BoostCamp AI Tech 4기 논문 스터디 5회차
Neural Collaborative Filtering
Abstract
- 추천의 핵심 문제인 implicit feedback 기반 CF에 deep neural networks(DNN)를 어떻게 사용할지 알아보자
- 추천에 딥러닝을 사용한다고 해도, 보조적인 정보(아이템의 텍스트 설명, 음악의 음향적 특징 등)를 모델링할 때 사용, 아직도 CF의 핵심인 유저와 아이템 feature는 MF와 내적에 의존
- Neural networkbased Collaborative Filtering(NCF)를 제시
- 데이터로부터 얻은 신경 구조가 내적을 대체
- Framework 내에서 MF를 일반화
- 비선형적인 NCF 모델을 supercharge 하기 위해 multi-layer perceptron을 통해 유저-아이템 상호작용 함수(interaction function)를 학습
- 두 가지 실제 데이터를 가지고 진행한 시험은 이것이 state-of-the-art보다 개선됨을 증명
- 이로써 더 깊은 신경망이 더 좋은 추천 성능을 낸다는 것을 경험적 증거를 통해 보여줌
심층 신경망은 CV, NLP 분야에서 엄청난 성공을 보였지만 Recsys에서는 많이 사용되지 않았음. 이 논문에서는 NCF를 제시하여, Recsys에서도 심층 신경망을 사용하면 좋은 성능을 낼 수 있다는 것을 보여줄 것.
1. INTRODUCTION
- 추천 시스템은 넘쳐나는 정보 사이에서 정보 과부화를 완화하는 역할
- CF처럼, 개인화된 추천 시스템은 과거 상호작용(평점, 클릭 등) 기반으로 사용자의 선호도를 모델링
- 다양한 CF 기술 중 MF는 latent feature vector를 사용해 latent space로 유저와 아이템을 projection, 그리고 그들의 내적을 통해 아이템에 대한 유저의 상호작용을 모델링
- Neflix Prize로 유명해진 MF는 계속해서 연구되어 왔음
- 하지만 MF의 효율에도 불구하고 상호작용 함수(내적 등)를 쉽게 고르면 성능을 저하시킬 수 있음
- 단순한 내적은 복잡한 유저 상호작용 데이터를 나타내기에 충분하지 않음
- Explicit feedback에 대한 MF에서 유저, 아이템 bias를 도입하면 성능 향상이 가능한 경우 존재
- 논문에서는 DNN을 어떻게 MF에 적용할지 살펴볼 것
- DNN이 추천 시스템에 사용되긴 했어도, 근본적인 CF 모델링 관련해서는 내적을 사용하는 MF에 의존해 왔음
- CF에 신경망 모델링 접근 방법을 적용해 이 문제를 해결할 것
- noise가 존재하는 implicit feedback을 모델링하기 위해 DNN을 활용하자
사용자의 선호도를 모델링하기 위해 사용되는 CF는 보통 MF를 기반으로 작동하는데, 이 MF를 적용할 때 상호작용 함수로 (latent factor와 유저 및 아이템 사이의)내적을 사용하는 것은 복잡한 상호작용을 모델링할 수 없다는 단점이 있음. 이를 위해 내적 대신 DNN을 사용하여 MF와 CF에 어떻게 적용할지, 이로써 implicit feedback을 어떻게 모델링할지 알아보자는 의미
- 유저와 아이템의 latent feature에 대한 neural network architecture을 제시하고 CF에 대한 일반적인 NCF Framework를 고안
- MF는 NCF의 specialization이라는 걸 보이고, NCF 모델링에 고차원의 비선형성을 부여하기 위해 다층 퍼셉트론을 사용
- NCF 접근의 효율성과 CF에 딥러닝을 적용할 수 있는 가능성을 실험으로 보여줄 것
2. PRELIMINARIES
- 기존의 Implicit feedback 기반 CF 논의
- MF 요약 및 내적의 한계 강조
2.1 Learning from Implicit Data
- : 유저의 수
- : 아이템의 수
- 상호작용 이고, 유저 와 아이템 사이 상호작용은 아래와 같이 표현

- 위 값이 1일 때 즉, interaction이 관측되었을 때 유저 가 아이템 를 좋아한다는 것은 아님
- 그저 유저 의 noisy preference(단순한 흥미)만을 알 수 있음
- 위 값이 0일 때 즉, interaction이 관측되지 않았을 때는 단지 missing data 취급
- 0을 부정적 반응이라고 확정하지 않았으니 negative feedback의 자연스러운 부족이 존재
- implicit feedback에 대한 추천 문제는 관측되지 않은 의 점수를 추정하는 문제로 이어짐
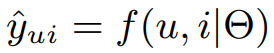
