MediaPipe Hands: On-device Real-time Hand Tracking

https://arxiv.org/pdf/2006.10214
Abstract
- 우리는 무려 실시간으로 모바일 환경에서도 아주 잘 돌아가는 손 트래킹 방법을 보여줄 것임
- 파이프라인은 두 갈래로 나뉨
- 손바닥 탐지기(Palm Detector) → 손 바운딩 박스 생성
- 손 특징 모델(Hand Landmark Model) → 손 뼈대 예측
Introduction
기존의 문제점
- 기존 연구들의 대부분은 아주 특별한 하드웨어(ex. 깊이 센서)를 사용함
- 실시간으로 돌릴 수 없는 아주 무거운 모델
- 따라서 플랫폼에 한계가 발생
논문의 차이점 및 기여 내용
- 모바일 환경에서도 여러 개의 손을 추적할 수 있음
- 센서 없이 오직 RGB Input에 대해서도 *2.5D의 손 포즈를 예측함
- 다양한 플랫폼에서도 사용 가능
📦 2.5D
일반적으로 말하는 평면의 2D와 깊이(Depth)를 합한 개념
즉 해당 모델은 손의 깊이까지도 센서 없이 예측할 수 있다는 것임,,!
Architecture
이 모델은 abstract에서 말한 것과 같이 두 개의 모델이 함께 작동함.
- 손바닥 탐지기(Palm Detector)
- 바운딩 박스를 통해 손바닥의 위치를 알아냄
- 입력 이미지는 전체 크기(full)의 이미지
- 손 특징 모델(Hand Landmark Model)
- 높은 정확도의 2.5D 특징점을 return
- 탐지기로부터 넘어온 잘려진(cropped) 이미지를 입력값으로 받음
*탐지기에 잘린 이미지를 입력값으로 넣는 이유는
- 데이터 증강(aumentation)을 줄일 수 있음
- 특징점(landmark)의 위치를 정확하게 알아낼 수 있도록 함
❓ 잘린 이미지와 두 근거 사이의 관계
데이터 증강은 데이터의 양이 부족하거나 다양한 상황에 대처하기 위해 사용됨
그런데 만약 탐지기의 과정을 거친 잘린 이미지를 특징점 모델의 입력값으로 넣게 되면
- 복잡한 배경이 제거되며 특징점 모델이 더 안정적으로 학습할 수 있게 됨
- 탐지기로부터 이미 손바닥의 위치 정보 또한 얻었기 때문에 사진의 위치나 크기를 변형할 필요가 없어짐
또한 *이전 프레임에서 특징점 예측으로부터 얻어낸 바운딩 박스를 다음 프레임의 입력으로 사용함으로써 모든 프레임에서 탐지기를 사용할 필요가 없어짐.
🧐 아까는 탐지기(바운딩 박스) 이후에 특징점 모델이라며,,,?
아까는 탐지기에서 바운딩 박스를 만든 후 탐지기에서 자른 이미지를 특징점 모델의 입력값으로 사용한다고 했는데,,, 지금은 또 특징점 예측으로 얻어낸 바운딩 박스라고 말하니,,
잘 읽어보니 마지막에
The detector is only applied on the first frame or when the hand prediction indicates that the hand is lost
라고 적혀있음
이는 즉 탐지기 이후에 특징점 모델이 성립하는 경우는 처음과 손이 감지되지 않았을 때 뿐이라고 이해할 수 있음
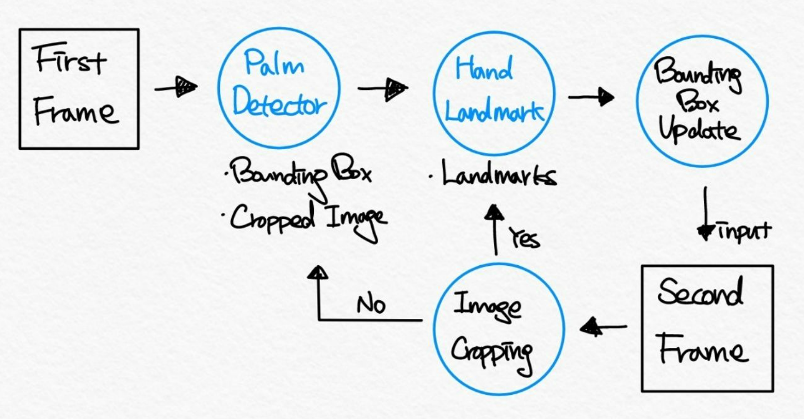
이를 바탕으로 깨달은 구조를 직접 그려보았음.
