03. 경사하강법(Gradient Descent)
개념
RSS(=RMS), RMA와 같은 방법으로 우리는 회귀식이 갖는 오차를 확인할 수 있었다. 그렇다면 회귀계수들을 어떻게 최적화할 수 있을까? 방법이 바로 이번 절에서 소개할 경사하강법(Gradient Descent, 이하 GD)이다.
교재의 말을 빌리면, GD란 점진적인 반복 계산을 통해 회귀계수를 업데이트하며 오류값이 최소가 되는 회귀계수를 구하는 방법이다.
GD는 "분류분석 - GBM"에서 가볍게 다룬 적이 있다. 기억을 상기시키며 다시 한 번 GD에 대해 공부해보자.
< Gradient Descent >
GD는 오차가 최소가 되는 지점의 weight를 찾는 방법이다. wheight는 결과값에 대하여 각 feature가 갖는 가중치이다. w를 바꿔가며 모델의 오차를 측정하면 위와 같은 그림이 나온다.(실제로는 더욱 복잡한 그래프가 나오겠지만, 설명을 위해 간략히 3차 함수로 그렸다.) x축은 weight의 변화를 나타내고, y축은 weight에 따른 모델의 오차이다. GD는 다음과 같은 단계를 거치며 진행된다.
- 초기 weight로 임의의 값이 지정된다.
- 초기 weight 지점에서 미분을 한다. 미분을 하게되면 그 시점의 기울기가 나오는데, 기울기가 음수라면 양의 방향으로, 기울기가 양수라면 음의 방향으로 학습률(learning rate)만큼 이동한다.(이동한다는 의미는 weight를 업데이트 한다는 의미)
- 업데이트한 weight에서 2번 작업을 반복해서 수행한다. 수행이 완료되는 시점은 기울기가 0이 되는 시점이다. 왜냐하면 기울기가 0이라는 것은 모델이 가질 수 있는 최소한의 오차를 뜻하기 때문이다.(모든 ML 모델은 오차가 0일 수 없음)
(GD를 수식으로 표현한 부분은 과감히 생략)
이렇게 똑똑하게도 손실함수가 최소가 되는 회귀계수를 찾아가는 GD에도 단점이 있다. GD는 모든 학습 데이터를 대상으로 하나하나 업데이트 하기 때문에 수행시간이 오래 걸린다. 따라서 실제로는 결과가 다소 부정확하더라도 경사하강법이 아닌 확률적 경사하강법(Stochastic gradient descent) 이나, 미니 배치 확률적 경사하강법(Mini-batch stochastic gradient descent) 가 많이 사용된다.
optimizer의 종류
사실 Gradient Descent 종류와 발전 방향을 이야기 하기에는 그 양이 너무도 방대하고 깊이도 깊어 전부 소개할 수는 없을 것 같다.(optimizer는 모델의 중요한 한 부분이므로 내용이 너무 많다,,,) 따라서 를 업데이트 하는 방법인 optimzer의 종류를 간단하게만 살펴보면 좋겠다.
gradient descent의 한계
optimizer는 GD에 기반들 두고 있으며 를 업데이트 하는 방법이다. optimizer가 발전하게 된 이유는 아래와 같다.
1. 앞서 잠깐 언급한 대로 GD는 모든 데이터를 하나하나 확인하므로 시간이 매우 오래 걸린다.
2. 모든 데이터를 하나하나 확인하므로 데이터셋 크기에 따라 메모리가 부족할 수 있다.
3. 학습율에 따라 그 결과가 오히려 발산을 할 수도 있다.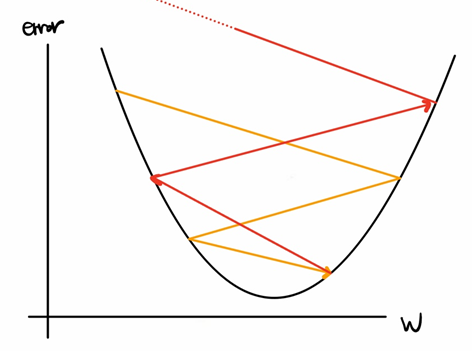
- 학습율이 너무 크게 설정되어있다면 노란색 화살표를 따라 업데이트 하다가 최소 지점에 도달하지 못하고 빨간색 화살표처럼 발산을 하게 될 수도 있다.
