K-Means 알고리즘은 군집화에서 일반적으로 사용되는 기법이다. K-Means는 임의의 중심점을 잡고, 그 주변에 가까운 데이터를 하나의 군집으로 선정하는 방법이다. K-Means가 동작하는 원리는 아래와 같다.
[ K-Means 동작 원리 ]
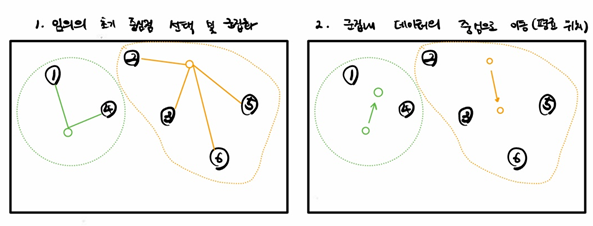
1. 임의의 중심점 선정하고 해당 위치에서 가까운 데이터들을 하나의 군집으로 군집화
2. 군집으로 선택된 데이터들의 평균 위치로 중심점 이동
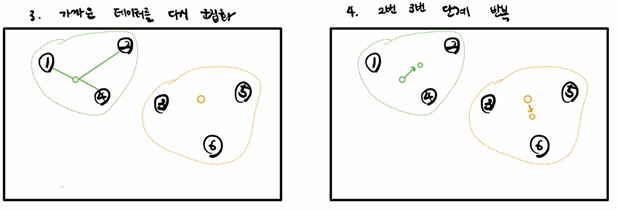
3. 이동한 위치에서 다시 가까운 데이터들을 하나의 군집으로 군집화
4. 중심점이 더 이상 이동하지 않을 때까지 앞선 단계 반복
K-Means 알고리즘은 쉽고 간결하다는 장점을 가진다. 하지만 거리에 기반을 둔 알고리즘이기 때문에 feature의 개수가 늘어나면 수행 속도가 매우 느려진다.(feature가 늘어나면 그 만큼 수행해야 하는 연산이 많아지기 때문) 또한 군집의 개수가 하이퍼 파라미터이고 가장 중요한 파라미터인데 몇 개의 군집이 최적의 개수인지 선택하는 것도 어렵다는 단점이 있다.
K-Means는 skleanrn.cluster 모듈에 KMeans 클래스로 구현되어있다.
from sklearn.cluster import KMeans
kmeans = KMeans(n_cluster=5, init='k-means++', max_iter=100)
kmeans.fit(data)K-Means의 주요 하이퍼 파라미터는 아래와 같다.
- n_cluster : 앞서 언급한 것처럼 군집의 개수가 가장 중요한 하이퍼퍼라미터이다.
- init : 초기 중심점 선정 방법을 선택한다. k-means++, random 중 선택할 수 있으며 default는 k-means++이다.
- k-means++ : '경험적 확률 분포'에 의해 데이터 샘플링을 하여 초기 중심점을 선택한다. 알고리즘 수행 속도를 높일 수 있다.
- random : 초기 중심점을 무작위로 선택한다.
- max_iter : 최대 반복 횟수를 의미한다. 최대 반복 횟수에 다다르기 전 최적의 중심점이 선정 되었으면(=중심점의 이동이 없다면) 반복을 종료한다.
K-Means의 주요 속성은 아래와 같다.
- labels_ : 각 데이터가 속한 군집의 라벨값 반환
- clustercenters : 각 군집의 중심점 좌표 반환(시각화에 쓰임)
