
교차검증
cross_val_score
- 교차 검증을 간단하게 진행할 수 있는 방법
- 기본적으로 cv파라미터에 숫자를 넣으면 kfold가 실행
- StratifiedKFold를 하고싶으면 객체 생성 후 cv에 생성한 객체를 넣어줌
| 매개변수 | 설명 | 기본값 |
|---|---|---|
estimator | 모델 객체 (예: SVC(), KNeighborsClassifier()) | - |
X | 독립 변수 데이터셋 | - |
y | 종속 변수 (타겟 레이블) | - |
scoring | 여러 개의 평가지표를 설정할 수 있음 (예: accuracy, precision_macro, recall_macro, f1_macro 등) | - |
cv | 교차검증 폴드 수 | 5 |
return_train_score | 훈련 세트에서의 성능 점수를 반환할지 여부 (True 또는 False) | False |
n_jobs | 병렬 처리 설정 | 1 |
verbose | 실행 중 로그 출력 수준 설정 | 0 |
return_estimator | 각 교차검증의 폴드별로 학습된 모델을 반환할지 여부 | False |
X | 독립 변수 데이터셋 (입력 데이터) | - |
y | 종속 변수 (타겟 레이블) | - |
scoring | 모델 성능을 평가하는 지표 (예: f1, precision, recall, roc_auc 등) | accuracy |
cv | 교차검증을 위한 폴드 수 | 5 |
n_jobs | 여러 코어를 사용해 병렬 처리를 할 수 있도록 설정 | None |
verbose | 실행 중 출력되는 로그의 상세 수준 | 0 |
cross_validate
- cross_val_score보다 좀 더 세부적인 정보를 확인할 수 있음
- 훈련, 테스트하는데 걸린 시간
- train, test 스코어 등
| 파라미터 | 설명 | 기본값 |
|---|---|---|
estimator | 모델 객체 (예: SVC(), KNeighborsClassifier()) | - |
X | 독립 변수 데이터셋 | - |
y | 종속 변수 (타겟 레이블) | - |
scoring | 여러 개의 평가지표를 설정할 수 있음 (예: accuracy, precision_macro, recall_macro, f1_macro 등) | - |
cv | 교차검증 폴드 수 | 5 |
return_train_score | 훈련 세트에서의 성능 점수를 반환할지 여부 (True 또는 False) | False |
n_jobs | 병렬 처리 설정 | 1 |
verbose | 실행 중 로그 출력 수준 설정 | 0 |
return_estimator | 각 교차검증의 폴드별로 학습된 모델을 반환할지 여부 | False |
Micro / Macro / Weighted
- Micro : 모든 클래스의 TP, FP, FN을 합산해 계산한 성능 지표로, 클래스 간 중요도를 동등하게 평가
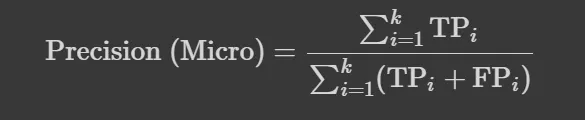
- Macro : 각 클래스의 성능 지표를 개별적으로 계산한 후 평균하여 도출, 클래스 간 불균형을 고려하지 않음
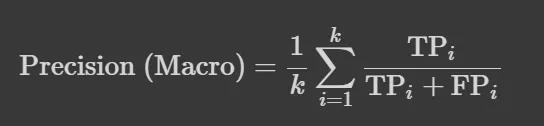
- Weighted : 각 클래스의 성능 지표를 계산하고, 클래스의 샘플 수에 따라 가중치를 부여하여 평균을 도출, 클래스 간 불균형을 반영
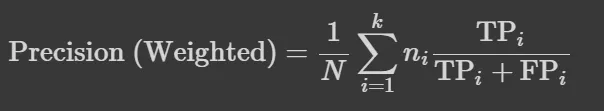
💡 3가지 방법 중 어떤 것을 사용해야하나?
Micro
- 장점: 전체적인 성능을 반영하며, 데이터 불균형이 있을 때 더 정확한 성능 평가를 제공
- 단점: 소수 클래스의 성능이 무시될 수 있어, 특정 클래스의 성능 저하가 전체 성능에 미치는 영향이 적음
macro
- 장점: 각 클래스의 성능을 동등하게 고려하므로, 모든 클래스의 성능을 공정하게 평가
- 단점: 클래스 간 불균형이 클 경우, 주요 클래스의 성능이 낮아도 전체 평가가 영향을 받을 수 있음
Weighted
- 장점: 클래스 샘플 수를 고려하므로, 불균형한 데이터셋에서도 더 신뢰성 있는 성능 평가 가능
- 단점: 소수 클래스의 중요성이 낮아질 수 있어, 특정 클래스의 성능 저하를 간과할 위험이 있음
선택 기준
- 데이터 불균형이 심한 경우: Micro Average 또는 Weighted Average 사용
- 모든 클래스의 성능을 동등하게 중요시할 경우: Macro Average 사용
실습
라이브러리 import
from sklearn.tree import DecisionTreeClasifier
from sklearn.ensemble import RandomForestClassifier
from sklear.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cacner
import numpy as np데이터 불러오기
# 유방암 데이터
cancer = load_breast_cancer()
X, y = cancer.data, cancer.target모델 불러오기
clf = DecisionTreeClassifier(random_state=42)cross_val_score 실행
from sklearn.model_selection import cross_val_score, StratifiedKFold
stkfold= StratifiedKFold(n_splits=5) # StratifedKFold 객체 생성
scores = cross_val_score(clf, X, y, cv=stkfold, scoring='accuracy')
scores.mean()cross_validate 실행
from sklearn.model_selection import cross_validate
result = cross_validate(clf, X, y, cv=stkfold, scoring='accuracy', return_train_score=True)
result여러가지 지표 cross_validate 실행
scorings = ['accuracy','precision','recall']
cross_validate(clf, X,y, cv =stkfold, scoring= scorings, return_train_score=True)다양한 모델 사용
#DecisionTreeClassifier, RandomForestClassifier, SVC
models = [DecisionTreeClassifier(random_state=42), RandomForestClassifier(random_state=42), SVC(random_state=42)]
name =['DT','RF','LR']
for model, name in zip(models, name):
print('###사용 알고리즘',name,'###')
for score in ['accuracy','precision_micro','recall_micro','f1_micro']:
print(score)
print("-" * 20)
print(cross_val_score(model, X, y, cv=stkfold, scoring=score))임계점
- 기본적인 평가 지표의 임계점의 default 값은 0.5
- 임계값을 조정하여 다른 결과를 나타낼 수 있음
- predict_proba를 이용해 예측 확률값 출력 가능
실습
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
from sklearn.ensemble import RandomForestClassifier
# train, test 분리
X_train, X_test, y_train, y_test = train_test_split(df_x, df_y, test_size=0.3,random_state=42)
# 모델 생성
clf = RandomForestClassifier(random_state=42)
def get_clf_eval(y_test, pred):
conf = confusion_matrix(y_test, pred)
acc = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred, average='micro')
recall = recall_score(y_test, pred, average ='micro')
print(conf)
print(acc, precision, recall)
# 모델 학습
clf.fit(X_train, y_train)
# 예측
pred = clf.predict(X_test)
# 성능 평가
get_clf_eval(y_test, pred)
# 각 클래스에 속할 확률을 예측
clf.predict_proba(X_test) 
제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.