
💡 도움이 되셨다면 ♡와 팔로우 부탁드려요! 미리 감사합니다.
결측치 (Missing Value)
-
데이터셋에서 특정 값이 존재하지 않거나 누락된 상태를 의미
-
기본적으로 평균으로 대치하거나 제거하곤 한다.
-
어떤 방법을 사용하는 것이 옳을까?
→ 결측치에 대해서 도메인 지식이 없으면 정말 위험하다.
다양한 기술적인 방법들은 수치적인 것들만 생각하는 것인데, 도메인보다 더 중요한 것은 없다.
모든 데이터는 데이터에 해당하는 도메인 기반으로 만들어진 것이기 때문이다.
제거
- 판단을 했을때 제거하는것이 확실하다면 제거하는게 맞다.
- 잘못된 데이터를 계속해서 대치하거나 보간하면 전체에 영향을 줄 수 있기 때문이다.
- 만약 결측치가 큰 영향을 주지 않는 소량의 데이터라면(약 1% 미만 정도?) 무시해도 좋다.
- 단, 제거하는 1%가 중요한 의미를 지닌다면 제거할 수 없다.
Missing Data Mechanisms
MCAR (Missing Completely At Random)
- 결측 데이터가 완전히 무작위로 발생하는 경우이다.
- 즉, 결측 데이터가 모든 다른 변수(관측된 다른 변수와 관측되지 않은 변수)에 대해 무관한 경우이다.

MAR (Missing At Random)
- 결측 데이터가 관측된 다른 변수에만 관련이 있는 경우이다.
- 즉, 결측이 발생할 확률이 관측된 다른 변수와 의해 설명될 수 있지만, 결측된 데이터 그 자체에는 관련이 없는 경우이다.
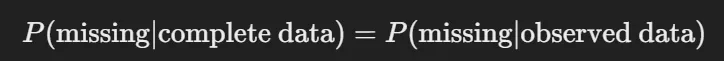
MNAR (Missing Not At Random)
- 결측 데이터가 관측되지 않은 변수나 결측된 데이터 자체와 관련이 있는 경우이다.
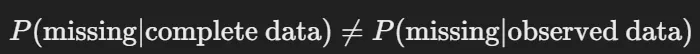
결측값 처리를 위한 접근법
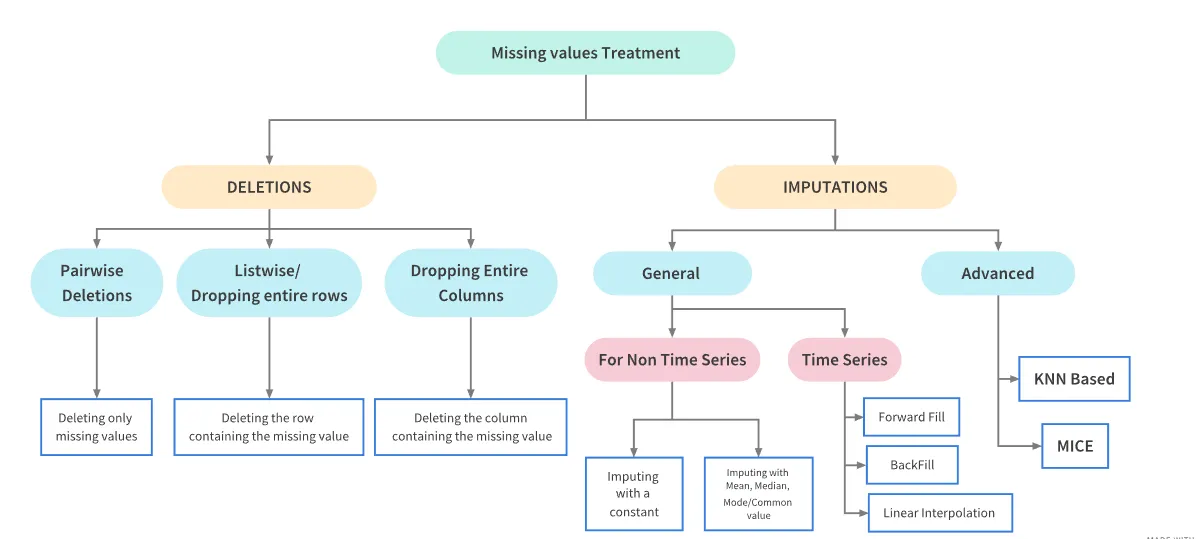
결측치 처리에 크게 두가지가 존재한다.
