FaceNet, Picasa, MTCNN 논문 읽어보기

❗ 얼굴 인식 프로젝트 진행 중 사용한 FaceNet의 깊은 이해를 위해 처음으로 논문을 제대로 읽어본 터라,, 잘못된 개념 및 부족한 사항이 존재할 수 있습니당,,,ㅎ
피드백은 언제나 환영입니다😄
FaceNet
FaceNet의 기본 원리
FaceNet은 얼굴 인식(recognition), 검증(verification), 군집화(clustering)과 같은 작업을 위해 설계된 CNN 기반의 딥러닝 모델이다. 이 모델의 핵심 아이디어는 얼굴 이미지를 고정된 차원의 벡터 공간으로 변형(임베딩, embedding)하는 것이다. 두 얼굴의 이미지가 같은 사람인지의 여부를 임베딩 공간에서의 거리를 통해 판단한다.
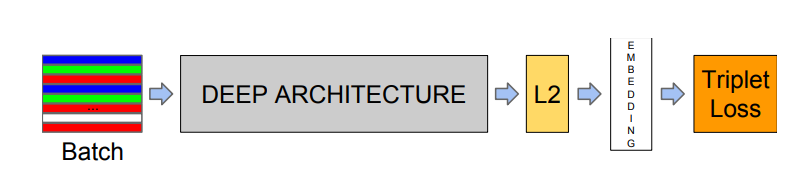
임베딩 공간
임베딩 공간은 고차원의 유클리드 공간으로, FaceNet은 각 얼굴 이미지를 이 공간의 한 점으로 매핑(mapping)한다.
🔨 임베딩(Embedding) in Image
이미지에서의 임베딩은 고차원의 이미지 데이터를 저차원 벡터 공간으로 변환하는 방법을 말한다.
RGB 이미지는 MxNx3의 크기를 가지는데, 만약 1,280×720×3 크기의 사진이라면 크기가 2,764,800 차원으로 매우 커지게 되는 것이다. 과연 이 모든 차원이 의미가 있을지 생각해본다면, 그렇지 않으므로 임베딩 과정에서 데이터의 중요한 특징을 유지하면서도 표현을 단순화하거나 효율적으로 만드는 것을 목표로 한다.
임베딩의 주요한 목적을 정리하면 아래와 같다.
- 불필요한 노이즈나 중복 정보를 제거
- 임베딩 공간에서 벡터 간의 거리를 사용해 유사도 측정 가능
- 메모리 사용량과 계산 복잡도가 줄어들게 됨
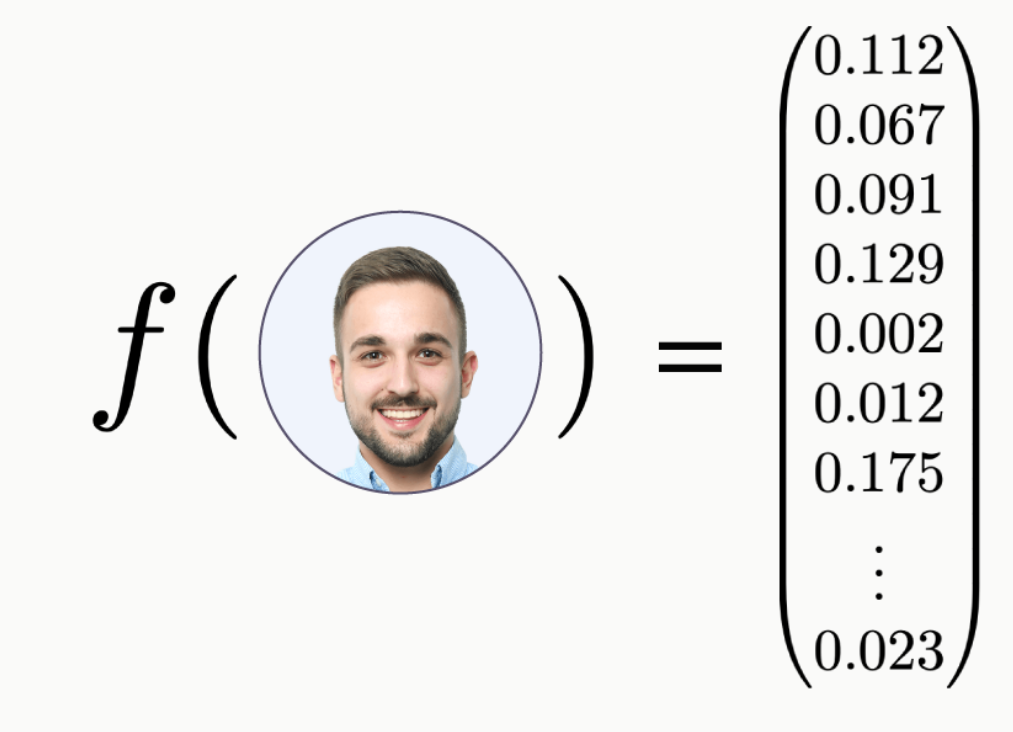
FaceNet에서는 고차원의 이미지 데이터를 128차원의 벡터로 임베딩했다.(여전히 높은 차원이지만 원본 이미지 차원에 비하면 "비교적" 매우 작은 차원이다.) 각 차원은 얼굴의 특정한 특징을 나타내게 되며, 임베딩의 과정은 다음과 같다.