: 에 대한 추정 값
: model parameter
: model parameter를 예측 값으로 mapping
- 를 추정하기 위해서는 objective function(pointwise loss, pairwise loss)을 최적화 함
- pointwise loss: , 사이 squared loss를 최소화
(관측되지 않은 것은 부정적이라고 해석) - pairwise loss: , 사이 margin을 최대화
(관측된 것의 순위가 관측되지 않은 것의 순위보다 높음, BPR, )
(예시) Bayesian Personalized Ranking(BPR), margin-based loss
- pointwise loss: , 사이 squared loss를 최소화
- NCF는 interaction function 를 매개변수화, 이는 pointwise와 pairwise 학습을 모두 지원
2.2 Matrix Factorization
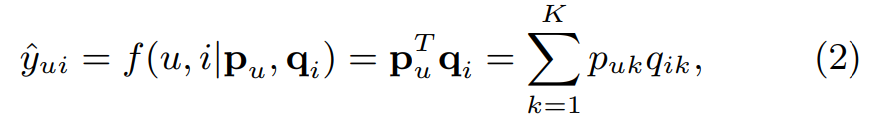
: 유저 에 대한 latent vector
: 아이템 에 대한 latent vector
: dimesion of the latent space
- MF는 interaction을 , 의 내적으로 구함
- MF는 latent factor의 선형 모델이라고 볼 수 있음
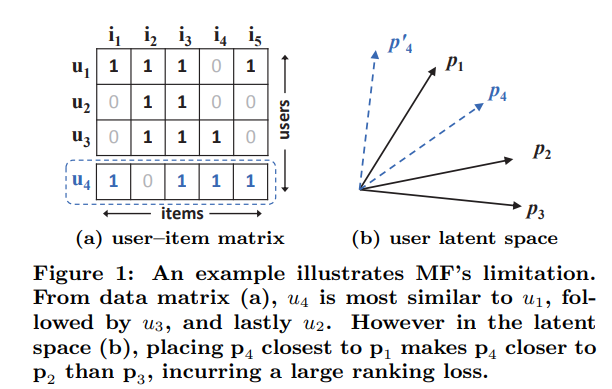
- 위 그림에서 내적 함수가 MF의 표현력을 제한하는 것을 볼 수 있음
- 유저 가 추가되었을 때 유저 보다 와 유사도가 큼에도 불구하고, 를 보다 에 가깝게 놓는 게 불가능
- 저차원의 latent space에서 복잡한 사용자-아이템 상호작용을 추정하기 위해 내적만을 사용하는 것은 제한적
- 어떻게 해결할까?
- 많은 latent factor를 사용해 표현력을 높이자 » 모델의 일반화에 악영향(overfitting)
- 내적을 사용하기보다 DNN을 사용하여 상호작용 함수를 학습하자
기존 CF와는 달리 interaction function 를 매개변수로 학습하여 MF(내적)의 단점을 해결하자!
3. NEURAL COLLABORATIVE FILTERING
- NCF 학습 방법 설명을 위해 일반적인 NCF Framework 설명
- implicit data의 이진 특징(0 또는 1)을 자세히 설명
- MF가 NCF에서 일반화될 수 있음을 증명
- 사용자-아이템 상호작용 학습을 위해 MLP를 사용해 NCF의 instance화 제안
3.1 General Framework
- CF의 full neural treatment를 위해 다층 표현을 하기로 함 (Figure 2)
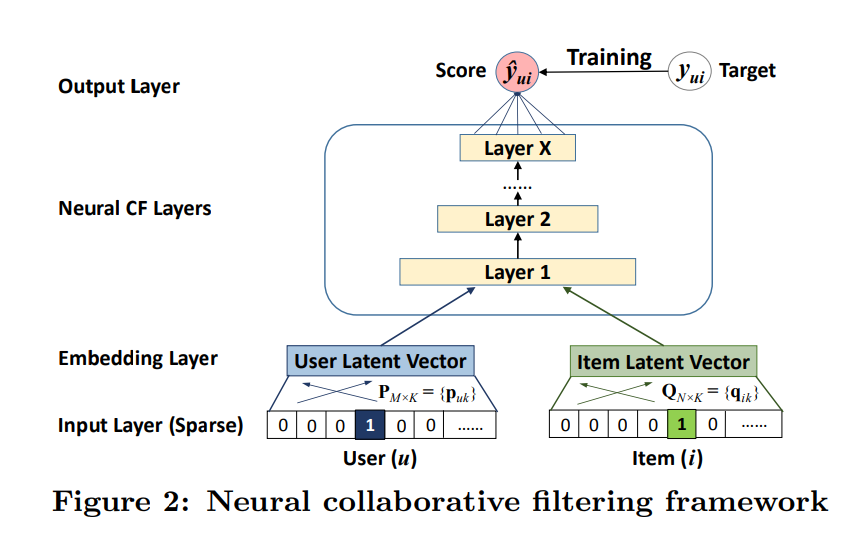
- 한 층의 output은 다음 층의 input
맨 밑의 input layer
- 유저 와 아이템 를 나타내는 vector
- 유저와 아이템의 identity만 one-hot encoding하여 생성된 sparse vector를 input
- cold start 문제를 해결(유저와 아이템을 타나내는 feature만 사용하니까 빈 데이터 고려하지 않음)
그 다음 embedding layer
- sparse vector를 dense vector로 바꾸는 fully connected layer
- 얻은 유저 및 아이템 embedding은 latent vector로 해석
- 이후 multi-layer neural architecture로 이동
neural collaborative filtering layers
- latent vector를 예측 점수로 mapping
- 각 layer는 유저-아이템 상호작용의 특정 latent 구조를 발견하도록 customize 가능
- 마지막 hidden layer는 모델의 capability 결정
끝의 Output layer
- 예측
- 훈련은 pointwise로 , 사이 squared loss를 최소화
- 다른 훈련 방식인 pairwise로 확장하는 것도 가능
neural collaborative filtering framework는 이렇게 구성되는구나
NCF 예측 모델
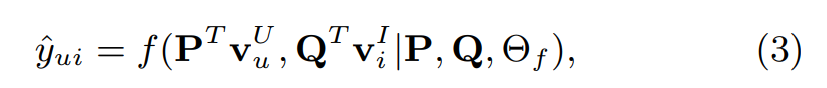
: 유저의 latent factor matrix (은 유저의 수, 는 dimesion of the latent space였음)
: 아이템의 latent factor matrix (은 아이템의 수였음)
: 상호작용 함수 의 모델 parameter
- 가 다층 신경망으로 이루어진다면 아래와 같이 공식화 가능
