
이 블로그글은 2019년 조재영(Kevin Jo), 김승수(SeungSu Kim)님의 딥러닝 홀로서기 세미나를 수강하고 작성한 글임을 밝힙니다.
💡 도움이 되셨다면 ♡와 팔로우 부탁드려요! 미리 감사합니다.
Github 링크 : 실습 코드 링크
어떻게 Experiment 결과를 저장할까?
Goal
- Args에 있는 실험 세팅 값들을 저장해야 한다.
- Epoch에 따른 train loss, val loss, train acc, val acc를 저장해야 한다. (단, loss의 경우 리스트 형태)
- 최종 train acc, val acc, test acc도 저장해야 한다.
해결책 고민
- 각 실험 결과를 딕셔너리에 넣어 append하는거 어떨까?
→ 실험 결과가 RAM에 올라가 있다가 인터넷이나 프로세스가 종료되는 상황이 오면 실험 결과가 다 날아간다.
→ 딕셔너리를 하드디스크에 파일 형태로 저장하는 것이 어떨까?
해결책 : JSON 포맷을 활용하자!!
JSON 포맷을 사용한 실험 결과 저장
JSON
- 웹 상에서 데이터를 송수신할 때 많이 사용하는 규격
- 프로그래밍 언어에 상관없이 호환되는 파일 규격 (Python도 가능)
파일 이름 설정
파일이름을 어떻게 할까?
- 시간_랜덤 숫자.json (e.g. 190128_3242.json)
→ 같은 실험 세팅으로 다시 돌리면 시간에 따라 다른 json 파일이 또 생긴다.
- 변수 값들을 파일 제목에 같이 넣자 (e.g. N_layer_4_hid_dim_100.json)
→ 하이퍼파라미터가 많아지면 최대 파일 이름 길이를 초과해버림
해결책 : 실험 이름 + 실험 세팅 값의 해쉬.json으로 파일 이름을 정하자!!
💡 해쉬 (Hash)
- 데이터를 고정된 크기의 고유한 값으로 변환하는 함수이다.
- 입력값이 같으면 항상 같은 해시 값이 생성되며, 입력이 조금이라도 다르면 완전히 다른 해시 값이 나온다.
- 데이터의 무결성 : 데이터가 원본 그대로 유지되었는지 확인하는 과정
- 고유 식별 : 대상을 유일하게 구분할 수 있는 값을 부여하는 것
json, hashlib 튜토리얼
json을 이용해 json 포맷으로 파일 저장하기
import json
a = {'value' : 5, 'value2': 10, 'seq' : [1, 2, 3, 4, 5]}
filename = 'test.json'
with open(filename, 'w') as f:
json.dump(a, f)
with open(filename, 'r') as f:
result = json.load(f)
print(result)json.dump(): 파이썬 딕셔너리를 json 형태로 저장json.load(): json 파일을 읽어 파이썬 딕셔너리 형태로 가져오기- 자세한 내용은 다음 링크를 확인하세요 : json 톺아보기
hashlib을 이용해 파일 이름 정하기
import hashlib
setting = {'value' : 5, 'value2': 10, 'seq' : [1, 2, 3, 4, 5], 'exp_name' : 'exp1'}
exp_name = setting['exp_name']
hash_key = hashlib.sha1(str(setting).encode()).hexdigest()[:6]
filename = f'{exp_name}-{hash_key}.json'
print(filename)hashlib.sha1(): 딕셔너리를 str으로 변환하고encode()함수를 적용하여 binary 형태로 변환 후SHA-1알고리즘 적용- 파일 이름을
exp_name(실험 이름)_ hash_key(해시로 변환한 세팅값).json형태로 둔다. - 자세한 내용은 다음 링크를 확인하세요 : hashlib 톺아보기
실습
Lec16. Assignment #2 Review 문서의 코드부분과 거의 동일하며experiment() 에 바뀜 Result 부분만 변화됨
Experiment
def experiment(partition, args):
net = MLP(args.in_dim, args.out_dim, args.hid_dim, args.n_layer, args.act, args.dropout, args.use_bn, args.use_xavier)
if args.device == 'cuda':
net.cuda()
criterion = nn.CrossEntropyLoss()
if args.optim == 'SGD':
optimizer = optim.RMSprop(net.parameters(), lr=args.lr, weight_decay=args.l2)
elif args.optim == 'RMSprop':
optimizer = optim.RMSprop(net.parameters(), lr=args.lr, weight_decay=args.l2)
elif args.optim == 'Adam':
