이 글은 CloudNet@팀의 AWS EKS Workshop Study(AEWS) 3기 스터디 내용을 바탕으로 작성되었습니다.
AEWS는 CloudNet@의 '가시다'님께서 진행하는 스터디로, EKS를 학습하는 과정입니다.
EKS를 깊이 있게 이해할 기회를 주시고, 소중한 지식을 나눠주시는 가시다님께 다시 한번 감사드립니다.
이 글이 EKS를 학습하는 분들께 도움이 되길 바랍니다.
Amazon EKS, AI 인스턴스(GPU 등) 기반 실습을 수행하기 위해 다음과 같은 사전 환경 구성이 필요합니다.
0. 실습 환경 구성
0.1 Quota 확보
실습을 원활히 진행하기 위해서는 EC2 인스턴스 관련 Quota(할당량) 확보가 선행되어야 합니다.
1. Quota 신청 절차
AWS에서는 기본적으로 GPU 및 AI 가속 인스턴스에 대해 낮은 수준의 할당량이 설정되어 있습니다. 실습 환경을 구성하기 위해 다음과 같이 할당량을 증가시켜야 합니다.
- 신청 URL (us-west-2 리전 기준)
https://us-west-2.console.aws.amazon.com/servicequotas/home/services/ec2/quotas
2. 신청 항목 예시
아래 예시를 참고하여 필요한 인스턴스 유형에 대해 신청을 진행합니다.
- G 인스턴스 (예: G4dn, G5 등)
- 검색어:
on-demand G - 항목 선택: Running On-Demand G and VT instances
- 요청 절차:
- 항목 선택 후 Request increase at account level 클릭
- vCPU 수량 입력 (예: 64)
- 요청 제출 (Request 버튼 클릭)
- 검색어:
📌 참고: 지원되는 G 인스턴스 타입 및 사양은 아래 URL에서 확인 가능합니다
https://aws.amazon.com/ko/ec2/instance-types/#Accelerated_Computing
3. 신청 결과 확인
할당량 증가 요청 후, AWS에서 아래와 같은 형식의 확인 이메일을 수신하게 됩니다.
- 제목: Your Service Quotas request was successfully submitted / approved
- 본문: 요청한 인스턴스 타입 및 할당량 증가 내역 명시


0.2 로컬 환경 도구 설치
실습을 원활하게 진행하려면 다음과 같은 CLI 및 도구들이 로컬 환경에 설치되어 있어야 합니다.
| 도구 | 설명 | 설치 링크 |
|---|---|---|
| eksdemo | Amazon EKS 클러스터 및 워크로드를 빠르게 데모 및 학습할 수 있도록 도와주는 도구 | 설치 가이드 |
| helm | Kubernetes용 패키지 관리자. 애플리케이션 배포 및 관리를 간편하게 도와줍니다 | 설치 가이드 |
| AWS CLI | AWS 리소스를 명령어로 제어하기 위한 공식 CLI 도구 | 설치 가이드 |
| kubectl | Kubernetes 클러스터와 상호작용하기 위한 명령줄 도구 | 설치 가이드 |
| jq | JSON 데이터를 필터링하고 가공할 수 있는 커맨드라인 유틸리티 | 설치 가이드 |
| Terraform | 인프라를 코드로 관리할 수 있는 IaC(Infrastructure as Code) 도구 | docs |
1. 컨테이너 환경에서의 GPU 리소스 사용 (단일 GPU) - GPU Time-slicing on Amazon EKS 실습
Amazon EKS 상에서 NVIDIA GPU Time-slicing 기능을 활용한 실습입니다. 이 실습은 AWS 공식 블로그의 가이드를 기반으로 구성되었습니다.
Amazon EKS와 NVIDIA GPU를 활용하여 GPU 자원을 효율적으로 공유하는 실습을 위해 eksdemo CLI 도구를 이용하여 클러스터를 생성합니다. 이 과정에서는 먼저 GPU를 사용하지 않는 기본 클러스터를 생성하고, 이후 GPU 노드 그룹을 추가할 계획입니다.
1.1 클러스터 구성
1.1.1 Dry-run을 통한 클러스터 구성 미리보기
사전 점검을 위해 eksdemo CLI를 이용한 dry-run 명령어를 실행합니다. 이 명령어는 실제 클러스터를 생성하지 않고, 생성될 리소스 구성을 YAML로 출력합니다.
$ eksdemo create cluster gpusharing-demo -i t3.large -N 2 --region us-west-2 --dry-run
Eksctl Resource Manager Dry Run:
eksctl create cluster -f -
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: gpusharing-demo
region: us-west-2
version: "1.32"
tags:
eksdemo.io/version: 0.18.2
addons:
- name: vpc-cni
version: latest
configurationValues: |-
enableNetworkPolicy: "true"
env:
ENABLE_PREFIX_DELEGATION: "false"
cloudWatch:
clusterLogging:
enableTypes: ["*"]
iam:
withOIDC: true
serviceAccounts:
- metadata:
name: aws-load-balancer-controller
namespace: awslb
roleName: eksdemo.us-west-2.gpusharing-demo.awslb.aws-load-balanc-e4dab3bd
roleOnly: true
attachPolicy:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- iam:CreateServiceLinkedRole
Resource: "*"
Condition:
StringEquals:
iam:AWSServiceName: elasticloadbalancing.amazonaws.com
- Effect: Allow
Action:
- ec2:DescribeAccountAttributes
- ec2:DescribeAddresses
- ec2:DescribeAvailabilityZones
- ec2:DescribeInternetGateways
- ec2:DescribeVpcs
- ec2:DescribeVpcPeeringConnections
- ec2:DescribeSubnets
- ec2:DescribeSecurityGroups
- ec2:DescribeInstances
- ec2:DescribeNetworkInterfaces
- ec2:DescribeTags
- ec2:GetCoipPoolUsage
- ec2:DescribeCoipPools
- elasticloadbalancing:DescribeLoadBalancers
- elasticloadbalancing:DescribeLoadBalancerAttributes
- elasticloadbalancing:DescribeListeners
- elasticloadbalancing:DescribeListenerCertificates
- elasticloadbalancing:DescribeSSLPolicies
- elasticloadbalancing:DescribeRules
- elasticloadbalancing:DescribeTargetGroups
- elasticloadbalancing:DescribeTargetGroupAttributes
- elasticloadbalancing:DescribeTargetHealth
- elasticloadbalancing:DescribeTags
- elasticloadbalancing:DescribeTrustStores
- elasticloadbalancing:DescribeListenerAttributes
Resource: "*"
- Effect: Allow
Action:
- cognito-idp:DescribeUserPoolClient
- acm:ListCertificates
- acm:DescribeCertificate
- iam:ListServerCertificates
- iam:GetServerCertificate
- waf-regional:GetWebACL
- waf-regional:GetWebACLForResource
- waf-regional:AssociateWebACL
- waf-regional:DisassociateWebACL
- wafv2:GetWebACL
- wafv2:GetWebACLForResource
- wafv2:AssociateWebACL
- wafv2:DisassociateWebACL
- shield:GetSubscriptionState
- shield:DescribeProtection
- shield:CreateProtection
- shield:DeleteProtection
Resource: "*"
- Effect: Allow
Action:
- ec2:AuthorizeSecurityGroupIngress
- ec2:RevokeSecurityGroupIngress
Resource: "*"
- Effect: Allow
Action:
- ec2:CreateSecurityGroup
Resource: "*"
- Effect: Allow
Action:
- ec2:CreateTags
Resource: arn:aws:ec2:*:*:security-group/*
Condition:
StringEquals:
ec2:CreateAction: CreateSecurityGroup
'Null':
aws:RequestTag/elbv2.k8s.aws/cluster: 'false'
- Effect: Allow
Action:
- ec2:CreateTags
- ec2:DeleteTags
Resource: arn:aws:ec2:*:*:security-group/*
Condition:
'Null':
aws:RequestTag/elbv2.k8s.aws/cluster: 'true'
aws:ResourceTag/elbv2.k8s.aws/cluster: 'false'
- Effect: Allow
Action:
- ec2:AuthorizeSecurityGroupIngress
- ec2:RevokeSecurityGroupIngress
- ec2:DeleteSecurityGroup
Resource: "*"
Condition:
'Null':
aws:ResourceTag/elbv2.k8s.aws/cluster: 'false'
- Effect: Allow
Action:
- elasticloadbalancing:CreateLoadBalancer
- elasticloadbalancing:CreateTargetGroup
Resource: "*"
Condition:
'Null':
aws:RequestTag/elbv2.k8s.aws/cluster: 'false'
- Effect: Allow
Action:
- elasticloadbalancing:CreateListener
- elasticloadbalancing:DeleteListener
- elasticloadbalancing:CreateRule
- elasticloadbalancing:DeleteRule
Resource: "*"
- Effect: Allow
Action:
- elasticloadbalancing:AddTags
- elasticloadbalancing:RemoveTags
Resource:
- arn:aws:elasticloadbalancing:*:*:targetgroup/*/*
- arn:aws:elasticloadbalancing:*:*:loadbalancer/net/*/*
- arn:aws:elasticloadbalancing:*:*:loadbalancer/app/*/*
Condition:
'Null':
aws:RequestTag/elbv2.k8s.aws/cluster: 'true'
aws:ResourceTag/elbv2.k8s.aws/cluster: 'false'
- Effect: Allow
Action:
- elasticloadbalancing:AddTags
- elasticloadbalancing:RemoveTags
Resource:
- arn:aws:elasticloadbalancing:*:*:listener/net/*/*/*
- arn:aws:elasticloadbalancing:*:*:listener/app/*/*/*
- arn:aws:elasticloadbalancing:*:*:listener-rule/net/*/*/*
- arn:aws:elasticloadbalancing:*:*:listener-rule/app/*/*/*
- Effect: Allow
Action:
- elasticloadbalancing:ModifyLoadBalancerAttributes
- elasticloadbalancing:SetIpAddressType
- elasticloadbalancing:SetSecurityGroups
- elasticloadbalancing:SetSubnets
- elasticloadbalancing:DeleteLoadBalancer
- elasticloadbalancing:ModifyTargetGroup
- elasticloadbalancing:ModifyTargetGroupAttributes
- elasticloadbalancing:DeleteTargetGroup
- elasticloadbalancing:ModifyListenerAttributes
Resource: "*"
Condition:
'Null':
aws:ResourceTag/elbv2.k8s.aws/cluster: 'false'
- Effect: Allow
Action:
- elasticloadbalancing:AddTags
Resource:
- arn:aws:elasticloadbalancing:*:*:targetgroup/*/*
- arn:aws:elasticloadbalancing:*:*:loadbalancer/net/*/*
- arn:aws:elasticloadbalancing:*:*:loadbalancer/app/*/*
Condition:
StringEquals:
elasticloadbalancing:CreateAction:
- CreateTargetGroup
- CreateLoadBalancer
'Null':
aws:RequestTag/elbv2.k8s.aws/cluster: 'false'
- Effect: Allow
Action:
- elasticloadbalancing:RegisterTargets
- elasticloadbalancing:DeregisterTargets
Resource: arn:aws:elasticloadbalancing:*:*:targetgroup/*/*
- Effect: Allow
Action:
- elasticloadbalancing:SetWebAcl
- elasticloadbalancing:ModifyListener
- elasticloadbalancing:AddListenerCertificates
- elasticloadbalancing:RemoveListenerCertificates
- elasticloadbalancing:ModifyRule
Resource: "*"
- metadata:
name: ebs-csi-controller-sa
namespace: kube-system
roleName: eksdemo.us-west-2.gpusharing-demo.kube-system.ebs-csi-c-937ae3a3
roleOnly: true
attachPolicyARNs:
- arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy
- metadata:
name: external-dns
namespace: external-dns
roleName: eksdemo.us-west-2.gpusharing-demo.external-dns.external-dns
roleOnly: true
attachPolicy:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- route53:ChangeResourceRecordSets
Resource:
- arn:aws:route53:::hostedzone/*
- Effect: Allow
Action:
- route53:ListHostedZones
- route53:ListResourceRecordSets
- route53:ListTagsForResource
Resource:
- "*"
- metadata:
name: karpenter
namespace: karpenter
roleName: eksdemo.us-west-2.gpusharing-demo.karpenter.karpenter
roleOnly: true
attachPolicy:
Version: "2012-10-17"
Statement:
- Sid: AllowScopedEC2InstanceAccessActions
Effect: Allow
Resource:
- arn:aws:ec2:us-west-2::image/*
- arn:aws:ec2:us-west-2::snapshot/*
- arn:aws:ec2:us-west-2:*:security-group/*
- arn:aws:ec2:us-west-2:*:subnet/*
Action:
- ec2:RunInstances
- ec2:CreateFleet
- Sid: AllowScopedEC2LaunchTemplateAccessActions
Effect: Allow
Resource: arn:aws:ec2:us-west-2:*:launch-template/*
Action:
- ec2:RunInstances
- ec2:CreateFleet
Condition:
StringEquals:
aws:ResourceTag/kubernetes.io/cluster/gpusharing-demo: owned
StringLike:
aws:ResourceTag/karpenter.sh/nodepool: "*"
- Sid: AllowScopedEC2InstanceActionsWithTags
Effect: Allow
Resource:
- arn:aws:ec2:us-west-2:*:fleet/*
- arn:aws:ec2:us-west-2:*:instance/*
- arn:aws:ec2:us-west-2:*:volume/*
- arn:aws:ec2:us-west-2:*:network-interface/*
- arn:aws:ec2:us-west-2:*:launch-template/*
- arn:aws:ec2:us-west-2:*:spot-instances-request/*
Action:
- ec2:RunInstances
- ec2:CreateFleet
- ec2:CreateLaunchTemplate
Condition:
StringEquals:
aws:RequestTag/kubernetes.io/cluster/gpusharing-demo: owned
aws:RequestTag/eks:eks-cluster-name: gpusharing-demo
StringLike:
aws:RequestTag/karpenter.sh/nodepool: "*"
- Sid: AllowScopedResourceCreationTagging
Effect: Allow
Resource:
- arn:aws:ec2:us-west-2:*:fleet/*
- arn:aws:ec2:us-west-2:*:instance/*
- arn:aws:ec2:us-west-2:*:volume/*
- arn:aws:ec2:us-west-2:*:network-interface/*
- arn:aws:ec2:us-west-2:*:launch-template/*
- arn:aws:ec2:us-west-2:*:spot-instances-request/*
Action: ec2:CreateTags
Condition:
StringEquals:
aws:RequestTag/kubernetes.io/cluster/gpusharing-demo: owned
aws:RequestTag/eks:eks-cluster-name: gpusharing-demo
ec2:CreateAction:
- RunInstances
- CreateFleet
- CreateLaunchTemplate
StringLike:
aws:RequestTag/karpenter.sh/nodepool: "*"
- Sid: AllowScopedResourceTagging
Effect: Allow
Resource: arn:aws:ec2:us-west-2:*:instance/*
Action: ec2:CreateTags
Condition:
StringEquals:
aws:ResourceTag/kubernetes.io/cluster/gpusharing-demo: owned
StringLike:
aws:ResourceTag/karpenter.sh/nodepool: "*"
StringEqualsIfExists:
aws:RequestTag/eks:eks-cluster-name: gpusharing-demo
ForAllValues:StringEquals:
aws:TagKeys:
- eks:eks-cluster-name
- karpenter.sh/nodeclaim
- Name
- Sid: AllowScopedDeletion
Effect: Allow
Resource:
- arn:aws:ec2:us-west-2:*:instance/*
- arn:aws:ec2:us-west-2:*:launch-template/*
Action:
- ec2:TerminateInstances
- ec2:DeleteLaunchTemplate
Condition:
StringEquals:
aws:ResourceTag/kubernetes.io/cluster/gpusharing-demo: owned
StringLike:
aws:ResourceTag/karpenter.sh/nodepool: "*"
- Sid: AllowRegionalReadActions
Effect: Allow
Resource: "*"
Action:
- ec2:DescribeImages
- ec2:DescribeInstances
- ec2:DescribeInstanceTypeOfferings
- ec2:DescribeInstanceTypes
- ec2:DescribeLaunchTemplates
- ec2:DescribeSecurityGroups
- ec2:DescribeSpotPriceHistory
- ec2:DescribeSubnets
Condition:
StringEquals:
aws:RequestedRegion: "us-west-2"
- Sid: AllowSSMReadActions
Effect: Allow
Resource: arn:aws:ssm:us-west-2::parameter/aws/service/*
Action:
- ssm:GetParameter
- Sid: AllowPricingReadActions
Effect: Allow
Resource: "*"
Action:
- pricing:GetProducts
- Sid: AllowInterruptionQueueActions
Effect: Allow
Resource: arn:aws:sqs:us-west-2:767397897074:karpenter-gpusharing-demo
Action:
- sqs:DeleteMessage
- sqs:GetQueueUrl
- sqs:ReceiveMessage
- Sid: AllowPassingInstanceRole
Effect: Allow
Resource: arn:aws:iam::767397897074:role/KarpenterNodeRole-gpusharing-demo
Action: iam:PassRole
Condition:
StringEquals:
iam:PassedToService:
- ec2.amazonaws.com
- ec2.amazonaws.com.cn
- Sid: AllowScopedInstanceProfileCreationActions
Effect: Allow
Resource: arn:aws:iam::767397897074:instance-profile/*
Action:
- iam:CreateInstanceProfile
Condition:
StringEquals:
aws:RequestTag/kubernetes.io/cluster/gpusharing-demo: owned
aws:RequestTag/eks:eks-cluster-name: gpusharing-demo
aws:RequestTag/topology.kubernetes.io/region: "us-west-2"
StringLike:
aws:RequestTag/karpenter.k8s.aws/ec2nodeclass: "*"
- Sid: AllowScopedInstanceProfileTagActions
Effect: Allow
Resource: arn:aws:iam::767397897074:instance-profile/*
Action:
- iam:TagInstanceProfile
Condition:
StringEquals:
aws:ResourceTag/kubernetes.io/cluster/gpusharing-demo: owned
aws:ResourceTag/topology.kubernetes.io/region: "us-west-2"
aws:RequestTag/kubernetes.io/cluster/gpusharing-demo: owned
aws:RequestTag/eks:eks-cluster-name: gpusharing-demo
aws:RequestTag/topology.kubernetes.io/region: "us-west-2"
StringLike:
aws:ResourceTag/karpenter.k8s.aws/ec2nodeclass: "*"
aws:RequestTag/karpenter.k8s.aws/ec2nodeclass: "*"
- Sid: AllowScopedInstanceProfileActions
Effect: Allow
Resource: arn:aws:iam::767397897074:instance-profile/*
Action:
- iam:AddRoleToInstanceProfile
- iam:RemoveRoleFromInstanceProfile
- iam:DeleteInstanceProfile
Condition:
StringEquals:
aws:ResourceTag/kubernetes.io/cluster/gpusharing-demo: owned
aws:ResourceTag/topology.kubernetes.io/region: "us-west-2"
StringLike:
aws:ResourceTag/karpenter.k8s.aws/ec2nodeclass: "*"
- Sid: AllowInstanceProfileReadActions
Effect: Allow
Resource: arn:aws:iam::767397897074:instance-profile/*
Action: iam:GetInstanceProfile
- Sid: AllowAPIServerEndpointDiscovery
Effect: Allow
Resource: arn:aws:eks:us-west-2:767397897074:cluster/gpusharing-demo
Action: eks:DescribeCluster
vpc:
cidr: 192.168.0.0/16
hostnameType: resource-name
managedNodeGroups:
- name: main
ami: ami-092590b6039cd49ed
amiFamily: AmazonLinux2
desiredCapacity: 2
iam:
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
instanceType: t3.large
minSize: 0
maxSize: 10
volumeSize: 80
volumeType: gp3
overrideBootstrapCommand: |
#!/bin/bash
/etc/eks/bootstrap.sh gpusharing-demo
privateNetworking: true
spot: falseDry-run 결과 주요 구성 요소
- Cluster Metadata
- 이름:
gpusharing-demo - 리전:
us-west-2 - Kubernetes 버전:
1.32
- 이름:
- VPC 및 네트워크 설정
- CIDR 블록:
192.168.0.0/16 - hostnameType:
resource-name
- CIDR 블록:
- Addons
vpc-cni: 네트워크 정책 활성화- CloudWatch 로깅:
api,audit,authenticator,controllerManager,scheduler등 전체 활성화
- IAM 구성
- OIDC Provider 사용 활성화
- 주요 서비스 계정에 대한 IAM 역할 생성 및 정책 연결
aws-load-balancer-controllerebs-csi-controller-saexternal-dnskarpenter
- Managed NodeGroup
- 이름:
main - 인스턴스 타입:
t3.large - 최소: 0 / 최대: 10 / 원하는 개수: 2
- AMI:
ami-092590b6039cd49ed(Amazon Linux 2) - EBS 볼륨: 80GB, gp3
- Private Networking 설정
- Spot 인스턴스 아님
- 이름:
- 부트스트랩 스크립트
- 클러스터 이름을 인자로 전달하여 기본 bootstrap 실행
1.1.2 클러스터 생성
실제 클러스터를 생성하기 위해 다음 명령어를 실행합니다.