1. 삭제 (Deletions)
- Pairwise Deletions: 결측값만 삭제
- Listwise/Row Deletions: 결측값이 있는 행(row) 전체 삭제
- Column Deletions: 결측값이 많은 열(column) 삭제
2. 대치 (Imputations)
- 일반 대치 (General)
- 비시계열 데이터: 평균, 중앙값, 최빈값 또는 일정한 값으로 채움
- 시계열 데이터: 이전 값(Forward Fill), 다음 값(Back Fill), 또는 선형 보간법(Linear Interpolation)으로 채움
- 고급 대치 (Advanced)
- KNN: K-최근접 이웃을 사용해 유사한 값으로 대치
- MICE: 여러 번 예측 후 평균 대치 (다중 대치법)
결측값을 처리하는 다양한 고급 기법
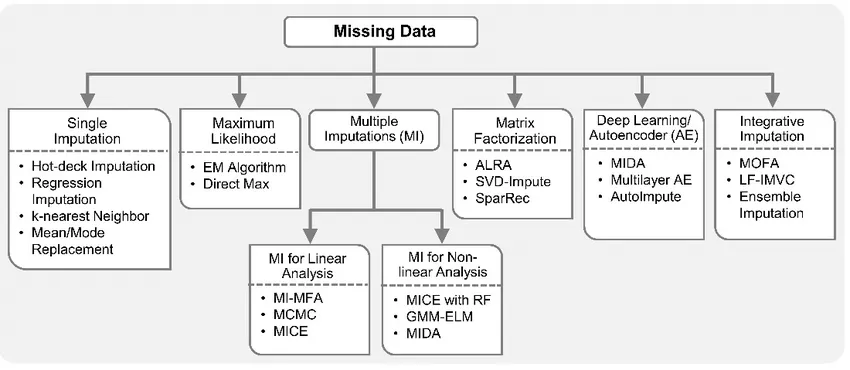
결측값을 처리하는 다양한 고급 기법을 보여준다.
- Single Imputation (단일 대치)
- 한 번만 대치: 평균, 회귀, KNN 등.
- Maximum Likelihood (최대 가능도)
- 결측값의 가능도를 최대화하여 추정: EM 알고리즘 등.
- Multiple Imputations (다중 대치)
- 결측값을 여러 번 예측하여 평균화: 선형(MICE 등), 비선형 분석용 기법.
- Matrix Factorization (행렬 분해)
- 행렬 분해를 통한 대치: SVD-Impute, SparRec 등.
- Deep Learning/Autoencoder (딥러닝/오토인코더)
- 딥러닝 기법을 이용한 대치: MIDA, 오토인코더 등.
- Integrative Imputation (통합 대치)
- 여러 기법을 결합해 결측값을 대치: MOFA, 앙상블 대치.
보간법과 보외법
보간법 (Interpolation)
- 주어진 데이터 범위 내에서 결측값을 예측하는 방법입니다.
- 이미 알고 있는 데이터 사이에서 값을 추정하기 때문에 비교적 정확한 결과를 기대할 수 있다.
보외법 (Extrapolation)
- 주어진 데이터 범위 밖의 값을 예측하는 방법이다.
- 데이터 범위 밖의 값을 예측하므로 불확실성이 크고, 예측의 정확도가 떨어질 수 있습니다.
Sklearn impute
Sklearn에서 결측치 처리를 위해 제공하는 모듈이 존재하며 다음과 같다.
