Feature Extraction vs Feature Selection

Feature Engineering
Feature의 정의 및 중요성
- 머신러닝이나 데이터 분석에 사용되는 개별 독립 변수를 의미한다.
- 데이터는 머신러닝의 핵심이다.
- 데이터 속에서 특징을 정제하고 선택하는 과정은 필수이다.

- 순서대로 표 데이터, 이미지, 텍스트 데이터
Feature Engineering
- 데이터 속에서 유의미한 특징을 정제하고 선택하는 과정으로, 데이터 품질을 높이고 모델의 성능을 향상시키기 위한 필수적인 단계입니다.
효과
- 모델 성능 향상
- 차원 축소
- 계산 효율성 향상
대표적인 종류
- Feature Extraction과 Feature Selection이 존재한다.

Feature Extraction
- 원본 데이터로부터 새로운 특징을 생성하여 중요한 정보를 더 잘 표현하면서 차원을 축소하는 과정이다.
PCA
- Feature Extraction의 대표 기법 중 하나이다.
- 데이터를 구성하는 여러 특성 중 가장 큰 분산을 설명하는 축(주성분)을 찾고, 데이터를 이 축으로 투영해 고차원의 데이터를 저차원으로 압축하는 방법
- 수치형 독립변수를 다룰때 적합한 방법이다.
코드 예시
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 예제 데이터 (2차원 데이터)
data = np.array([
[2.5, 2.4],
[0.5, 0.7],
[2.2, 2.9],
[1.9, 2.2],
[3.1, 3.0],
[2.3, 2.7],
[2, 1.6],
[1, 1.1],
[1.5, 1.6],
[1.1, 0.9]
])
# PCA를 사용하여 1차원으로 축소
pca = PCA(n_components=1)
data_1d = pca.fit_transform(data)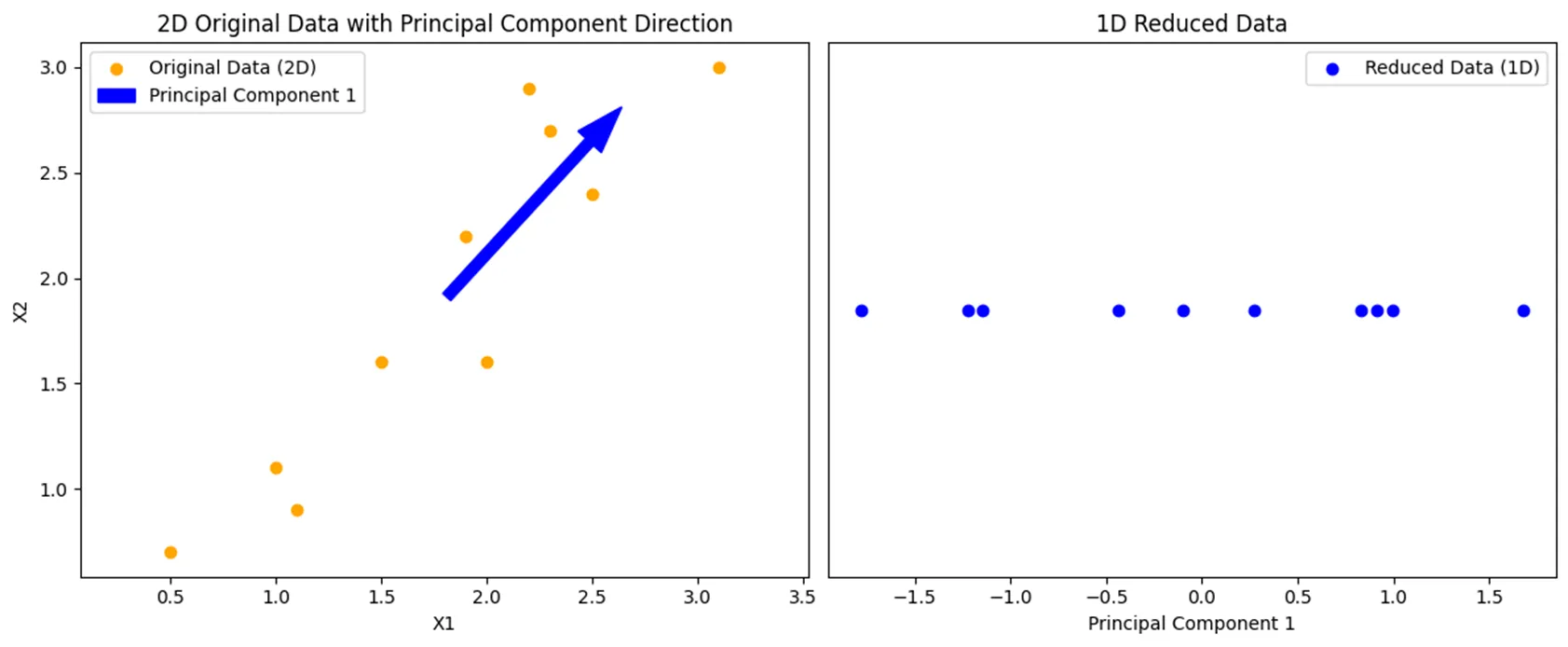
- 좌측의 X1, X2 특성을 가진 원본 데이터를 주성분 방향(파란색 화살표)의 1차원 데이터로 변환한 결과를 나타낸다.
