실루엣 분석
intro
머신러닝 모델을 만드는 이유는 현실에서 데이터를 정확히 처리하기 위함이다. 따라서 모델을 만들 때에는 항상 평가할 수 있는 수단이 필요하다.
정답 값이 명확한 지도학습의 경우 모델이 예측한 결과와 정답 값을 비교하면 쉽게 모델의 성능을 측정할 수 있지만, 비지도학습은 정답 값이 없기 때문에 어떻게 성능을 측정할 수 있을지 의문이 든다. 그렇다면, 비지도학습의 대표 주자인 군집분석 알고리즘을 평가할 수 있는 방법인 실루엣 분석을 알아보자
개요
실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지를 나타낸다. 조금 더 자세히 말하자면 얼마나 군집 내부의 데이터는 잘 뭉쳐 있고, 다른 군집의 데이터끼리는 먼 거리를 유지하는가에 대한 평가이다. 실루엣 분석의 과정은 아래와 같다.
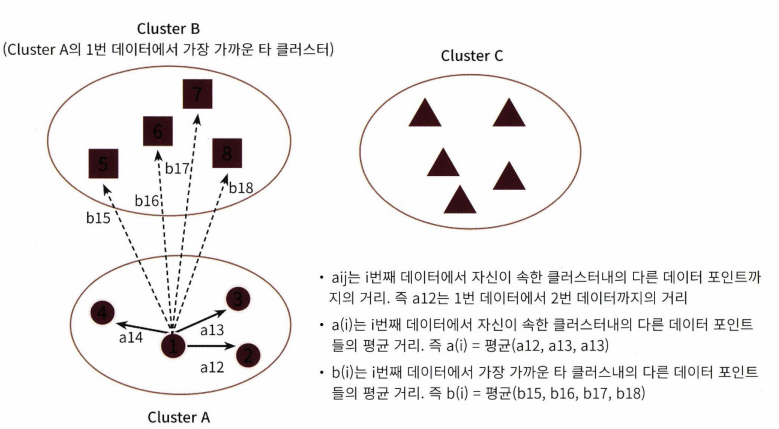 1. 각 데이터마다 같은 군집에 속한 데이터의 거리와 자신의 군집과 가장 가까운 군집에 속한 데이터의 거리를 구한다.
1. 각 데이터마다 같은 군집에 속한 데이터의 거리와 자신의 군집과 가장 가까운 군집에 속한 데이터의 거리를 구한다.
- 위의 예에서 군집 A와 가장 가까운 군집은 B이므로, 군집 A의 데이터 거리를 계산할 때 B와의 거리만을 구한 것(군집 C가 계산에서 제외된 이유)
- 자신의 군집에 속한 데이터끼리의 평균 거리를 라고 하고, 인접한 군집의 데이터와 평균 거리를 라고 한다. 아래 식을 통해 실루엣 계수 를 구한다. 와 중 최대값으로 나누는 이유는 정규화를 위함이다.
실루엣 계수는 자신의 군집 내 데이터 거리와 타 군집 내 데이터 거리의 비율을 의미하며 계산 결과로는 -1 ~ 1 사이의 값이 나온다. 1로 가까워질 수록 좋은 성능을 기대할 수 있다.(실루엣 계수가 높다고 언제나 좋은 성능을 가지는 것은 아니다. )
- : 인접 군집과의 거리가 멀다
- : 인접 군집과의 거리가 가깝다.
- : 군집화가 제대로 이루어지지 않았다.
sklearn에서 실루엣 분석을 하기 위해 sklearn.metrics모듈의 silhouette_samples와 silhouette_score를 사용하면 된다.
silhouette_samples는 각 데이터 포인트마다의 실루엣 계수를 반환하고, silhouette_score는 전체 실루엣 계수의 평균을 반환한다. 인자로는 두 클래스 모두 군집화가 필요한 feature들과 군집화 결과 label이 들어간다.
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
# 군집화 알고리즘 객체 생성
kmeans = KMeans(n_cluster=5, init='k-means++', max_iter=100)
kmeans.fit(data)
# 개별 실루엣 계수 구하기
samples_score = silhouette_samples(data, kmeans.labels_)
# 평균 실루엣 계수 구하기
average_score = silhouette_score(data, kmeans.labels_시각화를 통한 최적의 군집 개수 선정
전체 데이터의 평균 실루엣 계수가 높다고 하여 군집화가 잘 이루어진 것은 아닐 수 있다. 한 군집의 실루엣 계수가 굉장히 높고(= 한 군집만 잘 군집화 하고) 다른 군집의 실루엣 계수는 낮을 수 있기 때문이다.(= 다른 군집은 군집화가 잘 이루어지지 않음) 아래 내용은 sklearn 공식 문서 중 silhouette_score에 대한 예제이다.(링크 참고)
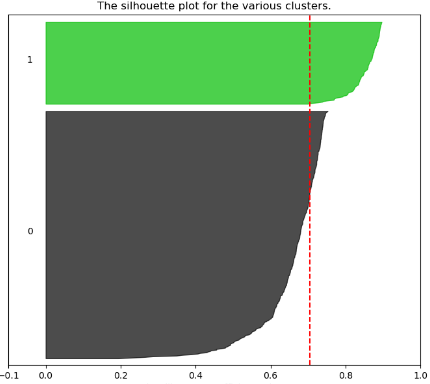 x축은 실루엣 계수를 나타내고, y축은 데이터가 속한 군집의 label을 나타낸다. y축에 평행한 빨간색 점선은 전체 평균 실루엣 계수이다.
x축은 실루엣 계수를 나타내고, y축은 데이터가 속한 군집의 label을 나타낸다. y축에 평행한 빨간색 점선은 전체 평균 실루엣 계수이다.

 군집이 2 개일 때 실루엣 계수가 제일 높다. 그런데 0번 라벨로 분류된 데이터는 대부분이 평균 값보다 작다.(1번 라벨로 분류된 데이터가 압도적으로 높은 수치를 기록해 평균이 커짐) 따라서 군집이 2개인 것은 제대로 군집화를 하지 못하고 있다고 판단할 수 있다. 군집이 3개일 때도 대부분의 데이터가 평균 값에 다다르지 못하고 있다.
군집이 2 개일 때 실루엣 계수가 제일 높다. 그런데 0번 라벨로 분류된 데이터는 대부분이 평균 값보다 작다.(1번 라벨로 분류된 데이터가 압도적으로 높은 수치를 기록해 평균이 커짐) 따라서 군집이 2개인 것은 제대로 군집화를 하지 못하고 있다고 판단할 수 있다. 군집이 3개일 때도 대부분의 데이터가 평균 값에 다다르지 못하고 있다.
군집이 4개일 때에는 어떨까? 군집이 4개일 때에는 대부분의 데이터가 평균 값보다 큰 값을 가진다.(일부 데이터만이 평균보다 작음) 따라서 평균 실루엣 값이 상대적으로 작지만, 더 효과적으로 군집을 분리할 수도 있으니 실루엣 계수를 절대적인 평가 지표로 생각하지는 말자!