eksdemo create cluster gpusharing-demo -i t3.large -N 2 --region us-west-21.1.3 클러스터 생성 로그
1.1.4 클러스터 구성 완료 및 확인
- CloudFormation Stack을 통해 클러스터와 NodeGroup 리소스가 순차적으로 생성됩니다.
- 모든 리소스 생성이 완료되면 kubeconfig 파일이 자동 저장되며, kubectl 명령으로 클러스터 접근이 가능합니다.
kubectl get nodes
1.2 GPU 노드 그룹 추가
기존 클러스터(gpusharing-demo)에 GPU 인스턴스로 구성된 노드 그룹을 추가합니다.
1.2.1 GPU 노드 그룹 구성 계획
- 클러스터 이름:
gpusharing-demo - 추가 대상: GPU 노드 그룹 (Managed NodeGroup)
- 사용 인스턴스 타입:
g5.8xlarge(NVIDIA A10G GPU 포함) - 노드 개수: 1대
- AMI:
ami-0111ed894dc3ec059(Amazon Linux 2, Kubernetes 1.32) - 기타 구성
- EBS: 80GB, gp3
- Private Networking 활성화
- Taint 설정:
nvidia.com/gpu:NoSchedule
1.2.2 Dry-run을 통한 리소스 생성 미리보기
실제 리소스를 생성하기 전에 eksdemo CLI를 사용하여 생성될 리소스 구성을 Dry-run으로 확인합니다.
$ eksdemo create nodegroup gpu -i g5.8xlarge -N 1 -c gpusharing-demo --region us-west-2 --dry-run
# 출력 예시
Eksctl Resource Manager Dry Run:
eksctl create nodegroup -f - --install-nvidia-plugin=false --install-neuron-plugin=false
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: gpusharing-demo
region: us-west-2
version: "1.32"
tags:
eksdemo.io/version: 0.18.2
managedNodeGroups:
- name: gpu
ami: ami-0111ed894dc3ec059
amiFamily: AmazonLinux2
desiredCapacity: 1
iam:
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
instanceType: g5.8xlarge
minSize: 0
maxSize: 10
volumeSize: 80
volumeType: gp3
overrideBootstrapCommand: |
#!/bin/bash
/etc/eks/bootstrap.sh gpusharing-demo
privateNetworking: true
spot: false
taints:
- key: nvidia.com/gpu
value: ""
effect: NoSchedule--install-nvidia-plugin=false옵션은 디바이스 플러그인 수동 설치를 전제로 하므로, 이후 단계에서 수동으로 설치해야 합니다.
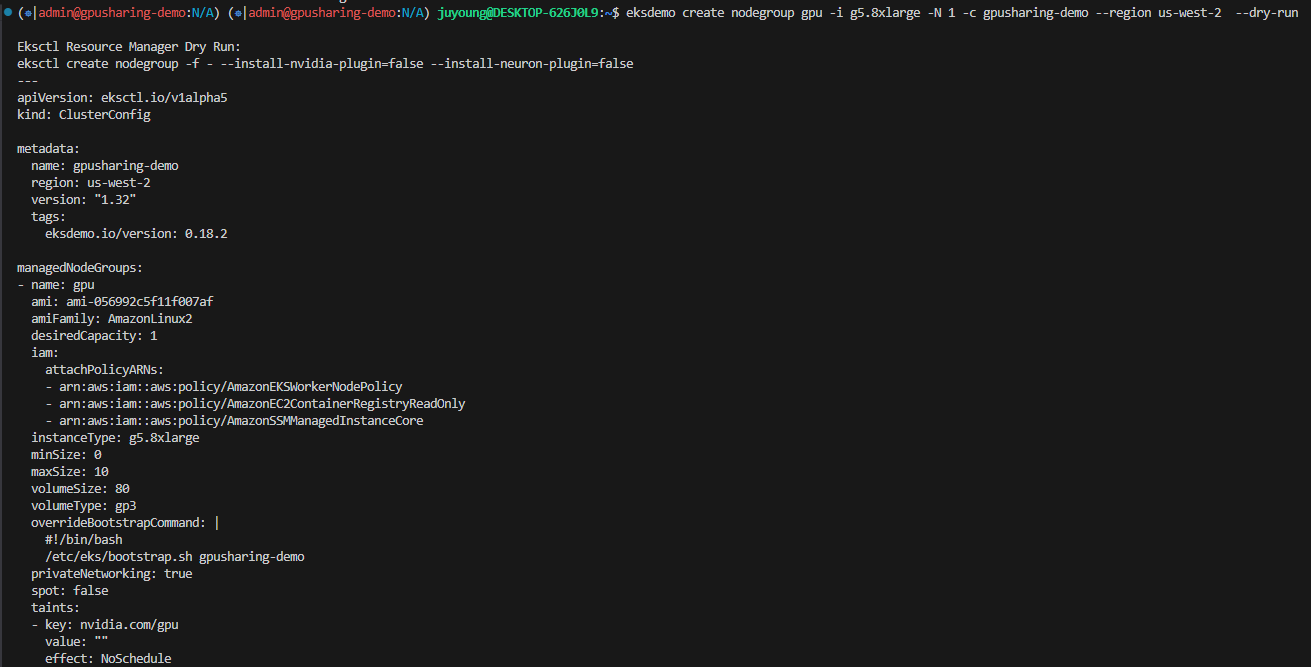
1.2.3 GPU 노드 그룹 생성
Dry-run 결과 확인 후 실제로 GPU 노드 그룹을 생성합니다.
$ eksdemo create nodegroup gpu -i g5.8xlarge -N 1 -c gpusharing-demo --region us-west-2
# 출력 예시
2025-04-13 00:41:45 [ℹ] nodegroup "gpu" will use "ami-0111ed894dc3ec059" [AmazonLinux2/1.32]
2025-04-13 00:41:48 [ℹ] 1 existing nodegroup(s) (main) will be excluded
2025-04-13 00:41:48 [ℹ] 1 nodegroup (gpu) was included (based on the include/exclude rules)
2025-04-13 00:41:48 [ℹ] will create a CloudFormation stack for each of 1 managed nodegroups in cluster "gpusharing-demo"
2025-04-13 00:41:49 [ℹ]
2 sequential tasks: { fix cluster compatibility, 1 task: { 1 task: { create managed nodegroup "gpu" } }
}
2025-04-13 00:41:49 [ℹ] checking cluster stack for missing resources
2025-04-13 00:41:51 [ℹ] cluster stack has all required resources
2025-04-13 00:41:52 [ℹ] building managed nodegroup stack "eksctl-gpusharing-demo-nodegroup-gpu"
2025-04-13 00:41:52 [ℹ] skipping us-west-2d from selection because it doesn't support the following instance type(s): g5.8xlarge
2025-04-13 00:41:53 [ℹ] deploying stack "eksctl-gpusharing-demo-nodegroup-gpu"
2025-04-13 00:41:53 [ℹ] waiting for CloudFormation stack "eksctl-gpusharing-demo-nodegroup-gpu"
2025-04-13 00:42:24 [ℹ] waiting for CloudFormation stack "eksctl-gpusharing-demo-nodegroup-gpu"
2025-04-13 00:43:10 [ℹ] waiting for CloudFormation stack "eksctl-gpusharing-demo-nodegroup-gpu"
2025-04-13 00:43:46 [ℹ] waiting for CloudFormation stack "eksctl-gpusharing-demo-nodegroup-gpu"
2025-04-13 00:44:55 [ℹ] waiting for CloudFormation stack "eksctl-gpusharing-demo-nodegroup-gpu"
2025-04-13 00:44:55 [ℹ] as you are using a GPU optimized instance type you will need to install NVIDIA Kubernetes device plugin.
2025-04-13 00:44:55 [ℹ] see the following page for instructions: https://github.com/NVIDIA/k8s-device-plugin
2025-04-13 00:44:55 [ℹ] no tasks
2025-04-13 00:44:55 [✔] created 0 nodegroup(s) in cluster "gpusharing-demo"
2025-04-13 00:44:55 [✔] created 1 managed nodegroup(s) in cluster "gpusharing-demo"
2025-04-13 00:44:57 [ℹ] checking security group configuration for all nodegroups
2025-04-13 00:44:57 [ℹ] all nodegroups have up-to-date cloudformation templates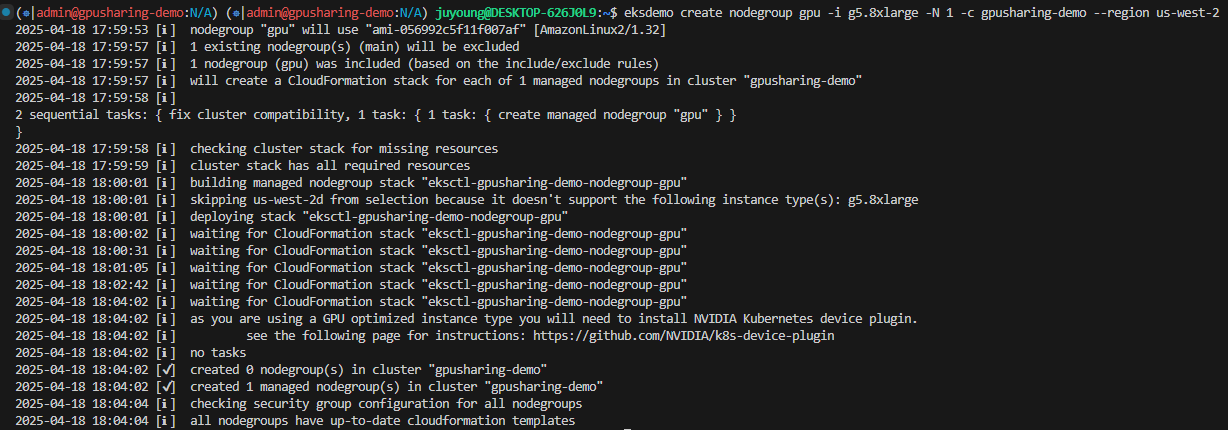
로그 요약
- 기존 클러스터와 호환성 점검
- 기존 nodegroup
main은 제외하고, 새로 생성될gpu만 포함 - CloudFormation을 이용한 스택 생성 준비
- 기존 nodegroup
- 가용 영역 선택
g5.8xlarge인스턴스를 지원하지 않는 AZ(us-west-2d)는 자동 제외됨
- CloudFormation 스택 생성 및 진행
"eksctl-gpusharing-demo-nodegroup-gpu"라는 이름으로 스택 생성- 약 3~5분 정도 소요됨
- 디바이스 플러그인 설치 안내
- GPU 인스턴스를 사용하는 경우, NVIDIA Kubernetes Device Plugin을 수동 설치해야 함
- 공식 가이드: https://github.com/NVIDIA/k8s-device-plugin
- NodeGroup 생성 완료
- GPU 노드 그룹 1개 생성 완료
- 전체 클러스터에는 총 2개의 NodeGroup (
main,gpu) 존재
- 보안 그룹 점검
- 모든 노드 그룹에 대한 CloudFormation 템플릿이 최신 상태임을 확인
1.3 Time Slicing 적용 전
1.3.1 클러스터 노드 확인
$ kubectl get node --label-columns=node.kubernetes.io/instance-type,eks.amazonaws.com/capacityType,topology.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE CAPACITYTYPE ZONE
i-01edff2cd3456af51.us-west-2.compute.internal Ready <none> 43m v1.32.1-eks-5d632ec t3.large ON_DEMAND us-west-2d
i-072eb4b66c886d137.us-west-2.compute.internal Ready <none> 43m v1.32.1-eks-5d632ec t3.large ON_DEMAND us-west-2a
i-0af783eca345807e8.us-west-2.compute.internal Ready <none> 4m53s v1.32.1-eks-5d632ec g5.8xlarge ON_DEMAND us-west-2a
1.3.2 GPU 노드 라벨 설정 및 노드그룹 확장
# g5 - GPU 노드 에 label을 지정: "i-0af783eca345807e8.us-west-2.compute.internal" 를 바꿔주세요!
$ kubectl label node i-0af783eca345807e8.us-west-2.compute.internal eks-node=gpu
# 참고: 노드 그룹 스케일링 (할당량 한도 내에서 2 등으로 변경 가능)
$ eksctl scale nodegroup --name gpu --cluster gpusharing-demo --nodes 2
1.3.3 NVIDIA Device Plugin 설치
# nvidia-device-plugin을 helm을 사용하여 설치
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
$ helm repo update
$ helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace kube-system \
-f nvdp-values.yaml \
--version 0.14.0
Release "nvdp" does not exist. Installing it now.