Feature Selection
- 원본 데이터의 중요한 특성을 최대한 유지하면서, 분석에 필요하지 않은 특성을 제거하여 더 효율적이고 의미 있는 데이터로 만드는 과정
Feature Selection 방법 3가지
- Filter Method
- Wrapper Method
- Embedded Method
Filter Method
- 통계적인 속성을 조사하여 가장 유의미한 특성을 선택하는 방법이다.

카이제곱 분석
- 카이제곱 분석의 대표 기법 중 하나이다.
- 두 범주형 변수 간의 독립성 또는 관련성을 검정하기 위한 통계적 방법으로, 관측된 빈도와 기대 빈도 간의 차이를 측정한다.
- 두 변수 간의 상관 관계가 유의미한지 판단할 수 있다.
- 독립변수와 종속변수가 모두 범주형일 때 적용한다.
코드 예시
import pandas as pd
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.preprocessing import LabelEncoder
# 예제 데이터 생성
data = pd.DataFrame({
'Age Group': ['20대', '30대', '40대', '50대', '20대', '30대', '40대', '50대'],
'Income Level': ['Low', 'Medium', 'High', 'Medium', 'High', 'Low', 'Medium', 'High'],
'Promotion Response': ['Responded', 'Not Responded', 'Responded', 'Responded', 'Not Responded', 'Responded', 'Not Responded', 'Responded']
})
# 범주형 변수를 레이블 인코딩
label_encoders = {}
for column in ['Age Group', 'Income Level', 'Promotion Response']:
le = LabelEncoder()
data[column] = le.fit_transform(data[column])
label_encoders[column] = le
# 독립 변수 (Age Group, Income Level)와 종속 변수 (Promotion Response) 구분
X = data[['Age Group', 'Income Level']]
y = data['Promotion Response']
# SelectKBest와 chi2 사용 (상위 1개 변수 선택)
selector = SelectKBest(score_func=chi2, k=1)
X_new = selector.fit_transform(X, y)
# 선택된 특성과 점수 출력
selected_features = X.columns[selector.get_support()]
chi2_scores = selector.scores_
print("선택된 특성:", selected_features)
print("chi2 점수:", chi2_scores)선택된 특성: Index(['Age Group'], dtype='object’)
chi2 점수: [0.8 0.53333333]- 실행결과 chi2 점수가 더 높은
Age Group이 목표 변수와 유의미한 연관성이 있을 가능성이 있다고 판단되어 선택된다.
Wrapper Method
- 시행착오를 통해 가장 높은 품질의 예측을 만드는 특성의 부분조합을 찾는 방법이다.
