
Super Resolution
기계학습 수업의 Final Project로 CVPR 2016의 논문 "Is the deconvolution layer the same as a convolutional layer?" 를 참고하였습니다.

Super Resolution(고해상화)는 Low Resolution(저해상도)의 이미지나 영상을 High Resolution(고해상도)이미지로 변환시키는 것을 의미합니다.
과거에는 영상처리기법의 다양한 보간법을 사용해 화질을 변환했지만 현재는 딥러닝 기술을 활용하여 보다 효과적으로 화질개선을 이루고 있습니다.
딥러닝 기술을 활용한 Super Resolution에도 종류가 다양합니다. GAN(Generative Adversarial Network)을 활용한 기술이 효과적이지만 Sub-pixel Latey를 포함한 Sub-pixel CNN(Convolutional Neural Network)Model을 사용하여 Super Resolution 기술을 다뤄보도록하겠습니다.
Data set
학습에 사용한 데이터셋은 Kaggle에서 제공하는 CelebFaces Attributes Dataset을 사용하였습니다. 데이터는 총 202,509장의 사람 얼굴 사진으로 구성되어있습니다.
| Data | Train | Validation | Test | Total |
|---|---|---|---|---|
| 162,770 | 19,867 | 19,962 | 202,509 |

같은 데이터를 4배 저해상화(down scale)하여 Model의 Input data로 사용하고 원본 이미지를 Target data로 사용하였습니다.
Model
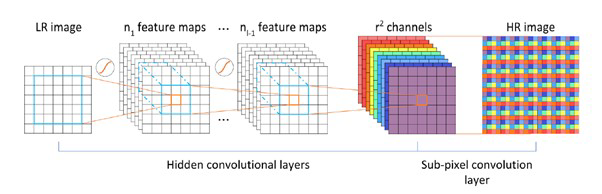
Model은 SubPixelCNN을 참고하여 구성하였습니다. 일반적인 CNN은 이미지로부터 Feature map을 추출하는 Convolutional Layers와 추출한 Features map을 활용하여 분류를 수행하는 Classifier Fully-Connected Laters로 구성됩니다. SubPixelCNN은 Classifier 대신 Feature map의 Channel을 색상으로 인식하여 단순히 재배치하는 Sub-Pixel convolution layer로 구성됩니다.
PSNR, Loss Function
Classification 문제에서는 모델의 성능을 정확도(Accuracy)를 척도로 삼는 반면, Super resolution 문제에서 통용적으로 사용되는 척도는 PSNR(Peak signal-to-noise ratio)(단위:db)입니다. 최대 신호 대 잡음비로 두 영상의 유사성을 수치로 표현한 것입니다. 수식으로 표현하면 다음과 같습니다
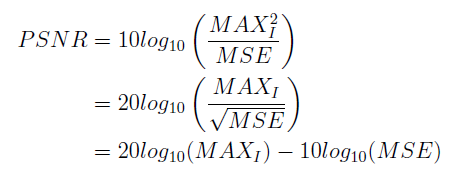
Max_I는 하나의 sample data가 구성된 값 중 최대 값을 의미하며 8bit 이진수로 표현된 RGB이미지에서는 255를 의미합니다. 이번 Application에서는 전처리 과정에서 Normalization으로 값을 변환하였기에 최대값은 1이 됩니다. 모델의 성능 척도를 올리는 관점에서 보았을 때 Mean Square Error값이 작을수록 큰 값으로 계산이 됨을 알 수 있습니다. MSE는 거리를 측정해 오차로 적용하는 방법으로 값을 근사할수록 좋은 성능을 내는 Regression 문제에서 오차함수로 많이 사용됩니다.
Output이 target data와 유사하며 PSNR역시 큰 값으로 측정되기를 바라는 관점에서 Loss function은 MES Loss function을 사용하였습니다. PSNR의 수치에 따라 영상의 품질을 말할 수 있는데 일반적으로 30db 이상의 PSNR값을 가지면 두 영상의 차이를 사람의 눈으로 확인하기 어렵다고 알려져 있습니다.
Training methodology
| Optimizer | Batch size | Learning rate | Epochs | |
|---|---|---|---|---|
| Hyper parameters | Adam | 256 | 1e-2 ~ 1e-3 | 40 |
모델 학습에 사용한 파라미터들은 위 표와 같습니다. Loss를 줄이는 것은 Adam optimizer와 Learning rate 조작을 통해 적은 시도로 충분히 낮은 값을 기록할 수 있었습니다. 그러나 낮은 오차에도 불구하고 결과는 학습 방법에 따라 달라짐을 볼 수 있었습니다. 저의 학습 방법에 있어 큰 차이를 보이길 기대했던 요인은 학습 모델의 Input channel과 output channel에 있었습니다. 때문에 RGB to RGB, Gray to RGB , Gray to Gray 로 Super Resolution을 수행하는 세가지 Model로 학습을 진행 하였습니다.