- 이미지 입력 : 고차원의 픽셀 데이터로 표현된 원본 얼굴의 이미지를 입력한다.
- 특징 추출 : 합성곱 신경망(CNN)이 얼굴 이미지에서 특징을 추출한다. 이 과정을 통해 얼굴의 중요한 시각적 특징들이 강조된다.
- 임베딩 벡터 생성: 추출된 특징을 바탕으로 이미지 데이터를 벡터로 표현하고, FaceNet의 학습을 통해 특정 임베딩 공간으로 변환한다.
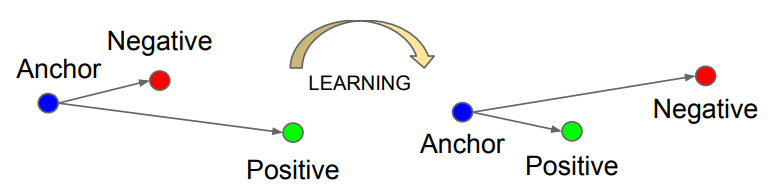
Triplet 손실함수
FaceNet은 Triplet 손실함수를 사용한다. 이 손실함수는 세 가지 얼굴 이미지를 사용하여 모델을 훈련시킨다.
세 가지 얼굴 이미지 종류는 다음과 같다.
- 🔵Anchor : 기준이 되는 얼굴 이미지
- 💚Positive : Anchor와 같은 사람의 다른 얼굴 이미지
- 🔴Negative : Anchor와 다른 사람의 얼굴 이미지
Triplet 손실함수의 목표는 Anchor와 Positive의 거리는 가깝게, Anchor와 Negative의 거리는 멀게 만드는 것이다. 수식으로 표현하면 아래와 같다.
이때 는 Margin으로, 거리 차이의 최솟값을 의미한다.
FaceNet에서 사용한 손실함수의 수식은 다음과 같다.
수식을 바탕으로 손실함수를 해석해보면 시그마 안의 수식이 Anchor-Positive 와 Anchor-Negative 의 벡터 간의 거리 제곱 차가 최소한 (Margin) 이상이 되어야 0이 출력된다. 이는 단순히 Positive가 Negative보다 Anchor에 가깝기만 하면 되는 것이 아니라 만큼 더 가까워야 손실함수가 최소가 된다는 것이다.
이를 바탕으로 학습한 결과는 아래와 같다.
Picasa
https://link.springer.com/chapter/10.1007/978-3-319-10599-4_8
Picasa는 FaceNet 논문에서 사용했던 얼굴 탐지(Detection) 모델이다.
이 논문에서는 얼굴 정렬(face alignment)을 이용하여 얼굴 탐지의 성능을 향상시켰다. 얼굴 정렬을 통해 얻어진 정렬된 얼굴이 더 나은 feature를 제공하고, 얼굴과 비얼굴을 구별하는 정확도가 높아진다.
Cascade Face Detection
Cascade face detection은 얼굴 검출 알고리즘 중 하나로 이미지에서 얼굴을 효율적으로 탐지하기 위해 일련의 단계를 통해 점진적으로 얼굴과 비얼굴을 구분하는 방법이다.
단계적으로 이미지의 각 영역에 대해 약한 분류기(weak classifier)를 적용하여 얼굴이 아닌 영역을 빠르게 배제하고, 얼굴일 가능성이 높은 영역에 대해 더 정밀한 검사를 진행한다.
(마치 영단어를 외울 때 아는 것은 빠르게 넘기고 모르는 것만 집중적으로 외우는 것과 같다고 볼 수 있다.)
