
이 블로그글은 2019년 조재영(Kevin Jo), 김승수(SeungSu Kim)님의 딥러닝 홀로서기 세미나를 수강하고 작성한 글임을 밝힙니다.
Assignment #3 Review
Goal
- MLP를 이용하여 Cifar-10 데이터셋을 학습하고 다양한 파라미터로 실험하여 모델 성능 높이기
문제점 / 해결책
하이퍼 파라미터 튜닝을 할 대 test accuracy를 봐도 되는가?
- 지난번 코드에서
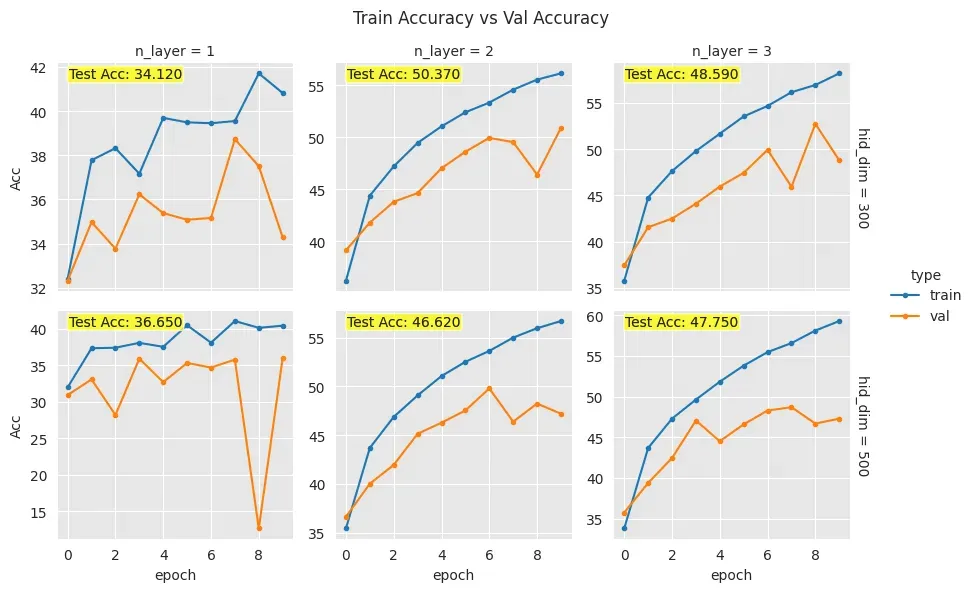
plt.text를 통해 test accuracy를 표시한 것은 큰 오류이다. Test accuracy는 모델의 최종 성능 평가를 위해 보존된 데이터로, 하이퍼파라미터 튜닝 중에 확인하거나 활용해서는 안된다. 이를 통해 튜닝을 진행하면 Test 데이터에 과적합될 위험이 있으며, 모델의 일반화 성능 평가가 왜곡될 수 있다. Test 데이터는 반드시 최종 평가 단계에서만 사용해야 합니다.
코드 수정
var1 = 'n_layer'
var2 = 'hid_dim'
df = load_exp_result('exp1')
list_v1 = df[var1].unique()
list_v2 = df[var2].unique()
list_data = []
for value1 in list_v1:
for value2 in list_v2:
row = df.loc[df[var1] == value1]
row = row.loc[df[var2] == value2]
train_accs = list(row.train_accs)[0]
val_accs = list(row.val_accs)[0]
max_val_acc = max(val_accs) # 최대 val accuracy 계산
print(f"Max Val Accuracy: {max_val_acc}")
for epoch, train_acc in enumerate(train_accs):
list_data.append({'type': 'train', 'Acc': train_acc, 'max_val_acc': max_val_acc, 'epoch': epoch, var1: value1, var2: value2})
for epoch, val_acc in enumerate(val_accs):
list_data.append({'type': 'val', 'Acc': val_acc, 'max_val_acc': max_val_acc, 'epoch': epoch, var1: value1, var2: value2})
df = pd.DataFrame(list_data)
g = sns.FacetGrid(df, row=var2, col=var1, hue='type', margin_titles=True, sharey=False)
g = g.map(plt.plot, 'epoch', 'Acc', marker='.')