(솔직히 제가 그러놓고 좀 감탄했습니다.)
1. 첫 번째 프레임이 들어오면 탐지기가 바운딩 박스를 생성 및 사진을 자름
2. 특징점 모델이 특징점을 예측
3. 예측한 특징점을 바탕으로 바운딩 박스를 새로 업데이트
4. 3번의 바운딩 박스를 두 번째 프레임의 입력값으로 넣음
5. 바운딩 박스를 바탕으로 이미지를 크롭
_5-1. 손을 탐지했다면 특징점 모델의 입력값으로 보내어 2~5 과정 반복
_5-2. 손을 탐지하지 못했다면 다시 탐지기로 돌아가 1~5 과정 반복
즉 처음에 말한 탐지기 → 특징점 모델은 초기 입력된 사진에 대해 이루어지는 과정이고, 이후에 말한 특징점 → 바운딩 박스는 그 이후의 과정들을 이야기 한 것이었음
BlazePalm Detector
- 초기 이미지가 들어올 때 손의 위치를 탐지하는 데에는 모바일 실시간 적용을 위해 최적화한 Single-Shot Detecor를 사용함 (BlazeFace에서 비슷한 방식을 사용)
- 손은 다양한 크기와 가려지기 쉽다는 등의 이유로 탐지하기 어려움,,, → 우리가 해결해야 할 점
- 우리는 기존과 다른 방법을 써버림😎
손 대신에 손바닥을 탐지하자
왜냐??
- 손바닥(손가락과 손목 사이의 넓은 평평한 부분)이나 주먹은 일반적인 손(손가락, 손바닥, 손목을 포함)보다 간단하기 때문! → 손가락을 포함하면 관절로 연결된 구조 때문에 탐지가 어려움,,ㅠ
- *비최대 억제(Non-Maximum Suppression)가 더 잘 작동됨
- *오직 정사각형의 바운딩 박스만을 사용해서 모델링이 가능함
✋ 왜 NMS가 손바닥에서 더 잘 작동할까?
비최대 억제는 객체 탐지에서 한 객체에 대해 Confidence Score가 가장 높은 바운딩 박스만을 남기고, IoU(Intersection over Union)가 높은 박스를 억제함.
손바닥같이 작은 객체들은
- 바운딩 박스가 겹칠 일이 잘 없고
→ 여러 손 바닥인데 IoU 때문에 인식 안 될 위험 낮아짐- 대체로 객체의 경계가 더 분명함
→ 경계가 분명하면 confidence가 높을 확률이 높음
따라서 손바닥에서 NMS가 잘 작동하게 되는 것임
📦 손바닥이 아니라 손도 정사각형 바운딩 박스로 할 수 있지 않나?