NAME: nvdp
LAST DEPLOYED: Sun Apr 13 00:50:38 2025
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
$ kubectl get daemonset -n kube-system | grep nvidia
nvdp-nvidia-device-plugin 1 1 1 1 1 eks-node=gpu 23s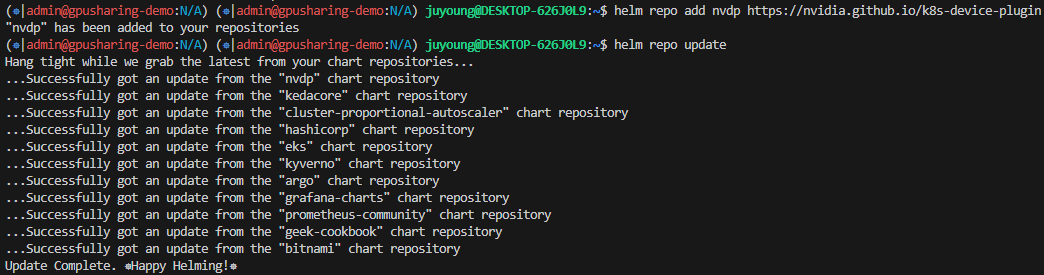

1.3.4 모델 배포 및 GPU 리소스 확인
# time-slicing을 활성화하지 않았을 때: GPU가 1개임
$ kubectl get nodes -o json | jq -r '.items[] | select(.status.capacity."nvidia.com/gpu" != null) | {name: .metadata.name, capacity: .status.capacity}'
{
"name": "i-0af783eca345807e8.us-west-2.compute.internal",
"capacity": {
"cpu": "32",
"ephemeral-storage": "83873772Ki",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "130502176Ki",
"nvidia.com/gpu": "1",
"pods": "234"
}
}
# GPU 모델 배포
$ kubectl create namespace gpu-demo
$ cat << EOF > cifar10-train-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: tensorflow-cifar10-deployment
namespace: gpu-demo
labels:
app: tensorflow-cifar10
spec:
replicas: 5
selector:
matchLabels:
app: tensorflow-cifar10
template:
metadata:
labels:
app: tensorflow-cifar10
spec:
containers:
- name: tensorflow-cifar10
image: public.ecr.aws/r5m2h0c9/cifar10_cnn:v2
resources:
limits:
nvidia.com/gpu: 1
EOF
$ kubectl apply -f cifar10-train-deploy.yaml- GPU 1개만 인식됨 → 파드 1개만 Running 상태로 전환될 것
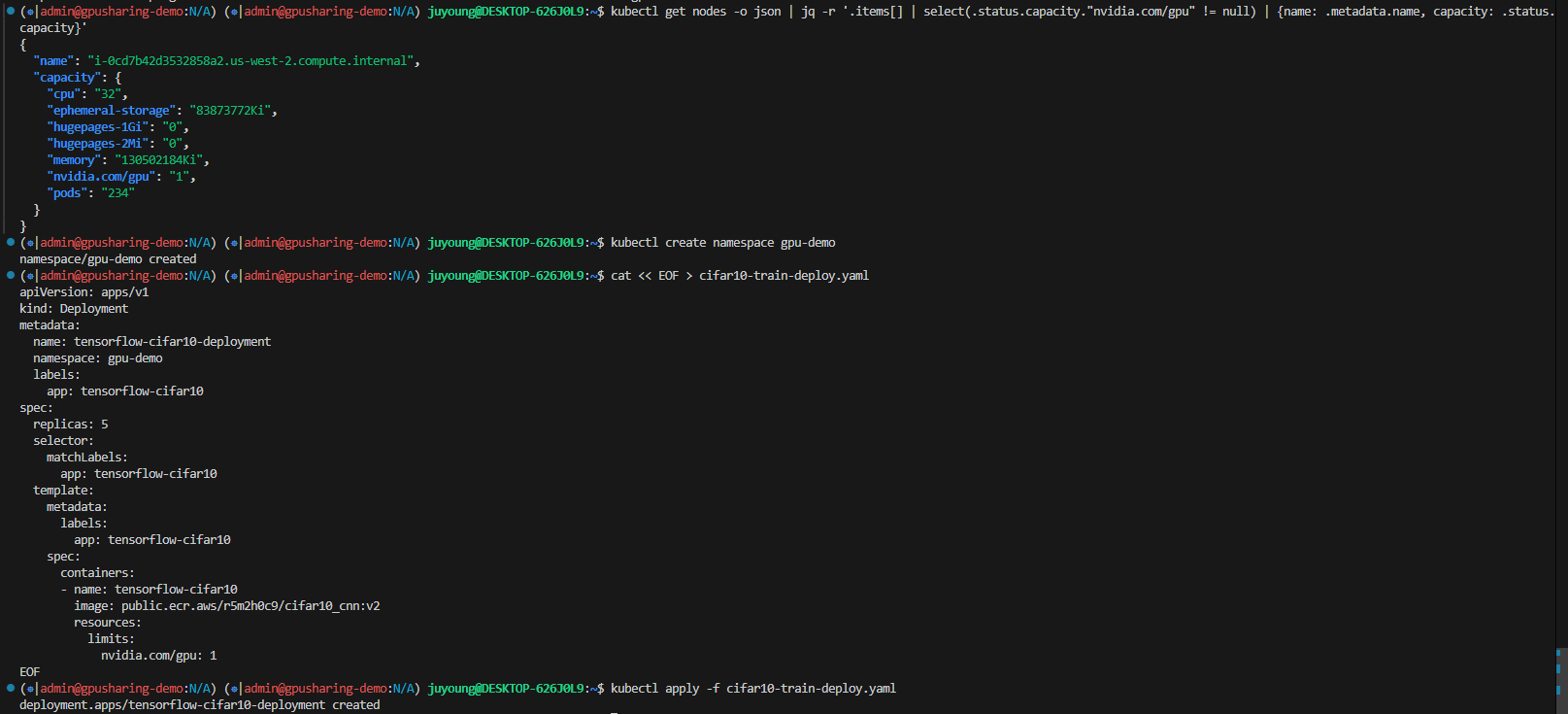
1.3.5 결과 확인
# 시간이 지나면 ContainerCreating -> Running으로 변경
$ watch -d 'kubectl get pods -n gpu-demo'
# [Optional] 상태 살펴보기: 모델 다운로드 중
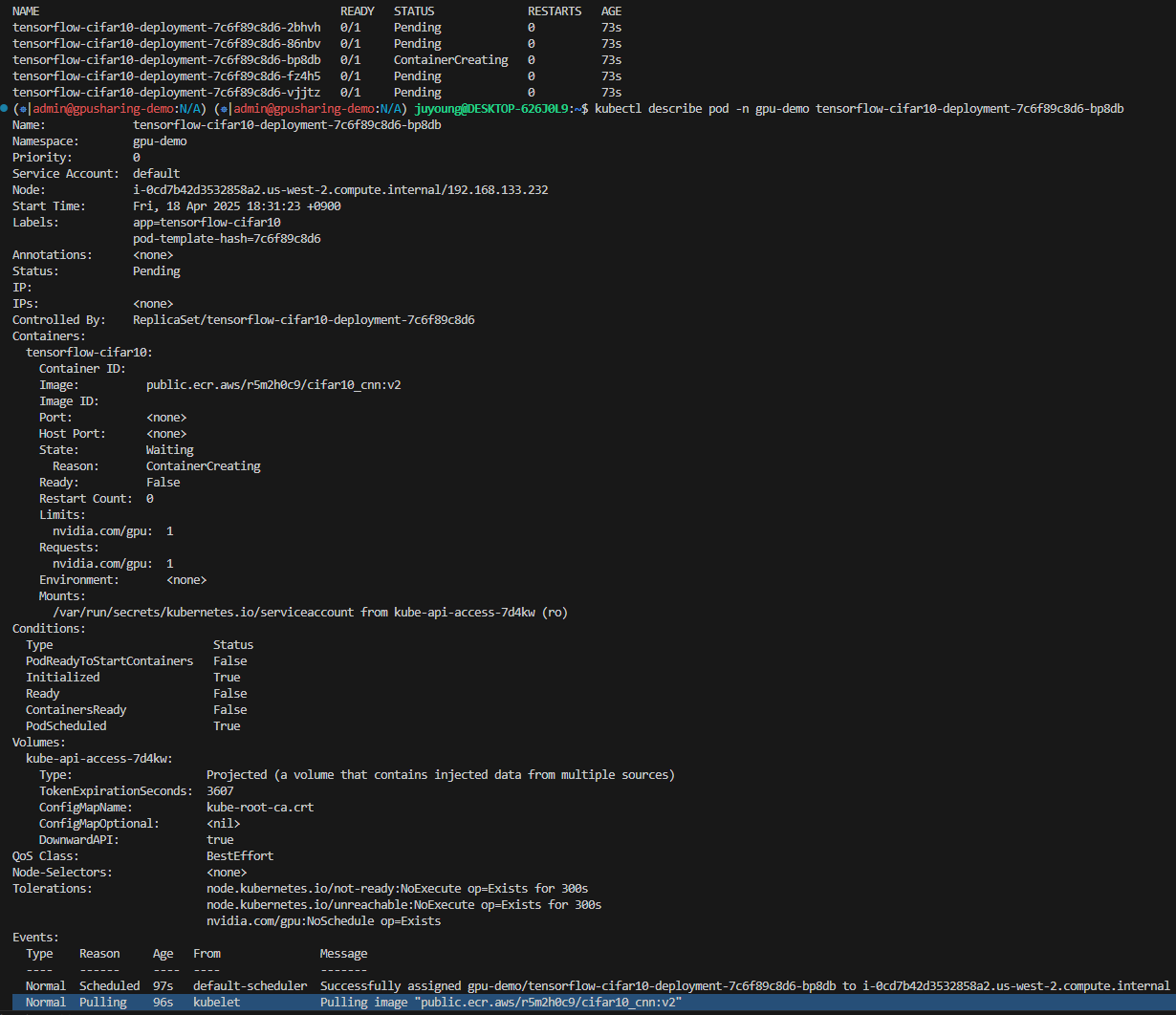
$ kubectl describe pod tensorflow-cifar10-deployment-7c6f89c8d6-kpzmb -n gpu-demo
Name: tensorflow-cifar10-deployment-7c6f89c8d6-kpzmb
Namespace: gpu-demo
Priority: 0
Service Account: default
Node: i-0af783eca345807e8.us-west-2.compute.internal/192.168.123.238
Start Time: Sun, 13 Apr 2025 00:53:46 +0900
Labels: app=tensorflow-cifar10
pod-template-hash=7c6f89c8d6
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/tensorflow-cifar10-deployment-7c6f89c8d6
Containers:
tensorflow-cifar10:
Container ID:
Image: public.ecr.aws/r5m2h0c9/cifar10_cnn:v2
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Limits:
nvidia.com/gpu: 1
Requests:
nvidia.com/gpu: 1
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-z5fss (ro)
Conditions:
Type Status
PodReadyToStartContainers False
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-z5fss:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
nvidia.com/gpu:NoSchedule op=Exists
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 78s default-scheduler Successfully assigned gpu-demo/tensorflow-cifar10-deployment-7c6f89c8d6-kpzmb to i-0af783eca345807e8.us-west-2.compute.internal
Normal Pulling 77s kubelet Pulling image "public.ecr.aws/r5m2h0c9/cifar10_cnn:v2"
# 이제 Running!
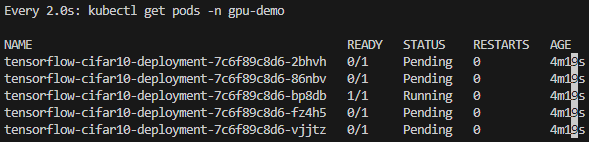
$ kubectl get pods -n gpu-demo
NAME READY STATUS RESTARTS AGE
tensorflow-cifar10-deployment-7c6f89c8d6-k7z77 0/1 Pending 0 2m6s
tensorflow-cifar10-deployment-7c6f89c8d6-kpzmb 1/1 Running 0 2m6s
tensorflow-cifar10-deployment-7c6f89c8d6-n6djg 0/1 Pending 0 2m6s
tensorflow-cifar10-deployment-7c6f89c8d6-x7zws 0/1 Pending 0 2m6s
tensorflow-cifar10-deployment-7c6f89c8d6-zx8dq 0/1 Pending 0 2m6s
# 다른 pod를 조회해보면 GPU 리소스 부족으로 생성 불가능한 상황
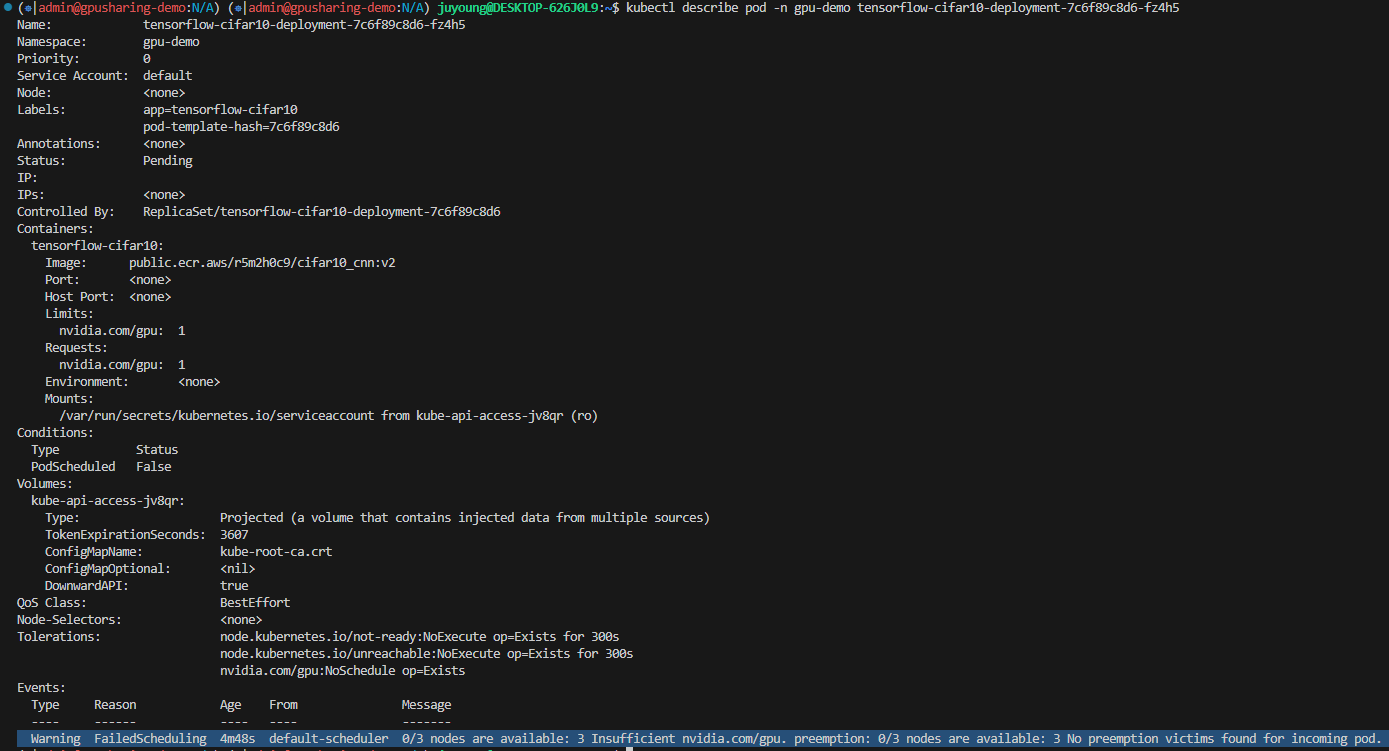
$ kubectl describe pod tensorflow-cifar10-deployment-7c6f89c8d6-k7z77 -n gpu-demo
Name: tensorflow-cifar10-deployment-7c6f89c8d6-k7z77
Namespace: gpu-demo
Priority: 0
Service Account: default
Node: <none>
Labels: app=tensorflow-cifar10
pod-template-hash=7c6f89c8d6
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/tensorflow-cifar10-deployment-7c6f89c8d6
Containers:
tensorflow-cifar10:
Image: public.ecr.aws/r5m2h0c9/cifar10_cnn:v2
Port: <none>
Host Port: <none>
Limits:
nvidia.com/gpu: 1
Requests:
nvidia.com/gpu: 1
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-x2jt4 (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-x2jt4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
nvidia.com/gpu:NoSchedule op=Exists
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 2m46s default-scheduler 0/3 nodes are available: 3 Insufficient nvidia.com/gpu. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.- 1개의 파드만 Running 상태, 나머지는 Pending 상태
1.4 Time-Slicing 적용 후
1.4.1 ConfigMap 작성 및 적용
# Time-slicing 적용하기
$ cat << EOF > nvidia-device-plugin.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: nvidia-device-plugin
namespace: kube-system
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 10
EOF
$ kubectl apply -f nvidia-device-plugin.yaml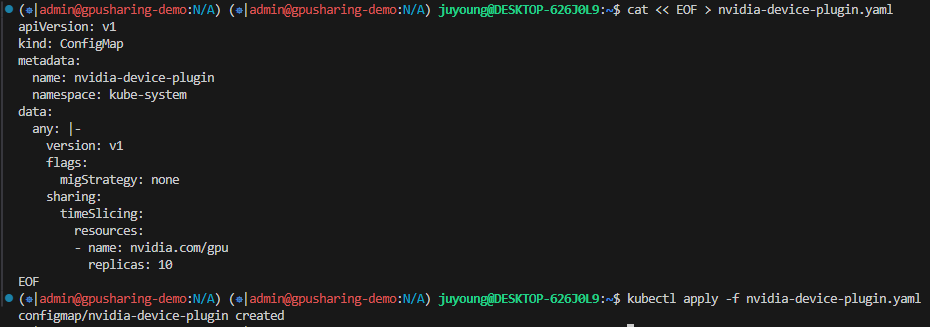
1.4.2 Time-slicing 반영을 위한 helm 업그레이드
# 새로운 ConfigMap 기반으로 반영하기
$ helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace kube-system \
-f nvdp-values.yaml \
--version 0.14.0 \
--set config.name=nvidia-device-plugin \
--force
# 출력 예시
Release "nvdp" has been upgraded. Happy Helming!