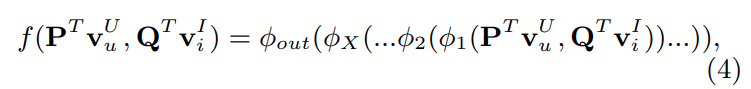
: output layer의 mapping 함수
: 번째 neural CF층의 mapping 함수 (최대 층)
3.1.1 Learning NCF
- pointwise method로 학습하는 방법은 보통 regression with squared loss
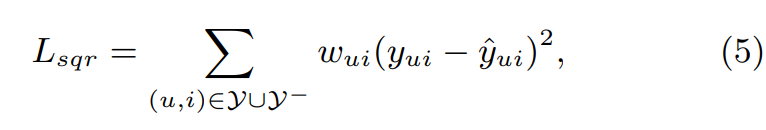
: 관측된 상호작용
: 관측되지 않은 모든 상호작용
: 훈련 instance 의 weight hyperparameter - 다만 여기서 는 implicit data의 binary(0 또는 1) 특성 때문에 squared loss 방식이 어울리지 않음
- 따라서 probabilistic 접근을 pointwise NCF에 제안
- probabilistic explanation을 NCF에 부여하려면 을 [0,1] 이내로 제한해야 함
- 여기서 1은 가 관련이 있음, 0은 관련이 없음을 의미
- output layer에서 probabilistic function을 activation function 으로 사용하면 가능
- probabilistic function의 예시로는 Logistic or Probit function
- 이제 그러면 아래와 같이 likelihood function을 정의 가능
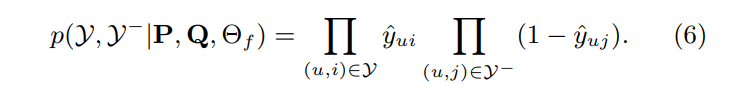
- negative logarithm을 취하면 아래와 같아짐
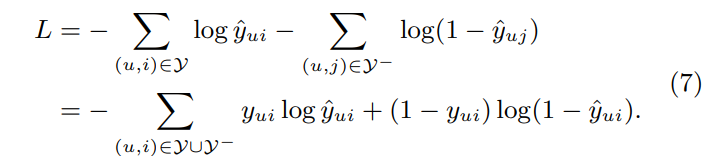
- 이는 NCF method에서 최소화해야 할 objective function (SGD 사용)
- binary cross-entropy loss(= log loss)와 동일한 모양임
- probabilistic treatment를 위해서는 implicit feedback을 binary 분류 문제로 봐야 함
- classification-aware log loss는 4.3에서 보여줄 것
- negative instance인 는 관측되지 않은 상호작용에서 각 iteration마다 uniform하게 추출할 것
- non-uniform sampling strategy에 대해서는 더 탐구해볼 가치가 있음
implicit data의 binary 특성 때문에 squared loss 방식은 어울리지 않고, 확률적인 접근을 해야 하는데, 그걸 pointwise 훈련을 하는 NCF에 어떻게 적용할까?
probabilistic function을 output layer의 activation function으로 사용하여 예측 값을 0에서 1 사이의 값으로 만들자. 이로써 implicit feedback을 binary 분류 문제(확률로 표현)로 보게 되었고, loss function도 정의 완료
3.2 Generalized Matrix Factorization (GMF)
- 이제 MF는 NCF framework의 specialization(특별한 경우)이라는 것을 보이자
- embedding된 유저 latent vector 는 로 해석
- embedding된 아이템 latent vector 는 로 해석
- mapping function을 아래와 같이 정의
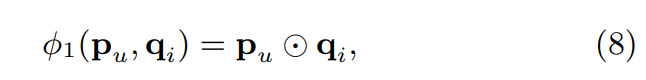
- output layer에 project 하면
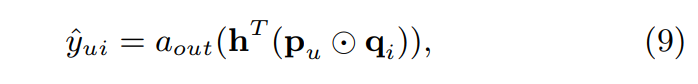
: output layer의 activation function
: output layer의 edge weights
- 위 둘을 1로 이루어진 벡터로 나타낸다면 MF 식과 같아짐
- NCF 아래에서 일반화된 MF인 Generalized Matrix Factorization(GMF)인 것
- 즉 activation function을 사용해 non-linear 성질을 더했고 (는 sigmoid 사용)
- latent dimensions의 다양한 중요성을 허용(it will result in a variant of MF that allows varying importance of latentdimensions) (는 log loss에서 학습)
NCF의 특정한 조건에서는 MF와 같이 작동하는구나. MF가 일반화되었으니 GMF라고 하는 것이구나. 그러면서 activation function에 따라 non-linear하게 표현(가능하다는 거지 무조건 non-linear 하다는 게 아님)하거나 latent dimensions을 다양하게 할 수 있게 되었다.