🧐 특징 추출
일반적으로 사용되는 특징 추출 방법은 Haar-like features로, 이는 이미지의 밝기 차이를 기반으로 얼굴의 특정 패턴(눈, 코, 입,,)을 포착할 수 있는 간단한 특징이다. 특정 영역 내에서 픽셀 강도의 합을 계산하고 이를 인접 영역과 비교하는 방식으로 계산한다.
예를 들어, 눈은 얼굴의 상단 부분에서 밝기가 낮은 영역으로 나타나고, 위에 있는 밝은 영역인 이마와 비교하여 특정 패턴을 형성한다.
Face Alignment
사진에서 얼굴의 위치와 포즈가 다양할 수 있기 때문에 정렬되지 않은 사진에 대해서는 얼굴 탐지이 정확도가 떨어질 수 있다. 이때 정렬(alignment)은 얼굴 이미지 내에서 눈, 코, 입 등의 주요 특징점(facial landmarks)을 찾아내고, 이를 활용해 얼굴을 표준적인 위치로 맞추는 작업이다.
Joint Cascade Structure
face alignment와 face detection을 동일한 cascade structure 내에서 동시에 학습하는 방법이다.
1. 간단한 검출 및 초기값 설정
이미지 내의 각 검출 후보 영역에 대해 mean face shape을 초기값으로 설정한다.
이는 후보 영역에 평균적인 얼굴 모양을 대입하여 임의로 설정한다는 뜻이다.
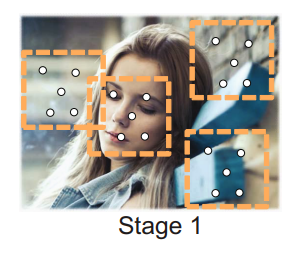
2. 정렬과 검출의 반복
검출된 후보 영역에서 얼굴의 특징점을 점진적으로 조정하면서 이를 기반으로 추가적인 특징을 추출한다. 각 단계에서 분류기와 회귀기는 현재가지 조정된 얼굴 모양을 기반으로 학습된다. 해당 과정을 각 후보영역에 대해 반복한다.
단계를 지날수록 더 복잡한 분류기와 회귀기를 사용하여 검출과 정렬의 정확도를 높인다. 각 단계에서 후보의 개수는 줄어들고 남은 후보들의 정렬 정확도는 향상된다.
3. 최종 결과
모든 단계를 통과한 후보 영역이 얼굴로 최종 검출되며, 해당 영역에 대한 얼굴 모양도 함게 검출된다.
MTCNN
https://arxiv.org/abs/1604.02878
해당 모델은 현재 진행하고 있는 FaceNet을 바탕으로 한 얼굴 인식 프로젝트의 레퍼런스에서 사용한 것이기에 조사하여 읽어보았다.
(레퍼런스: https://github.com/ColdBottle0226/FaceNet)
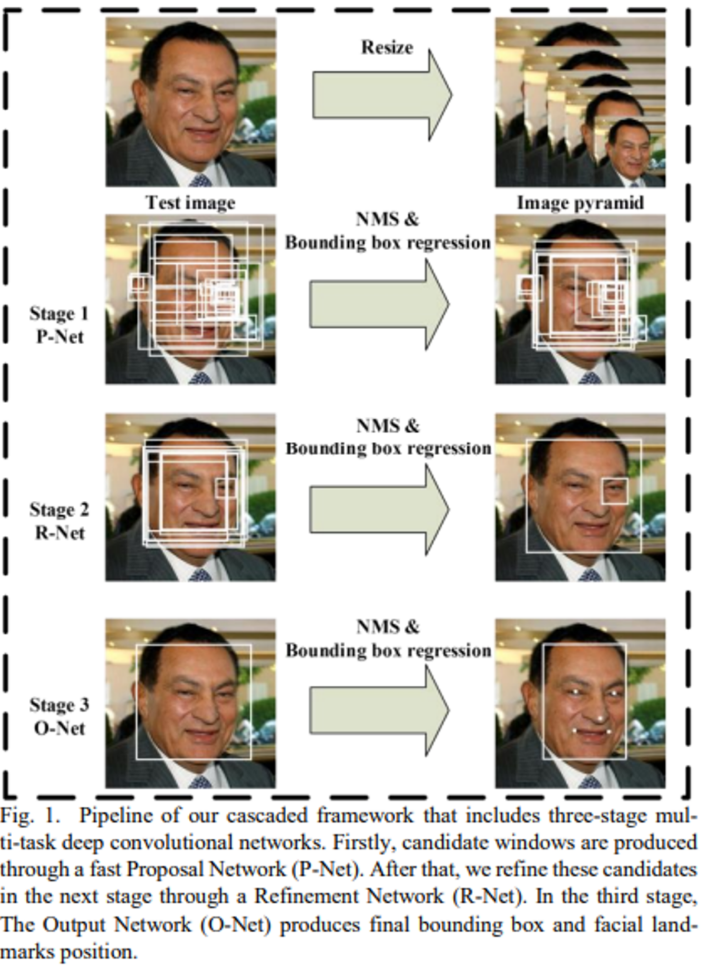
이 논문에서는 다중 작업 학습을 통해 통합된 Cascade CNN을 제안한다. 이 제안된 CNN은 세 단계로 구성된다. 첫 번째 단계에서는 간단한 CNN을 사용하여 후보 창을 신속하게 생성하고, 두 번째 단계에서는 더 복잡한 CNN으로 비얼굴 후보를 제거한다. 마지막 단계에서는 가장 복잡한 CNN을 사용하여 얼굴 랜드마크 위치를 출력한다.