- SimpleImputer
- 단순 대치 도구로, 평균, 중앙값 등으로 결측값을 대치한다.
- IterativeImputer
- 여러 변수를 고려하여 각 변수를 반복적으로 추정하는 다변량 대치 기법이다.
- KNNImputer
- K-최근접 이웃(K-Nearest Neighbors) 방법을 사용해 결측값을 유사한 다른 값으로 대치한다.
- MissingIndicator
- 결측값이 있는 위치를 이진 형태로 표시하는 지표이다.
MICE
- 다중 대치(Multiple Imputation)의 한 종류로 여러 번 반복적인 예측 과정을 통해 결측값을 채워나가는 방식이다.
- 변수 간 상관관계가 중요한 데이터셋에서 유용하며, 여러 번 대치하여 신뢰성 있는 결과를 도출한다.
단계
- Imputation (대치 단계): 결측값을 여러 번 채워서
m개의 완전한 데이터셋을 만듭니다. 각 대치는 가능한 값의 분포에서 추출된다. - Analysis (분석 단계): 생성된
m개의 데이터셋 각각에 대해 분석을 수행하여 모수 추정치와 오차를 계산한다. - Pooling (통합 단계):
m개의 분석 결과를 결합하여 최종 결과를 도출한다. 이를 통해 대치의 불확실성을 줄이고 신뢰성을 높인다.
여기서 m은 사용자거 설정해주는 값으로 3~10 사이로 설정한다.
예시
MICE에서 대치 단계의 단일 iteration이 어떻게 진행되는지 설명하는 예시
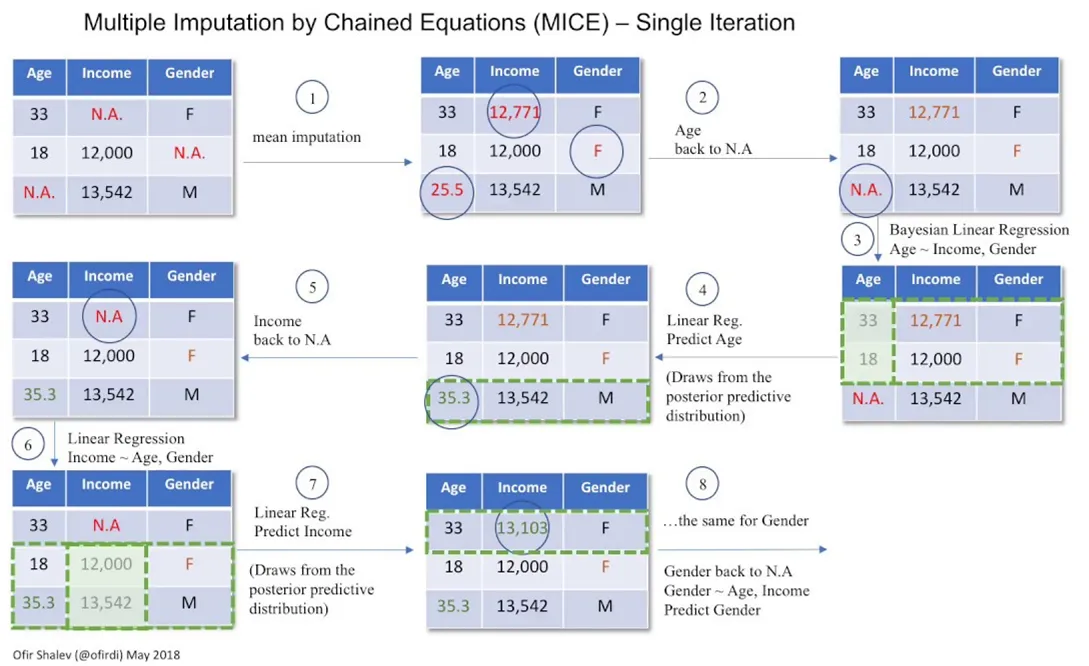
- 초기 대치값 설정: 결측값을 평균 등으로 임시 대치
- 변수 결측으로 되돌리기:
Age를 다시 결측값으로 돌림 - 첫 번째 변수 예측:
Income과Gender를 사용해Age예측 - 다음 변수 준비:
Income을 다시 결측값으로 돌림 - 두 번째 변수 예측:
Age와Gender로Income예측 - 마지막 변수 준비:
Gender를 다시 결측값으로 돌림 - 세 번째 변수 예측:
Age와Income을 사용해Gender예측 - 모든 결측값 대치 완료: 단일 반복(iteration) 완료
이러한 iteration을 m번 반복하게되면 m개의 서로 다른 데이터셋이 생성된다.