3.3 Multi-Layer Perceptron (MLP)
- NCF는 사용자와 아이템을 모델링하기 위해 두 경로를 채택하고, 두 경로의 features를 concatenate
- 다만 단순한 concatenate는 유저와 아이템의 latent features 사이 상호작용을 나타내지 못함
- 그래서 이를 위해 standard MLP 도입
- 사이의 상호작용 학습
- flexibility와 non-linearity 확보 가능
- NCF에서 MLP는 아래와 같이 작성
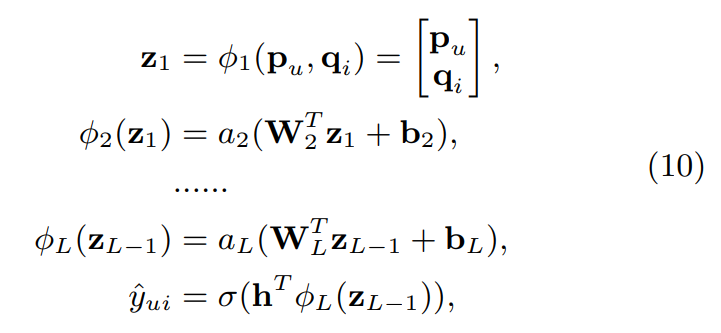
: Weight matrix
: bias vector
: 번째 layer의 activation fuction
- activation fuction은 sigmoid, tanh, ReLU 아무거나 가능
- sigmoid: (0,1)이라는 범위가 performance 제한, stop learning 문제
- tanh: rescaled version of sigmoid, 좀 더 나은 선택일 뿐
- ReLU: sparse data에 잘 맞고, overfitting 가능성이 적음 (이걸 사용할 것)
- 층의 위로 갈수록 더 적은 neuron을 사용하는데, 이는 점차 데이터의 더 추상적인 feature를 학습한다는 의미
MLP를 사용하면서 flexibility와 non-linearity 확보하였구나. 추상적인 feature를 파악하는 것도 가능해졌구나
3.4 Fusion of GMF and MLP
3.1에서 배운 NCF framework 하에서 3.2의 GMF, 3.3의 MLP를 사용했을 때의 장점을 알았으니, 어떻게 둘을 섞어서 적용할까 알아보자.
- linear kernel을 적용하여 latent feature 상호작용을 모델링하는 GMF
- non-linear kernel을 사용하여 데이터로부터 상호작용 함수를 학습하는 MLP
- 이들은 복잡한 유저-아이템 상호작용을 더 좋게 모델링하기 위해 서로 도움을 줄 수 있음
- GMF와 MLP가 같은 embedding layer를 공유하게 하고 상호작용 함수의 출력을 결합
- Neural Tensor Network (NTN)과 비슷한 방식
- GMF와 one-layer MLP를 결합하는 모델은 아래와 같음
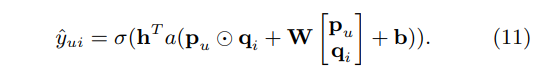
- 하지만 embeddings을 공유하는 것은 fused model의 성능을 제한하는 것
- GMF와 MLP가 동일한 크기의 embedding을 사용해야 함
- 두 모델의 최적 embedding 크기가 다른 데이터 셋이라면 최적의 ensemble을 얻지 못함
- 따라서 fused model의 유연성 확보를 위해 GMF와 MLP가 별도의 embedding 학습하고, 마지막 hidden layer를 연결해 두 모델 결합 가능(Figure 3)
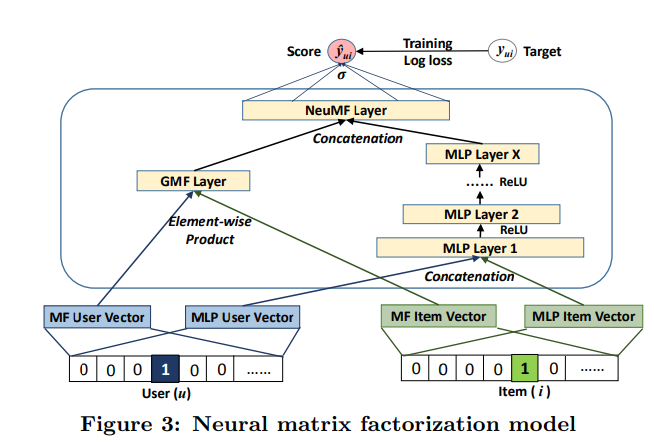
- 위 모델의 공식은 아래와 같음
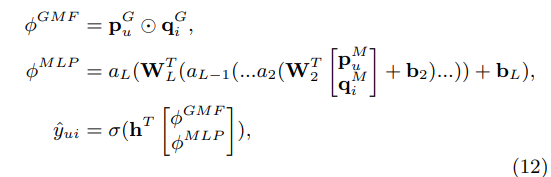
: 유저 embedding for GMF, MLP
: 아이템 embedding for GMF, MLP
- 유저-아이템 latent structures를 모델링하기 위해 MF의 선형성과 DNN의 비선형성을 결합
- 이와 같이 GMF와 MLP의 ensemble을 Neural Matrix Factorization(NeuMF)라고 함
3.4.1 Pre-training
- NeuMF objective function은 볼록하지 않아서 gradient-based optimization은 local optimal만 찾음
- 그래서 수렴과 딥러닝 성능에 중요한 역할을 하는 initialization(초기화)가 중요
- NeuMF는 GMF와 MLP의 ensemble이므로 이 둘의 사전 훈련된 모델을 사용해 초기화를 하자
- 수렴할 때까지 GMF와 MLP를 무작위 초기화하여 훈련 (Adam 사용)
- 모델 parameter를 NeuMF parameter의 해당 부분 초기화로 사용하고 훈련 (vanilla SGD 사용)
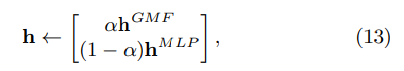
: 사전 훈련된 GMF, MLP 모델의 vector
: 둘의 trade-off를 조정하는 hyperparameter
GMF와 MLP가 별도의 embedding 학습하고, 마지막 hidden layer를 연결해 두 모델을 결합하는데, 이는 MF의 선형성과 DNN의 비선형성을 융합한 것이구나. 그리고 목적 함수의 최적화를 위해 기존 두 모델의 parameter를 초기화에 사용할 수 있구나.