def show_acc(x, y, metric, **kwargs):
plt.scatter(x, y, alpha=0.3, s=1)
metric = "Max Val Acc: {:1.3f}".format(list(metric.values)[0])
plt.text(0.05, 0.95, metric, horizontalalignment='left', verticalalignment='center', transform=plt.gca().transAxes, bbox=dict(facecolor='yellow', alpha=0.5, boxstyle="round,pad=0.1"))
g = g.map(show_acc, 'epoch', 'Acc', 'max_val_acc')
g.add_legend()
g.fig.suptitle('Train Accuracy vs Val Accuracy')
plt.subplots_adjust(top=0.89)
plt.show()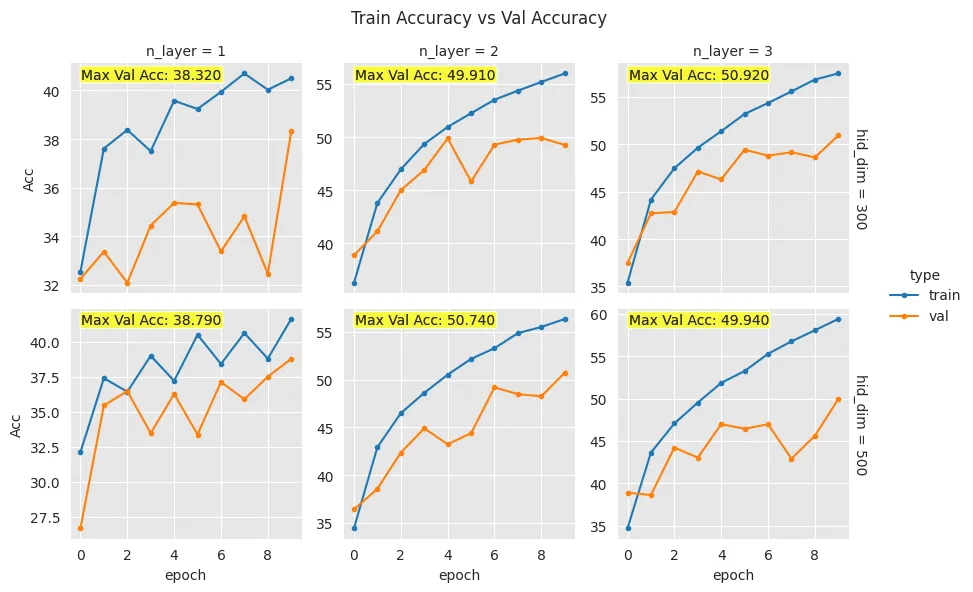
- Test accuracy 대신 Max validation accuracy를 확인하게 코드를 수정한다.
Optimizer를 Adam으로 했을때 학습이 잘 안되는데 이유는?
- Adam의 경우 학습률이 너무 작거나 크면 학습이 잘되지 않는다.
- 학습률이 크면 손실이 발산하거나 최적점을 지나칠 수 있다.
- 학습률이 작으면 모델이 수렴하지 못하거나, 너무 느리게 학습이 진행된다.
- 해결 방법:
- 학습률 조정(예: 0.0001~0.01 사이를 실험)
- 학습률 감소(Learning Rate Decay) 기법 적용
- 데이터셋의 특성과 관련된 문제일 수있다.
- Adam은 희소한 데이터에서 잘 작동한다. 반면 밀집된 데이터의 경우 SGD와 같은 단순한 최적화 방법이 더 잘 작동 할 수도 있다.
- 해결 방법:
- SGD, RMSProp 등 다른 Optimizer도 실험
Ensemble을 사용하여 성능을 높일 수 없을까?
- 서로 다른 Seed로 동일한 모델 n개 앙상블
- 동일한 모델 구조와 데이터로 시드만 다르게 설정해 학습.
- 랜덤성으로 인해 모델 간 다양성을 확보하고 다수결(분류) 또는 평균(회귀)으로 결합.
- 장점: 간단하고 예측 안정성 향상.
- 단점: 데이터 다양성 부족으로 성능 향상이 제한적일 수 있음.
- 서로 다른 데이터셋에 이종 모델 n개 앙상블
- 데이터셋을 다양화(샘플링, 전처리 등)하고, 서로 다른 모델을 학습시켜 결합.
- 장점: 모델 간 다양성이 높아 앙상블 효과 극대화.
- 단점: 구현 복잡성과 자원 소모 증가.

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.