또한 online hard sample mining으로 학습 과정에서 자동으로 어려운 샘플을 선택하여 성능을 향상시키는 새로운 전략을 도입했다. 이는 detection model을 강화하는 데에 덜 도움이 되는 쉬운 샘플을 무시하여 수동 샘플 없이도 더 나은 성능을 보여준다.
전반적인 과정
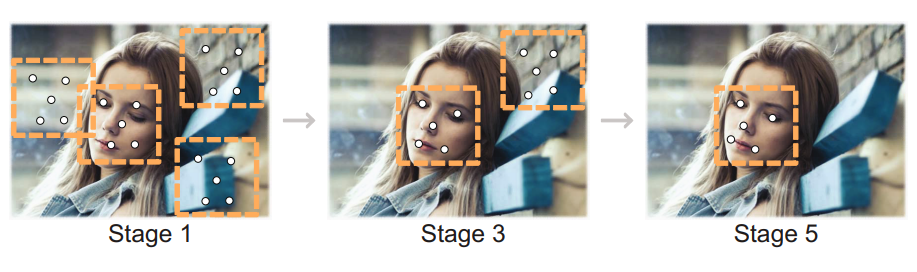
1단계
우선 이미지가 주어지면 이를 다양한 스케일로 resize하여 이미지 피라미드를 만든다. 이 피라미드는 다음 세 단계로 이루어진 Cascade 프레임워크의 input이 된다.
🧐 이미지 피라미드를 왜 만드는가?
- 이미지를 다양한 크기로 조절함으로써 단일 크기의 얼굴만 탐지하는 것이 아니라, 이미지 내의 모든 크기의 얼굴을 탐지할 수 있다.
- detection 모델의 구조나 가중치를 변경하지 않아도 된다.
- 여러 스케일의 얼굴을 학습하면 비스듬히 보이는 얼굴도 효과적으로 탐지할 수 있다.
2단계
Proposal Network(P-Net)을 사용하여 후보 창과 그들의 Bounding Box 회귀 벡터를 추출한다. 이후 추정된 바운딩 박스 회귀 벡터를 사용하여 후보 창을 보정하고, 비최대 억제(NMS)를 적용하여 중복된 후보 창을 병합한다.
🧐 비최대 억제(Non-Maximun Suppression, NMS)
NMS는 Bounding Box에 대한 Confidence Score가 가장 높은 Box를 선택하고, 해당 Box와의 IoU가 threshold보다 높은 Box를 제거하는 방법이다.IoU(Intersection over Union)
말 그대로 교집합/합집합 을 말한다.
두 개 이상의 Bounding Box가 있을 때 Box가 많이 겹쳐질수록 IoU가 높아진다.
3단계
모든 후보 창은 또 다른 CNN인 Refinement Network(R-Net)에 입력되며, 이 네트워크는 더 많은 비얼굴 후보를 제거하고, Bounding Box 회귀로 보정하며, NMS로 후보 창을 병합한다.
4단계
마지막은 Output Network(O-Net)을 거치며, 두 번째 단계와 유사하지만 이 네트워크는 다섯 개의 얼굴 특징점(landmark) 위치를 출력한다.