NAME: nvdp
LAST DEPLOYED: Sun Apr 13 01:03:05 2025
NAMESPACE: kube-system
STATUS: deployed
REVISION: 2
TEST SUITE: None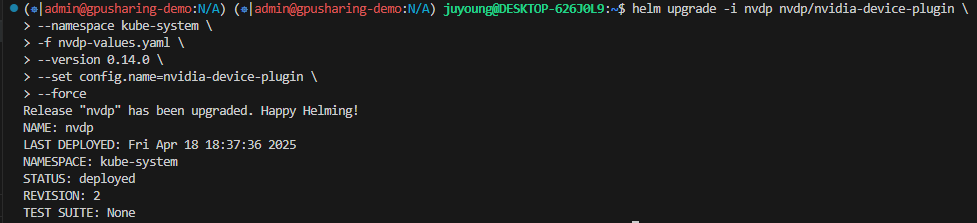
1.4.3 GPU 용량 확인
# 조금 지나고 조회해보면 GPU값이 늘어남!
$ kubectl get nodes -o json | jq -r '.items[] | select(.status.capacity."nvidia.com/gpu" != null) | {name: .metadata.name, capacity: .status.capacity}'
{
"name": "i-0af783eca345807e8.us-west-2.compute.internal",
"capacity": {
"cpu": "32",
"ephemeral-storage": "83873772Ki",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "130502176Ki",
"nvidia.com/gpu": "10",
"pods": "234"
}
}- GPU가 10개의 슬라이스로 논리적으로 분할됨

1.4.4 모델 실행 결과
# 모두 실행된 상황
$ kubectl get pods -n gpu-demo
NAME READY STATUS RESTARTS AGE
tensorflow-cifar10-deployment-7c6f89c8d6-k7z77 1/1 Running 1 (24s ago) 10m
tensorflow-cifar10-deployment-7c6f89c8d6-kpzmb 1/1 Running 0 10m
tensorflow-cifar10-deployment-7c6f89c8d6-n6djg 1/1 Running 1 (34s ago) 10m
tensorflow-cifar10-deployment-7c6f89c8d6-x7zws 1/1 Running 1 (35s ago) 10m
tensorflow-cifar10-deployment-7c6f89c8d6-zx8dq 1/1 Running 1 (34s ago) 10m
# 그런데 계속 재시작이 되고 있음
$ kubectl get pods -n gpu-demo
NAME READY STATUS RESTARTS AGE
tensorflow-cifar10-deployment-7c6f89c8d6-k7z77 1/1 Running 4 (57s ago) 12m
tensorflow-cifar10-deployment-7c6f89c8d6-kpzmb 1/1 Running 0 12m
tensorflow-cifar10-deployment-7c6f89c8d6-n6djg 1/1 Running 4 (56s ago) 12m
tensorflow-cifar10-deployment-7c6f89c8d6-x7zws 0/1 Error 3 (91s ago) 12m
tensorflow-cifar10-deployment-7c6f89c8d6-zx8dq 1/1 Running 1 (2m50s ago) 12m
# 메모리 부족 이슈
$ kubectl logs tensorflow-cifar10-deployment-7c6f89c8d6-k7z77 -n gpu-demo | grep memory
2025-04-12 16:07:59.910576: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1635] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 196 MB memory: -> device: 0, name: NVIDIA A10G, pci bus id: 0000:00:1e.0, compute capability: 8.6
2025-04-12 16:07:59.924567: I tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:736] failed to allocate 196.62MiB (206176256 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out ofmemory
2025-04-12 16:08:01.219272: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:222] Failure to initialize cublas may be due to OOM (cublas needs some free memory when you initialize it, and your deep-learning framework may have preallocated more than its fair share), or may be because this binary was not built with support for the GPU in your machine.- 모든 파드가 Running 상태로 전환됨
- 일부 파드가 재시작을 반복하는 것은 TensorFlow가 초기화 시 메모리 과다 사용으로 OOM(Out of Memory) 발생하는 것


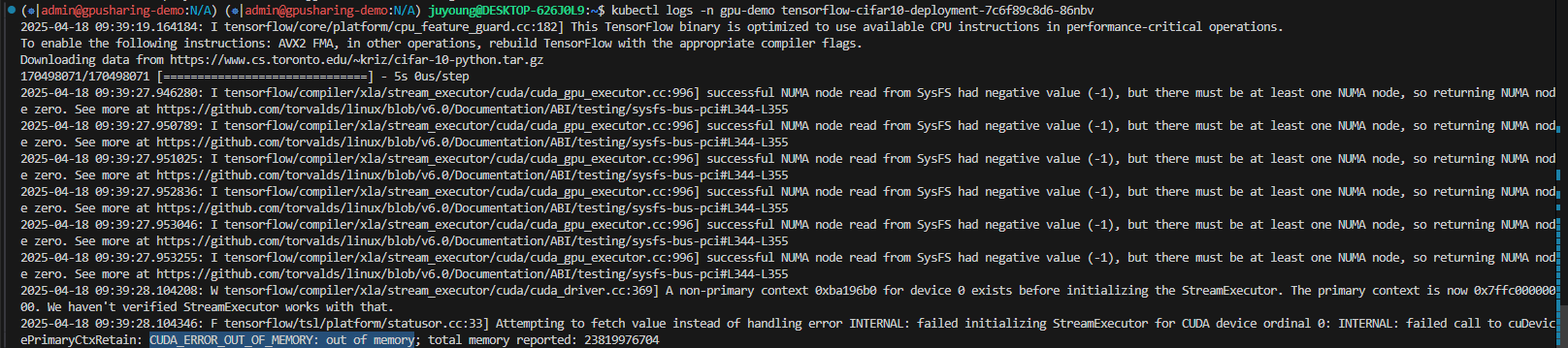
1.4.5 GPU 메모리 상태 확인
AWS Systems Manager를 통해 GPU 노드에 접속:
- AWS Systems Manager 터미널 연결:
https://us-west-2.console.aws.amazon.com/systems-manager/home?region=us-west-2# - GPU 정보 확인:
nvidia-smi
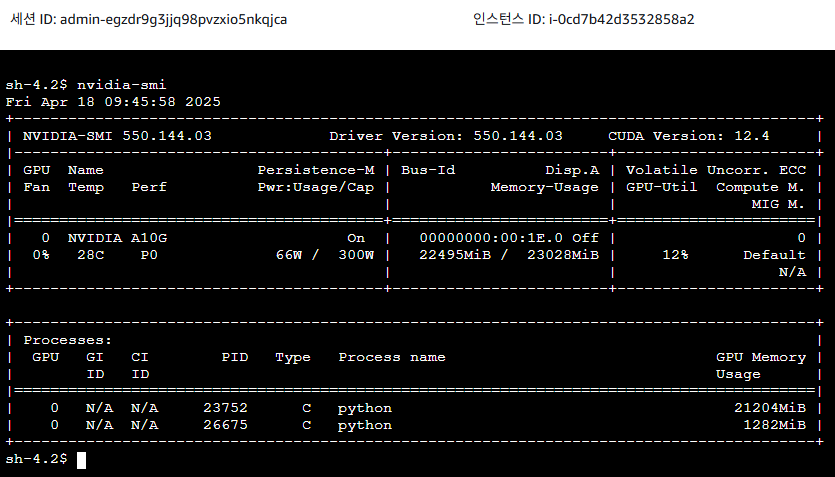
1.5 리소스 정리
실습이 완료되면 아래 명령어로 클러스터를 삭제합니다.
eksdemo delete cluster gpusharing-demo --region us-west-2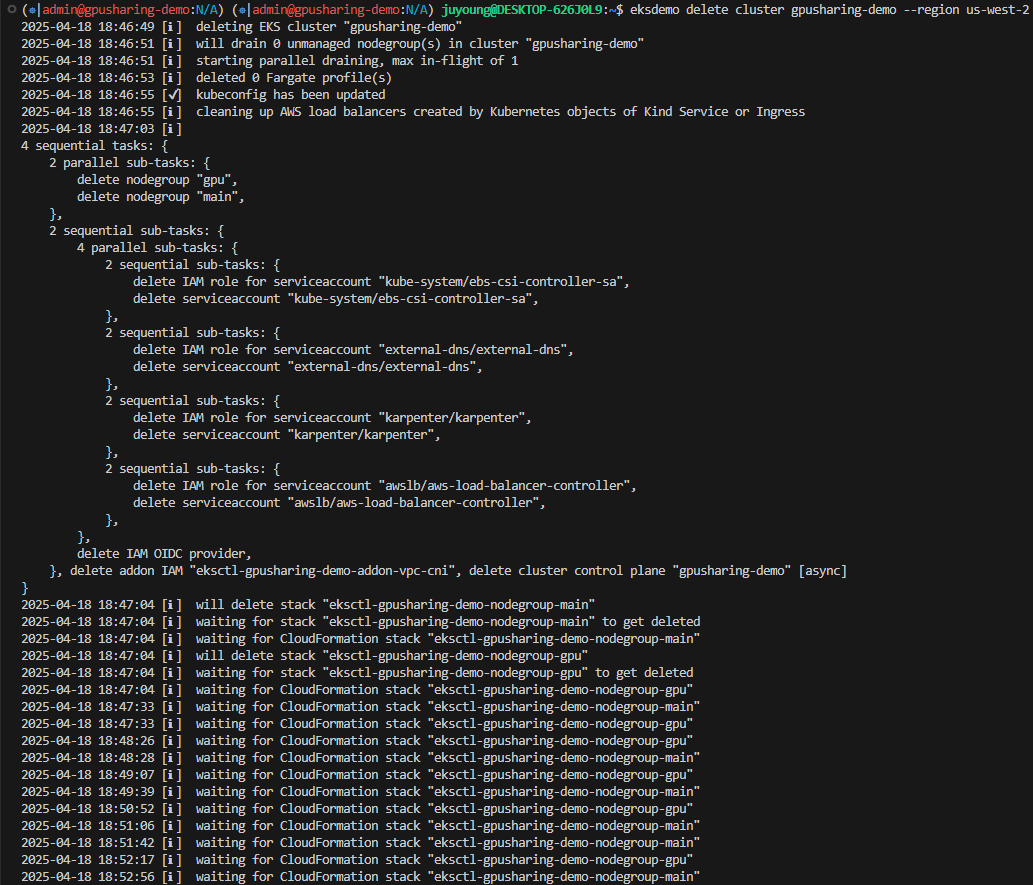
2. 멀티 GPU 활용을 위한 AI/ML 인프라
Amazon EKS 기반 인프라에서 멀티 GPU 학습 환경 구축과 MPI 기반 분산 학습을 실험하는 과정입니다. g5.8xlarge 인스턴스를 활용하며, EFA(RDMA) 미지원 환경에서의 GPU 병렬 처리 성능을 확인합니다.
2.1 실습 준비: Terraform으로 EKS 클러스터 구축
# 코드 다운로드 및 환경 설정
$ git clone https://github.com/aws-ia/terraform-aws-eks-blueprints.git
$ cd terraform-aws-eks-blueprints/patterns/nvidia-gpu-efa