- 손바닥은 대개 균등하게 넙적한 모양을 가지고 있음
→ 정사각형 박스만으로도 충분함- 그러나 일반적으로 손은 손가락 때문에 한쪽으로 길쭉한 모양을 하고 있음
→ 짧은 부분을 기준으로 정사각형 바운딩 박스를 적용하면 포함하지 못하는 부분이 생길 수 있음
→ 그렇다고 긴 부분을 기준으로 정사각형 바운딩 박스를 적용하면 손을 다 포함하긴 하지만 Bounding 박스라는 이름과 맞지 않게 남는 공간이 많아짐(비효율적)
따라서 일반적으로 손은 손바닥보다 다양한 모양의 바운딩 박스가 필요하게 됨,,
Encoder-decoder feature extractor 사용하자
*FPN과 같은 *Encoder-decoder feature extractor를 사용하여 작은 객체에 대한 장면 맥락 인식(scene-context awareness)이 가능함
🔠 Encoder, Decoder, FPN
- Encoder: 이미지에서 고차원의 특징을 추출한 채로 해상도를 낮추는 것
- Decoder: 이미지의 중요한 정보를 유지한 채 해상도를 높여 복원하는 것
- FPN(Feature Pyramid Networks): Encoding 으로 이미지의 중요한 특징을 추출해내고, 이 특징을 살린 채로 다양한 해상도로 Decoding함 . 이후 여러 해당도의 피처맵들을 하나로 결합함
→ 다양한 크기의 객체에 대응이 가능해짐
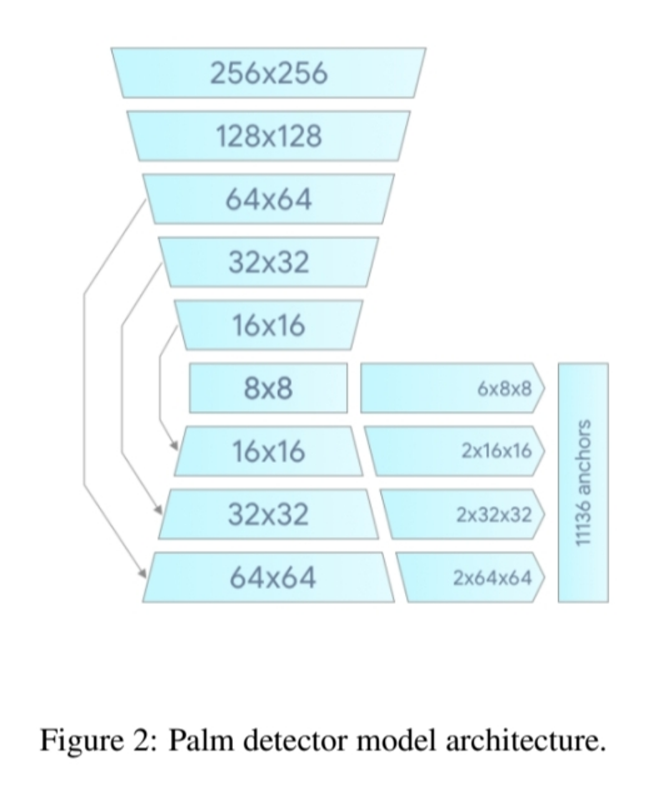
아래는 해당 논문에서 제시한 FPN구조임
위 사진을 보면 차근차근 인코딩하다가 8x8 크기에서 다시 디코딩하는 것을 볼 수 있음.
기본적으로 각 해상도에서 2개의 앵커를 뽑아내지만, 8x8 크기의 해상도에서만 앵커가 6개임. 이는 해당 모델에서 작은 크기의 객체를 더 잘 탐지하기 위해 8x8의 앵커의 개수를 늘렸다고 이해할 수 있음.
Focal Loss를 최소화하자
높은 스케일 분산(High Scale Variance)을 갖는 많은 앵커들을 더 잘 학습하기 위해 *Focal Loss를 최소화함.
📷 Focal Loss & High Scale Variance
Focal Loss는 간단히 말해 배경과 같이 탐지하기 쉬운 부분에 대한 가중치를 낮추고, 객체와 같이 탐지하기 어려운 부분에 대한 가중치를 더 부여하는 손실함수 중 하나임.
우리가 탐지하고자 하는 손바닥은 전체 사진에서 차지하는 부분이 매우 작은 객체이므로 해당 손실함수를 사용하는 것이 더 효율적일 것.
여기서 말하는 High Scale Variance는 FPN 구조를 통해 다양한 해상도에서 앵커를 추출하며 발생한 것임. 당연히 다양한 해상도에서 앵커를 추출했으므로 앵커의 크키가 아주 작지만 다양하고, 또 매우 많을 거임.
→ 여기서 나온 작은 앵커들을 Focal Loss로 학습한다고 이해하면 됨
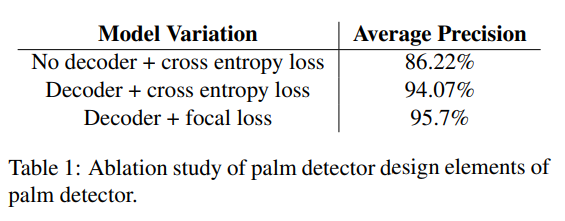
결과를 보았을 때, Decoder와 Focal Loss를 함께 사용하는 것이 더 정확도가 높은 것을 알 수 있음.
