
도입
- 데이터 분석에서는 도메인이 중요하다.
- 데이터 분석 및 머신러닝의 전반적인 이해
- 데이터 분석 ≠ 머신러닝
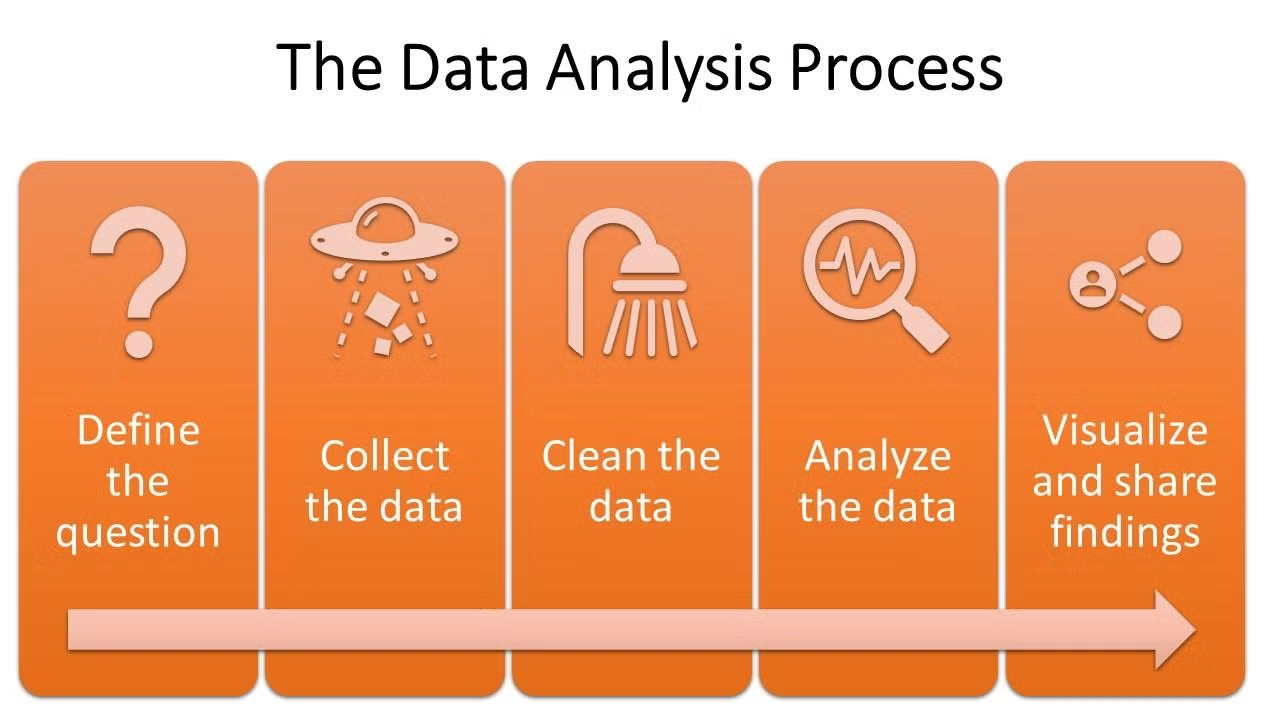
데이터 분석 프로세스
- 문제 정의 → 데이터 수집 → 데이터 전처리 → 데이터 분석 → 인사이트 추출
- 문제 정의가 매우 중요함
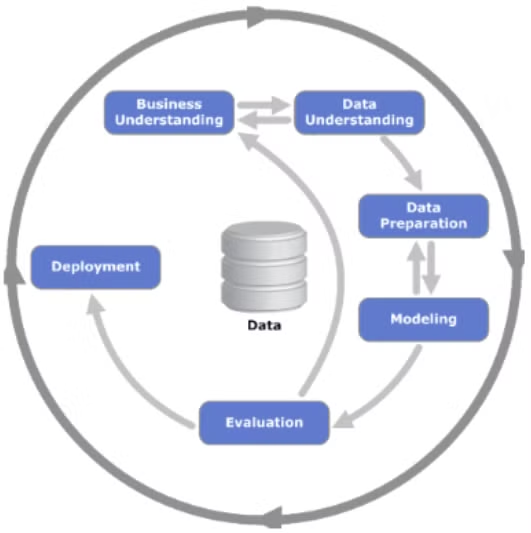
머신러닝 프로세스
- 비즈니스 이해 → 데이터 이해 → 데이터 전처리 → 모델링 → 평가 → 배포
- 모든 문제가 머신러닝으로 해결되는 것은 아님 (기초 통계료도 해결)
- 특화된 문제가 있음
- 전처리 (판다스)반에서는 Data Preparation 부분에 집중하여 공부함
- 전처리가 전체 프로세스 중에 가장 오래걸림 (너무 중요함)
분석용 파이썬 라이브러리와 프레임워크
- 다양한 라이브러리와 프레임워크가 있어 모델을 사용할 수 있지만, 모델에 대한 이해가 매우 중요함