4. EXPERIMENTS
- 실험은 아래 세 가지 질문에 답을 하는 방향으로 이루어짐
- RQ1 이 NCF 방식이 state-of-the-art를 능가할까?
- RQ2 제안한 최적화 framework(log loss with negative sampling)가 추천 작업에 적합한가?
- RQ3 유저-아이템 상호작용을 학습하는데 더 깊은 hidden layer(딥러닝)가 도움이 될까?
4.1 Experimental Settings
Datasets
- Datasets 1: MovieLens
- 각 유저마다 최소 20개의 평가를 한 100만 개의 평가 데이터
- explicit feedback data이지만 implicit signal of explicit feedback을 조사하기 위해 선정
- 따라서 각 평가 점수를 1또는 0으로 변환하여 평가 여부만 취함
- Datasets 2: Pinterest
- content-based 이미지 추천을 평가하기 위해 구성
- 각 유저마다 최소 20개의 pin이 있는 55,187명의 1,500,809개의 상호작용 데이터
- 상호작용은 자신의 board에 이미지 고정 여부
Evaluation Protocols
- leave-one-out evaluation 유저의 가장 최신 상호작용을 test set으로, 나머지 데이터를 training에 사용
- 상호작용이 존재하지 않는 무작위 100개의 아이템을 샘플링하여 test set의 아이템의 순위를 정하는 방식
- Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDCG)로 평가
- HR test 아이템이 상위 10개 목록에 있는지 직관적인 평가
- NDCF 상위 등수에 높은 점수를 부여하여 hit의 위치를 설명
Baselines
- NCF 방식(GMF, MLP, NeuMF)과 아래 방법들(유저-아이템 모델)을 비교
- ItemPop 상호작용의 수로 평가된 인기도에 따라 순위가 매겨짐(non-personalized
method) - ItemKNN item-based CF
- BPR MF 모델을 pairwise ranking loss로 최적화
- eALS 아이템 추천을 위한 최첨단 MF 방식, squared loss of Equation 5를 최적화