optimizer = optim.Adam(net.parameters(), lr=args.lr, weight_decay=args.l2)
else:
raise ValueError('In-valid optimizer choice')
# ===== List for epoch-wise data ====== #
train_losses = []
val_losses = []
train_accs = []
val_accs = []
# ===================================== #
for epoch in range(args.epoch): # loop over the dataset multiple times
ts = time.time()
net, train_loss, train_acc = train(net, partition, optimizer, criterion, args)
val_loss, val_acc = validate(net, partition, criterion, args)
te = time.time()
# ====== Add Epoch Data ====== #
train_losses.append(train_loss)
val_losses.append(val_loss)
train_accs.append(train_acc)
val_accs.append(val_acc)
# ============================ #
print(f'Epoch {epoch}, Acc(train/val): {train_acc:2.2f}/{val_acc:2.2f}, Loss(train/val) {train_loss:2.2f}/{val_loss:2.2f}. Took {te-ts:2.2f} sec')
test_acc = test(net, partition, args)
# ======= Add Result to Dictionary ======= #
result = {}
result['train_losses'] = train_losses
result['val_losses'] = val_losses
result['train_accs'] = train_accs
result['val_accs'] = val_accs
result['train_acc'] = train_acc
result['val_acc'] = val_acc
result['test_acc'] = test_acc
return vars(args), result
# ===================================== #- epoch마다 train_loss, val_loss, train_acc, val_loss를 list를 만들어 저장하고 최종 학습 모델에 계산된 test_acc와 함께
result딕셔너리를 만들어 저장해줌 - 함수의 반환값
result: 실험 결과 저장 (딕셔너리)vars(args): 설정한 실험 하이퍼파라미터 저장 (딕셔너리)
실험 결과 json 포맷 저장 함수
def save_exp_result(setting, result):
exp_name = setting['exp_name']
del setting['epoch']
del setting['test_batch_size']
del setting['device']
hash_key = hashlib.sha1(str(setting).encode()).hexdigest()[:6]
filename = './results/{}-{}.json'.format(exp_name, hash_key)
result.update(setting)
with open(filename, 'w') as f:
json.dump(result, f)- 전체적인 과정은 이전 설명과 동일하나 다음의 과정만 추가
result에setting(이전의var(args))을 update를 통해 넣어준다.
저장한 모든 json 실험 결과 데이터 불러오는 함수
def load_exp_result(exp_name):
dir_path = './results'
filenames = [f for f in listdir(dir_path) if isfile(join(dir_path, f)) if '.json' in f]
list_result = []
for filename in filenames:
if exp_name in filename:
with open(join(dir_path, filename), 'r') as infile:
results = json.load(infile)
list_result.append(results)
df = pd.DataFrame(list_result) # .drop(columns=[])
return dfexp_name(실험 이름)을 가지는 json 파일을 모두 가져와 내용을 딕셔너리 형태로 받아 리스트에 저장하고 데이터프레임 형태로 반환한다.