- 반대로 학습율이 너무 작게 설정되어있다면, 발산하는 문제는 없겠지만 시간이 더 훨씬 더 오래 걸린다.(작은 보폭으로 걸어가면 목적지에 다다르기까지 여러번 발을 내딛어야하고 시간이 오래 걸리는 것처럼 말이다.)
- 지역 최소점(local minima)에 빠질 수 있다.
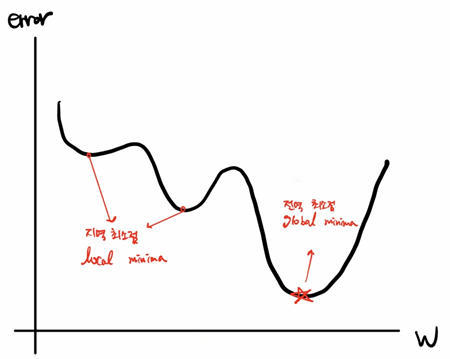
- 모델의 오차를 측정해보면 위와 같이 기울기가 0이 되는 지점이 여러번 있다. 그런데 GD의 기준(미분 값이 0, 오차가 작아지는 방향)만으로는 지역 최소점에 빠질 수도 있다.
위와 같은 이유 때문에 나온 방법이 확률적 경사하강법(stochastic gradient descent)이다.
확률적 경사하강법 - SGD(Stochastic gradient descent)
SGD는 모든 데이터를 사용하여 를 업데이트하는 GD와 달리 일부 데이터만을 사용한다.(정확히 말하자면 한 건의 데이터) 랜덤으로 하나의 데이터를 뽑아 오차를 측정하고 를 업데이터한다. 따라서 GD보다 훨씬 빠르지만, 한 개의 데이터만 오차를 측정하는 만큼 GD보다는 덜 정확하다.
하나의 데이터가 아니라 일정한 배치만큼 한 step에 사용하는 것은 미니배치 확률적 경사하강법이다. 배치의 크기는 지정이 가능하다.(step은 를 한 번 업데이트 하는 것을 의미한다.)
SGD는 속도가 느리다는 단점은 보완 했지만, 여전히 학습율과 지역최소점 문제는 해결하지 못했다. 그리고 또 하나의 단점이 생겼는데, 학습에 편차가 크다는 점이다. 랜덤하게 데이터를 추출하여 오차를 측정하므로 step별로 편차가 크다.
모멘텀(Momenturm)
모멘텀은 SGD의 큰 학습 편차를 줄이기 위해 만들어졌다. 업데이트에 가속도를 부여한다는 아이디어인데, 오차의 최저 지점에서 멀 때에는 빠른 속도로(를 큰 폭으로 업데이트), 최저 지점에 가까울 때에는 조금 더 천천히(를 작은 폭으로 업데이트) 하는 방법이다.
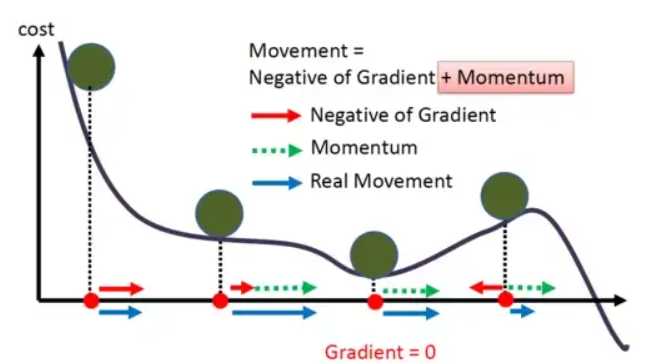 위 그림은 모멘텀의 학습 과정을 그림으로 나타낸 것이다.
위 그림은 모멘텀의 학습 과정을 그림으로 나타낸 것이다.
아다그라드(Adagrad)
앞서 나온 optimizer의 한계점은 모든 step과 모든 feature에 대한 학습율이 동일하다는 것이다. 따라서 각 step마다, feature마다 학습율이 달라지는 optimizer인 아다그라드가 개발되었다.
아다그라드는 '지금까지 변화가 많았던 변수는 조금 더 세밀하게 를 조정하고, 변화가 적었던 변수는 를 크게 조정한다'라는 아이디어이다.
optimizer는 사실 머신러닝보다 딥러닝을 할 때 더 중요하고 자세히 다룬다. 따라서 이번 책에서는 여기까지만 다루고, 기회가 된다면 조금 더 자세하게 공부해보자.
< 출처 >