- ItemPop 상호작용의 수로 평가된 인기도에 따라 순위가 매겨짐(non-personalized
Parameter Settings
- Keras를 기반으로 제안된 방법을 구현
4.2 Performance Comparison (RQ1)
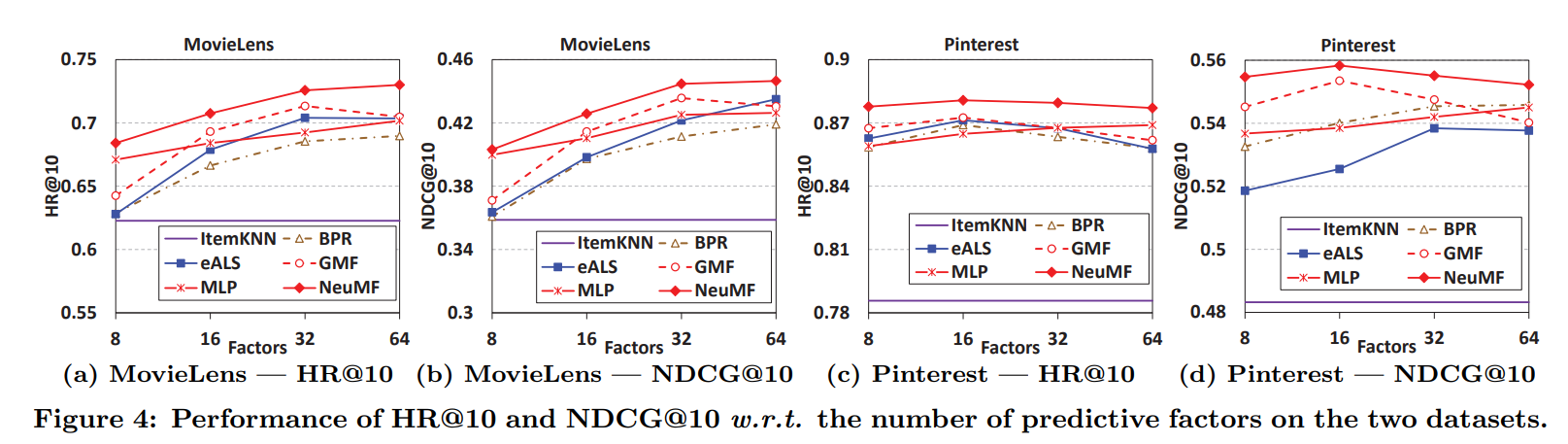
- MF 기반인 BPR과 eALS는 latent factor의 수가 predictive factors와 같음
- ItemKNN이 최고의 성능을 낼 수 있도록 parameter를 조정
- 그럼에도 ItemKNN 성능이 안 좋아서 밑에 깔린 보라색 선으로 나타남
- ItemPop은 나쁜 성능으로 인해 생략
- 예측 인자(predictive factors)에 따라 HR@10과 NDCF@10이 모델별로 어떤 차이를 보이는가 살펴보자
- NeuMF가 두 데이터 세트 모두에서 eALS 및 BPR(둘은 MF 기반)을 크게 능가
- 이는 linear MF와 non-linear MLP의 결합으로 달성한 NeuMF의 높은 표현력을 의미
- NCF 방식인 GMF, MLP도 좋은 성능을 보임(MLP < GMF)
- MLP는 hidden layer를 더 쌓아서 성능 향상의 여지 존재
- small predictive factors에서 GMF는 eALS를 능가, 이는 GMF가 large factors에서는 과적합 문제를 겪기 때문
- GMF는 BPR에 비해 일관된 improvements를 보임
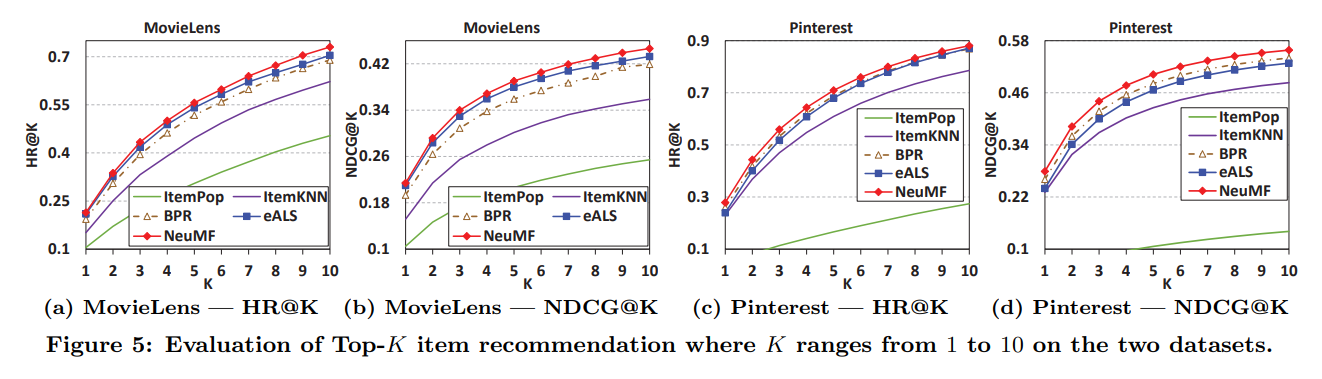
- 그림을 명확히 하기 위해 NCF 방식 중 NeuMF만 대표적으로 넣음
- K가 1부터 10까지 각각을 조사하여 Top-K 추천의 성능을 비교하자
- NeuMF는 다른 모든 방식들보다 항상 높은 성능
- MovieLens에서 eALS는 BPR보다 좋은 성능, Pinterest에서는 나쁜 성능.
- neighbor-based ItemKNN은 model-based 방식보다 나쁜 성능
- ItemPop의 최악의 성능은 유저 개인화된 추천 모델링의 필요성을 강조
RQ1 이 NCF 방식이 state-of-the-art를 능가할까?