하이퍼파리미터를 변경하며 실행
for var1 in list_var1:
for var2 in list_var2:
setattr(args, name_var1, var1)
setattr(args, name_var2, var2)
print(args)
setting, result = experiment(partition, deepcopy(args))
save_exp_result(setting, result)- 하이퍼파라미터 변경시
setattr()내장 함수를 사용하여 실험마다 변경되는 하이퍼파라미터를 설정해준다.
setattr()
- Python에서 객체의 속성 값을 동적으로 설정할 때 사용되는 함수이다
기본 형식
setattr(object, attribute_name, value)
- object: 속성을 설정할 객체
- attribute_name: 설정할 속성의 이름을 문자열로 지정
- value: 설정할 속성의 값
실험 결과 시각화 (seaborn, matplotlib 사용)
epoch이 끝났을때 최종 acc 값 비교하기 (train/validate/test)
result = load_exp_result('exp1')
fig, ax = plt.subplots(1, 3)
fig.set_size_inches(15, 6)
sns.set_style("darkgrid", {'axes.facecolor' : ".9"})
sns.barplot(x = 'n_layer', y ='train_acc', hue='hid_dim', data=result, ax=ax[0])
sns.barplot(x = 'n_layer', y ='val_acc', hue='hid_dim', data=result, ax=ax[1])
sns.barplot(x = 'n_layer', y ='test_acc', hue='hid_dim', data=result, ax = ax[2])
plt.show()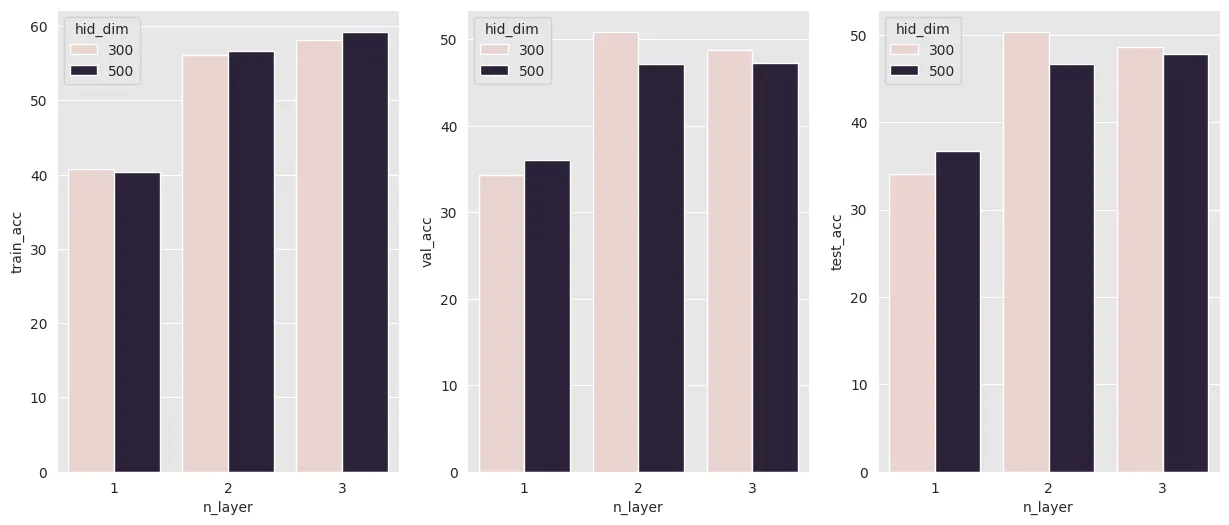
- train, val, test 데이터에 대한 실험 결과를
barplot형태로 그림 - 구체적인 설정
- x 축 : layer 수
- y 축 : accuracy로 설정
- hue : hidden layer 차원 수
각 실험에서 epoch에 따른 loss의 변화 확인하기
# 각 실험에서 epoch에 따른 loss의 변화 확인
var1 = 'n_layer'
var2 = 'hid_dim'
df = load_exp_result('exp1')
# 실험한 종류
list_v1 = df[var1].unique()
list_v2 = df[var2].unique()
list_data = []
for value1 in list_v1:
for value2 in list_v2:
row = df.loc[df[var1]==value1]
row = row.loc[df[var2]==value2]
train_losses = list(row.train_losses)[0]
val_losses = list(row.val_losses)[0]
for epoch, train_loss in enumerate(train_losses):
list_data.append({'type':'train', 'loss':train_loss, 'epoch':epoch, var1:value1, var2:value2})
for epoch, val_loss in enumerate(val_losses):
list_data.append({'type':'val', 'loss':val_loss, 'epoch':epoch, var1:value1, var2:value2})
df = pd.DataFrame(list_data)
# row를 'hid_dim' 변수로 나누고, col을 'n_layer' 변수로 나누어서 grid를 생성
g = sns.FacetGrid(df, row=var2, col=var1, hue='type', margin_titles=True, sharey=False)
# 각 grid에 x축은 'epoch', y축은 'loss'로 선 그래프를 그림. marker='.'로 각 점을 표시
g = g.map(plt.plot, 'epoch', 'loss', marker='.')