# p5.48xlarge → g5.8xlarge로 인스턴스 설정 변경
$ sed -i "s/p5.48xlarge/g5.8xlarge/g" eks.tf
# Terraform 적용
$ terraform init
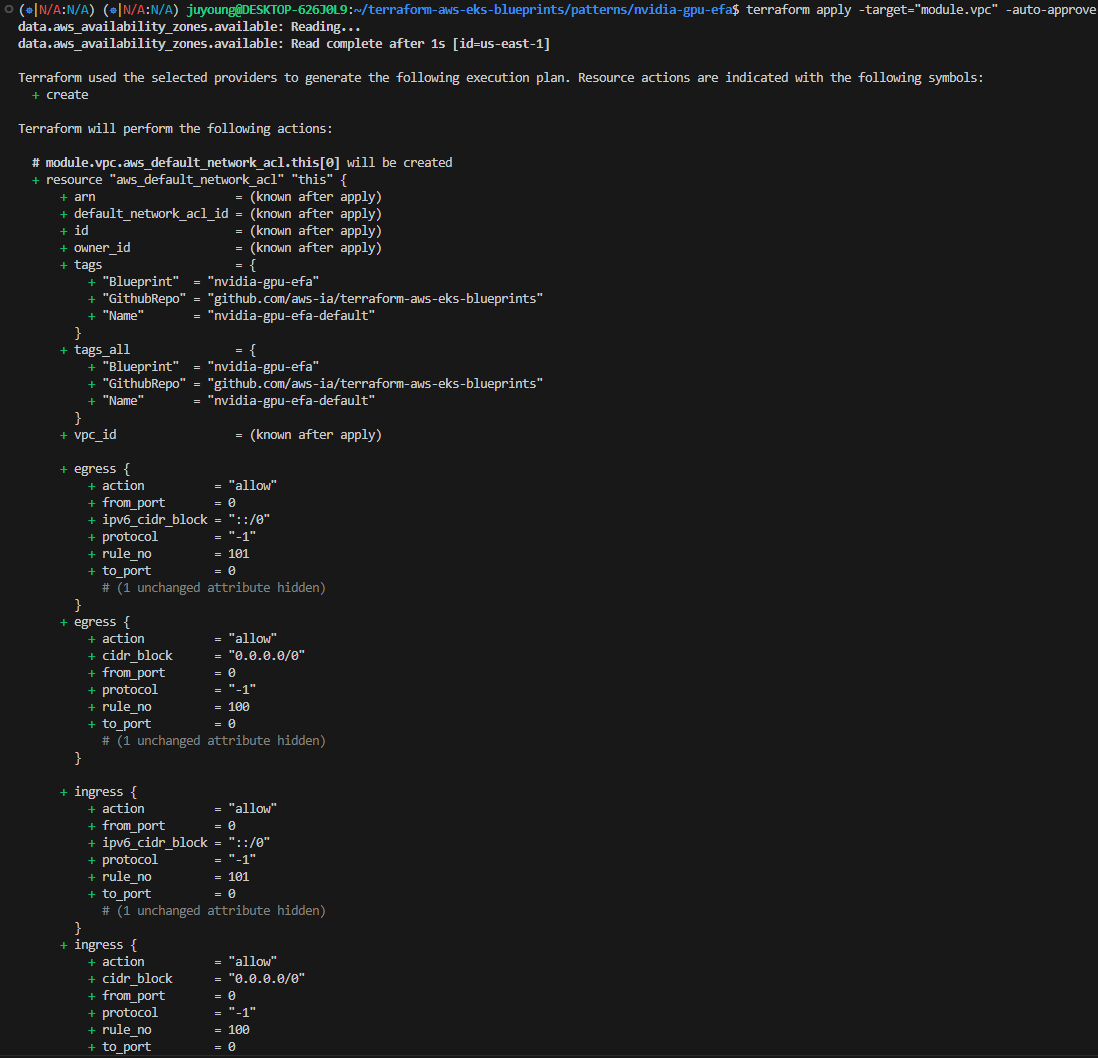
$ terraform apply -target="module.vpc" -auto-approve
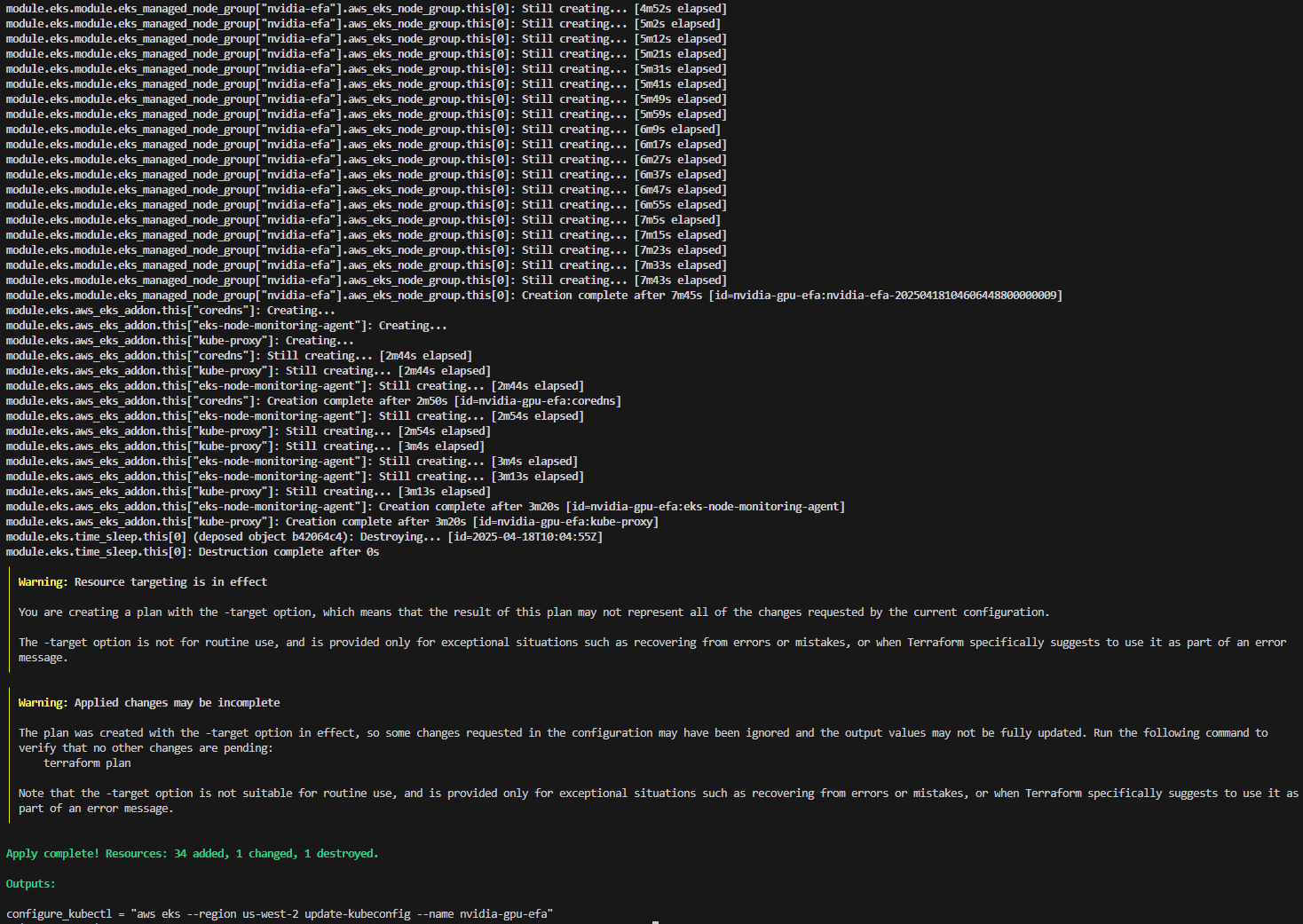
$ terraform apply -target="module.eks" -auto-approve
$ terraform apply -auto-approve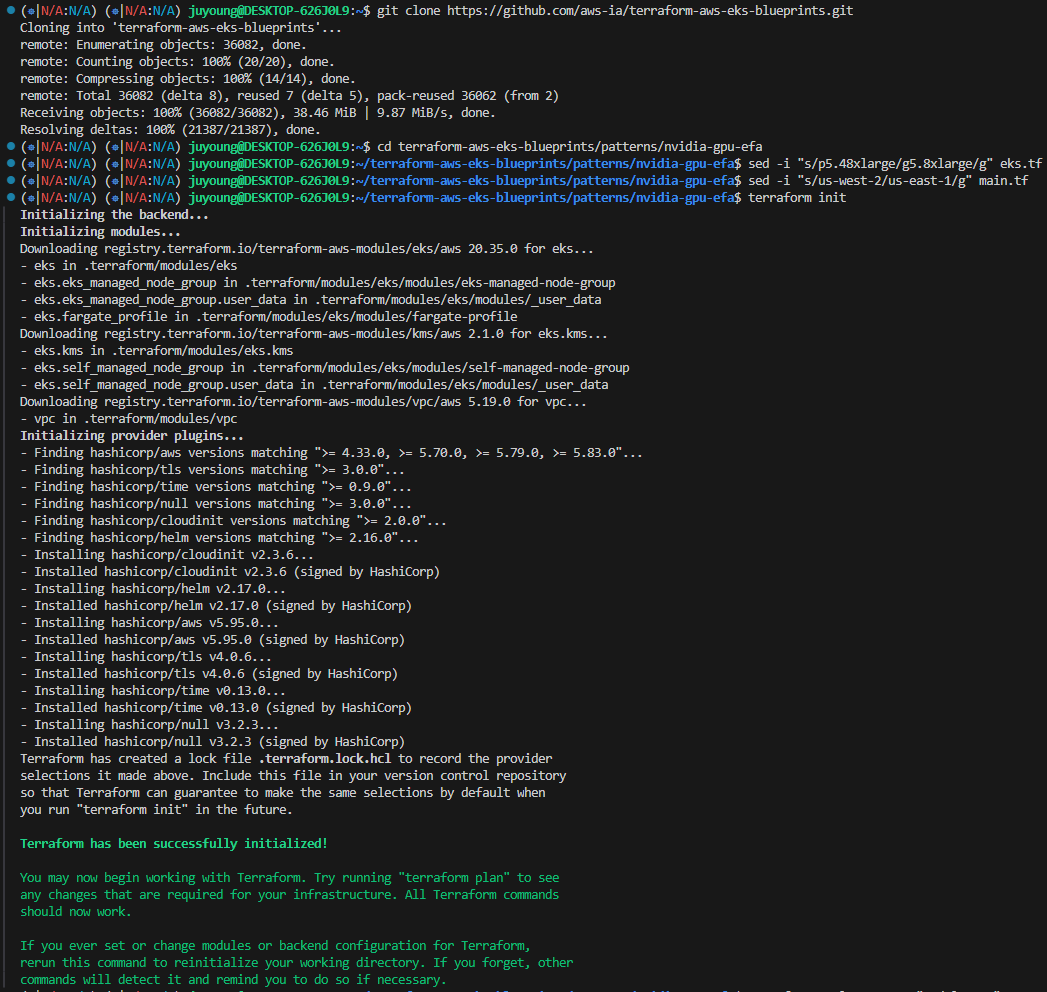
...
2.2 EKS 클러스터에 Kubeflow MPI Operator 배포
# kubeconfig 업데이트
$ aws eks --region us-west-2 update-kubeconfig --name nvidia-gpu-efa
# 인스턴스 유형별 노드 나열
$ kubectl get nodes -L node.kubernetes.io/instance-type
NAME STATUS ROLES AGE VERSION INSTANCE-TYPE
ip-10-0-1-129.ec2.internal Ready <none> 22m v1.32.1-eks-5d632ec g5.8xlarge
ip-10-0-11-12.ec2.internal Ready <none> 15m v1.32.1-eks-5d632ec g5.8xlarge
ip-10-0-12-158.ec2.internal Ready <none> 23m v1.32.1-eks-5d632ec m5.large
ip-10-0-26-134.ec2.internal Ready <none> 23m v1.32.1-eks-5d632ec m5.large
# Kubeflow MPI Operator 배포
$ kubectl apply -f https://raw.githubusercontent.com/kubeflow/mpi-operator/v0.4.0/deploy/v2beta1/mpi-operator.yaml
namespace/mpi-operator created
customresourcedefinition.apiextensions.k8s.io/mpijobs.kubeflow.org created
serviceaccount/mpi-operator created
clusterrole.rbac.authorization.k8s.io/kubeflow-mpijobs-admin created
clusterrole.rbac.authorization.k8s.io/kubeflow-mpijobs-edit created
clusterrole.rbac.authorization.k8s.io/kubeflow-mpijobs-view created
clusterrole.rbac.authorization.k8s.io/mpi-operator created
clusterrolebinding.rbac.authorization.k8s.io/mpi-operator created
deployment.apps/mpi-operator created
# 또한 mpi-operator 클러스터 역할에 패치를 적용하여 mpi-operator 서비스 계정이 apiGroup leases 리소스에 액세스할 수 있도록 설정
$ kubectl apply -f https://raw.githubusercontent.com/aws-samples/aws-do-eks/main/Container-Root/eks/deployment/kubeflow/mpi-operator/clusterrole-mpi-operator.yaml
clusterrole.rbac.authorization.k8s.io/mpi-operator configured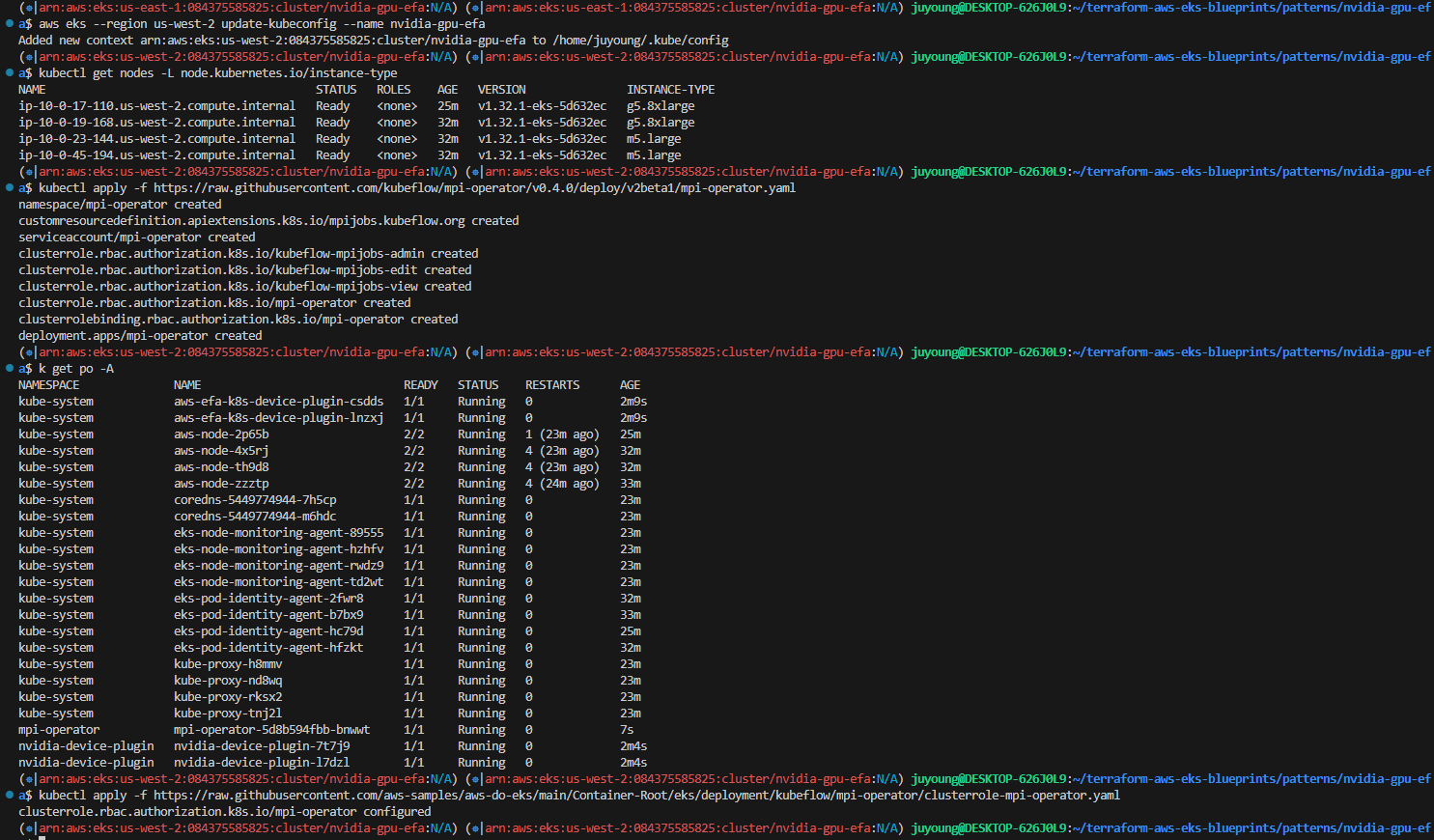
2.3 실습 1: EFA 테스트 (g5.8xlarge, RDMA 미지원)
# 실습에 사용하는 g5.8xlarge 인스턴스에는 인스턴스 당 GPU 1개 및 EFA 1개를 포함하고 있으므로 생성 스크립트를 수정하여 실행
$ sed -i "s/GPU_PER_WORKER=8/GPU_PER_WORKER=1/g" generate-efa-info-test.sh
$ sed -i "s/EFA_PER_WORKER=32/EFA_PER_WORKER=1/g" generate-efa-info-test.sh
# efa 테스트 수행
$ ./generate-efa-info-test.sh
$ kubectl apply -f ./efa-info-test.yaml
mpijob.kubeflow.org/efa-info-test created
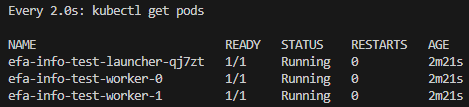
# 모니터링 (워커 포드가 완전히 실행될 때까지 런처 포드가 몇 번 다시 시작되는 것은 정상임)
$ watch 'kubectl get pods'
매 2.0초: kubectl get pods LOCK-PC: Sun Apr 13 01:27:45 2025
NAME READY STATUS RESTARTS AGE
efa-info-test-launcher-mbql8 0/1 ContainerCreating 0 57s
efa-info-test-worker-0 0/1 ContainerCreating 0 57s
efa-info-test-worker-1 0/1 ContainerCreating 0 57s
# (...시간이 지나고...)
매 2.0초: kubectl get pods LOCK-PC: Sun Apr 13 01:29:43 2025
NAME READY STATUS RESTARTS AGE
efa-info-test-launcher-mbql8 0/1 Completed 0 2m56s
# 테스트 결과 확인
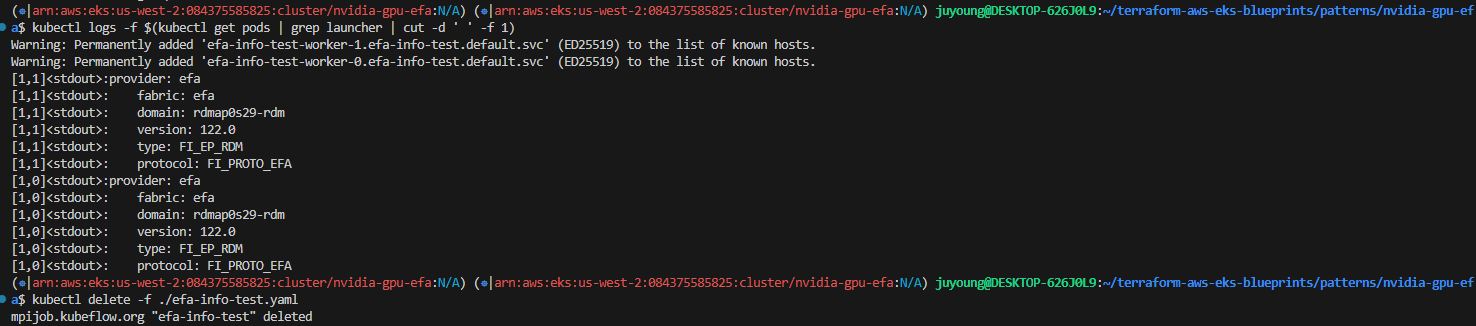
$ kubectl logs -f $(kubectl get pods | grep launcher | cut -d ' ' -f 1)
Warning: Permanently added 'efa-info-test-worker-1.efa-info-test.default.svc' (ED25519) to the list of known hosts.
Warning: Permanently added 'efa-info-test-worker-0.efa-info-test.default.svc' (ED25519) to the list of known hosts.
