
이 블로그글은 조재영(Kevin Jo), 김승수(SeungSu Kim)님의 2019년 딥러닝 홀로서기 세미나 영상을 수강하고 작성한 글임을 밝힙니다.
머신러닝
머신러닝이란?
💡“The Field Of Study That Gives Computers The Ability To Learn Without Being Explicitly Programmed” - Arthur Samuel, 1959
- rull base의 프로그래밍 없이 알아서 학습한다.
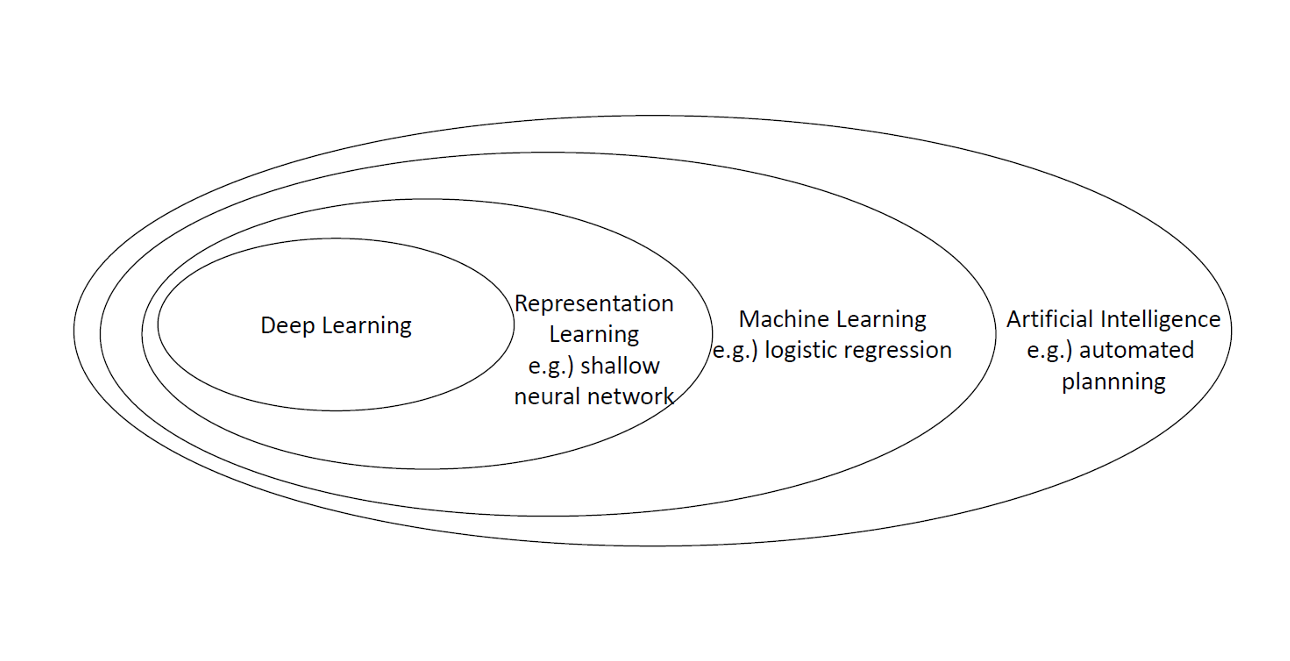
→ 딥러닝은 머신러닝에 범주에 속하며, Feature extractor이다
머신러닝의 범주
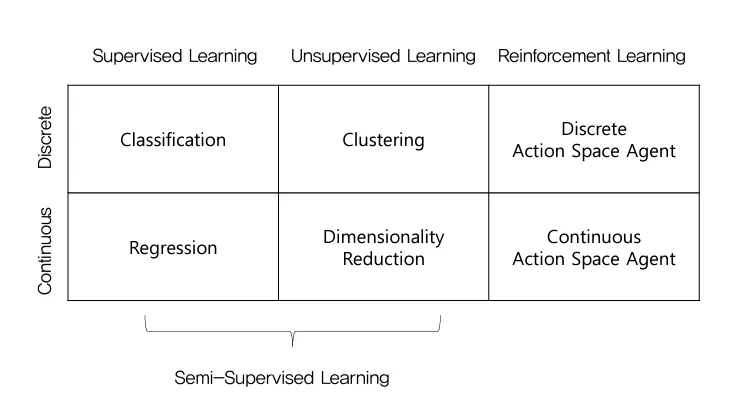
- Supervised Learning : 레이블이 있는 데이터로 학습하여 새로운 데이터를 예측하는 방법
- Unsupervised Learning : 레이블 없이 데이터의 패턴을 발견하는 학습 방법
- Reinforcement Learning : 보상을 통해 최적의 행동을 학습하는 방법
- Semi-Supervised Learing : 일부 데이터에만 레이블을 부여해 학습하는 방법.