g.add_legend()
g.fig.suptitle('Train loss vs Val loss')
plt.subplots_adjust(top=0.89)
plt.show()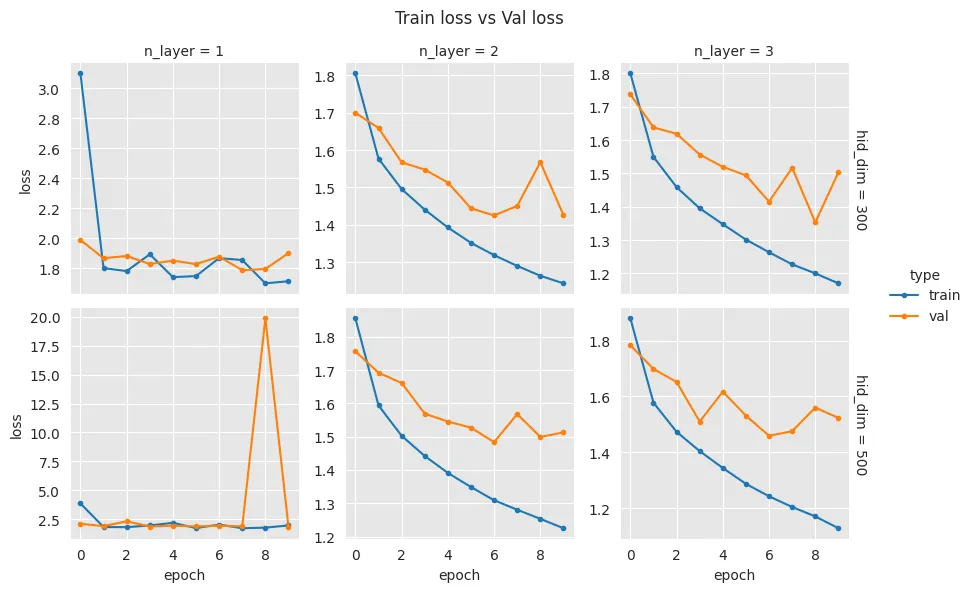
FacetGrid(): 데이터의 특정 변수 값에 따라 격자 형태로 분할된 그래프를 생성할 수 있게 해주는 기능이다.- 행(
row):hid_layer차원 수 - 열(
col):layer수 - 색상(
hue):train/val타입
- 행(
map(): 분할된 각 셀에 대해 지정된 플롯(여기서는lineplot)을 그리는 역할을 한다.- x축:
epoch - y축:
loss값
- x축:
epoch에 따른 Acc 확인하기
var1 = 'n_layer'
var2 = 'hid_dim'
df = load_exp_result('exp1')
list_v1 = df[var1].unique()
list_v2 = df[var2].unique()
list_data = []
for value1 in list_v1:
for value2 in list_v2:
row = df.loc[df[var1]==value1]
row = row.loc[df[var2]==value2]
train_accs = list(row.train_accs)[0]
val_accs = list(row.val_accs)[0]
test_acc = list(row.test_acc)[0]
for epoch, train_acc in enumerate(train_accs):
list_data.append({'type':'train', 'Acc':train_acc, 'test_acc':test_acc, 'epoch':epoch, var1:value1, var2:value2})
for epoch, val_acc in enumerate(val_accs):
list_data.append({'type':'val', 'Acc':val_acc, 'test_acc':test_acc, 'epoch':epoch, var1:value1, var2:value2})
df = pd.DataFrame(list_data)
g = sns.FacetGrid(df, row=var2, col=var1, hue='type', margin_titles=True, sharey=False)
g = g.map(plt.plot, 'epoch', 'Acc', marker='.')