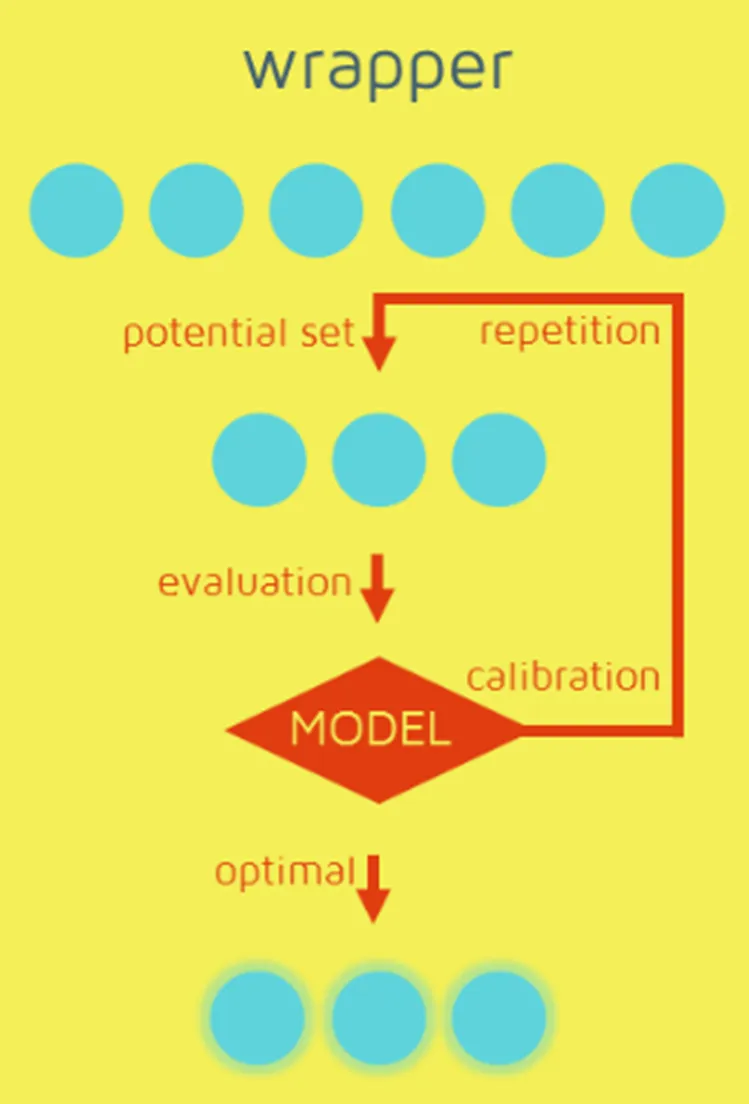
RFE(Recursive Feature Elimination)
- 모델 성능을 기준으로 반복적인 학습과 평가를 통해 최적의 특성 조합을 찾는 방식이다.
- 최종 모델을 학습하기 전에 특정 알고리즘(예: 선형 회귀, SVM 등)을 사용하여 각 특성의 중요도를 평가하고, 가장 덜 중요한 특성을 하나씩 제거해 나간다.
- 독립변수나 종속변수의 유형이 상관없이 사용 가능하다.
코드 예시
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 데이터셋 로드
data = load_iris()
X = data.data
y = data.target
# 훈련과 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 모델 정의
model = LogisticRegression(max_iter=1000)
# RFE를 사용하여 최적의 특성 조합 찾기
rfe = RFE(estimator=model, n_features_to_select=2) # 2개의 최종 특성을 선택
rfe.fit(X_train, y_train)
# 결과 출력
print("Selected features:", rfe.support_)
print("Feature ranking:", rfe.ranking_)Selected features: [False False True True]
Feature ranking: [3 2 1 1]- 가장 높은 순위로 평가된 3번째 특성(
petal length (cm))과 4번째 특성(petal width (cm))이 선택되었다.
Embedded Method
- 학습 알고리즘의 훈련 단계를 확장하거나 일부로 구성하여 가장 좋은 특성의 부분 조합을 선택하는 방법이다.