이미지 출처
Key Python Libraries for Data Analysis and Code examples
다양한 데이터 관련 직무

이미지 출처
필수 Skill
- 데이터 베이스/클라우드 서비스(Azure, AWS 등) 이해
- 데이터 추출 및 가공 (SQL)
- 데이터 분석 및 모델링 (R, Python)
- 데이터 시각화 및 대시보드 개발
수업
Pandas 기본 개념
- 데이터 분석과 조작을 위한 Python 라이브러리
- 데이터프레임을 활용해 데이터를 효율적으로 처리
- 구조화된 데이터를 다룸(표 형식)
Pandas 주요 데이터 구조
- Series : 1차원 데이터 구조, 인덱스와 값으로 구성된 데이터 타입
- DataFrame : 2차원 데이터 구조, 행(row)과 열(column)로 구성된 표 형식의 데이터
- index : Series와 DataFrame에서 데이터의 행과 열을 참조하는 레이블
Pandas 주요 기능
| 기능 | 설명 |
|---|---|
| 데이터 읽기/쓰기 | 다양한 데이터 소스로부터 데이터를 불러오고 저장 (CSV, Excel, SQL 등) |
| 데이터 선택 및 필터링 | 데이터를 선택하고 필터링 (인덱싱, 슬라이싱, 조건을 사용한 필터링) |
| 데이터 정렬 | 데이터를 특정 열이나 인덱스를 기준으로 정렬 |
| 결측값 처리 | 데이터에 존재하는 결측값 처리 (결측값 제거, 데체) |
| 데이터 번형 | 데이터를 변형하거나 조작 (열 추가/삭제, 데이터 형식 변환) |
| 그룹화와 집계 | 데이터를 특정 기준으로 그룹화하고 그룹별로 집계 연산 수행 |
| 병합과 결합 | 두 개 이상의 데이터프레임을 병합하거나 결합 |
| 데이터 프레임의 통계분석 | 데이터의 기본 통계값 (평균, 표준편차, 최소값/최대값 등)을 계산하는 기능 |
Pandas의 장점
- 사용 용이성 : 직관적인 API 제공 (데이터 조작 용이)
- 데이터 호환성 : CSV, Excel, SQL 등 다양한 포맷의 데이터를 불러오고 저장
- 다양한 기능 : 데이터 필터링, 변환, 결합, 집계 등 데이터 분석에 필요한 기능 제공
- 빠른 데이터 처리 : 내부적으로 NumPy를 사용하여 고속의 데이터 처리 지원
Pandas의 사용 사례
- 탐색적 데이터 분석(EDA)
- 데이터 전처리
- 데이터 조작 및 변환
Pandas는 데이터 분석에서 필수적인 도구로, 데이터를 쉽게 다루고 분석할 수 있는 강력한 기능을 제공함
import pandas as pd
import saeborn as sns
from sqlalchemy import create_engine
titanic = sns.load_dataset('titanic')
engine = create_engine("sqlite:///titanic.db", echo=False)
titanic.to_sql('titanic_table, con=engine, index=False, if_exists='replace', method="multi")
df_from_sql = pd.read_sql_query('SELECT * FROM titanic_table', con=engine)
print(df_from_sql.head())- SQLAlchemy : Python에서 다양한 데이터베이스 (MySQL, PostgreSQL, SQLite 등)에 연결할 수 있는 라이브러리
판다스 기초 문법
- 데이터 프레임 구조 만들기
- 데이터 직접 정의
- 패키지를 이용한 데이터 불러오기 (seaborn titanic 데이터)
- 데이터셋 불러오기 (e.g. pd.read_csv() - csv 파일)
import pandas ad pd
df_bda=pd.DataFrame({
'분반':['데이터분석입문반','SQL문법기초반','파이썬문법기초반','데이터분석모델링반'],
'학회원수':[100,200,300,400],
'우수학회원수':[50,60,70,80]
})
df_bda분반 학회원수 우수학회원수
0 데이터분석입문반 100 50
1 SQL문법기초반 200 60
2 파이썬문법기초반 300 70
3 데이터분석모델링반 400 80- 데이터 프레임에 대한 구조 이해하기
- 데이터 프레임은 2차원 구조 → 행/열
- 행과 열을 기준으로 불러오면 됨
- 대괄호 안에 대괄호를 넣어 불러옴
- 데이터 프레임은 2차원 구조 → 행/열
df_bda[['분반','우수학회원수']]분반 우수학회원수
0 데이터분석입문반 50
1 SQL문법기초반 60
2 파이썬문법기초반 70
3 데이터분석모델링반 80- 시리즈 형태(1차원)으로 불러오려면 컬럼 하나만 사용
- 시리즈 형식에는 숫자형일 경우 연산 가능
df_bda[['분반']] # DataFrame df_bda['분반'] # Series- 데이터 살펴보기
df_bda.info() # 모든 정보 확인df_bda.describe() # 요약 통계치 확인df_bda.describe(include="all") # 요약 통계치 전체 확인df_bda.shape # 행과 열df_bda.colums # 컬럼 출력df_bda.types # 데이터 타입 출력df_bda.head() # 앞에 데이터 추출 (이 경우 5개)df_bda.head() # 뒤에 데이터 추출 (이 경우 5개)- 특정 데이터 선택
- iloc (Integer Location)
- 정수 기반 인덱스를 사용하여 데이터를 선택
df.iloc[행번호, 열번호]
- loc (Label Location)
- 레이블 기반 인덱스를 사용하여 데이터를 선택
df.loc[행레이블, 열레이블]
- iloc (Integer Location)

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.