[1,1]<stdout>:provider: efa
[1,1]<stdout>: fabric: efa
[1,1]<stdout>: domain: rdmap0s29-rdm
[1,1]<stdout>: version: 122.0
[1,1]<stdout>: type: FI_EP_RDM
[1,1]<stdout>: protocol: FI_PROTO_EFA
[1,0]<stdout>:provider: efa
[1,0]<stdout>: fabric: efa
[1,0]<stdout>: domain: rdmap0s29-rdm
[1,0]<stdout>: version: 122.0
[1,0]<stdout>: type: FI_EP_RDM
[1,0]<stdout>: protocol: FI_PROTO_EFA
# 작업 제거
$ kubectl delete -f ./efa-info-test.yaml

2.4 실습 2: NCCL + EFA 테스트 (g5.8xlarge, RDMA 미지원)
# 실습에 사용하는 g5.8xlarge 인스턴스에는 인스턴스 당 GPU 1개 및 EFA 1개를 포함하고 있으므로 생성 스크립트를 수정하여 실행
$ sed -i "s/INSTANCE_TYPE=p5e\.48xlarge/INSTANCE_TYPE=g5\.8xlarge/g" generate-efa-nccl-test.sh
$ sed -i "s/GPU_PER_WORKER=8/GPU_PER_WORKER=1/g" generate-efa-nccl-test.sh
$ sed -i "s/EFA_PER_WORKER=32/EFA_PER_WORKER=1/g" generate-efa-nccl-test.sh
# RDMA=0으로 설정하여 EFA 하드웨어 기반 RDMA가 아닌 커널 기반 TCP 통신으로 대체
$ sed -i "s/FI_EFA_USE_DEVICE_RDMA=1/FI_EFA_USE_DEVICE_RDMA=0/g" generate-efa-nccl-test.sh
# 테스트 실행
$ ./generate-efa-nccl-test.sh
$ kubectl apply -f ./efa-nccl-test.yaml
mpijob.kubeflow.org/efa-nccl-test created
# 상태 확인
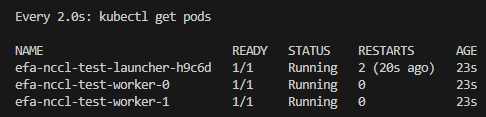
$ watch kubectl get pods
매 2.0초: kubectl get pods LOCK-PC: Sun Apr 13 01:39:18 2025
NAME READY STATUS RESTARTS AGE
efa-nccl-test-launcher-mmfxv 1/1 Running 2 (75s ago) 77s
efa-nccl-test-worker-0 1/1 Running 0 77s
efa-nccl-test-worker-1 1/1 Running 0 77s
# (...시간이 지나고...)
매 2.0초: kubectl get pods LOCK-PC: Sun Apr 13 01:48:52 2025
NAME READY STATUS RESTARTS AGE
efa-nccl-test-launcher-mmfxv 0/1 Completed 2 10m
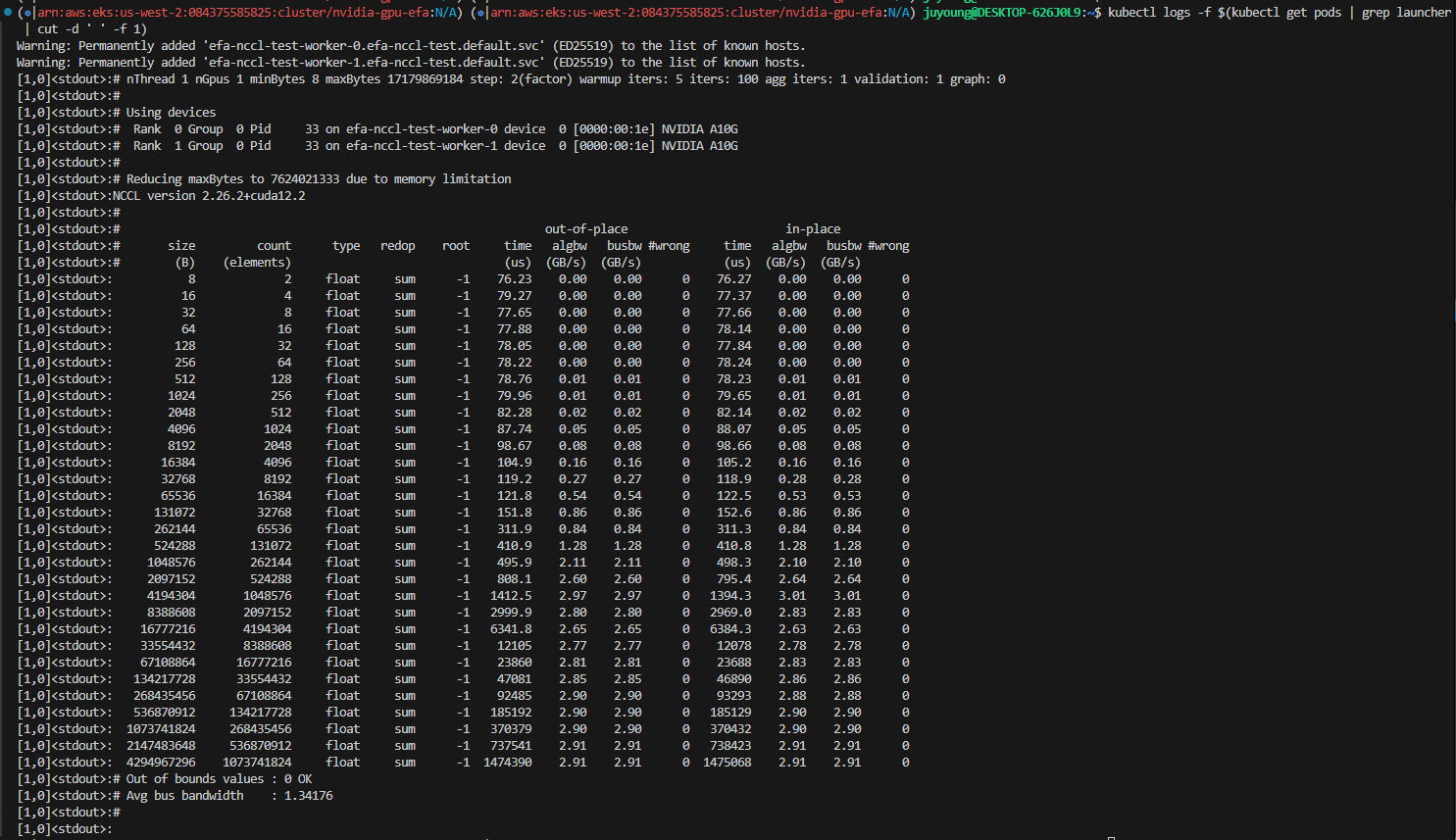
$ kubectl logs -f $(kubectl get pods | grep launcher | cut -d ' ' -f 1)
Warning: Permanently added 'efa-nccl-test-worker-0.efa-nccl-test.default.svc' (ED25519) to the list of known hosts.
Warning: Permanently added 'efa-nccl-test-worker-1.efa-nccl-test.default.svc' (ED25519) to the list of known hosts.
[1,0]<stdout>:# nThread 1 nGpus 1 minBytes 8 maxBytes 17179869184 step: 2(factor) warmup iters: 5 iters: 100 agg iters: 1 validation: 1 graph: 0
[1,0]<stdout>:#
[1,0]<stdout>:# Using devices
[1,0]<stdout>:# Rank 0 Group 0 Pid 33 on efa-nccl-test-worker-0 device 0 [0000:00:1e] NVIDIA A10G
[1,0]<stdout>:# Rank 1 Group 0 Pid 33 on efa-nccl-test-worker-1 device 0 [0000:00:1e] NVIDIA A10G
[1,0]<stdout>:#
[1,0]<stdout>:# Reducing maxBytes to 7624021333 due to memory limitation
[1,0]<stdout>:NCCL version 2.26.2+cuda12.2
[1,0]<stdout>:#
[1,0]<stdout>:# out-of-place in-place
[1,0]<stdout>:# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
[1,0]<stdout>:# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
[1,0]<stdout>: 8 2 float sum -1 67.14 0.00 0.00 0 67.69 0.00 0.00 0
[1,0]<stdout>: 16 4 float sum -1 69.12 0.00 0.00 0 68.49 0.00 0.00 0
[1,0]<stdout>: 32 8 float sum -1 70.05 0.00 0.00 0 69.90 0.00 0.00 0
[1,0]<stdout>: 64 16 float sum -1 70.44 0.00 0.00 0 69.89 0.00 0.00 0
[1,0]<stdout>: 128 32 float sum -1 70.64 0.00 0.00 0 70.60 0.00 0.00 0
[1,0]<stdout>: 256 64 float sum -1 71.02 0.00 0.00 0 70.79 0.00 0.00 0
[1,0]<stdout>: 512 128 float sum -1 72.00 0.01 0.01 0 71.11 0.01 0.01 0
[1,0]<stdout>: 1024 256 float sum -1 72.34 0.01 0.01 0 72.39 0.01 0.01 0
[1,0]<stdout>: 2048 512 float sum -1 74.97 0.03 0.03 0 74.22 0.03 0.03 0
[1,0]<stdout>: 4096 1024 float sum -1 80.03 0.05 0.05 0 79.39 0.05 0.05 0
[1,0]<stdout>: 8192 2048 float sum -1 89.68 0.09 0.09 0 88.78 0.09 0.09 0
[1,0]<stdout>: 16384 4096 float sum -1 95.54 0.17 0.17 0 94.89 0.17 0.17 0
[1,0]<stdout>: 32768 8192 float sum -1 109.7 0.30 0.30 0 108.3 0.30 0.30 0
[1,0]<stdout>: 65536 16384 float sum -1 112.6 0.58 0.58 0 111.5 0.59 0.59 0
[1,0]<stdout>: 131072 32768 float sum -1 142.0 0.92 0.92 0 141.3 0.93 0.93 0
[1,0]<stdout>: 262144 65536 float sum -1 281.7 0.93 0.93 0 281.3 0.93 0.93 0