Hand Landmark Model
탐지기 이후의 과정인 특징점 모델은 21개의 2.5D 특징점들의 좌표를 Regression을 통해 탐지함
이 모델의 출력값은 세 개로 나누어짐
- 21개의 특징점들의 2.5D 좌표
- 손이 존재할 확률
→ 이 확률이 임계값보다 낮으면 탐지기가 호출되는 것!
- 손잡이에 대한 이진 분류
특징점 모델의 세 출력과 입력되는 데이터들의 관계는 아래와 같음.
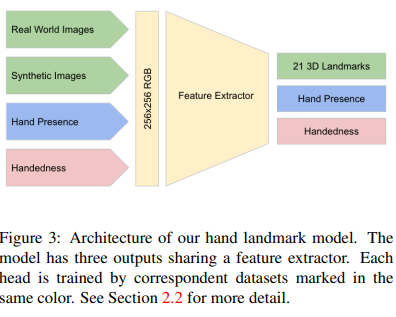
여기서 특이한 점은 손목 좌표를 학습할 때에는 오직 인위적인 이미지(Synthetic Image)만을 사용한다는 것임.
🧐 손목 좌표 학습에는 왜 인위적인 이미지만 사용할까?
우선 해당 논문에서 사용하는 이미지 데이터셋의 종류는 크게 두 가지임.
- 현실 이미지(Real World Image)
→ 실내, 야외에서 직접 찍은 사진- 인위적 이미지(Synthetic Image)
→ 컴퓨터 그래픽을 활용해 인위적으로 만든 사진
손목은 특히 다른 부위에 비해 작은 신체 부위이므로, 정밀한 라벨링이 필요함. 그러나 현실 이미지에서 손목을 학습시킬 경우, 주변 환경 요인의 영향으로 제대로 학습되지 않을 가능성이 있음.
컴퓨터 그래픽을 활용해 이미지를 만든다면 원하는 부위를 원하는 상황에 맞추어 이미지를 얻어낼 수 있기에 현실 이미지보다 더 높은 학습 정확도를 만들어낼 수 있을 것임.
모든 이미지를 인위적으로 만들어내기에는 현실과 다른 결과를 출력할 수도 있기에, 작은 부위인 손목에만 인위적 이미지만을 사용하여 학습시키는 것으로 예상됨.
Dataset and Annotation

Palm Detector
손바닥을 탐지하는 데에는 현실 이미지만을 사용함.
현실 이미지만으로도 손바닥의 위치를 다양하게 학습하기에 충분하기 때문.
Hand Landmark Model
특징점 모델에는 현실 이미지와 인위적 이미지를 모두 사용함.
현실 이미지에 21개의 특징점에 대한 주석을 모두 달고, 인위적 이미지는 3D 관절을 투영하여 정답 데이터(Ground-Truth)로 사용함.
Hand Presence
손의 존재성에 대해 학습할 때에는 일부 현실 이미지를 사용함.
Positive Example에는 현실 이미지가 그대로 사용되며, Negative Example에는 주석처리된 부분을 제외한 부분을 사용함.
Handedness
손잡이를 학습할 때에는 일부 현실 이미지에 주석을 달아 학습함.
Results
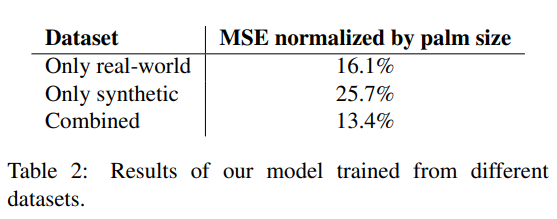
위 표를 통해서 현실 이미지 혹은 인위적 이미지 중 하나만을 사용하였을 때보다 둘을 함께 사용했을 때 더 나은 성능을 보임을 알 수 있음. 또한 인위적 이미지만을 사용했을 때에 MSE가 25.7%로 높지만 현실 이미지와 함께할 때 13.4%로 확연하게 낮아지는 것으로 보았을 때, 현실 이미지의 비율을 더 확장하면 모델의 일반화 능력을 더 향상시킬 수 있을 것이라 기대할 수 있음.