그렇다! 특히 NeuMF는 다른 것들보다 더 좋은 성능을 냄
4.2.1 Utility of Pre-training
NeuMF에 대한 pre-training은 효과가 있었을까? 아래를 보면 효과가 있었음을 알 수 있음
- pre-training이 있는 경우와 없는 경우 두 가지 NeuMF 버전의 성능 비교
- pre-training이 없는 경우엔 Adam을 사용하여 무작위 초기화로 학습
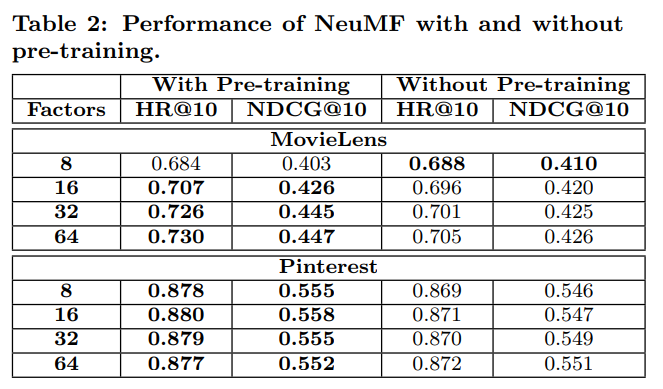
- 위에서 볼 수 있듯이, pre-training NeuMF는 대부분(Factors 8인 MovieLens 제외) 더 나은 성능
4.3 Log Loss with Negative Sampling (RQ2)
- implicit feedback의 one-class nature을 다루기 위해 추천을 binary 분류 문제로 봤음
- NCF를 probabilistic model로 보고 log loss 최적화
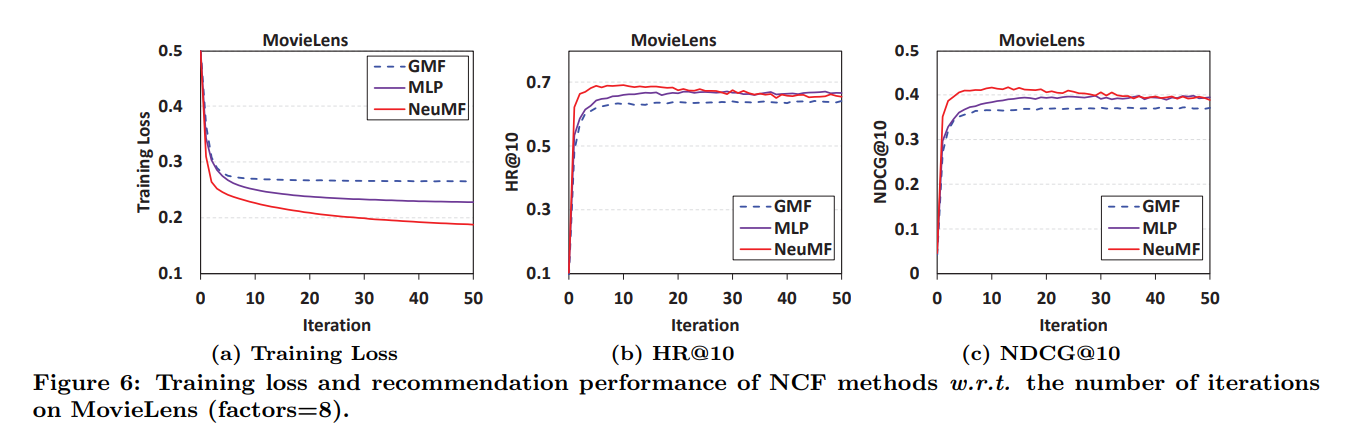
- MovieLens의 iteration마다의 NCF training loss와 추천 성능을 보여 줌
- Pinterest도 같은 경향이라 생략
- iteration이 계속될수록 NCF 모델의 training loss가 감소, 추천 성능은 향상
- 첫 10번의 iteration 동안 변화가 가장 크고, 이후 반복될수록 overfitting의 위험
- 실제로 training loss는 감소하더라도 성능 저하가 관측됨
- training loss는 NeuMF가 가장 낮아서 좋고 MLP, GMF 순으로 좋음
- 추천 성능도 NeuMF > MLP > GMF 순서
- implicit data로부터 학습할 때 log loss 최적화의 합리성과 효율성을 보여주는 실험
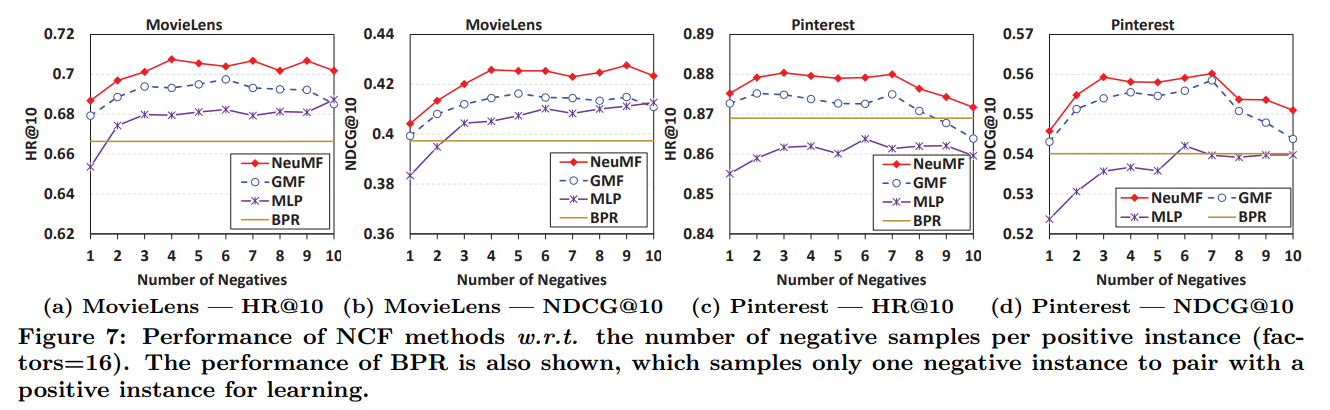
- Negatives 샘플링 비율에 따른 모델별 성능
- GMF와 BPR 비교하면 샘플링 비율 1일 때의 GMF 성능은 BPR과 비슷하지만, sampling ratio가 커지면 압도적인 성능
- pointwise log loss가 pairwise 목적 함수보다 좋은 점?