def show_acc(x, y, metric, **kwargs):
plt.scatter(x, y, alpha=0.3, s=1)
metric = "Test Acc: {:1.3f}".format(list(metric.values)[0])
plt.text(0.05, 0.95, metric, horizontalalignment='left', verticalalignment='center', transform=plt.gca().transAxes, bbox=dict(facecolor='yellow', alpha=0.5, boxstyle="round,pad=0.1"))
g = g.map(show_acc, 'epoch', 'Acc', 'test_acc')
g.add_legend()
g.fig.suptitle('Train Accuracy vs Val Accuracy')
plt.subplots_adjust(top=0.89)
plt.show()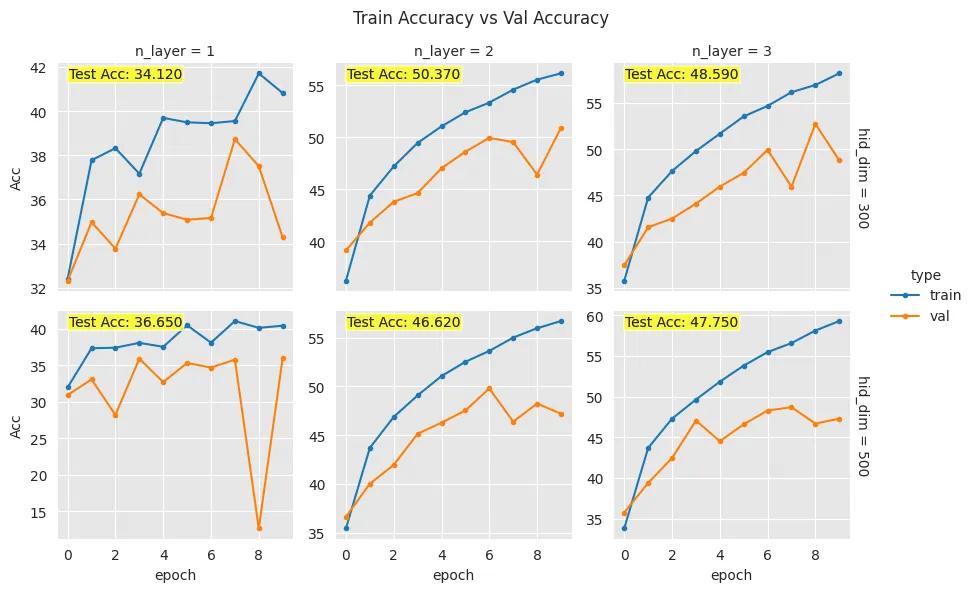
FacetGrid(): 데이터의 특정 변수 값에 따라 격자 형태로 분할된 그래프를 생성할 수 있게 해주는 기능이다.- 행(row):
hid_dim(hidden layer 차원 수) - 열(col):
n_layer(layer 수) - 색상(hue):
train/val타입 구분
- 행(row):
map(): 분할된 각 셀에 대해 지정된 플롯(여기서는lineplot)을 그리는 역할을 한다.- x축:
epoch(에포크 수) - y축:
Acc(정확도)
- x축:
show_acc():plt.text()를 이용해 각 셀에test_acc(테스트 정확도)를 표시하는 함수이다.

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.