNN으로 따로 처리 | Mansoor et al. 2021, Zheng et al. 2023 |
| Masked Structure Modeling 추가 | 서열과 구조를 모두 마스킹하여 학습 | LM-GVP, GearNet, MIF |
| 모델명 | 설명 | 주요 특징 |
|---|---|---|
| ESM-GearNet (Zhang et al. 2023) | ESM2 서열 표현 + GearNet 구조 인코더 결합 | diffusion 기반 사전학습도 포함됨, 여러 task에서 성능 향상 |
| DeProt (Li et al. 2024) | 각 residue 주변의 local 구조로 구조 인코딩 | GearNet과 유사한 접근 |
| PST (Chen et al. 2024) | PLM + GNN 통합 후 공동학습 (joint training) | PLM self-attention 수정, 파라미터 수 PLM 수준 |
| S-PLM (Wang et al. 2023) | contrastive learning 방식, 구조 인코더는 Swin Transformer | contact map 기반 구조 인식, 추론 시 구조 입력은 필요 없음 |
기존 hybrid 모델들은 대부분 GNN 기반 구조 인코더를 별도로 사용하거나
PLM 자체를 구조-aware 하게 변경
하지만 대부분 모델 크기 증가, 복잡한 joint training, 높은 계산량을 수반