- negative instance의 유연한 sampling ratio
- pairwise에서는 positive instance 하나당 negative instance 하나끼리 짝 지음
- 이걸로는 최적의 성능을 달성하기 충분하지 않고, negative instance를 많이 샘플링 할수록 유리
RQ2 제안한 최적화 framework(log loss with negative sampling)가 추천 작업에 적합한가?
그렇다! negative instance를 많이 뽑을수록 유리한데, pointwise log loss는 유연하게 sampling ratio를 조절할 수 있어서 BPR 같은 pairwise보다 좋은 성능
4.4 Is Deep Learning Helpful? (RQ3)
- 신경망으로 유저-아이템 상호작용 함수를 학습하는 것이 도움이 되는가에 대한 문제
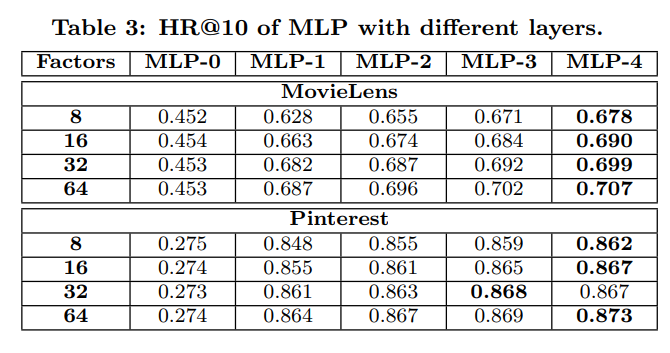
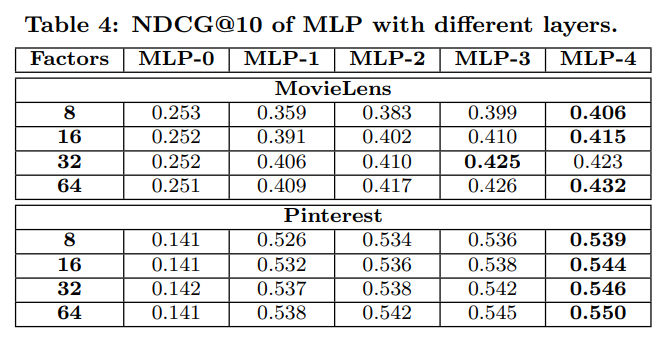
- MLP-n은 n개의 hidden layer가 있다는 의미
- hidden layer의 수가 다른 MLP를 조사하여 위 Table3, 4에 나타냄
- capability가 동일할 때 깊은 layer가 성능에 유리
- 이는 추천 시스템에 딥러닝을 사용하여 향상되는 효과를 강력히 증명
- non-linear layers를 더 많이 쌓아서 가져온 높은 non-linearities 때문
- MLP-0는 hidden layer가 없는데, 이는 개인화되지 않은 추천인 ItemPop보다 더 안 좋은 성능
- 이는 3.3에서 얘기했듯이, 유저와 아이템 latent vector를 단순히 concatenate한 것이 상호작용을 표현하기엔 부족하다는 것을 증명
- 따라서 hidden layer로 transforming하는 것은 필수적
RQ3 유저-아이템 상호작용을 학습하는데 더 깊은 hidden layer(딥러닝)가 도움이 될까?
그렇다! 깊은 layer가 높은 non-linearities를 확보하여 좋은 성능을 낸다는 것을 증명하였고, hidden layer로 transforming하여 유저와 아이템 상호작용을 더 잘 표현할 수 있다
5. RELATED WORK
- 다른 연구들의 특징을 언급
- NCF는 CDAE와 달리 two-pathway architecture를 채택하고 multilayer feedforward neural network로 유저-아이템 상호작용을 모델링
- 이는 NCF가 데이터로부터 임의의 함수를 학습할 수 있게 하고, 고정된 내적 함수보다 강력한 표현력을 가지게 함
- MF와 MLP를 결합한 NeuMF는 NTN에서 부분적으로 영감을 받았지만 MF와 MLP가 다른 embedding을 학습한다는 점에서 NTN보다 유연하고 일반적
- DNN이 사용자-아이템 상호작용 모델링을 위한 유망한 선택
6. CONCLUSION AND FUTURE WORK
- CF를 위한 neural network architecture를 탐구
- general framework NCF를 고안, GMF/MLP/NueMF 세 가지 인스턴스화(instantiations)를 제시
- 이들은 유저-아이템 상호작용을 서로 다른 방법으로 모델링
- 이 framework는 쉽고 generic하므로 이후 추천에 딥러닝을 사용할 때 guideline 역할 가능
- 따라서 CF의 shallow models을 보완하여 딥러닝 기반 추천을 위한 연구 가능성을 열음
- 미래에는 pairwise learners에 대한 연구 (여기서는 pointwise)
- 개인에 초점이 맞춰진 기존 개인화 모델을 넘어 유저 그룹에 대한 모델을 개발 가능
- 멀티미디어 추천 시스템을 구축하기 위해서는 multi-view and multi-modal data로부터 효과적인 학습 필요