- RGB to RGB

컬러이미지에서 컬러이미지를 반환하도록 학습한 결과로 어느정도 화질 개선은 이뤘지만 전체적인 선명도나 색상의 표현이 미흡하였습니다. 이에 특별한 Layer 없이 Convolution Layer로만 이루어진 모델 구조에서 Batchnormalization과 Dropout Layer를 추가해 더 좋은 품질을 기대하였습니다. 그렇지만 눈에 띄는 성능향상을 볼 수 없었습니다. - Gray to RGB

흑백이미지에서 컬러이미지로 학습한 결과 격자가 눈에 띄게 줄어들며 화질 개선이 됨을 볼 수 있었습니다. 다만 실제 결과에 비해 색상이 뚜렷하지 않고 전체적으로 채도가 낮아진 형상을 띄었습니다. - Gray to Gray

색상을 무시하고 흑백이미지를 통해 흑백이미지를 반환하는 모델을 학습하였습니다. 색상 표현을 무시하고 화질 개선에만 집중한 모델로 앞선 모델들에 비해 좀더 좋은 품질의 영상을 확인 할 수 있었습니다.
Checkerboard Artifact
성능 개선을 위해 Model Capacity와 Depth를 변경하였으나 Checkerboard Artifact 문제를 직면하였습니다.
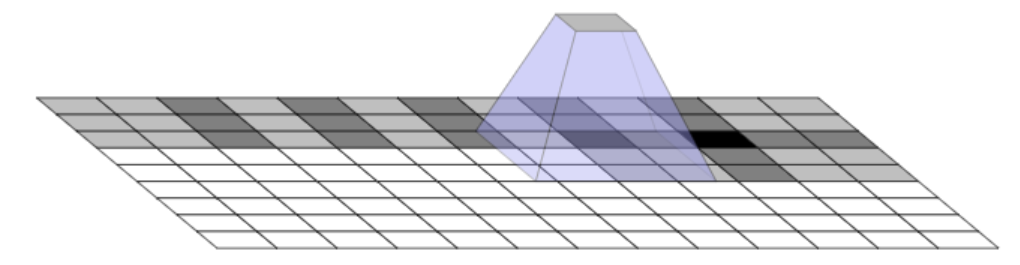
Deconvolution 연산 수행시 Filter의 크기와 Stride의 크기에 따라 Uneven overlap 이 발생하는 부분이 존재하기 때문에 생기는 현상으로 Super Resolution 연구에서 가장 조심해야할 문제점 중 하나입니다. 이를 피하는 방법 중 한가지로는 영상처리의 보간법을 기반으로 영상을 Resize 후 Convolution 연산을 수행하는 방법이 있습니다.
-
Uneven overlap
-
Checkerboard Artifact

Result
최종 결과로는 Gray to Gray Model을 사용하였습니다. 기본 RGB channel 이미지에서 각 색상을 분리해 Grayscale로 변환후 Model의 Input으로 활용하면 R,G,B 각 이미지에 대해 고해상화된 결과를 얻을 수 있었습니다. 이 결과들을 다시 RGB channel로 병합하여 이미지를 구성함으로써 고해상화와 동시에 색상에 대한 표현도 유지 할 수 있는 최적의 결과를 얻을 수 있었습니다. 최종 모델의 최저 Loss는 0.00145 , PSNR은 28.41db를 기록하였습니다.
Super-resolution 문제에서 척도로 사용되는 지표가 PSNR만 있는 것은 아닙니다. 이번 과제에서도 알 수 있듯이 비교적 좋은 PSNR 수치에도 Blurry 한 결과를 반환하는 경우가 생깁니다. 이는 PSNR에 직접적으로사용되는 MSE 값을 Loss function으로 사용하여 고해상화를 진행하다보니 수치를 높게 측정하는 방향으로만 학습이 되었다고 생각합니다. 때문에 이미 진행된 많은 연구에서 다양한 Loss 함수를 사용하고 성능 평가 척도 역시 PSNR뿐만 아니라 다양한 지표를 동시에 사용하고 있습니다.