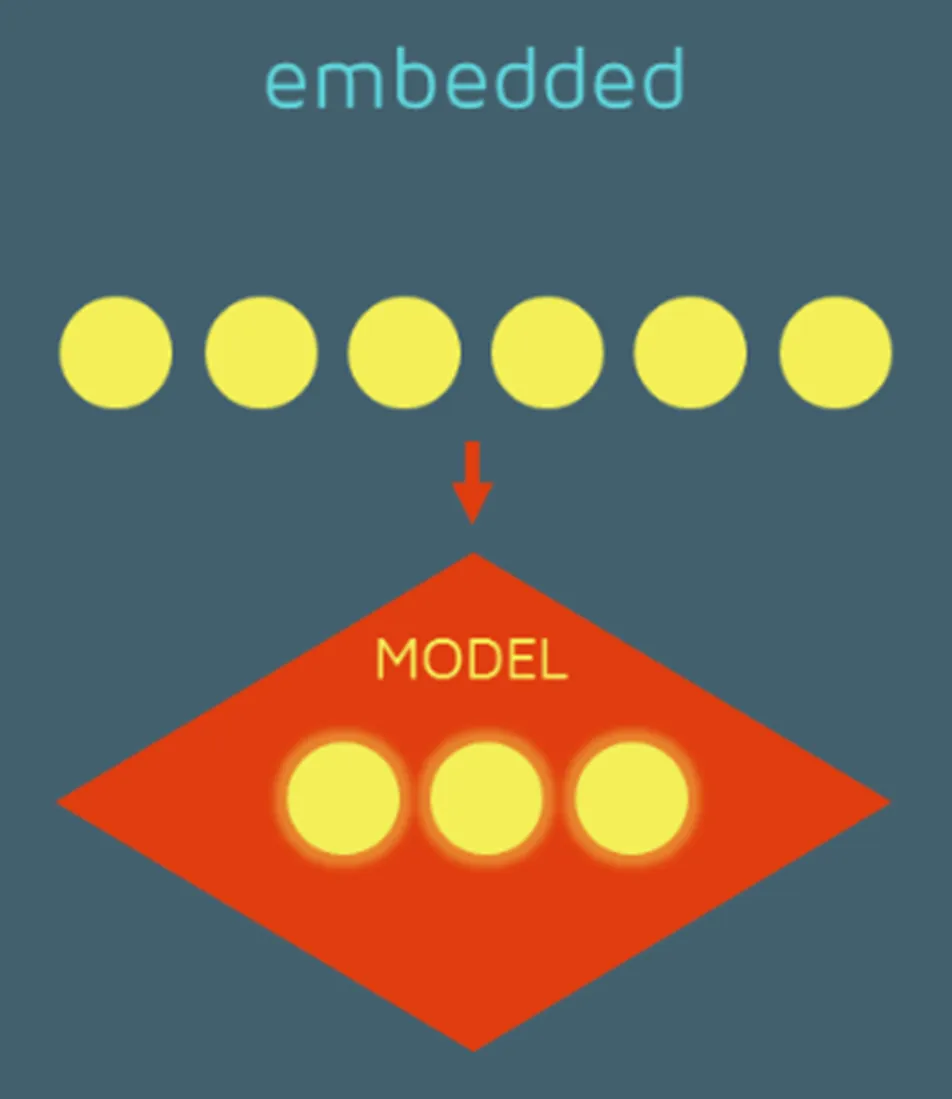
Feature Importance
- 학습 모델의 학습 과정에서 각 특성의 중요도를 계산하여 특성 선택에 활용하는 기법이다.
- 모델은 특성 분할로 인한 정보 이득을 기반으로 특성 중요도를 측정하며, 중요도가 낮은 특성들을 걸러낸다.
- 독립변수나 종속변수의 유형이 상관없이 사용 가능하다.