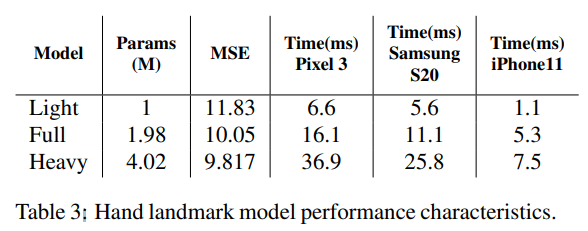
위 표에서는 파라미터의 정도에 따라 모델의 크기를 나누고, 모바일 별 실행 시간 비교하고 있음. Heavy는 확실히 파라미터의 양이 많아진 만큼 오차가 줄었지만 실행 시간이 너무 오래 걸리는 것을 볼 수 있고, Light와 Full은 Heavy에 비해 빠르지만 오차가 조금 더 큰 것을 볼 수 있음.
해당 논문에서는 Full 모델이 우수한 질과 속도를 가지고 있다고 소개하고 있음.
(세 모델 중 속도와 오차를 고려할 때, 가장 적당한 모델으로 생각됨)
Implementation in MediaPipe
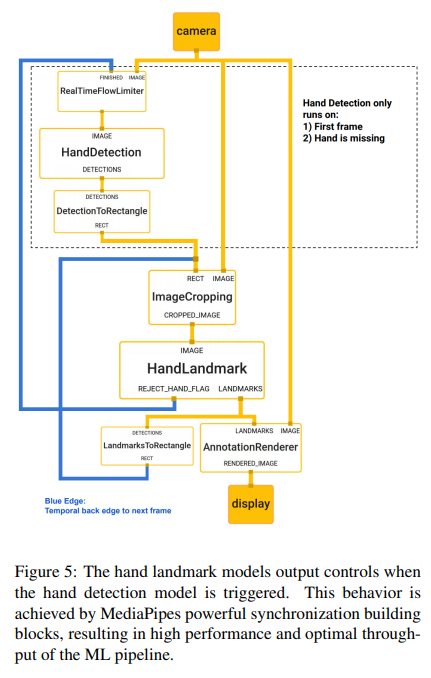
해당 파트에서는 위 그래프에 그려진 대로 작동되며, 이 모든 것이 구글의 MediaPipe로 이루어짐을 이야기함.
앞서 이야기했던 내용을 그대로 요약하여 나타내었기에 추가적으로 더 설명하지는 않겠음.
Application examples
해당 논문에서는 활용 예시로 크게 두 가지를 제안하고 있음.
Gesture Recognition
Static Gesture Recognition
아래의 알고리즘을 통해 정적인 제스처를 인식함.
1. 손가락의 상태(굽은 상태, 펴진 상태)를 관절의 누적된 각도를 통해 결정함
2. 손가락 상태의 집합(누적된 각도)을 미리 정의한 제스처 집합에 매핑

예를 들어 모든 손가락을 다 펴게 되면 손가락을 다 폈을 때의 각도들의 집합이 FIVE 제스처에 해당하는 집합과 매핑되고, FIVE라고 인식되는 것.
Dynamic Gesture Recognition
정적 제스처 인식에서 나아가 랜드마크의 시퀀스를 사용하여 동적 제스처도 인식할 수 있음.
AR
논문에서는 손의 골격을 바탕으로 하여 골격 위에 AR 효과를 씌우는 것을 제안함. 아래 그림과 같이 골격을 네온 스타일로 랜더링 할 수 있음.

Conclusion
- MediaPipe Hands라는 *End-to-End 손 추적 방안을 제시함.
- 이것을 오픈 소스로 공개하여 제스처 컨트롤 및 AR/VR 활용에 우리의 파이프라인을 사용할 수 있도록 함.
🧐 End-to-End 모델
입력부터 최종 결과까지 전체 과정을 하나의 시스템으로 처리할 수 있는 모델