[1,0]<stdout>: 524288 131072 float sum -1 382.5 1.37 1.37 0 381.4 1.37 1.37 0
[1,0]<stdout>: 1048576 262144 float sum -1 475.7 2.20 2.20 0 477.6 2.20 2.20 0
[1,0]<stdout>: 2097152 524288 float sum -1 779.3 2.69 2.69 0 779.7 2.69 2.69 0
[1,0]<stdout>: 4194304 1048576 float sum -1 1369.3 3.06 3.06 0 1356.9 3.09 3.09 0
[1,0]<stdout>: 8388608 2097152 float sum -1 3039.0 2.76 2.76 0 3016.8 2.78 2.78 0
[1,0]<stdout>: 16777216 4194304 float sum -1 6375.0 2.63 2.63 0 6341.5 2.65 2.65 0
[1,0]<stdout>: 33554432 8388608 float sum -1 12124 2.77 2.77 0 12060 2.78 2.78 0
[1,0]<stdout>: 67108864 16777216 float sum -1 23665 2.84 2.84 0 23565 2.85 2.85 0
[1,0]<stdout>: 134217728 33554432 float sum -1 47018 2.85 2.85 0 46881 2.86 2.86 0
[1,0]<stdout>: 268435456 67108864 float sum -1 94155 2.85 2.85 0 93550 2.87 2.87 0
[1,0]<stdout>: 536870912 134217728 float sum -1 185925 2.89 2.89 0 187473 2.86 2.86 0
[1,0]<stdout>: 1073741824 268435456 float sum -1 372377 2.88 2.88 0 371851 2.89 2.89 0
[1,0]<stdout>: 2147483648 536870912 float sum -1 745248 2.88 2.88 0 745261 2.88 2.88 0
[1,0]<stdout>: 4294967296 1073741824 float sum -1 1491861 2.88 2.88 0 1490178 2.88 2.88 0
[1,0]<stdout>:# Out of bounds values : 0 OK
[1,0]<stdout>:# Avg bus bandwidth : 1.35737
[1,0]<stdout>:#
[1,0]<stdout>:- NCCL이 GPU 간 통신 성능을 측정함
- 최대 2.88 GB/s 수준의 bus bandwidth 확인
- RDMA 없이도 실용 가능한 속도 측정
- 단, 실제 RDMA 지원 인스턴스에서 더 높은 성능 가능


2.5 리소스 정리
$ terraform destroy -target="module.eks_blueprints_addons" -auto-approve
$ terraform destroy -target="module.eks" -auto-approve
$ terraform destroy -auto-approve3. Inferentia 및 FSx를 활용한 GenAI 워크숍
이 워크숍에서는 AWS 서비스 스택에서 오픈 소스 LLM이 포함된 vLLM을 사용하여 생성형 AI 기반 대화형 챗봇 애플리케이션을 구축합니다.
3.1 실습 환경 구성 및 탐색
3.1.1 IAM 역할 검증
대부분의 경우 Cloud9는 IAM 자격 증명을 동적으로 관리하지만, 현재 Amazon EKS IAM 인증과 호환되지 않습니다. 따라서 이 기능을 비활성화하고 AWS IAM 역할을 사용합니다.
aws cloud9 update-environment --environment-id ${C9_PID} --managed-credentials-action DISABLE
rm -vf ${HOME}/.aws/credentials
# Cloud9 IDE가 올바른 IAM 역할을 사용하는지 확인
aws sts get-caller-identity
# Lab region 설정
TOKEN=`curl -s -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"`
export AWS_REGION=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/placement/region)
# EKS 클러스터명 변수 설정
export CLUSTER_NAME=eksworkshop
# 확인
echo $AWS_REGION
echo $CLUSTER_NAME
3.1.2 kube-config 파일 업데이트
aws eks update-kubeconfig --name $CLUSTER_NAME --region $AWS_REGION3.1.3 EKS 클러스터 조회
kubectl get nodes
3.1.4 Karpenter 조회 및 로그 표시
kubectl -n karpenter get deploy/karpenter -o yaml
kubectl get pods --namespace karpenter
# 출력 예시
NAME READY STATUS RESTARTS AGE
karpenter-75f6596894-pgrsd 1/1 Running 0 48s
karpenter-75f6596894-t4mrx 1/1 Running 0 48s
# 로그 표시
alias kl='kubectl -n karpenter logs -l app.kubernetes.io/name=karpenter --all-containers=true -f --tail=20'
kl
# 종료
Ctrl+c

3.2 스토리지 구성 - Amazon FSx for Lustre에 모델 데이터 호스팅
3.2.1 CSI 드라이버 배포
# 전제 조건 - account-id 환경 변수 설정
ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text)
# CSI 드라이버가 사용자를 대신하여 AWS API 호출을 수행할 수 있도록 하는 IAM 정책 및 서비스 계정 생성
cat << EOF > fsx-csi-driver.json
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"iam:CreateServiceLinkedRole",
"iam:AttachRolePolicy",
"iam:PutRolePolicy"
],
"Resource":"arn:aws:iam::*:role/aws-service-role/s3.data-source.lustre.fsx.amazonaws.com/*"
},
{
"Action":"iam:CreateServiceLinkedRole",
"Effect":"Allow",
"Resource":"*",
"Condition":{
"StringLike":{
"iam:AWSServiceName":[
"fsx.amazonaws.com"
]
}
}
},
{
"Effect":"Allow",
"Action":[
"s3:ListBucket",
"fsx:CreateFileSystem",
"fsx:DeleteFileSystem",
"fsx:DescribeFileSystems",
"fsx:TagResource"
],
"Resource":[
"*"
]
}
]
}
EOF
# IAM 정책 생성
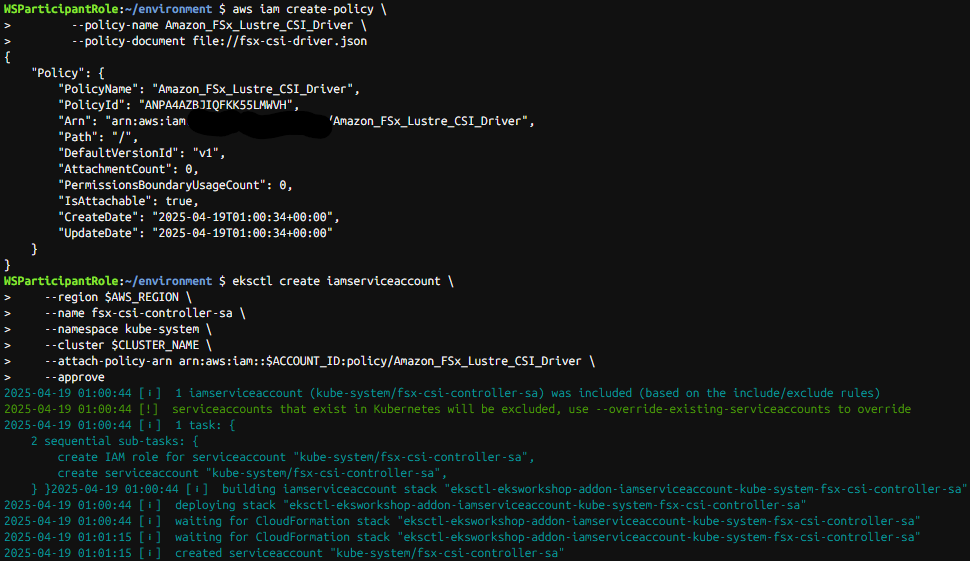
aws iam create-policy \