이후 후속 단계
분석 단계
- 평균과 표준 오차를 계산하거나 회귀 분석을 수행하여 각 데이터셋의 모수 추정치를 구한다.
통합 단계
- 분석 단계에서 얻은
m개의 결과 결합하여 최종 추정치를 도출한다.
💡 MICE와 Sklearn의 IteartiveImputer의 차이
- MICE : 결측치를 대치하는 서로 다른 데이터셋을 생성하고 분석, 통합 단계를 거쳐 최종 추정치를 도출한다.
- Sklearn의 IterativeImputer : 기본적으로 하나의 예측 모델(BaysianRidge, RandomForestRegressor 등)을 사용해 결측값을 예측한다. 기본적으로 **하나의 데이터셋에서 반복적인 대치 과정을 통해 결측값을 채우고, 최종적으로는 단일 대치 데이터셋만 생성한다. (
분석 단계,통합 단계가 생략, 결측값 대치에 집중**)Mice랑 다른 것 같은데 왜 유사하다고 하는걸까?
- 두 방법 모두 결측값을 대치하기 위해 회귀 모델을 사용하여 다른 변수들의 정보를 활용한다는 공통점
- 각 결측값을 예측할 때마다 반복이 진행된다. 즉, 하나의 변수를 대치한 후 그 대치 결과를 기반으로 다른 변수를 예측하는 방식이 두 방법의 공통점
실습
라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import SimpleImputer, KNNImputer, IterativeImputer데이터셋 로드
import statsmodels.api as sm
df = sm.datasets.get_rdataset("AirPassengers", package="datasets").data
# 'time' 컬럼을 datetime 형식으로 변환
df['time'] = pd.date_range(start='1949-01-01', periods=len(df), freq='MS')
df.set_index('time', inplace=True)
df.head()- 항공사 승객 수에 대한 시간 시계열 데이터를 사용한다.
결측치 임의 생성
# 데이터셋 복사
df_sp = df.copy()
# 결측치 구간 범위
nan_ranges = [(5, 15), (30, 40), (55, 65), (90, 110)]
for start, end in nan_ranges:
df.iloc[start:end, :] = np.nan결측치 데이터 시각화
plt.figure(figsize=(12, 6))
sns.lineplot(data = df, marker='o')
plt.title('Original')
plt.xlabel('Year-Month')
plt.ylabel('Number of Passengers')
plt.show()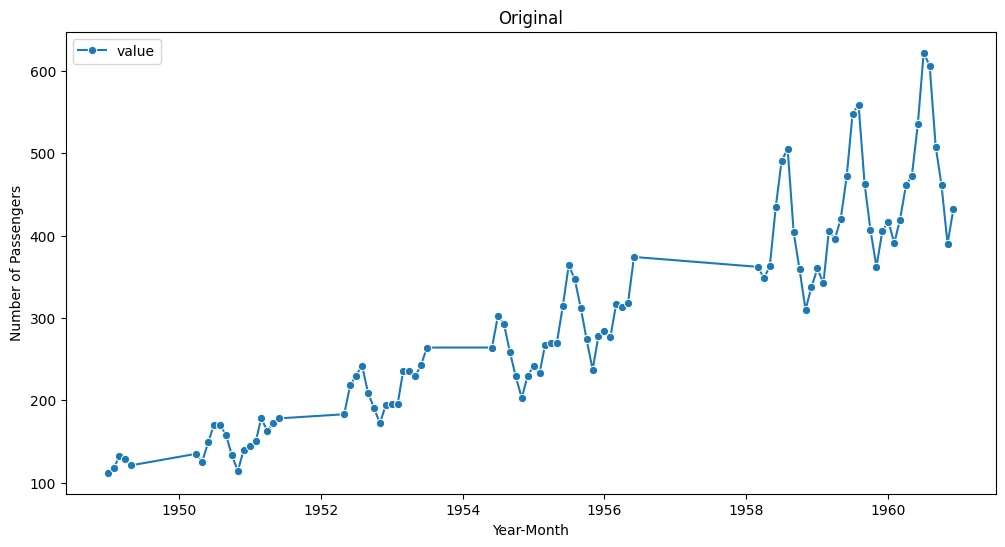
다양한 보간법 적용
# 1차 선형 보간법
df_linear = df.interpolate(method='linear')
# 2차 선형 보간법
df_quadratic = df.interpolate(method='quadratic')
# 평균 대치법
imputer_mean = SimpleImputer(strategy='mean')
df_mean = imputer_mean.fit_transform(df)
df_mean = pd.DataFrame(df_mean, columns = ['value'], index = df.index)
# 0값으로 대치
df_zero = df.fillna(0)
# KNN 방법으로 대치
imputer_knn = KNNImputer(n_neighbors=5)
df_knn = imputer_knn.fit_transform(df)
df_knn = pd.DataFrame(df_knn, columns = ['value'], index = df.index)
# MICE 다중대치법
imputer_mice = IterativeImputer()
df_mice = imputer_mice.fit_transform(df)
df_mice = pd.DataFrame(df_mice, columns = ['value'], index = df.index)- 1차 선형 보간법: 이전과 이후의 데이터 포인트를 연결하는 직선으로 결측값을 채움
- 2차 선형 보간법: 2차 다항식을 사용하여 더 부드러운 곡선으로 결측값을 채움
- 평균 대치법: 각 열의 평균값으로 결측값을 대치
- 0값으로 대치: 결측값을 0으로 채움
- KNN 방법으로 대치: K-최근접 이웃 알고리즘으로 주변 데이터의 평균으로 결측값을 채움
- MICE 다중대치법: 다른 변수의 정보를 사용해 결측값을 반복적으로 예측하여 대치
결측치 보간 시각화