코드 예시
# 필요한 라이브러리 불러오기
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
import pandas as pd
import matplotlib.pyplot as plt
# 데이터 불러오기
data = load_iris()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# Random Forest 모델 학습
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X, y)
# Feature Importance 추출
rf_importances = rf_model.feature_importances_
rf_feature_importance_df = pd.DataFrame({'Feature': X.columns, 'Importance': rf_importances})
rf_feature_importance_df = rf_feature_importance_df.sort_values(by='Importance', ascending=False)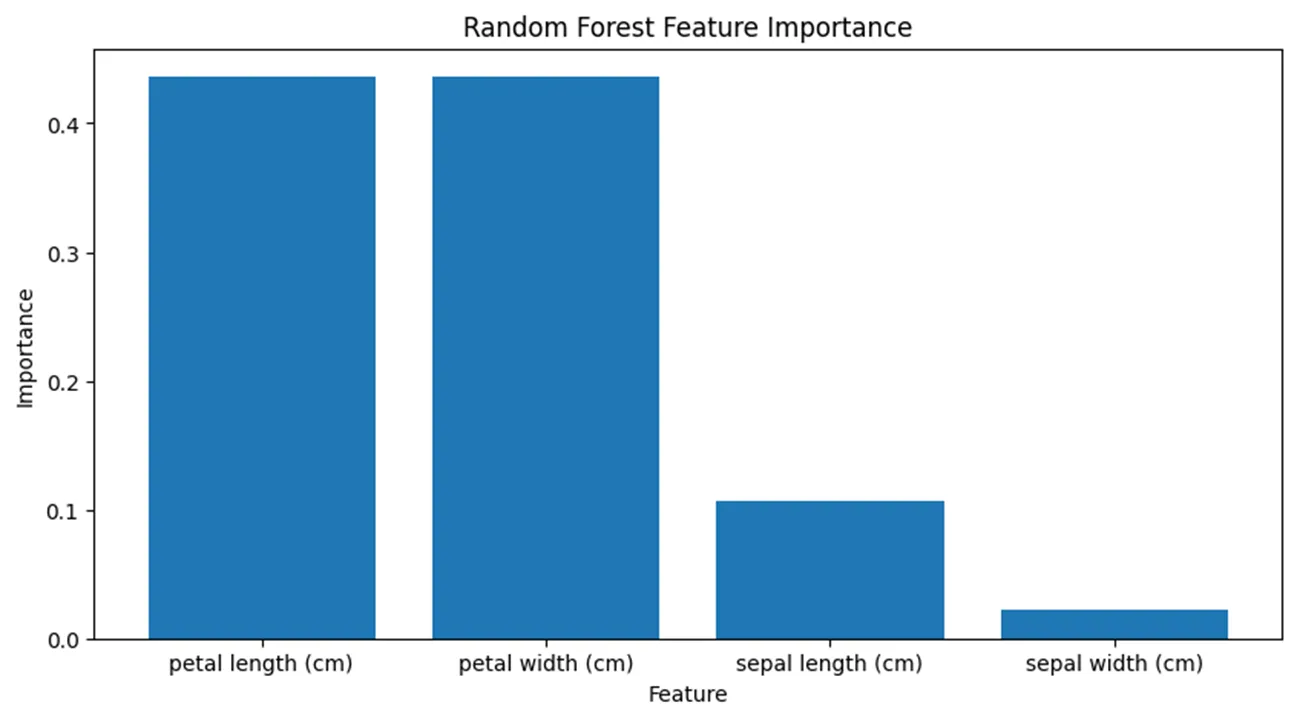
- 가장 높은 중요도로 평가된 특성은 3번째 특성(
petal length (cm))과 4번째 특성(petal width (cm))이다. - 이 두 특성이 목표 변수 예측에 가장 큰 기여를 하므로, 모델 학습 시 이들을 선택하는 것이 효과적일 것이다.
Feature Extraction vs Feature Selection
- 공통점
- 불필요한 정보를 줄이고 모델 성능을 향상시키는 것이 목표이다.
- 차이점
- Feature Extraction은 새로운 특성을 생성하며, 사람이 이해하기 어려울 수 있는 무작위한 숫자의 집합을 만듭니다.
- Feature Selection은 기존 특성 중 중요한 것만 선택하여 해석 가능한 모델을 유지할 수 있습니다.
- 데이터에 따라 적합한 기법이 달라질 수 있으며, 서로 다른 데이터에 대하여 같은 기법이라도 성능이 다르게 나타날 수 있어 신중한 적용이 필요하고, 이는 실험을 통해 확인해야 한다.
참고자료

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.
Feature Extraction과 Feature Selection 가장 큰 제목 밑에 있는 설명이 서로 똑같네요. Feature Extraction 쪽의 설명이 잘못된 것으로 보입니다.