--policy-name Amazon_FSx_Lustre_CSI_Driver \
--policy-document file://fsx-csi-driver.json
# 드라이버에 대한 K8S 서비스 계정을 만들고 정책을 서비스 계정에 연결
eksctl create iamserviceaccount \
--region $AWS_REGION \
--name fsx-csi-controller-sa \
--namespace kube-system \
--cluster $CLUSTER_NAME \
--attach-policy-arn arn:aws:iam::$ACCOUNT_ID:policy/Amazon_FSx_Lustre_CSI_Driver \
--approve
# 생성된 역할 ARN을 변수에 저장
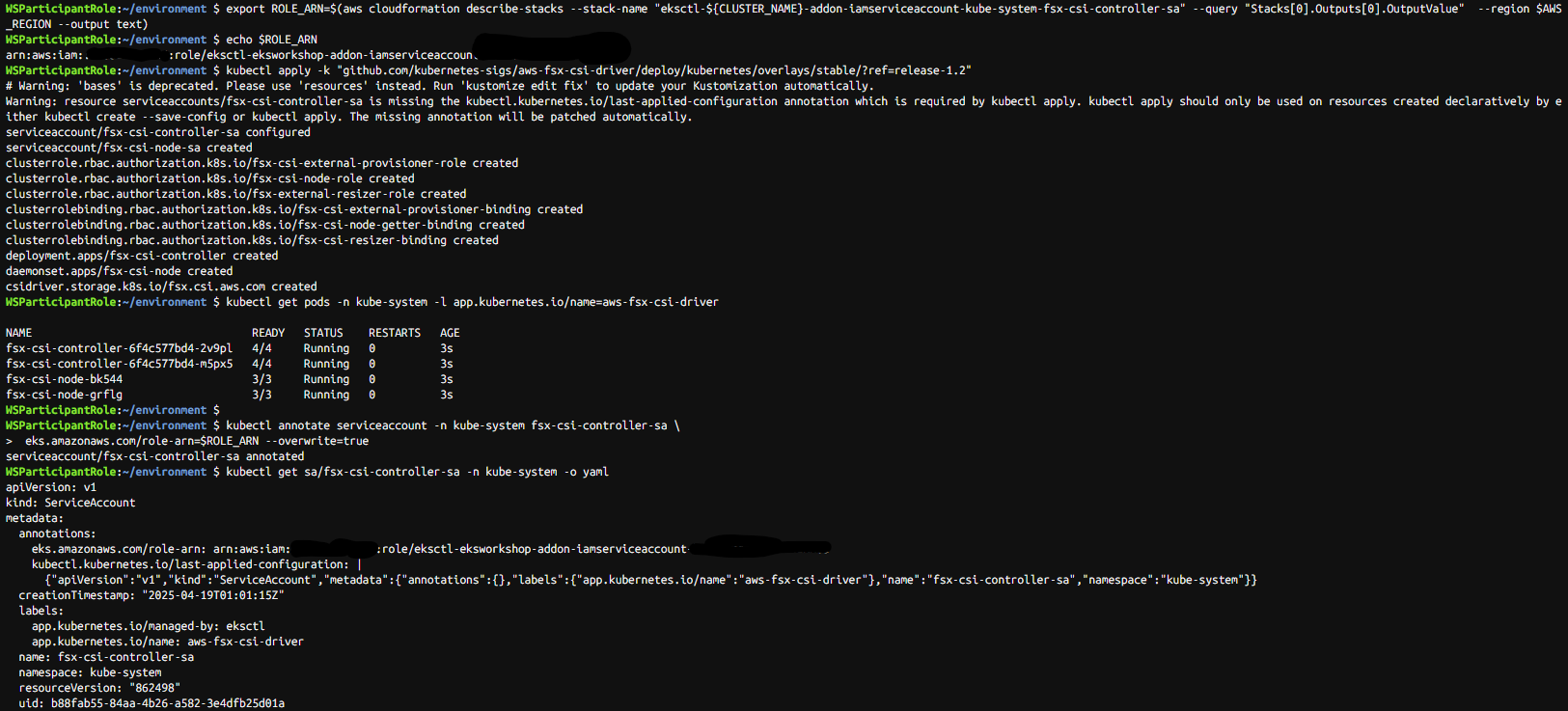
export ROLE_ARN=$(aws cloudformation describe-stacks --stack-name "eksctl-${CLUSTER_NAME}-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa" --query "Stacks[0].Outputs[0].OutputValue" --region $AWS_REGION --output text)
echo $ROLE_ARN
# Lustre용 FSx의 CSI 드라이버 배포
kubectl apply -k "github.com/kubernetes-sigs/aws-fsx-csi-driver/deploy/kubernetes/overlays/stable/?ref=release-1.2"
kubectl get pods -n kube-system -l app.kubernetes.io/name=aws-fsx-csi-driver
# 서비스 계정에 주석 달기
kubectl annotate serviceaccount -n kube-system fsx-csi-controller-sa \
eks.amazonaws.com/role-arn=$ROLE_ARN --overwrite=true
kubectl get sa/fsx-csi-controller-sa -n kube-system -o yaml
3.2.2 EKS 클러스터에 영구 볼륨 생성
cd /home/ec2-user/environment/eks/FSxL
FSXL_VOLUME_ID=$(aws fsx describe-file-systems --query 'FileSystems[].FileSystemId' --output text)
DNS_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].DNSName' --output text)
MOUNT_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].LustreConfiguration.MountName' --output text)
# fsxL-persistent-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: fsx-pv
spec:
persistentVolumeReclaimPolicy: Retain
capacity:
storage: 1200Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
mountOptions:
- flock
csi:
driver: fsx.csi.aws.com
volumeHandle: FSXL_VOLUME_ID
volumeAttributes:
dnsname: DNS_NAME
mountname: MOUNT_NAME
sed -i'' -e "s/FSXL_VOLUME_ID/$FSXL_VOLUME_ID/g" fsxL-persistent-volume.yaml
sed -i'' -e "s/DNS_NAME/$DNS_NAME/g" fsxL-persistent-volume.yaml
sed -i'' -e "s/MOUNT_NAME/$MOUNT_NAME/g" fsxL-persistent-volume.yaml
cat fsxL-persistent-volume.yaml
kubectl apply -f fsxL-persistent-volume.yaml
kubectl get pv
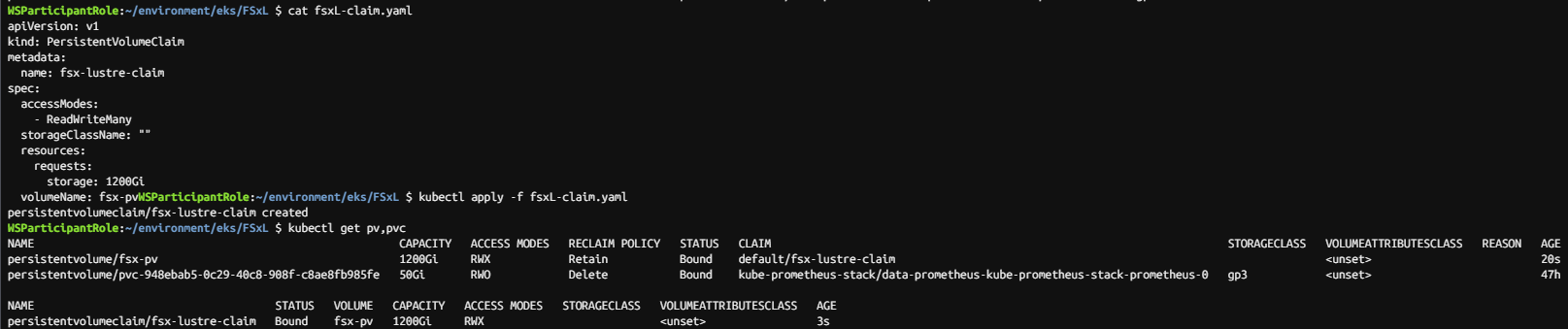
# fsxL-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-lustre-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 1200Gi
volumeName: fsx-pv
kubectl apply -f fsxL-claim.yaml
kubectl get pv,pvc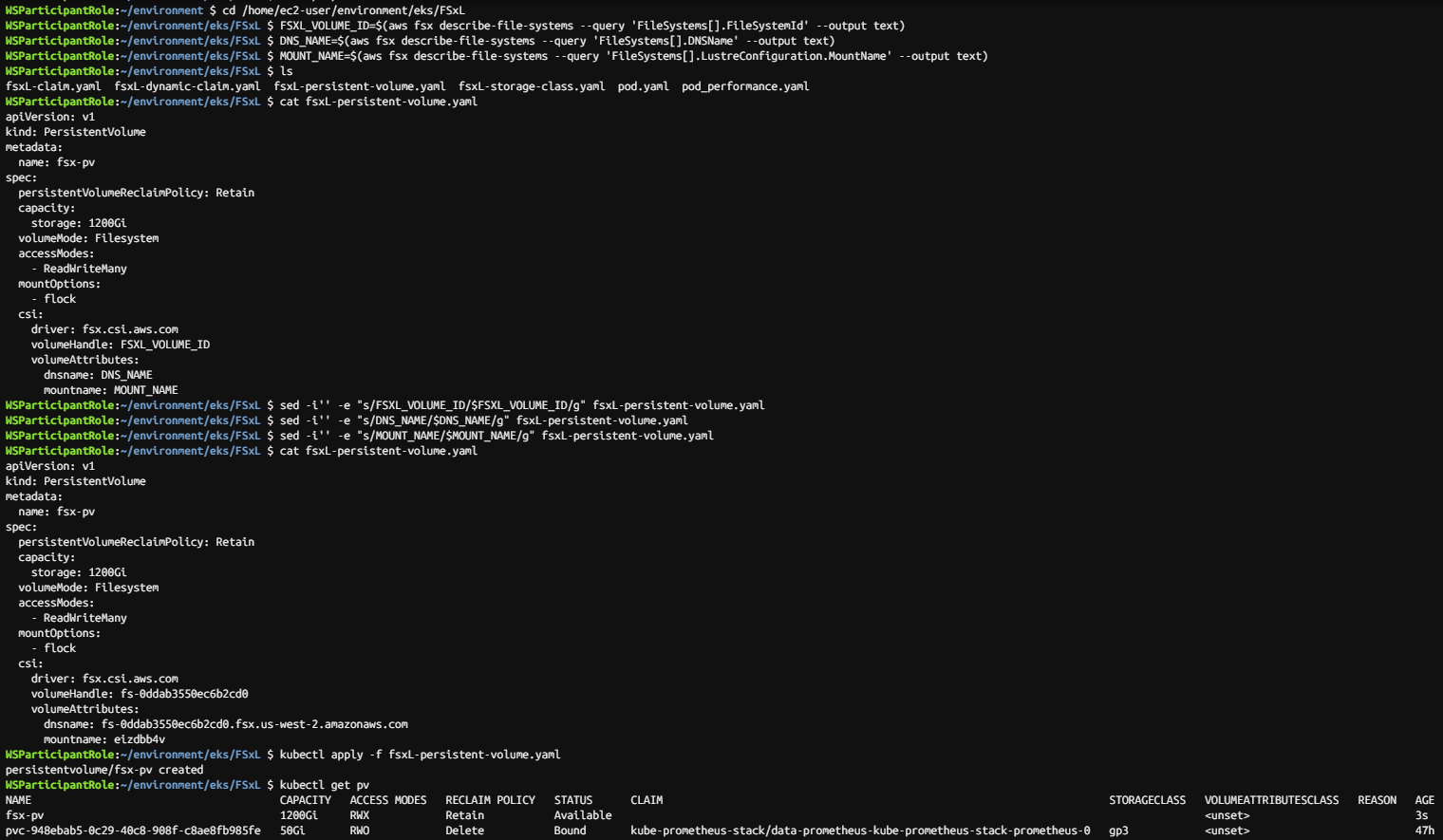
3.2.3 Amazon FSx 콘솔에서 옵션 및 성능 세부 정보 보기
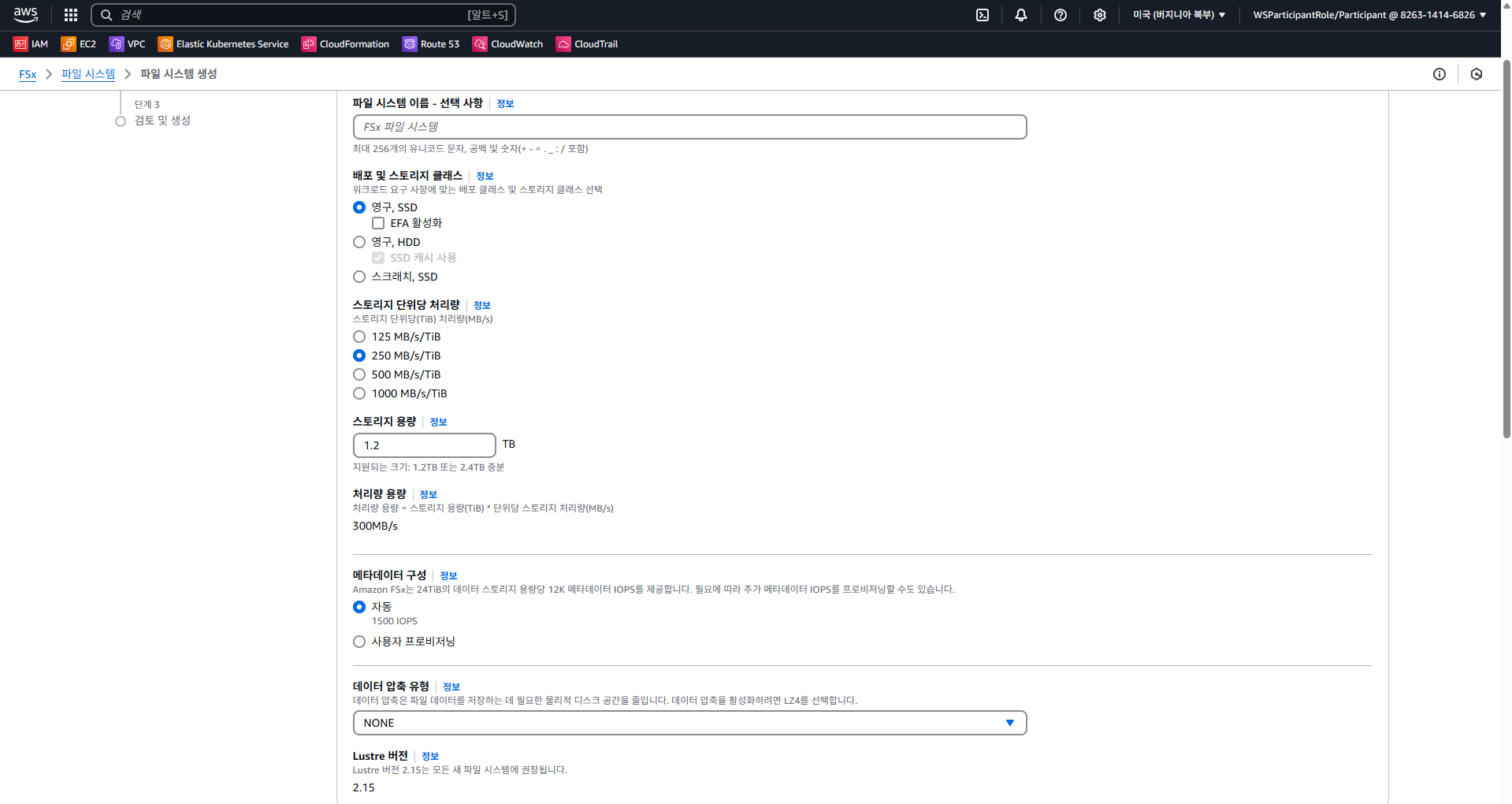
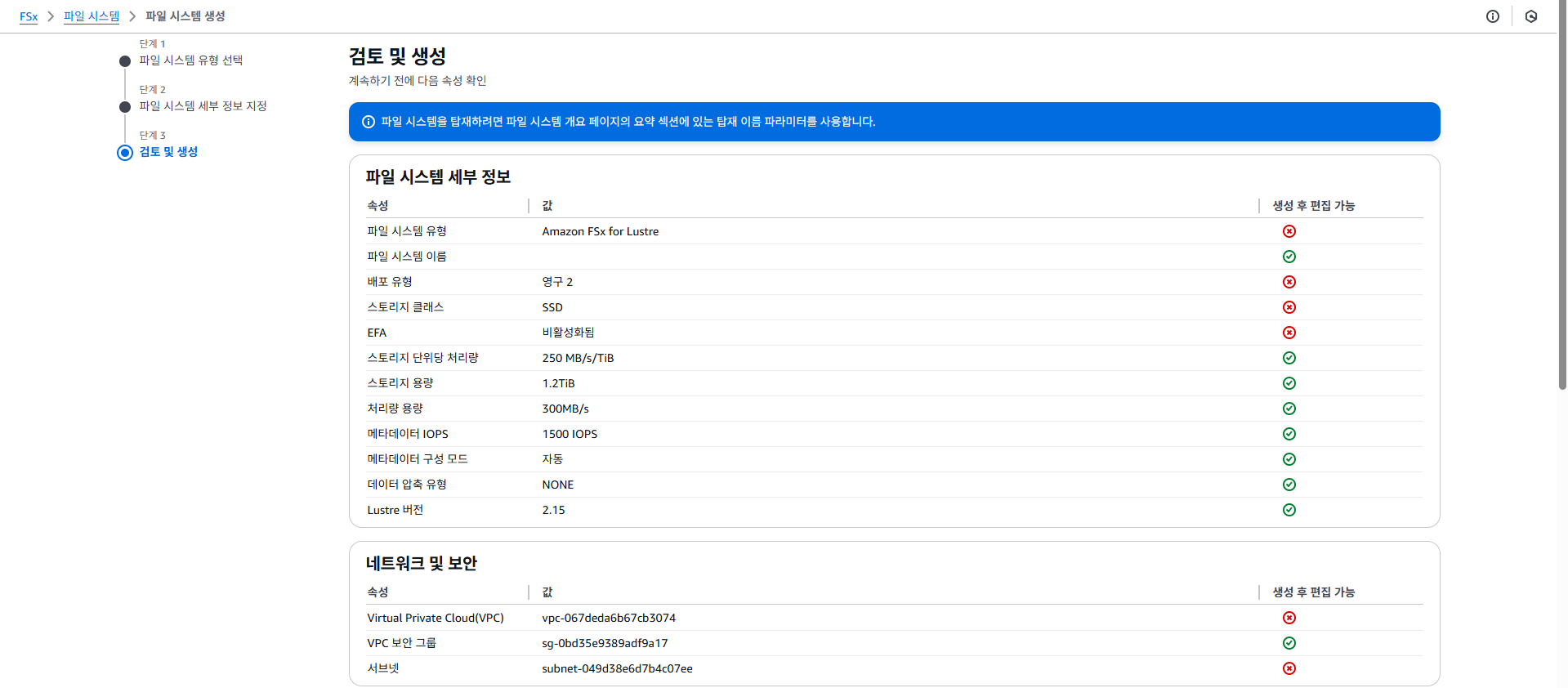
- us-west-2에 생성되어 있음 (워크샵)

3.3 생성형 AI 채팅 애플리케이션 배포
3.3.1 모델 추론을 위해 AWS Inferentia 노드에 vLLM 배포
cd /home/ec2-user/environment/eks/genai
cat inferentia_nodepool.yaml
kubectl apply -f inferentia_nodepool.yaml
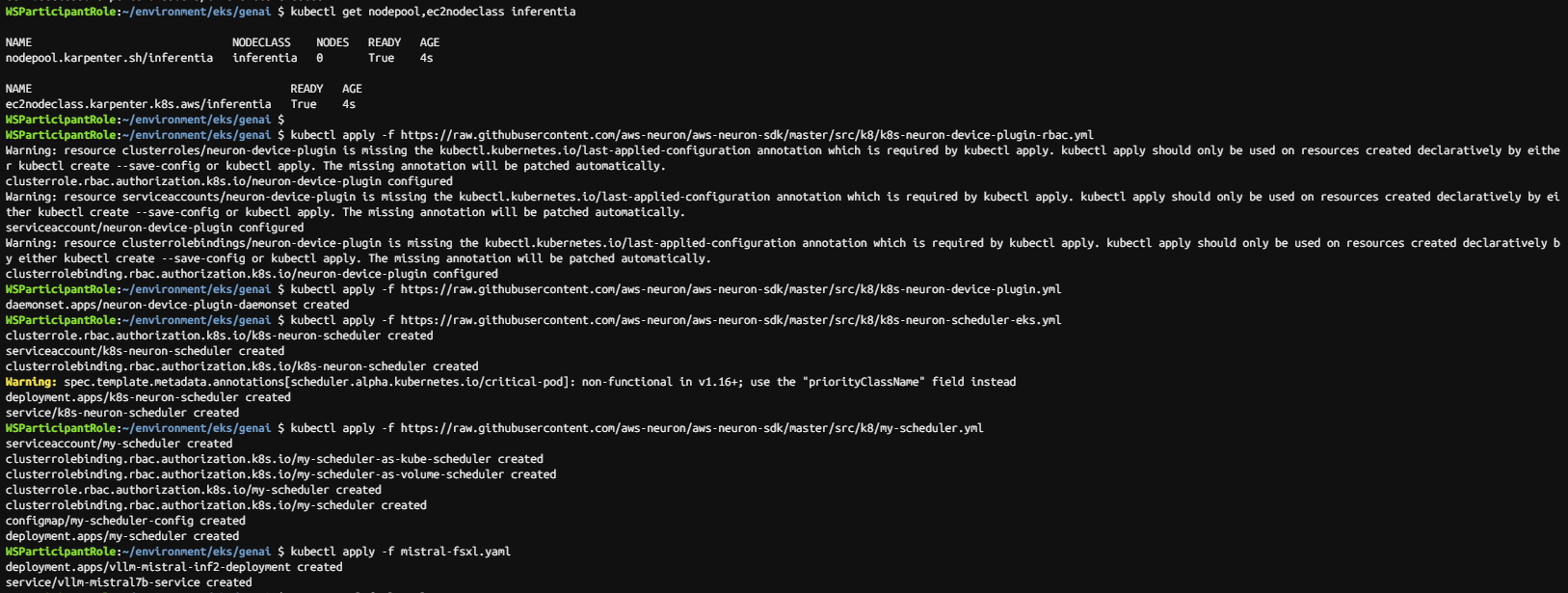
kubectl get nodepool,ec2nodeclass inferentia
# 출력 예시
NAME NODECLASS NODES READY AGE
nodepool.karpenter.sh/inferentia inferentia 0 True 6s
NAME READY AGE
ec2nodeclass.karpenter.k8s.aws/inferentia True 6s
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin-rbac.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-scheduler-eks.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/my-scheduler.yml
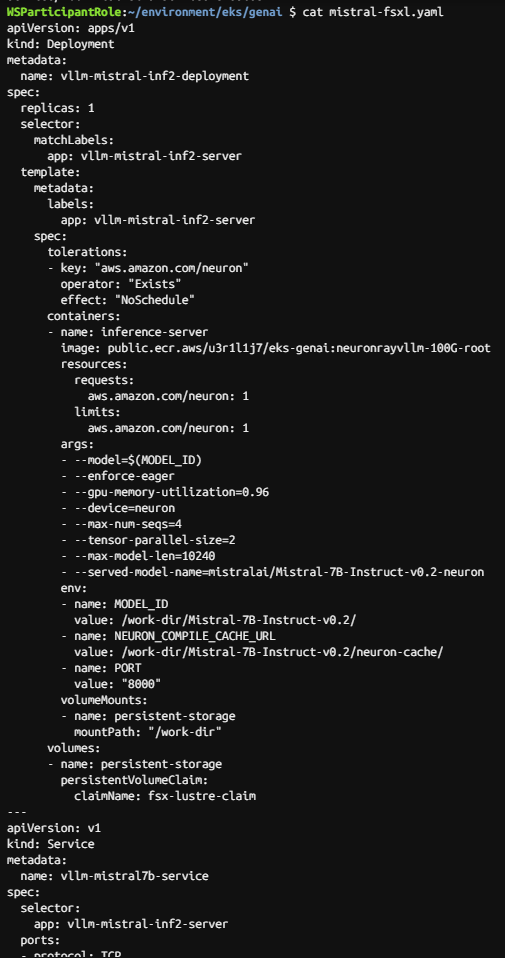
kubectl apply -f mistral-fsxl.yaml
cat mistral-fsxl.yaml
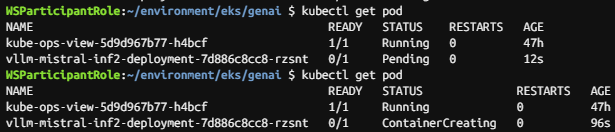
kubectl get pod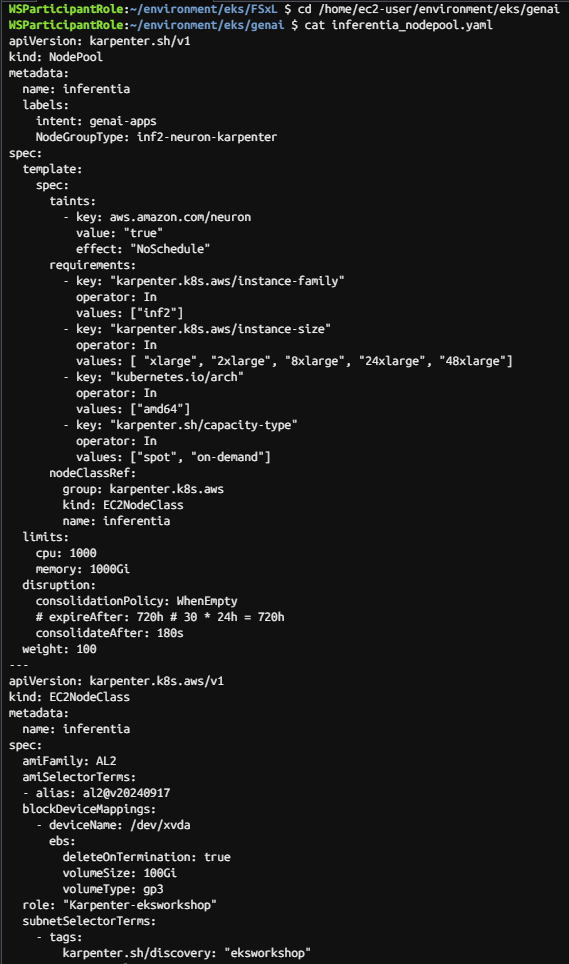

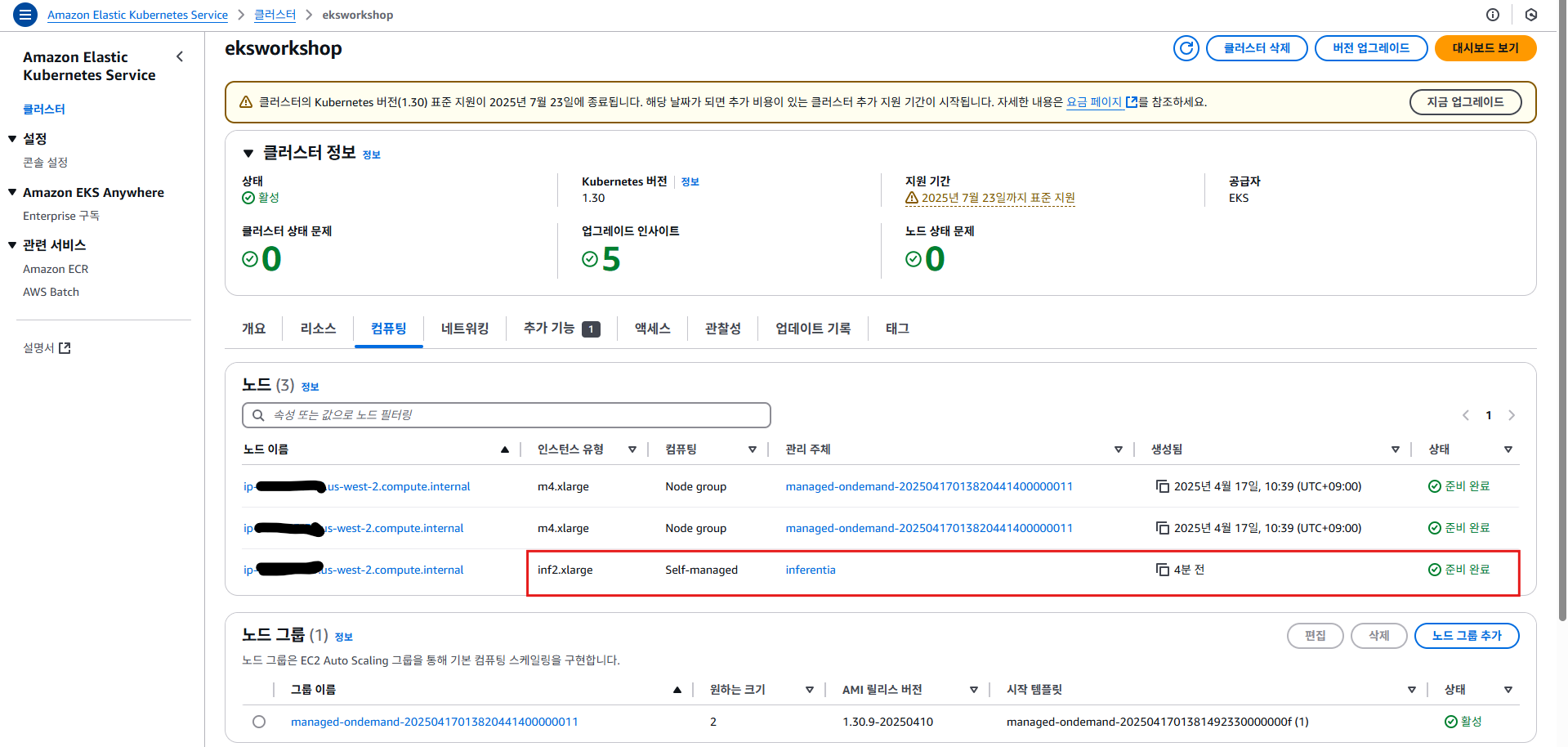
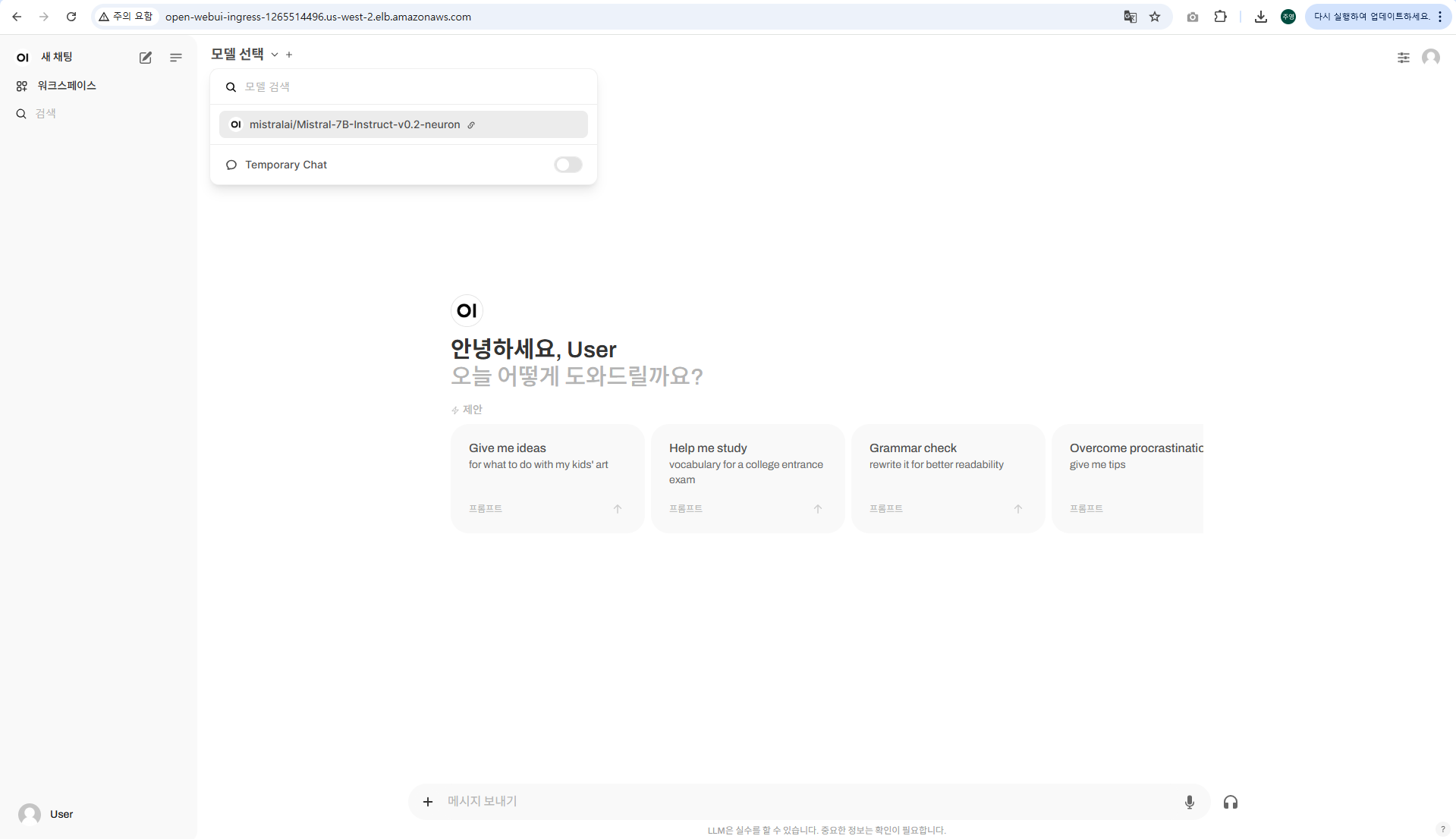
3.3.2 모델과 상호 작용하기 위한 WebUI 채팅 애플리케이션 배포
kubectl apply -f open-webui.yaml
kubectl get ing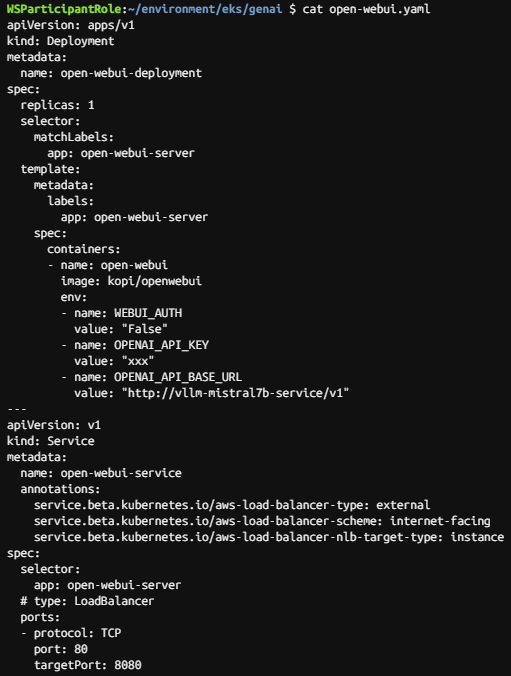
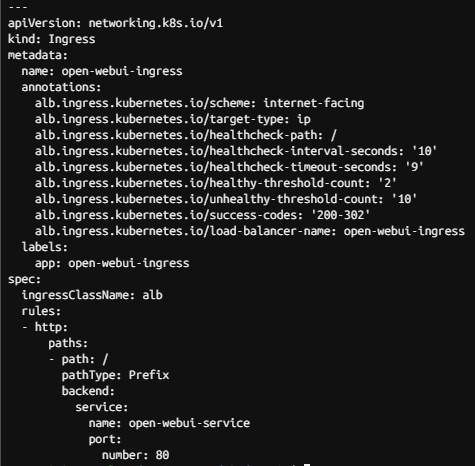
1~2분 후 URL 접속합니다.
Mistral-7B 모델이 보이지 않으면 상단 드롭다운 선택 메뉴에서 해당 모델이 보일 때까지 WebUI 페이지를 새로고침합니다.
vLLM Pod와 모델이 메모리에 로드되는 데 약 7~8분이 소요됩니다.