Regression Problem
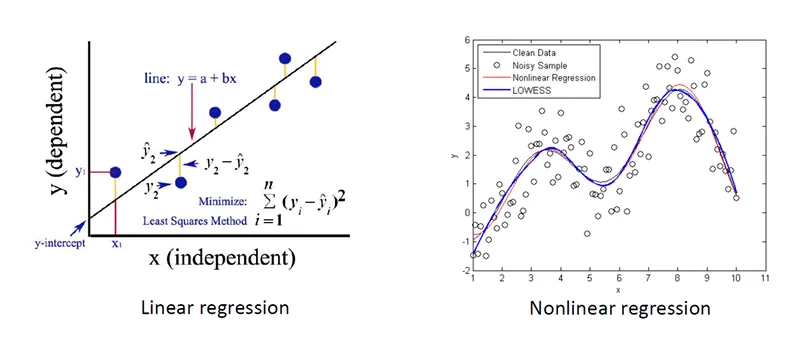
Regression (회귀)
- 수치형 데이터를 다룸
- 출력데이터는 Continous한 space
- 입력 데이터(X)를 출력 데이터(y)에 매핑하는 함수 f(X)를 찾는 것
Classification Problem
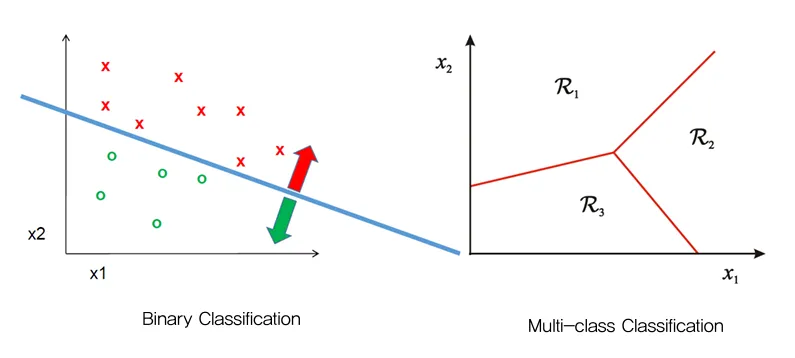
Classification (분류)
- 범주형 데이터를 다룸
- 출력데이터는 Discrete한 space
- 입력 데이터(X)를 특정 클래스 또는 범주(y)로 분류하는 함수 f(X)를 찾는 것
Clustering Problem
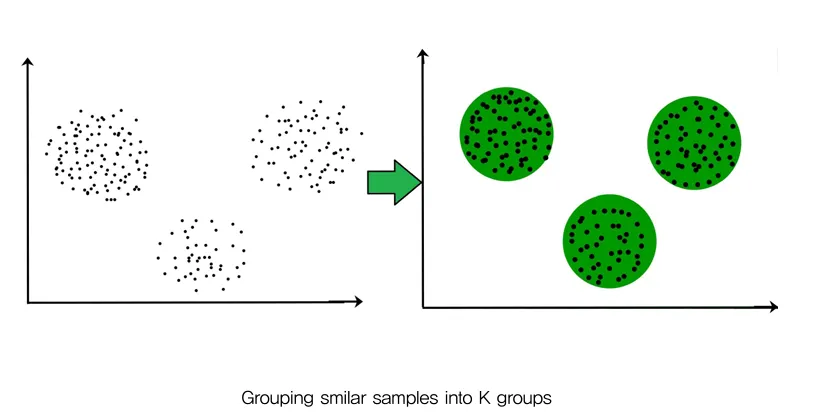
Clustering (군집화)
- 비지도 학습의 일종으로, 레이블이 없는 데이터를 다룸
- 유사한 특성을 가진 데이터들을 그룹(클러스터)으로 묶는 것
- metric를 정하기 어려운 점이 있음
Dimensionality Reduction Problem
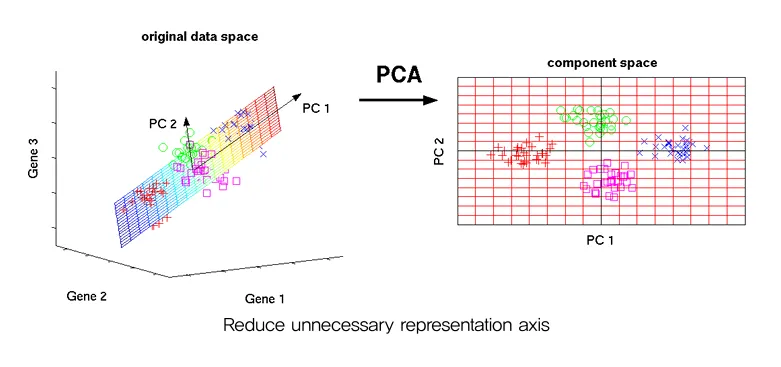
Dimensionality Reduction (차원 축소)
- 고차원 데이터를 낮은 차원으로 변환하여 데이터의 복잡성을 줄이는 방법
- 데이터의 주요 특성을 유지하면서 불필요한 정보를 제거하는 기술
- 데이터가 복잡해질수록 효과적인 분석과 시각화를 위해 차원 축소 기법을 사용함
- 다른 알고리즘과 함께 사용할 수 있음
💡
차원의 저주는 데이터의 차원이 높아질수록 데이터가 희소해지고 분석이 어려워지는 현상을 의미함
- 데이터 희소성 : 차원이 늘어날수록 데이터 포인트들이 멀리 떨어져 있어 유용한 패턴이나 정보를 찾기 어려움
- 과적합: 데이터가 많아 보이지만 실제로는 유용한 정보가 부족해져 모델이 훈련 데이터에> 만 잘 맞고 새로운 데이터에는 잘 작동하지 않게 됨.
- 계산 비용 : 차원이 높을수록 계산이 복잡해져 모델을 학습하거나 예측하는 데 더 많은 시간과 자원이 필요함
- 시각화의 어려움 : 4차원 이상의 데이터는 사람이 이해하기 어렵고 시각화하기 힘듦

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.