fig, axs = plt.subplots(8,1,figsize=(12,12))
# 그래프를 그리기 전에 결측치 구간 강조
for ax in axs:
for start, end in nan_ranges:
ax.axvspan(df.index[start], df.index[end-1], color='red', alpha=0.3)
sns.lineplot(data= df, marker='o',ax=axs[0], legend='auto')
axs[0].set_title('Original Missing Data')
sns.lineplot(data= df_sp, marker='o',ax=axs[1], legend='auto')
axs[1].set_title('Original Data')
sns.lineplot(data= df_linear, marker='o',ax=axs[2], legend='auto')
axs[2].set_title('Linear')
sns.lineplot(data= df_quadratic, marker='o',ax=axs[3], legend='auto')
axs[3].set_title('quadratic')
sns.lineplot(data= df_mean, marker='o',ax=axs[4], legend='auto')
axs[4].set_title('mean')
sns.lineplot(data= df_zero, marker='o',ax=axs[5], legend='auto')
axs[5].set_title('zero')
sns.lineplot(data= df_knn, marker='o',ax=axs[6], legend='auto')
axs[6].set_title('df_knn')
sns.lineplot(data= df_mice, marker='o',ax=axs[7], legend='auto')
axs[7].set_title('df_mice')
plt.tight_layout()
plt.show()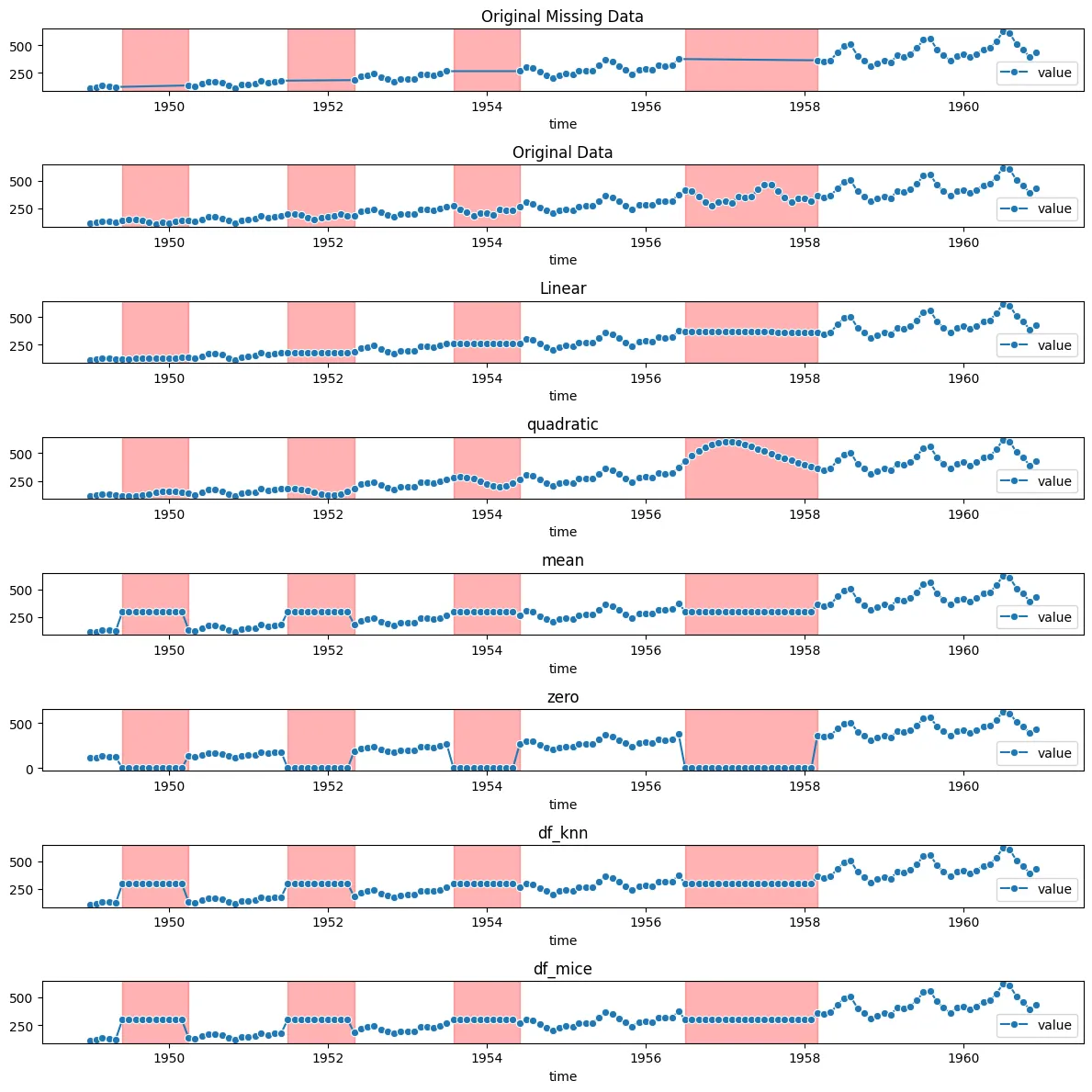
axvspan을 사용하여서드로, 수직 범위를 강조 표시, 특정 x축 값의 범위를 강조하여 시각적으로 강조함

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.